 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Fingerprints: Disentangled Attribution of LLM-Generated Code
Mar 04, 2026The rapid adoption of Large Language Models (LLMs) has transformed modern software development by enabling automated code generation at scale. While these systems improve productivity, they introduce new challenges for software governance, accountability, and compliance. Existing research primarily focuses on distinguishing machine-generated code from human-written code; however, many practical scenarios--such as vulnerability triage, incident investigation, and licensing audits--require identifying which LLM produced a given code snippet. In this paper, we study the problem of model-level code attribution, which aims to determine the source LLM responsible for generated code. Although attribution is challenging, differences in training data, architectures, alignment strategies, and decoding mechanisms introduce model-dependent stylistic and structural variations that serve as generative fingerprints. Leveraging this observation, we propose the Disentangled Code Attribution Network (DCAN), which separates Source-Agnostic semantic information from Source-Specific stylistic representations. Through a contrastive learning objective, DCAN isolates discriminative model-dependent signals while preserving task semantics, enabling multi-class attribution across models and programming languages. To support systematic evaluation, we construct the first large-scale benchmark dataset comprising code generated by four widely used LLMs (DeepSeek, Claude, Qwen, and ChatGPT) across four programming languages (Python, Java, C, and Go). Experimental results demonstrate that DCAN achieves reliable attribution performance across diverse settings, highlighting the feasibility of model-level provenance analysis in software engineering contexts. The dataset and implementation are publicly available at https://github.com/mtt500/DCAN.
Ultrafast Cardiac Imaging Using Deep Learning For Speckle-Tracking Echocardiography
Jun 25, 2023



High-quality ultrafast ultrasound imaging is based on coherent compounding from multiple transmissions of plane waves (PW) or diverging waves (DW). However, compounding results in reduced frame rate, as well as destructive interferences from high-velocity tissue motion if motion compensation (MoCo) is not considered. While many studies have recently shown the interest of deep learning for the reconstruction of high-quality static images from PW or DW, its ability to achieve such performance while maintaining the capability of tracking cardiac motion has yet to be assessed. In this paper, we addressed such issue by deploying a complex-weighted convolutional neural network (CNN) for image reconstruction and a state-of-the-art speckle tracking method. The evaluation of this approach was first performed by designing an adapted simulation framework, which provides specific reference data, i.e. high quality, motion artifact-free cardiac images. The obtained results showed that, while using only three DWs as input, the CNN-based approach yielded an image quality and a motion accuracy equivalent to those obtained by compounding 31 DWs free of motion artifacts. The performance was then further evaluated on non-simulated, experimental in vitro data, using a spinning disk phantom. This experiment demonstrated that our approach yielded high-quality image reconstruction and motion estimation, under a large range of velocities and outperforms a state-of-the-art MoCo-based approach at high velocities. Our method was finally assessed on in vivo datasets and showed consistent improvement in image quality and motion estimation compared to standard compounding. This demonstrates the feasibility and effectiveness of deep learning reconstruction for ultrafast speckle-tracking echocardiography.
High-quality Low-dose CT Reconstruction Using Convolutional Neural Networks with Spatial and Channel Squeeze and Excitation
Apr 01, 2021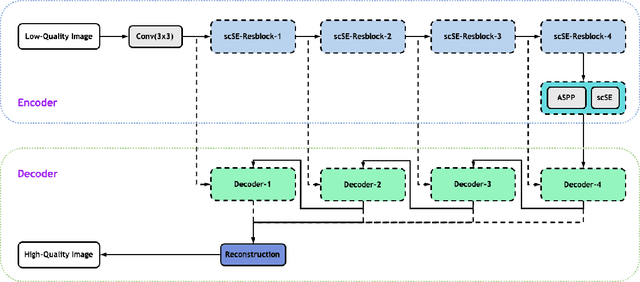
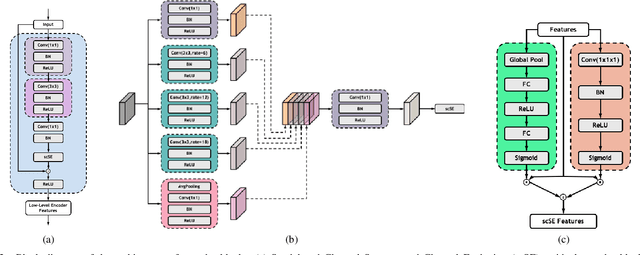
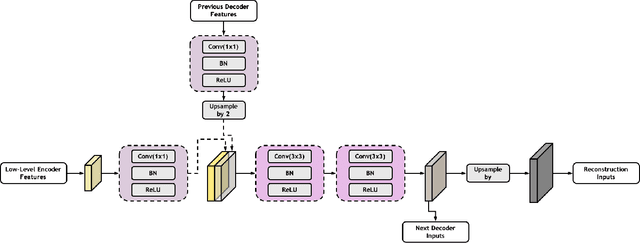
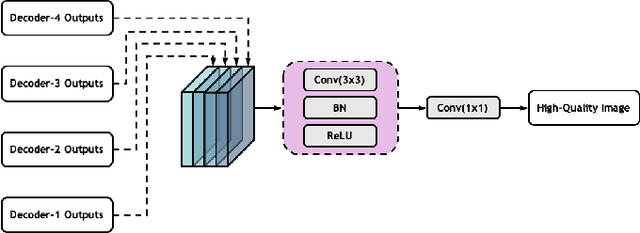
Low-dose computed tomography (CT) allows the reduction of radiation risk in clinical applications at the expense of image quality, which deteriorates the diagnosis accuracy of radiologists. In this work, we present a High-Quality Imaging network (HQINet) for the CT image reconstruction from Low-dose computed tomography (CT) acquisitions. HQINet was a convolutional encoder-decoder architecture, where the encoder was used to extract spatial and temporal information from three contiguous slices while the decoder was used to recover the spacial information of the middle slice. We provide experimental results on the real projection data from low-dose CT Image and Projection Data (LDCT-and-Projection-data), demonstrating that the proposed approach yielded a notable improvement of the performance in terms of image quality, with a rise of 5.5dB in terms of peak signal-to-noise ratio (PSNR) and 0.29 in terms of mutual information (MI).