 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-quality Low-dose CT Reconstruction Using Convolutional Neural Networks with Spatial and Channel Squeeze and Excitation
Apr 01, 2021
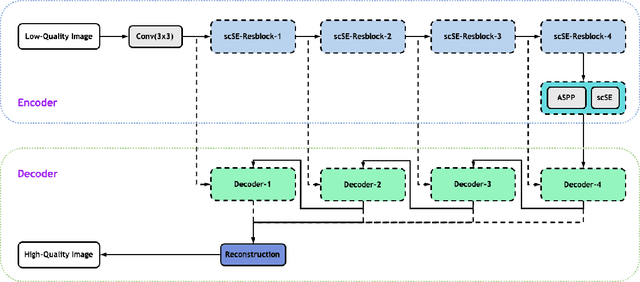
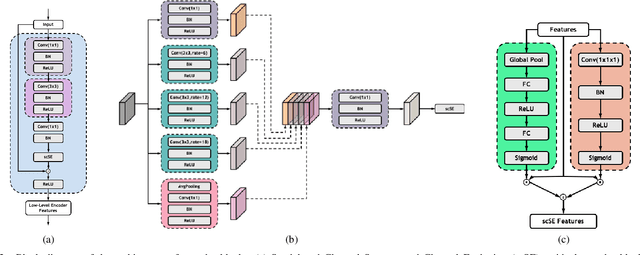
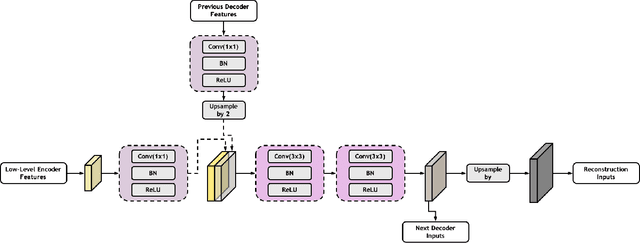
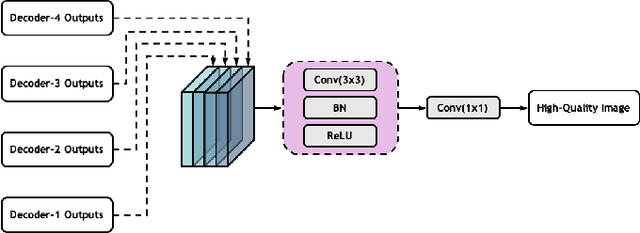
Low-dose computed tomography (CT) allows the reduction of radiation risk in clinical applications at the expense of image quality, which deteriorates the diagnosis accuracy of radiologists. In this work, we present a High-Quality Imaging network (HQINet) for the CT image reconstruction from Low-dose computed tomography (CT) acquisitions. HQINet was a convolutional encoder-decoder architecture, where the encoder was used to extract spatial and temporal information from three contiguous slices while the decoder was used to recover the spacial information of the middle slice. We provide experimental results on the real projection data from low-dose CT Image and Projection Data (LDCT-and-Projection-data), demonstrating that the proposed approach yielded a notable improvement of the performance in terms of image quality, with a rise of 5.5dB in terms of peak signal-to-noise ratio (PSNR) and 0.29 in terms of mutual information (MI).
Co-VeGAN: Complex-Valued Generative Adversarial Network for Compressive Sensing MR Image Reconstruction
Feb 24, 2020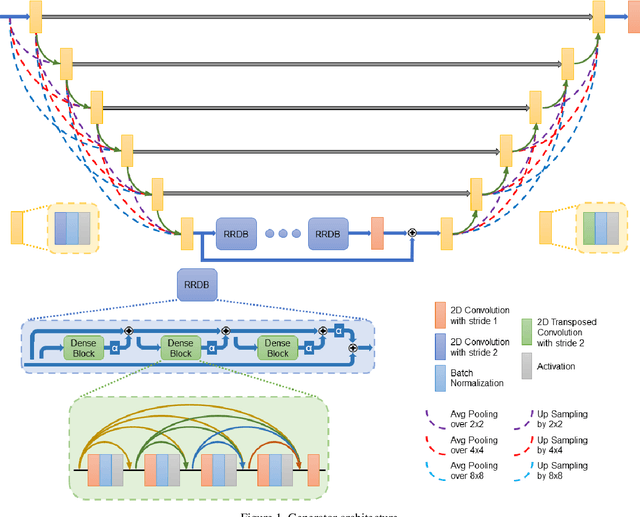
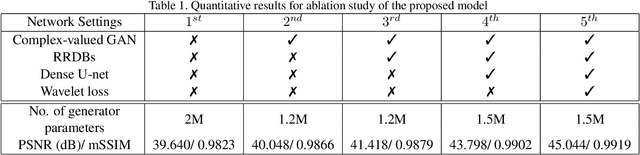
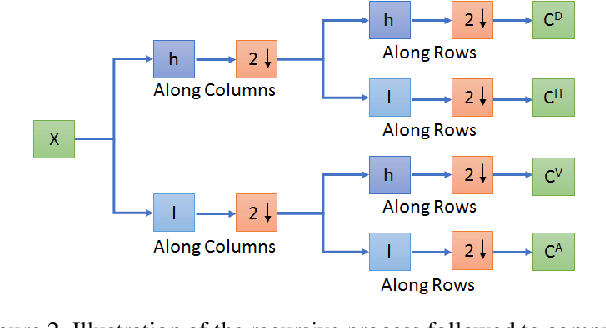
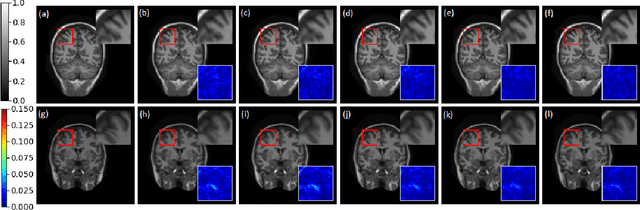
Compressive sensing (CS) is widely used to reduce the image acquisition time of magnetic resonance imaging (MRI). Though CS based undersampling has numerous benefits, like high quality images with less motion artefacts, low storage requirement, etc., the reconstruction of the image from the CS-undersampled data is an ill-posed inverse problem which requires extensive computation and resources. In this paper, we propose a novel deep network that can process complex-valued input to perform high-quality reconstruction. Our model is based on generative adversarial network (GAN) that uses residual-in-residual dense blocks in a modified U-net generator with patch based discriminator. We introduce a wavelet based loss in the complex GAN model for better reconstruction quality. Extensive analyses on different datasets demonstrate that the proposed model significantly outperforms the existing CS reconstruction techniques in terms of peak signal-to-noise ratio and structural similarity index.
Large-Scale Unsupervised Object Discovery
Jun 12, 2021
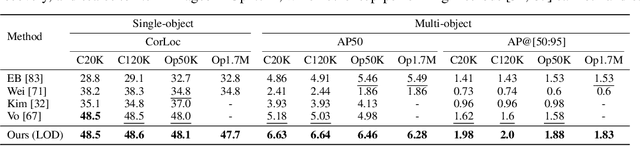
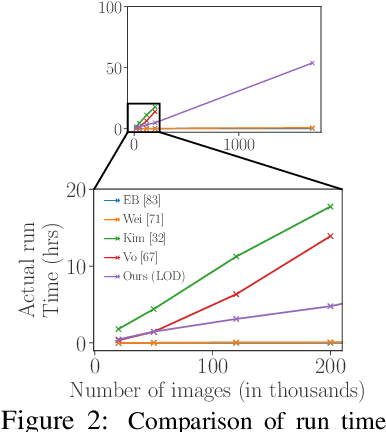
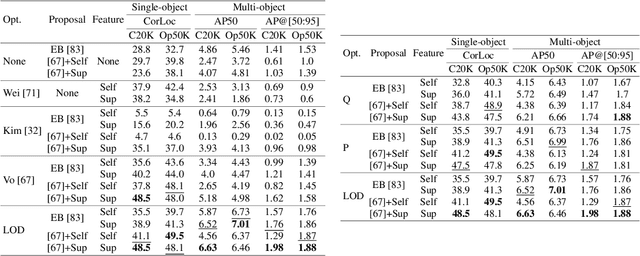
Existing approaches to unsupervised object discovery (UOD) do not scale up to large datasets without approximations which compromise their performance. We propose a novel formulation of UOD as a ranking problem, amenable to the arsenal of distributed methods available for eigenvalue problems and link analysis. Extensive experiments with COCO and OpenImages demonstrate that, in the single-object discovery setting where a single prominent object is sought in each image, the proposed LOD (Large-scale Object Discovery) approach is on par with, or better than the state of the art for medium-scale datasets (up to 120K images), and over 37% better than the only other algorithms capable of scaling up to 1.7M images. In the multi-object discovery setting where multiple objects are sought in each image, the proposed LOD is over 14% better in average precision (AP) than all other methods for datasets ranging from 20K to 1.7M images.
Learning and Exploiting Interclass Visual Correlations for Medical Image Classification
Jul 13, 2020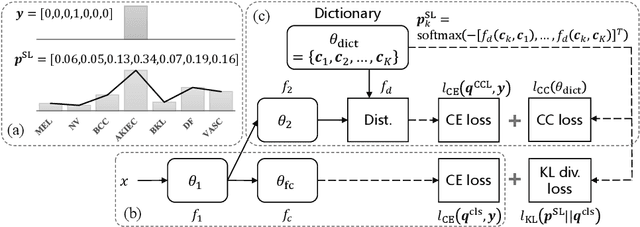
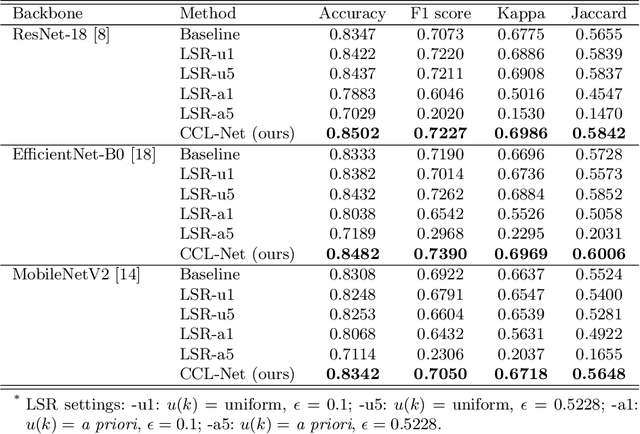

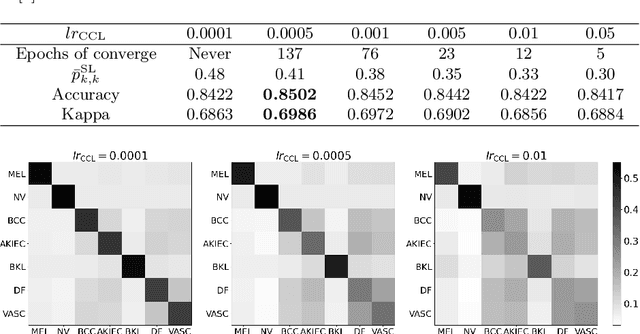
Deep neural network-based medical image classifications often use "hard" labels for training, where the probability of the correct category is 1 and those of others are 0. However, these hard targets can drive the networks over-confident about their predictions and prone to overfit the training data, affecting model generalization and adaption. Studies have shown that label smoothing and softening can improve classification performance. Nevertheless, existing approaches are either non-data-driven or limited in applicability. In this paper, we present the Class-Correlation Learning Network (CCL-Net) to learn interclass visual correlations from given training data, and produce soft labels to help with classification tasks. Instead of letting the network directly learn the desired correlations, we propose to learn them implicitly via distance metric learning of class-specific embeddings with a lightweight plugin CCL block. An intuitive loss based on a geometrical explanation of correlation is designed for bolstering learning of the interclass correlations. We further present end-to-end training of the proposed CCL block as a plugin head together with the classification backbone while generating soft labels on the fly. Our experimental results on the International Skin Imaging Collaboration 2018 dataset demonstrate effective learning of the interclass correlations from training data, as well as consistent improvements in performance upon several widely used modern network structures with the CCL block.
Unpaired Image Captioning by Language Pivoting
Jul 18, 2018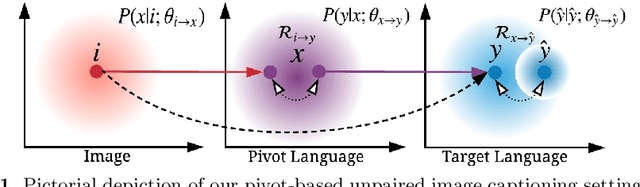
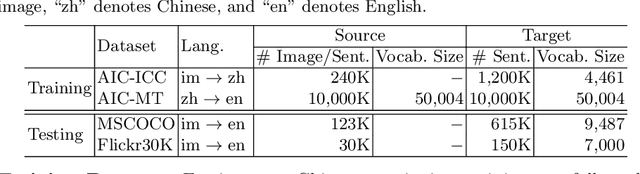
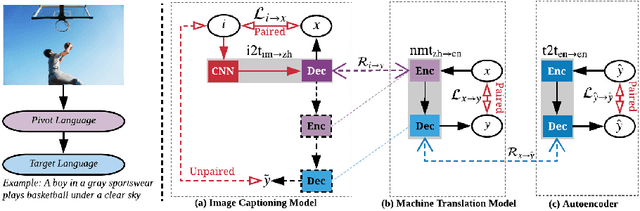

Image captioning is a multimodal task involving computer vision and natural language processing, where the goal is to learn a mapping from the image to its natural language description. In general, the mapping function is learned from a training set of image-caption pairs. However, for some language, large scale image-caption paired corpus might not be available. We present an approach to this unpaired image captioning problem by language pivoting. Our method can effectively capture the characteristics of an image captioner from the pivot language (Chinese) and align it to the target language (English) using another pivot-target (Chinese-English) sentence parallel corpus. We evaluate our method on two image-to-English benchmark datasets: MSCOCO and Flickr30K. Quantitative comparisons against several baseline approaches demonstrate the effectiveness of our method.
A multi-stage GAN for multi-organ chest X-ray image generation and segmentation
Jun 09, 2021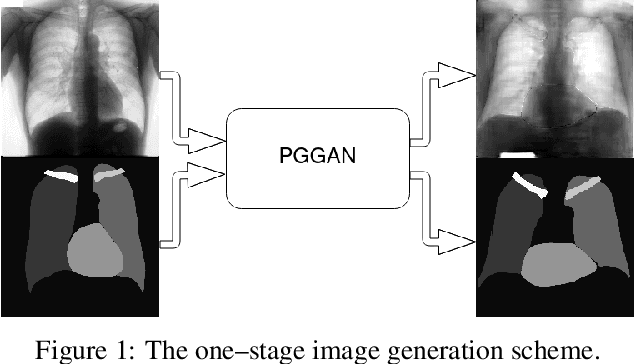
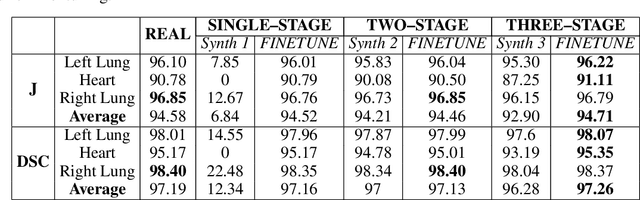
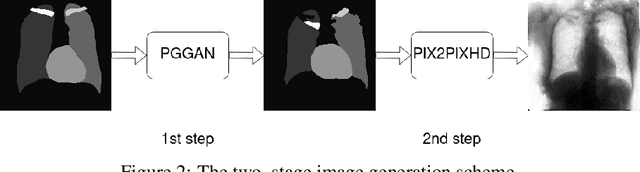
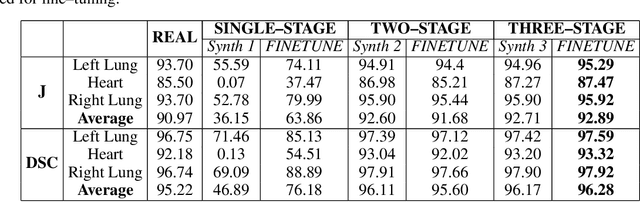
Multi-organ segmentation of X-ray images is of fundamental importance for computer aided diagnosis systems. However, the most advanced semantic segmentation methods rely on deep learning and require a huge amount of labeled images, which are rarely available due to both the high cost of human resources and the time required for labeling. In this paper, we present a novel multi-stage generation algorithm based on Generative Adversarial Networks (GANs) that can produce synthetic images along with their semantic labels and can be used for data augmentation. The main feature of the method is that, unlike other approaches, generation occurs in several stages, which simplifies the procedure and allows it to be used on very small datasets. The method has been evaluated on the segmentation of chest radiographic images, showing promising results. The multistage approach achieves state-of-the-art and, when very few images are used to train the GANs, outperforms the corresponding single-stage approach.
AD-GAN: End-to-end Unsupervised Nuclei Segmentation with Aligned Disentangling Training
Jul 23, 2021
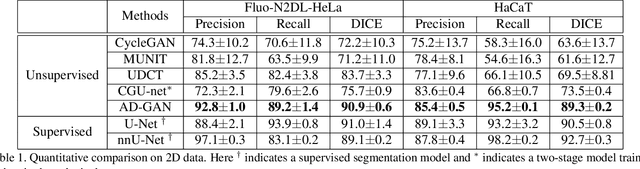
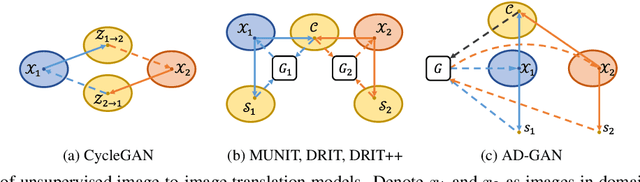
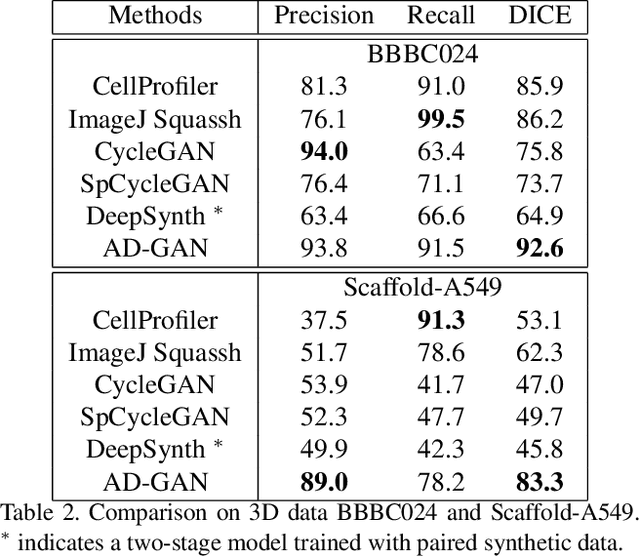
We consider unsupervised cell nuclei segmentation in this paper. Exploiting the recently-proposed unpaired image-to-image translation between cell nuclei images and randomly synthetic masks, existing approaches, e.g., CycleGAN, have achieved encouraging results. However, these methods usually take a two-stage pipeline and fail to learn end-to-end in cell nuclei images. More seriously, they could lead to the lossy transformation problem, i.e., the content inconsistency between the original images and the corresponding segmentation output. To address these limitations, we propose a novel end-to-end unsupervised framework called Aligned Disentangling Generative Adversarial Network (AD-GAN). Distinctively, AD-GAN introduces representation disentanglement to separate content representation (the underling spatial structure) from style representation (the rendering of the structure). With this framework, spatial structure can be preserved explicitly, enabling a significant reduction of macro-level lossy transformation. We also propose a novel training algorithm able to align the disentangled content in the latent space to reduce micro-level lossy transformation. Evaluations on real-world 2D and 3D datasets show that AD-GAN substantially outperforms the other comparison methods and the professional software both quantitatively and qualitatively. Specifically, the proposed AD-GAN leads to significant improvement over the current best unsupervised methods by an average 17.8% relatively (w.r.t. the metric DICE) on four cell nuclei datasets. As an unsupervised method, AD-GAN even performs competitive with the best supervised models, taking a further leap towards end-to-end unsupervised nuclei segmentation.
Gleason Score Prediction using Deep Learning in Tissue Microarray Image
May 11, 2020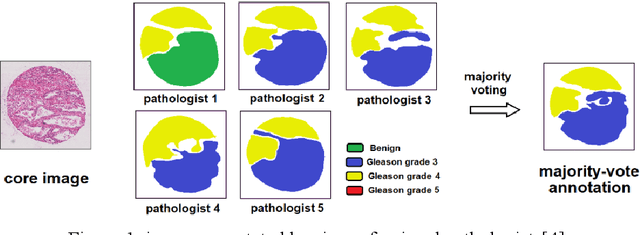
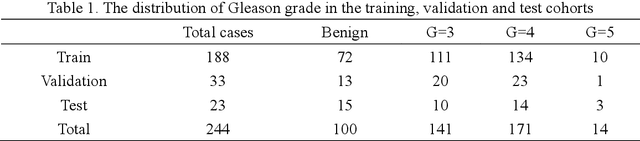
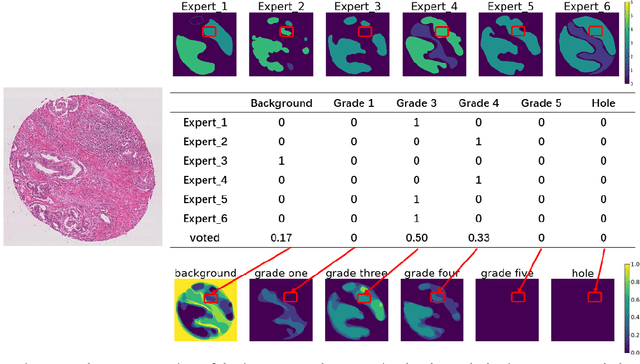
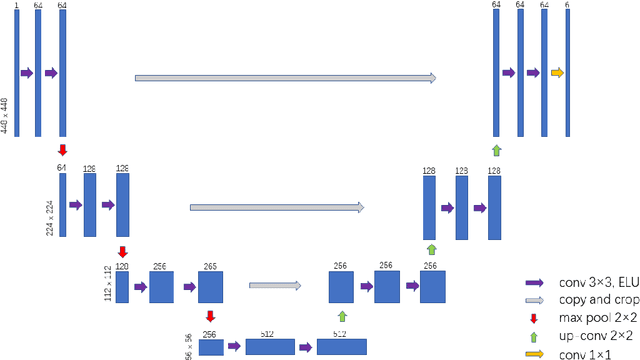
Prostate cancer (PCa) is one of the most common cancers in men around the world. The most accurate method to evaluate lesion levels of PCa is microscopic inspection of stained biopsy tissue and estimate the Gleason score of tissue microarray (TMA) image by expert pathologists. However, it is time-consuming for pathologists to identify the cellular and glandular patterns for Gleason grading in large TMA images. We used Gleason2019 Challenge dataset to build a convolutional neural network (CNN) model to segment TMA images to regions of different Gleason grades and predict the Gleason score according to the grading segmentation. We used a pre-trained model of prostate segmentation to increase the accuracy of the Gleason grade segmentation. The model achieved a mean Dice of 75.6% on the test cohort and ranked 4th in the Gleason2019 Challenge with a score of 0.778 combined of Cohen's kappa and the f1-score.
Selfie: Self-supervised Pretraining for Image Embedding
Jul 23, 2019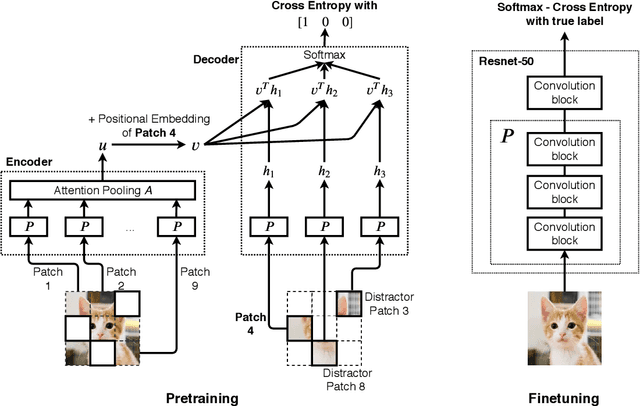
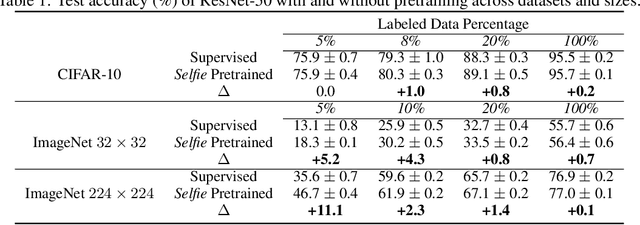

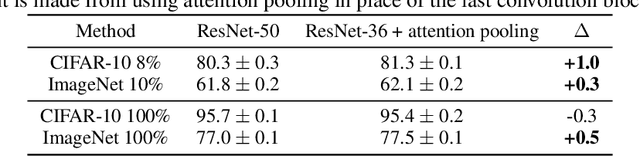
We introduce a pretraining technique called Selfie, which stands for SELFie supervised Image Embedding. Selfie generalizes the concept of masked language modeling of BERT (Devlin et al., 2019) to continuous data, such as images, by making use of the Contrastive Predictive Coding loss (Oord et al., 2018). Given masked-out patches in an input image, our method learns to select the correct patch, among other "distractor" patches sampled from the same image, to fill in the masked location. This classification objective sidesteps the need for predicting exact pixel values of the target patches. The pretraining architecture of Selfie includes a network of convolutional blocks to process patches followed by an attention pooling network to summarize the content of unmasked patches before predicting masked ones. During finetuning, we reuse the convolutional weights found by pretraining. We evaluate Selfie on three benchmarks (CIFAR-10, ImageNet 32 x 32, and ImageNet 224 x 224) with varying amounts of labeled data, from 5% to 100% of the training sets. Our pretraining method provides consistent improvements to ResNet-50 across all settings compared to the standard supervised training of the same network. Notably, on ImageNet 224 x 224 with 60 examples per class (5%), our method improves the mean accuracy of ResNet-50 from 35.6% to 46.7%, an improvement of 11.1 points in absolute accuracy. Our pretraining method also improves ResNet-50 training stability, especially on low data regime, by significantly lowering the standard deviation of test accuracies across different runs.
Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
Jun 02, 2021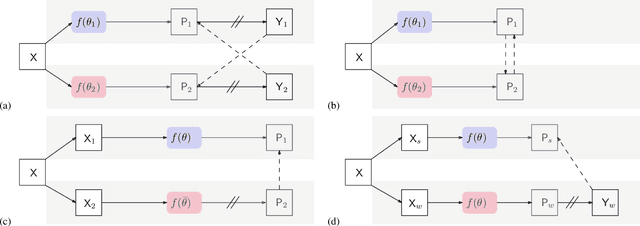
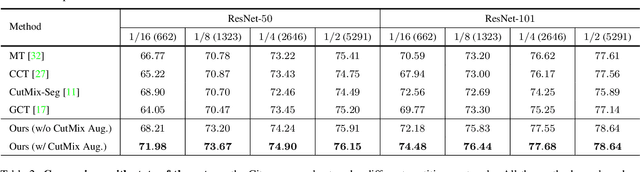
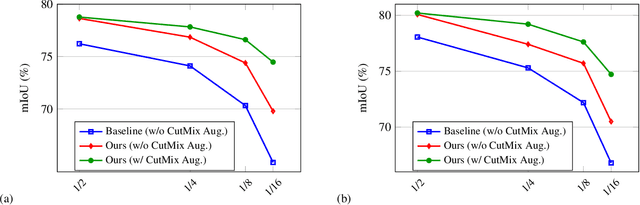
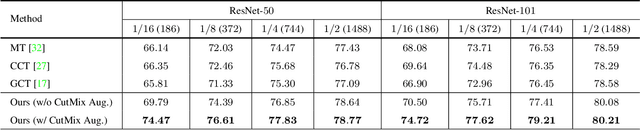
In this paper, we study the semi-supervised semantic segmentation problem via exploring both labeled data and extra unlabeled data. We propose a novel consistency regularization approach, called cross pseudo supervision (CPS). Our approach imposes the consistency on two segmentation networks perturbed with different initialization for the same input image. The pseudo one-hot label map, output from one perturbed segmentation network, is used to supervise the other segmentation network with the standard cross-entropy loss, and vice versa. The CPS consistency has two roles: encourage high similarity between the predictions of two perturbed networks for the same input image, and expand training data by using the unlabeled data with pseudo labels. Experiment results show that our approach achieves the state-of-the-art semi-supervised segmentation performance on Cityscapes and PASCAL VOC 2012.