 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Synergic Adversarial Label Learning with DR and AMD for Retinal Image Grading
Mar 24, 2020
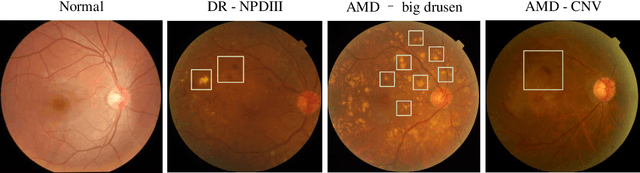
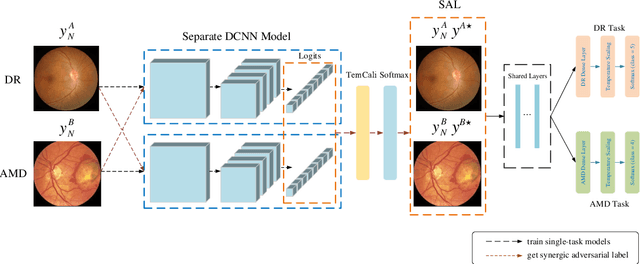
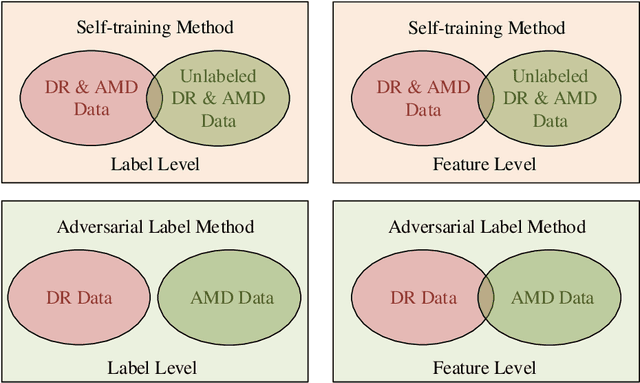
The need for comprehensive and automated screening methods for retinal image classification has long been recognized. Well-qualified doctors annotated images are very expensive and only a limited amount of data is available for various retinal diseases such as age-related macular degeneration (AMD) and diabetic retinopathy (DR). Some studies show that AMD and DR share some common features like hemorrhagic points and exudation but most classification algorithms only train those disease models independently. Inspired by knowledge distillation where additional monitoring signals from various sources is beneficial to train a robust model with much fewer data. We propose a method called synergic adversarial label learning (SALL) which leverages relevant retinal disease labels in both semantic and feature space as additional signals and train the model in a collaborative manner. Our experiments on DR and AMD fundus image classification task demonstrate that the proposed method can significantly improve the accuracy of the model for grading diseases. In addition, we conduct additional experiments to show the effectiveness of SALL from the aspects of reliability and interpretability in the context of medical imaging application.
Improving Pneumonia Localization via Cross-Attention on Medical Images and Reports
Oct 06, 2021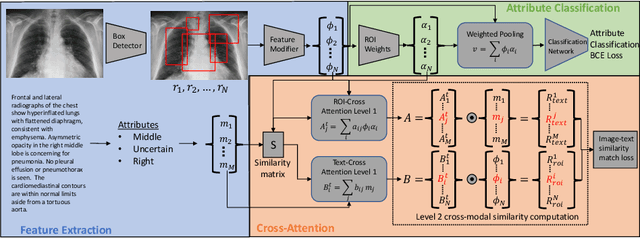
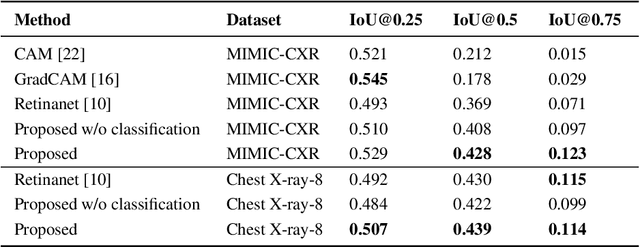
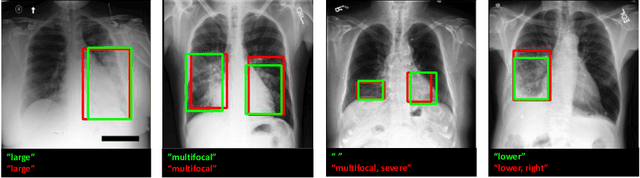

Localization and characterization of diseases like pneumonia are primary steps in a clinical pipeline, facilitating detailed clinical diagnosis and subsequent treatment planning. Additionally, such location annotated datasets can provide a pathway for deep learning models to be used for downstream tasks. However, acquiring quality annotations is expensive on human resources and usually requires domain expertise. On the other hand, medical reports contain a plethora of information both about pneumonia characteristics and its location. In this paper, we propose a novel weakly-supervised attention-driven deep learning model that leverages encoded information in medical reports during training to facilitate better localization. Our model also performs classification of attributes that are associated to pneumonia and extracted from medical reports for supervision. Both the classification and localization are trained in conjunction and once trained, the model can be utilized for both the localization and characterization of pneumonia using only the input image. In this paper, we explore and analyze the model using chest X-ray datasets and demonstrate qualitatively and quantitatively that the introduction of textual information improves pneumonia localization. We showcase quantitative results on two datasets, MIMIC-CXR and Chest X-ray-8, and we also showcase severity characterization on the COVID-19 dataset.
Autonomy 2.0: Why is self-driving always 5 years away?
Jul 16, 2021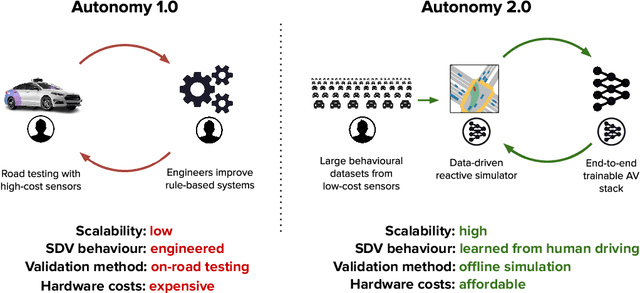

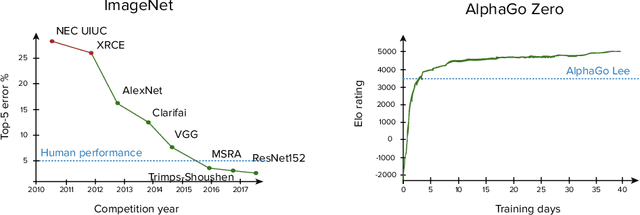
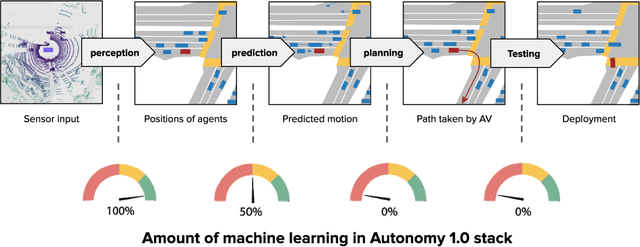
Despite the numerous successes of machine learning over the past decade (image recognition, decision-making, NLP, image synthesis), self-driving technology has not yet followed the same trend. In this paper, we study the history, composition, and development bottlenecks of the modern self-driving stack. We argue that the slow progress is caused by approaches that require too much hand-engineering, an over-reliance on road testing, and high fleet deployment costs. We observe that the classical stack has several bottlenecks that preclude the necessary scale needed to capture the long tail of rare events. To resolve these problems, we outline the principles of Autonomy 2.0, an ML-first approach to self-driving, as a viable alternative to the currently adopted state-of-the-art. This approach is based on (i) a fully differentiable AV stack trainable from human demonstrations, (ii) closed-loop data-driven reactive simulation, and (iii) large-scale, low-cost data collections as critical solutions towards scalability issues. We outline the general architecture, survey promising works in this direction and propose key challenges to be addressed by the community in the future.
An investigation of pre-upsampling generative modelling and Generative Adversarial Networks in audio super resolution
Sep 30, 2021
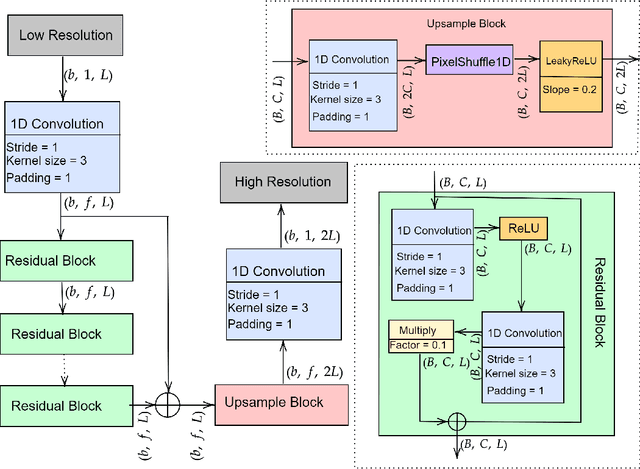
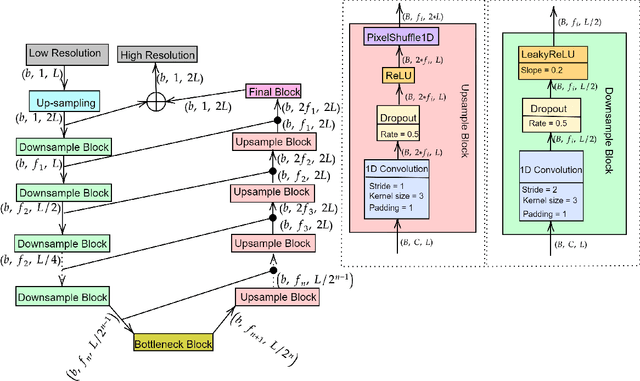
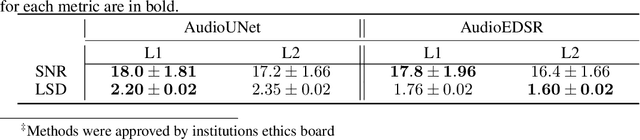
There have been several successful deep learning models that perform audio super-resolution. Many of these approaches involve using preprocessed feature extraction which requires a lot of domain-specific signal processing knowledge to implement. Convolutional Neural Networks (CNNs) improved upon this framework by automatically learning filters. An example of a convolutional approach is AudioUNet, which takes inspiration from novel methods of upsampling images. Our paper compares the pre-upsampling AudioUNet to a new generative model that upsamples the signal before using deep learning to transform it into a more believable signal. Based on the EDSR network for image super-resolution, the newly proposed model outperforms UNet with a 20% increase in log spectral distance and a mean opinion score of 4.06 compared to 3.82 for the two times upsampling case. AudioEDSR also has 87% fewer parameters than AudioUNet. How incorporating AudioUNet into a Wasserstein GAN (with gradient penalty) (WGAN-GP) structure can affect training is also explored. Finally the effects artifacting has on the current state of the art is analysed and solutions to this problem are proposed. The methods used in this paper have broad applications to telephony, audio recognition and audio generation tasks.
Time Series to Images: Monitoring the Condition of Industrial Assets with Deep Learning Image Processing Algorithms
May 14, 2020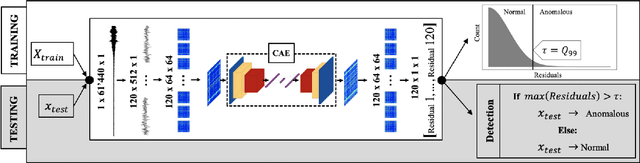
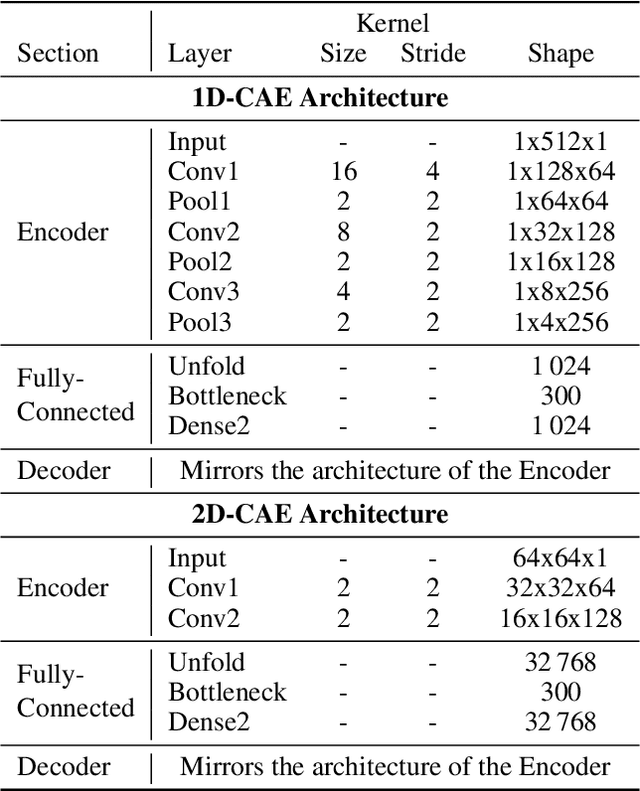
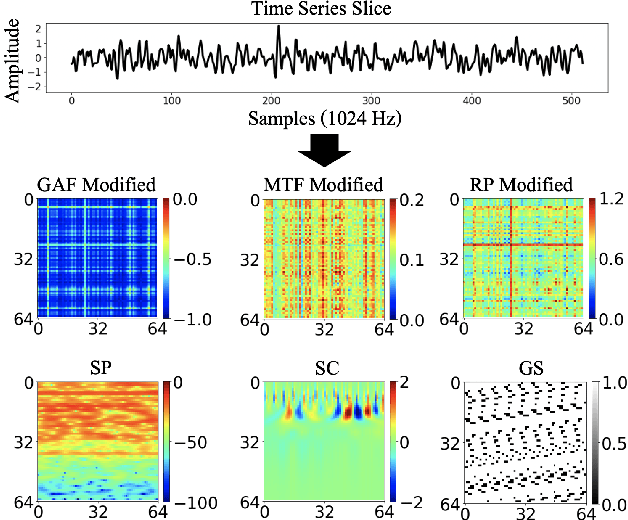
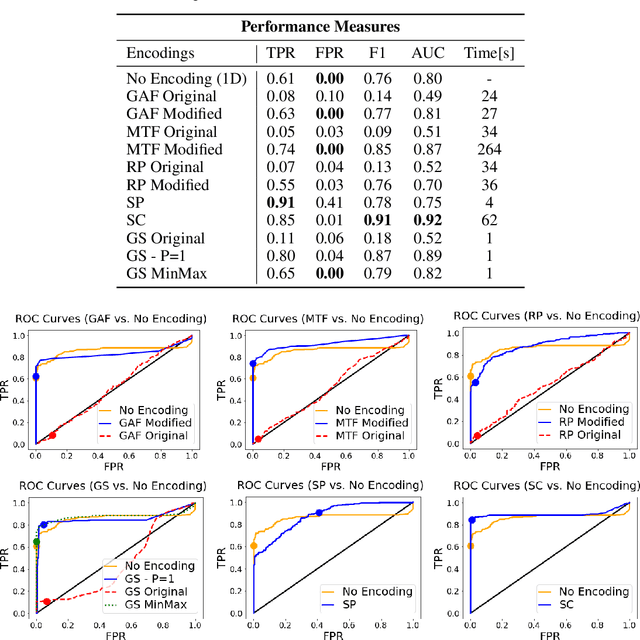
The ability to detect anomalies in time series is considered as highly valuable within plenty of application domains. The sequential nature of time series objects is responsible for an additional feature complexity, ultimately requiring specialized approaches for solving the task. Essential characteristics of time series, laying outside the time domain, are often difficult to capture with state-of-the-art anomaly detection methods, when no transformations on the time series have been applied. Inspired by the success of deep learning methods in computer vision, several studies have proposed to transform time-series into image-like representations, leading to very promising results. However, most of the previous studies implementing time-series to image encodings have focused on the supervised classification. The application to unsupervised anomaly detection tasks has been limited. The paper has the following contributions: First, we evaluate the application of six time-series to image encodings to DL algorithms: Gramian Angular Field, Markov Transition Field, Recurrence Plot, Grey Scale Encoding, Spectrogram and Scalogram. Second, we propose modifications of the original encoding definitions, to make them more robust to the variability in large datasets. And third, we provide a comprehensive comparison between using the raw time series directly and the different encodings, with and without the proposed improvements. The comparison is performed on a dataset collected and released by Airbus, containing highly complex vibration measurements from real helicopters flight tests. The different encodings provide competitive results for anomaly detection.
MLAN: Multi-Level Adversarial Network for Domain Adaptive Semantic Segmentation
Mar 24, 2021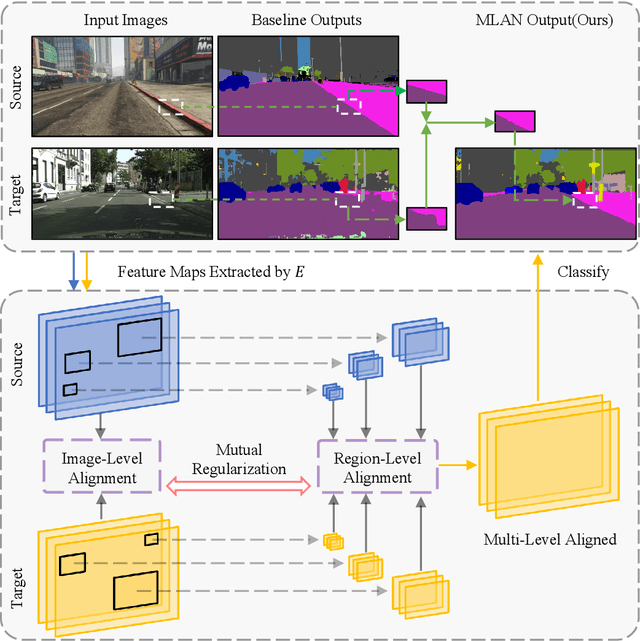

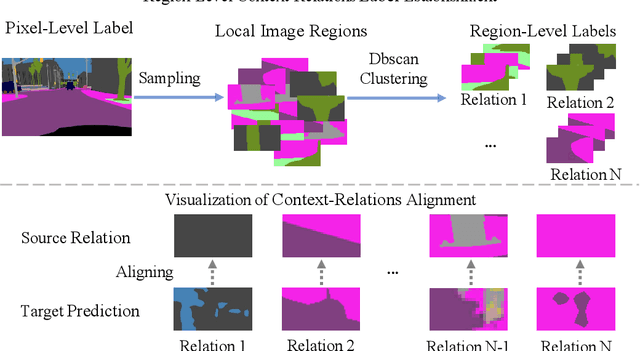

Recent progresses in domain adaptive semantic segmentation demonstrate the effectiveness of adversarial learning (AL) in unsupervised domain adaptation. However, most adversarial learning based methods align source and target distributions at a global image level but neglect the inconsistency around local image regions. This paper presents a novel multi-level adversarial network (MLAN) that aims to address inter-domain inconsistency at both global image level and local region level optimally. MLAN has two novel designs, namely, region-level adversarial learning (RL-AL) and co-regularized adversarial learning (CR-AL). Specifically, RL-AL models prototypical regional context-relations explicitly in the feature space of a labelled source domain and transfers them to an unlabelled target domain via adversarial learning. CR-AL fuses region-level AL and image-level AL optimally via mutual regularization. In addition, we design a multi-level consistency map that can guide domain adaptation in both input space ($i.e.$, image-to-image translation) and output space ($i.e.$, self-training) effectively. Extensive experiments show that MLAN outperforms the state-of-the-art with a large margin consistently across multiple datasets.
The Rich Get Richer: Disparate Impact of Semi-Supervised Learning
Oct 12, 2021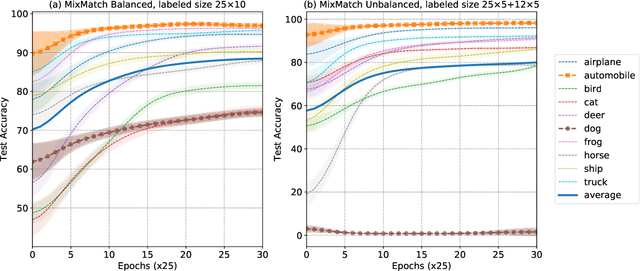

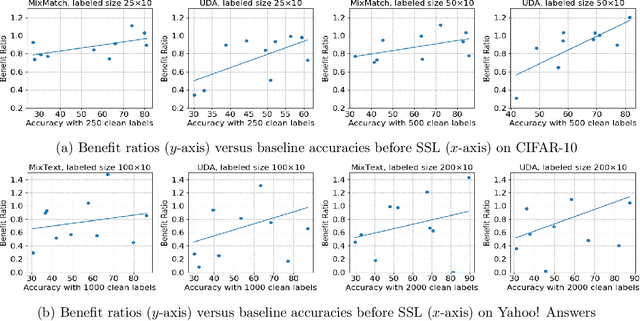

Semi-supervised learning (SSL) has demonstrated its potential to improve the model accuracy for a variety of learning tasks when the high-quality supervised data is severely limited. Although it is often established that the average accuracy for the entire population of data is improved, it is unclear how SSL fares with different sub-populations. Understanding the above question has substantial fairness implications when these different sub-populations are defined by the demographic groups we aim to treat fairly. In this paper, we reveal the disparate impacts of deploying SSL: the sub-population who has a higher baseline accuracy without using SSL (the ``rich" sub-population) tends to benefit more from SSL; while the sub-population who suffers from a low baseline accuracy (the ``poor" sub-population) might even observe a performance drop after adding the SSL module. We theoretically and empirically establish the above observation for a broad family of SSL algorithms, which either explicitly or implicitly use an auxiliary ``pseudo-label". Our experiments on a set of image and text classification tasks confirm our claims. We discuss how this disparate impact can be mitigated and hope that our paper will alarm the potential pitfall of using SSL and encourage a multifaceted evaluation of future SSL algorithms. Code is available at github.com/UCSC-REAL/Disparate-SSL.
TELET: A Monotonic Algorithm to Design Large Dimensional Equiangular Tight Frames for Applications in Compressed Sensing
Oct 23, 2021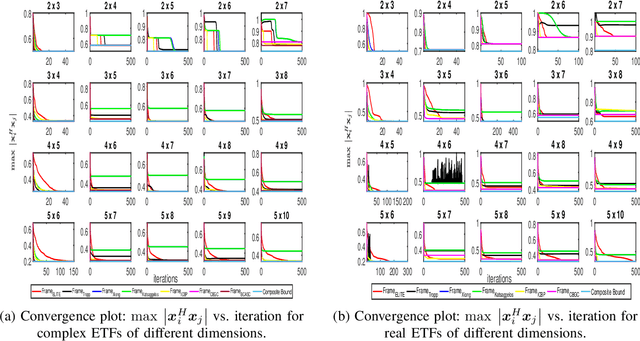
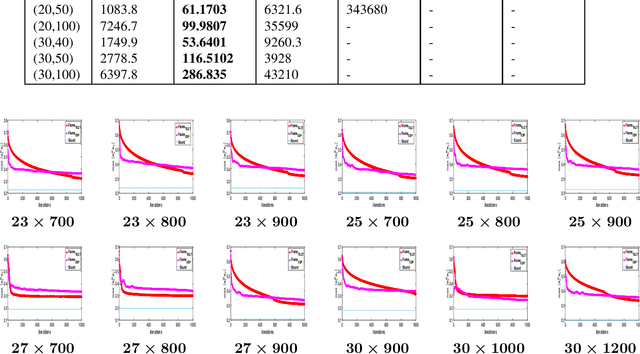
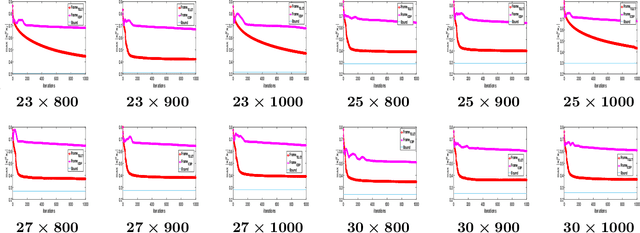
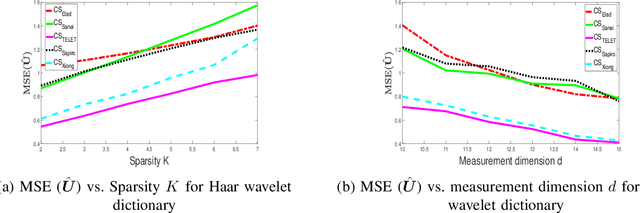
An Equiangular tight frame (ETF) - also known as the Welch-bound-equality sequences - consists of a sequence of unit norm vectors whose absolute inner product is identical and minimal. Due to this unique property, these frames are preferred in different applications such as in constructing sensing matrices for compressed sensing systems, robust transmission, and quantum computing. Construction of ETFs involves solving a challenging non-convex minimax optimization problem, and only a few methods were successful in constructing them, albeit only for smaller dimensions. In this paper, we propose an iterative algorithm named TEchnique to devise Large dimensional Equiangular Tight-frames (TELET-frames) based on the majorization minimization (MM) procedure - in which we design and minimize a tight upper bound for the ETF cost function at every iteration. Since TELET is designed using the MM approach, it inherits useful properties of MM such as monotonicity and guaranteed convergence to a stationary point. Subsequently, we use the derived frames to construct optimized sensing matrix for compressed sensing systems. In the numerical simulations, we show that the proposed algorithm can generate complex and real frames (in the order of hundreds) with very low mutual coherence value when compared to the state-of-the-art algorithm, with a slight increase in computational cost. Experiments using synthetic data and real images reveal that the optimized sensing matrix obtained through the frames constructed by TELET performs better, in terms of image reconstruction accuracy, than the sensing matrix constructed using state-of-the-art methods.
Towards Deterministic Diverse Subset Sampling
May 28, 2021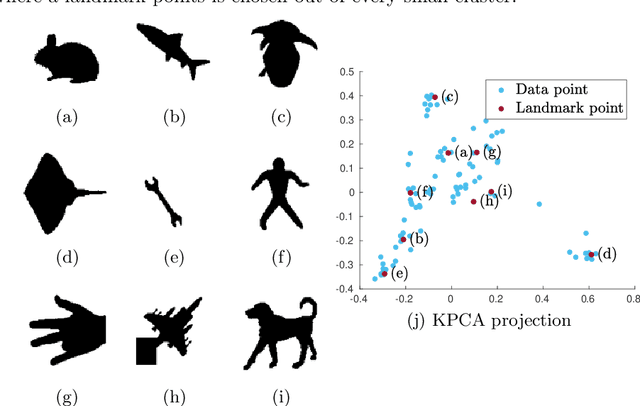
Determinantal point processes (DPPs) are well known models for diverse subset selection problems, including recommendation tasks, document summarization and image search. In this paper, we discuss a greedy deterministic adaptation of k-DPP. Deterministic algorithms are interesting for many applications, as they provide interpretability to the user by having no failure probability and always returning the same results. First, the ability of the method to yield low-rank approximations of kernel matrices is evaluated by comparing the accuracy of the Nystr\"om approximation on multiple datasets. Afterwards, we demonstrate the usefulness of the model on an image search task.
TRACE: Transform Aggregate and Compose Visiolinguistic Representations for Image Search with Text Feedback
Sep 03, 2020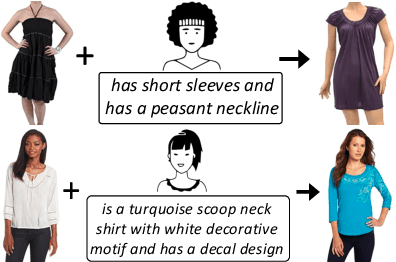
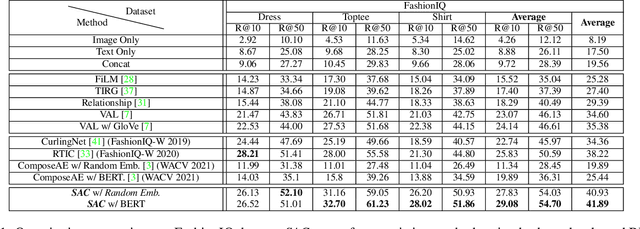
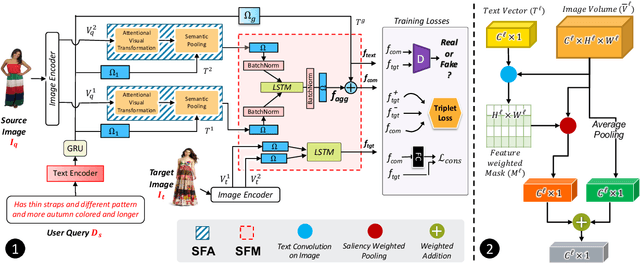
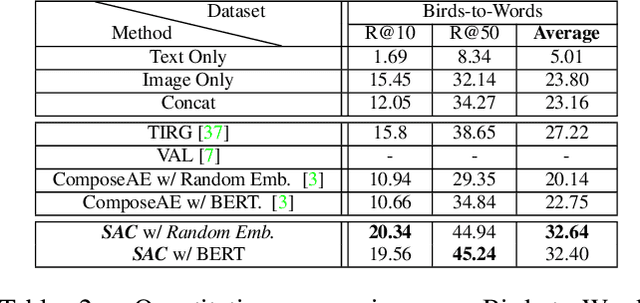
The ability to efficiently search for images over an indexed database is the cornerstone for several user experiences. Incorporating user feedback, through multi-modal inputs provide flexible and interaction to serve fine-grained specificity in requirements. We specifically focus on text feedback, through descriptive natural language queries. Given a reference image and textual user feedback, our goal is to retrieve images that satisfy constraints specified by both of these input modalities. The task is challenging as it requires understanding the textual semantics from the text feedback and then applying these changes to the visual representation. To address these challenges, we propose a novel architecture TRACE which contains a hierarchical feature aggregation module to learn the composite visio-linguistic representations. TRACE achieves the SOTA performance on 3 benchmark datasets: FashionIQ, Shoes, and Birds-to-Words, with an average improvement of at least ~5.7%, ~3%, and ~5% respectively in R@K metric. Our extensive experiments and ablation studies show that TRACE consistently outperforms the existing techniques by significant margins both quantitatively and qualitatively.