 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Resolved Coral Reef Thermal Fields from Satellite SST and Sparse In-Situ Loggers Using Physics-Informed Neural Networks
Apr 14, 2026Satellite sea surface temperature (SST) products underpin global coral bleaching monitoring, yet they measure only the ocean skin. Corals inhabit depths from the shallows to beyond 20 metres, where temperatures can be 1-3°C cooler than the surface; applying satellite SST uniformly to all depths therefore overestimates subsurface thermal stress. We present a physics-informed neural network (PINN) that fuses NOAA Coral Reef Watch SST with sparse in-situ temperature loggers within the one-dimensional vertical heat equation, enforcing SST as a hard surface boundary condition and jointly learning effective thermal diffusivity (\k{appa}) and light attenuation (Kd). Validated across four Great Barrier Reef sites (30 holdout experiments), the PINN achieves 0.25-1.38°C RMSE at unseen depths. Under extreme sparsity (three training depths), the PINN maintains 0.27°C RMSE at the 5 metre holdout and 0.32°C at the 9.1 metre holdout, where statistical baselines collapse to >1.8°C; it outperforms a physics-only finite-difference baseline in 90% of experiments. Depth-resolved Degree Heating Day (DHD) profiles show that thermal stress attenuates with depth: at Davies Reef, DHD drops from 0.29 at the surface to zero by 10.7 metres, consistent with logger observations, while satellite DHD remains constant at 0.31 across all depths. However, the PINN underestimates absolute DHD at shallow depths because its smooth predictions attenuate the short-duration peaks that drive threshold exceedances; PINN DHD values should be interpreted as conservative lower bounds on depth-resolved stress. These results demonstrate that physics-constrained fusion of satellite SST with sparse loggers can extend bleaching assessment to the depth dimension using existing observational infrastructure.
Weed Detection in Challenging Field Conditions: A Semi-Supervised Framework for Overcoming Shadow Bias and Data Scarcity
Aug 27, 2025The automated management of invasive weeds is critical for sustainable agriculture, yet the performance of deep learning models in real-world fields is often compromised by two factors: challenging environmental conditions and the high cost of data annotation. This study tackles both issues through a diagnostic-driven, semi-supervised framework. Using a unique dataset of approximately 975 labeled and 10,000 unlabeled images of Guinea Grass in sugarcane, we first establish strong supervised baselines for classification (ResNet) and detection (YOLO, RF-DETR), achieving F1 scores up to 0.90 and mAP50 scores exceeding 0.82. Crucially, this foundational analysis, aided by interpretability tools, uncovered a pervasive "shadow bias," where models learned to misidentify shadows as vegetation. This diagnostic insight motivated our primary contribution: a semi-supervised pipeline that leverages unlabeled data to enhance model robustness. By training models on a more diverse set of visual information through pseudo-labeling, this framework not only helps mitigate the shadow bias but also provides a tangible boost in recall, a critical metric for minimizing weed escapes in automated spraying systems. To validate our methodology, we demonstrate its effectiveness in a low-data regime on a public crop-weed benchmark. Our work provides a clear and field-tested framework for developing, diagnosing, and improving robust computer vision systems for the complex realities of precision agriculture.
Learning from the Giants: A Practical Approach to Underwater Depth and Surface Normals Estimation
Oct 02, 2024



Monocular Depth and Surface Normals Estimation (MDSNE) is crucial for tasks such as 3D reconstruction, autonomous navigation, and underwater exploration. Current methods rely either on discriminative models, which struggle with transparent or reflective surfaces, or generative models, which, while accurate, are computationally expensive. This paper presents a novel deep learning model for MDSNE, specifically tailored for underwater environments, using a hybrid architecture that integrates Convolutional Neural Networks (CNNs) with Transformers, leveraging the strengths of both approaches. Training effective MDSNE models is often hampered by noisy real-world datasets and the limited generalization of synthetic datasets. To address this, we generate pseudo-labeled real data using multiple pre-trained MDSNE models. To ensure the quality of this data, we propose the Depth Normal Evaluation and Selection Algorithm (DNESA), which evaluates and selects the most reliable pseudo-labeled samples using domain-specific metrics. A lightweight student model is then trained on this curated dataset. Our model reduces parameters by 90% and training costs by 80%, allowing real-time 3D perception on resource-constrained devices. Key contributions include: a novel and efficient MDSNE model, the DNESA algorithm, a domain-specific data pipeline, and a focus on real-time performance and scalability. Designed for real-world underwater applications, our model facilitates low-cost deployments in underwater robots and autonomous vehicles, bridging the gap between research and practical implementation.
Semi-Supervised Weed Detection for Rapid Deployment and Enhanced Efficiency
May 12, 2024



Weeds present a significant challenge in agriculture, causing yield loss and requiring expensive control measures. Automatic weed detection using computer vision and deep learning offers a promising solution. However, conventional deep learning methods often require large amounts of labelled training data, which can be costly and time-consuming to acquire. This paper introduces a novel method for semi-supervised weed detection, comprising two main components. Firstly, a multi-scale feature representation technique is employed to capture distinctive weed features across different scales. Secondly, we propose an adaptive pseudo-label assignment strategy, leveraging a small set of labelled images during training. This strategy dynamically assigns confidence scores to pseudo-labels generated from unlabeled data. Additionally, our approach integrates epoch-corresponding and mixed pseudo-labels to further enhance the learning process. Experimental results on the COCO dataset and five prominent weed datasets -- CottonWeedDet12, CropAndWeed, Palmer amaranth, RadishWheat, and RoboWeedMap -- illustrate that our method achieves state-of-the-art performance in weed detection, even with significantly less labelled data compared to existing techniques. This approach holds the potential to alleviate the labelling burden and enhance the feasibility and deployment speed of deep learning for weed detection in real-world agricultural scenarios.
ShadowRemovalNet: Efficient Real-Time Shadow Removal
Mar 13, 2024Shadows significantly impact computer vision tasks, particularly in outdoor environments. State-of-the-art shadow removal methods are typically too computationally intensive for real-time image processing on edge hardware. We propose ShadowRemovalNet, a novel method designed for real-time image processing on resource-constrained hardware. ShadowRemovalNet achieves significantly higher frame rates compared to existing methods, making it suitable for real-time computer vision pipelines like those used in field robotics. Beyond speed, ShadowRemovalNet offers advantages in efficiency and simplicity, as it does not require a separate shadow mask during inference. ShadowRemovalNet also addresses challenges associated with Generative Adversarial Networks (GANs) for shadow removal, including artefacts, inaccurate mask estimations, and inconsistent supervision between shadow and boundary pixels. To address these limitations, we introduce a novel loss function that substantially reduces shadow removal errors. ShadowRemovalNet's efficiency and straightforwardness make it a robust and effective solution for real-time shadow removal in outdoor robotics and edge computing applications.
Precise Robotic Weed Spot-Spraying for Reduced Herbicide Usage and Improved Environmental Outcomes -- A Real-World Case Study
Jan 25, 2024



Precise robotic weed control plays an essential role in precision agriculture. It can help significantly reduce the environmental impact of herbicides while reducing weed management costs for farmers. In this paper, we demonstrate that a custom-designed robotic spot spraying tool based on computer vision and deep learning can significantly reduce herbicide usage on sugarcane farms. We present results from field trials that compare robotic spot spraying against industry-standard broadcast spraying, by measuring the weed control efficacy, the reduction in herbicide usage, and the water quality improvements in irrigation runoff. The average results across 25 hectares of field trials show that spot spraying on sugarcane farms is 97% as effective as broadcast spraying and reduces herbicide usage by 35%, proportionally to the weed density. For specific trial strips with lower weed pressure, spot spraying reduced herbicide usage by up to 65%. Water quality measurements of irrigation-induced runoff, three to six days after spraying, showed reductions in the mean concentration and mean load of herbicides of 39% and 54%, respectively, compared to broadcast spraying. These promising results reveal the capability of spot spraying technology to reduce herbicide usage on sugarcane farms without impacting weed control and potentially providing sustained water quality benefits.
WeedCLR: Weed Contrastive Learning through Visual Representations with Class-Optimized Loss in Long-Tailed Datasets
Oct 19, 2023



Image classification is a crucial task in modern weed management and crop intervention technologies. However, the limited size, diversity, and balance of existing weed datasets hinder the development of deep learning models for generalizable weed identification. In addition, the expensive labelling requirements of mainstream fully-supervised weed classifiers make them cost- and time-prohibitive to deploy widely, for new weed species, and in site-specific weed management. This paper proposes a novel method for Weed Contrastive Learning through visual Representations (WeedCLR), that uses class-optimized loss with Von Neumann Entropy of deep representation for weed classification in long-tailed datasets. WeedCLR leverages self-supervised learning to learn rich and robust visual features without any labels and applies a class-optimized loss function to address the class imbalance problem in long-tailed datasets. WeedCLR is evaluated on two public weed datasets: CottonWeedID15, containing 15 weed species, and DeepWeeds, containing 8 weed species. WeedCLR achieves an average accuracy improvement of 4.3\% on CottonWeedID15 and 5.6\% on DeepWeeds over previous methods. It also demonstrates better generalization ability and robustness to different environmental conditions than existing methods without the need for expensive and time-consuming human annotations. These significant improvements make WeedCLR an effective tool for weed classification in long-tailed datasets and allows for more rapid and widespread deployment of site-specific weed management and crop intervention technologies.
Prawn Morphometrics and Weight Estimation from Images using Deep Learning for Landmark Localization
Jul 15, 2023



Accurate weight estimation and morphometric analyses are useful in aquaculture for optimizing feeding, predicting harvest yields, identifying desirable traits for selective breeding, grading processes, and monitoring the health status of production animals. However, the collection of phenotypic data through traditional manual approaches at industrial scales and in real-time is time-consuming, labour-intensive, and prone to errors. Digital imaging of individuals and subsequent training of prediction models using Deep Learning (DL) has the potential to rapidly and accurately acquire phenotypic data from aquaculture species. In this study, we applied a novel DL approach to automate weight estimation and morphometric analysis using the black tiger prawn (Penaeus monodon) as a model crustacean. The DL approach comprises two main components: a feature extraction module that efficiently combines low-level and high-level features using the Kronecker product operation; followed by a landmark localization module that then uses these features to predict the coordinates of key morphological points (landmarks) on the prawn body. Once these landmarks were extracted, weight was estimated using a weight regression module based on the extracted landmarks using a fully connected network. For morphometric analyses, we utilized the detected landmarks to derive five important prawn traits. Principal Component Analysis (PCA) was also used to identify landmark-derived distances, which were found to be highly correlated with shape features such as body length, and width. We evaluated our approach on a large dataset of 8164 images of the Black tiger prawn (Penaeus monodon) collected from Australian farms. Our experimental results demonstrate that the novel DL approach outperforms existing DL methods in terms of accuracy, robustness, and efficiency.
Adaptive Uncertainty Distribution in Deep Learning for Unsupervised Underwater Image Enhancement
Dec 18, 2022



One of the main challenges in deep learning-based underwater image enhancement is the limited availability of high-quality training data. Underwater images are difficult to capture and are often of poor quality due to the distortion and loss of colour and contrast in water. This makes it difficult to train supervised deep learning models on large and diverse datasets, which can limit the model's performance. In this paper, we explore an alternative approach to supervised underwater image enhancement. Specifically, we propose a novel unsupervised underwater image enhancement framework that employs a conditional variational autoencoder (cVAE) to train a deep learning model with probabilistic adaptive instance normalization (PAdaIN) and statistically guided multi-colour space stretch that produces realistic underwater images. The resulting framework is composed of a U-Net as a feature extractor and a PAdaIN to encode the uncertainty, which we call UDnet. To improve the visual quality of the images generated by UDnet, we use a statistically guided multi-colour space stretch module that ensures visual consistency with the input image and provides an alternative to training using a ground truth image. The proposed model does not need manual human annotation and can learn with a limited amount of data and achieves state-of-the-art results on underwater images. We evaluated our proposed framework on eight publicly-available datasets. The results show that our proposed framework yields competitive performance compared to other state-of-the-art approaches in quantitative as well as qualitative metrics. Code available at https://github.com/alzayats/UDnet .
A lightweight Transformer-based model for fish landmark detection
Sep 13, 2022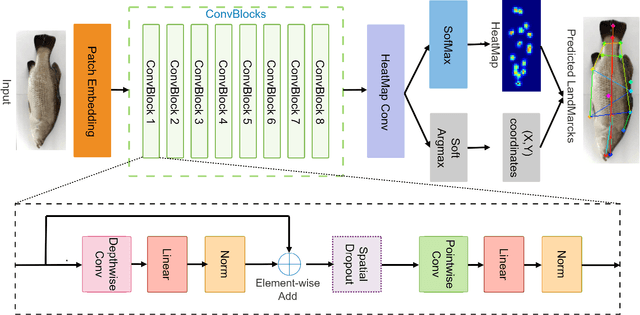
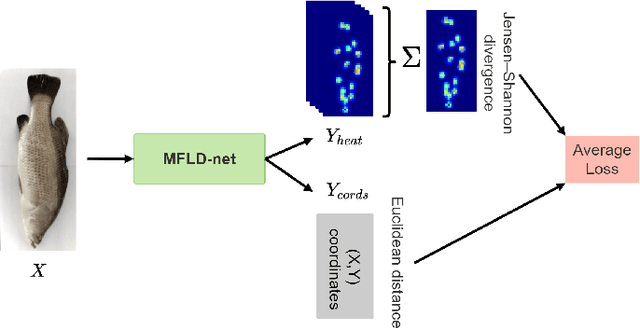


Transformer-based models, such as the Vision Transformer (ViT), can outperform onvolutional Neural Networks (CNNs) in some vision tasks when there is sufficient training data. However, (CNNs) have a strong and useful inductive bias for vision tasks (i.e. translation equivariance and locality). In this work, we developed a novel model architecture that we call a Mobile fish landmark detection network (MFLD-net). We have made this model using convolution operations based on ViT (i.e. Patch embeddings, Multi-Layer Perceptrons). MFLD-net can achieve competitive or better results in low data regimes while being lightweight and therefore suitable for embedded and mobile devices. Furthermore, we show that MFLD-net can achieve keypoint (landmark) estimation accuracies on-par or even better than some of the state-of-the-art (CNNs) on a fish image dataset. Additionally, unlike ViT, MFLD-net does not need a pre-trained model and can generalise well when trained on a small dataset. We provide quantitative and qualitative results that demonstrate the model's generalisation capabilities. This work will provide a foundation for future efforts in developing mobile, but efficient fish monitoring systems and devices.