 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automatic Feature Highlighting in Noisy RES Data With CycleGAN
Aug 25, 2021
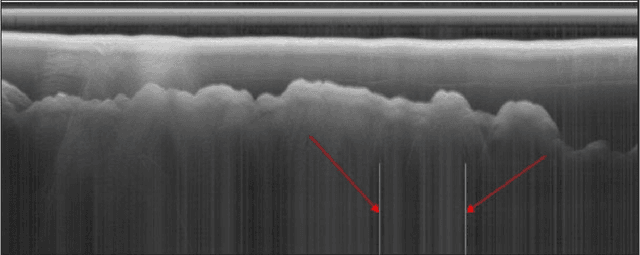

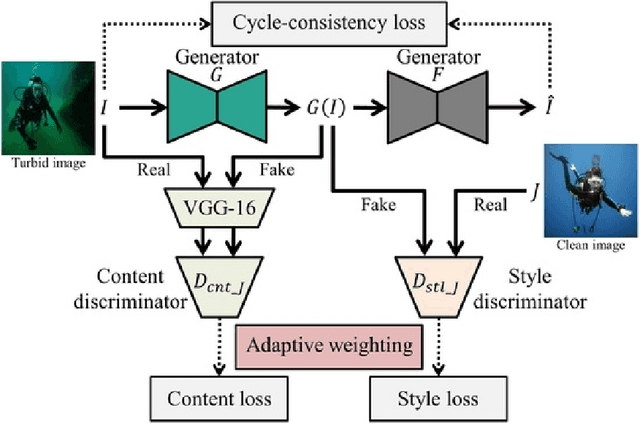
Radio echo sounding (RES) is a common technique used in subsurface glacial imaging, which provides insight into the underlying rock and ice. However, systematic noise is introduced into the data during collection, complicating interpretation of the results. Researchers most often use a combination of manual interpretation and filtering techniques to denoise data; however, these processes are time intensive and inconsistent. Fully Convolutional Networks have been proposed as an automated alternative to identify layer boundaries in radargrams. However, they require high-quality manually processed training data and struggle to interpolate data in noisy samples (Varshney et al. 2020). Herein, the authors propose a GAN based model to interpolate layer boundaries through noise and highlight layers in two-dimensional glacial RES data. In real-world noisy images, filtering often results in loss of data such that interpolating layer boundaries is nearly impossible. Furthermore, traditional machine learning approaches are not suited to this task because of the lack of paired data, so we employ an unpaired image-to-image translation model. For this model, we create a synthetic dataset to represent the domain of images with clear, highlighted layers and use an existing real-world RES dataset as our noisy domain. We implement a CycleGAN trained on these two domains to highlight layers in noisy images that can interpolate effectively without significant loss of structure or fidelity. Though the current implementation is not a perfect solution, the model clearly highlights layers in noisy data and allows researchers to determine layer size and position without mathematical filtering, manual processing, or ground-truth images for training. This is significant because clean images generated by our model enable subsurface researchers to determine glacial layer thickness more efficiently.
Cluster Analysis with Deep Embeddings and Contrastive Learning
Oct 02, 2021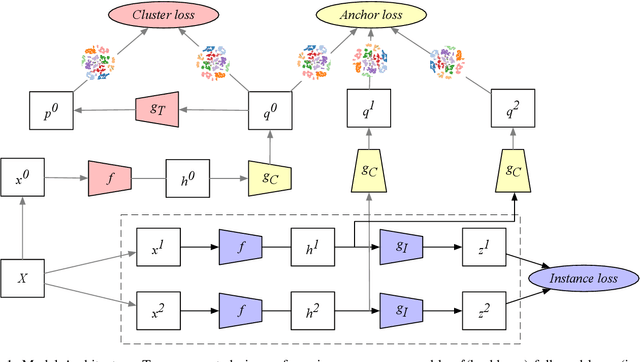
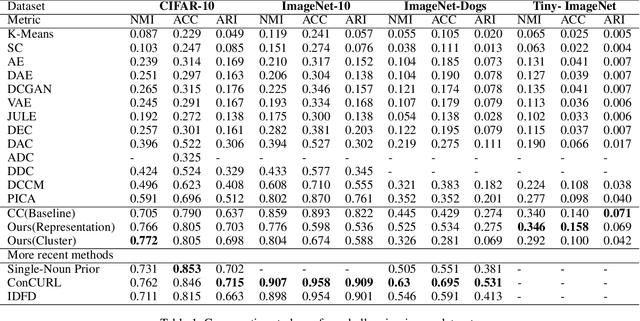
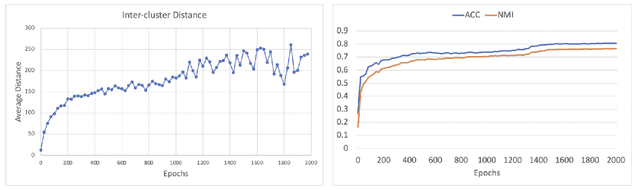
Unsupervised disentangled representation learning is a long-standing problem in computer vision. This work proposes a novel framework for performing image clustering from deep embeddings by combining instance-level contrastive learning with a deep embedding based cluster center predictor. Our approach jointly learns representations and predicts cluster centers in an end-to-end manner. This is accomplished via a three-pronged approach that combines a clustering loss, an instance-wise contrastive loss, and an anchor loss. Our fundamental intuition is that using an ensemble loss that incorporates instance-level features and a clustering procedure focusing on semantic similarity reinforces learning better representations in the latent space. We observe that our method performs exceptionally well on popular vision datasets when evaluated using standard clustering metrics such as Normalized Mutual Information (NMI), in addition to producing geometrically well-separated cluster embeddings as defined by the Euclidean distance. Our framework performs on par with widely accepted clustering methods and outperforms the state-of-the-art contrastive learning method on the CIFAR-10 dataset with an NMI score of 0.772, a 7-8% improvement on the strong baseline.
Learning Image Labels On-the-fly for Training Robust Classification Models
Sep 22, 2020
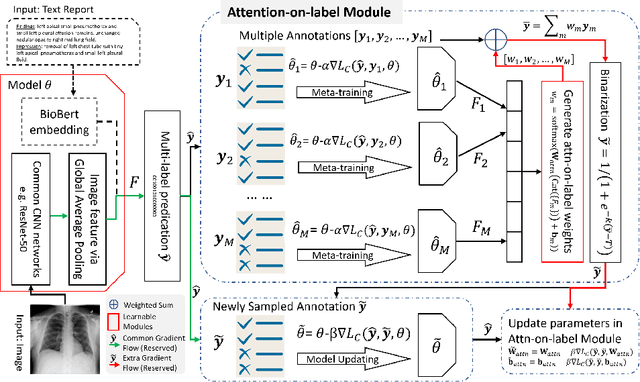

Current deep learning paradigms largely benefit from the tremendous amount of annotated data. However, the quality of the annotations often varies among labelers. Multi-observer studies have been conducted to study these annotation variances (by labeling the same data for multiple times) and its effects on critical applications like medical image analysis. This process indeed adds an extra burden to the already tedious annotation work that usually requires professional training and expertise in the specific domains. On the other hand, automated annotation methods based on NLP algorithms have recently shown promise as a reasonable alternative, relying on the existing diagnostic reports of those images that are widely available in the clinical system. Compared to human labelers, different algorithms provide labels with varying qualities that are even noisier. In this paper, we show how noisy annotations (e.g., from different algorithm-based labelers) can be utilized together and mutually benefit the learning of classification tasks. Specifically, the concept of attention-on-label is introduced to sample better label sets on-the-fly as the training data. A meta-training based label-sampling module is designed to attend the labels that benefit the model learning the most through additional back-propagation processes. We apply the attention-on-label scheme on the classification task of a synthetic noisy CIFAR-10 dataset to prove the concept, and then demonstrate superior results (3-5% increase on average in multiple disease classification AUCs) on the chest x-ray images from a hospital-scale dataset (MIMIC-CXR) and hand-labeled dataset (OpenI) in comparison to regular training paradigms.
Gait-based Human Identification through Minimum Gait-phases and Sensors
Oct 15, 2021
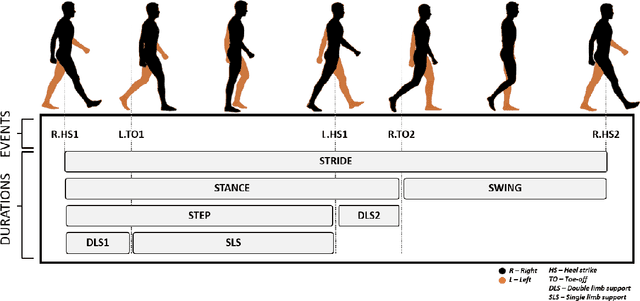
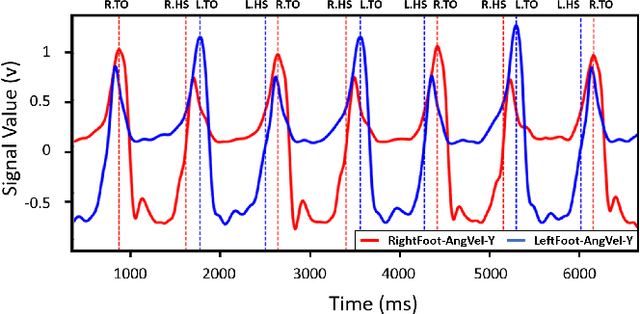
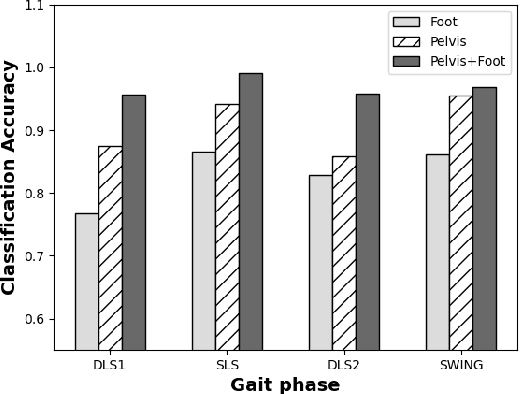
Human identification is one of the most common and critical tasks for condition monitoring, human-machine interaction, and providing assistive services in smart environments. Recently, human gait has gained new attention as a biometric for identification to achieve contactless identification from a distance robust to physical appearances. However, an important aspect of gait identification through wearables and image-based systems alike is accurate identification when limited information is available, for example, when only a fraction of the whole gait cycle or only a part of the subject body is visible. In this paper, we present a gait identification technique based on temporal and descriptive statistic parameters of different gait phases as the features and we investigate the performance of using only single gait phases for the identification task using a minimum number of sensors. It was shown that it is possible to achieve high accuracy of over 95.5 percent by monitoring a single phase of the whole gait cycle through only a single sensor. It was also shown that the proposed methodology could be used to achieve 100 percent identification accuracy when the whole gait cycle was monitored through pelvis and foot sensors combined. The ANN was found to be more robust to fewer data features compared to SVM and was concluded as the best machine algorithm for the purpose.
One-Shot Object Affordance Detection in the Wild
Aug 08, 2021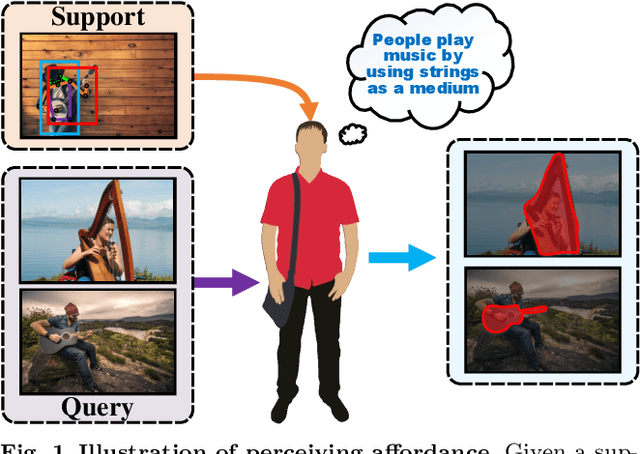
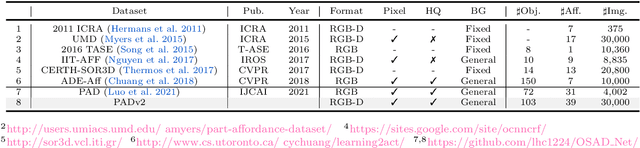
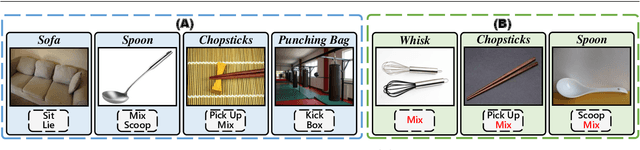
Affordance detection refers to identifying the potential action possibilities of objects in an image, which is a crucial ability for robot perception and manipulation. To empower robots with this ability in unseen scenarios, we first study the challenging one-shot affordance detection problem in this paper, i.e., given a support image that depicts the action purpose, all objects in a scene with the common affordance should be detected. To this end, we devise a One-Shot Affordance Detection Network (OSAD-Net) that firstly estimates the human action purpose and then transfers it to help detect the common affordance from all candidate images. Through collaboration learning, OSAD-Net can capture the common characteristics between objects having the same underlying affordance and learn a good adaptation capability for perceiving unseen affordances. Besides, we build a large-scale Purpose-driven Affordance Dataset v2 (PADv2) by collecting and labeling 30k images from 39 affordance and 103 object categories. With complex scenes and rich annotations, our PADv2 dataset can be used as a test bed to benchmark affordance detection methods and may also facilitate downstream vision tasks, such as scene understanding, action recognition, and robot manipulation. Specifically, we conducted comprehensive experiments on PADv2 dataset by including 11 advanced models from several related research fields. Experimental results demonstrate the superiority of our model over previous representative ones in terms of both objective metrics and visual quality. The benchmark suite is available at https://github.com/lhc1224/OSAD Net.
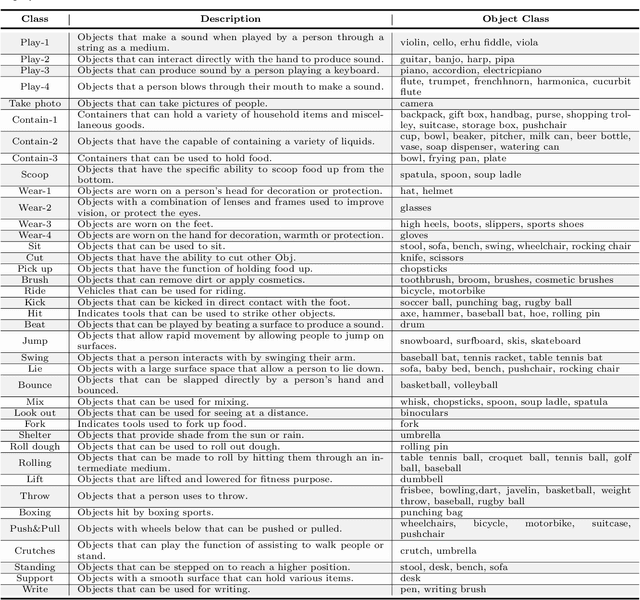
Less is More: Pay Less Attention in Vision Transformers
May 29, 2021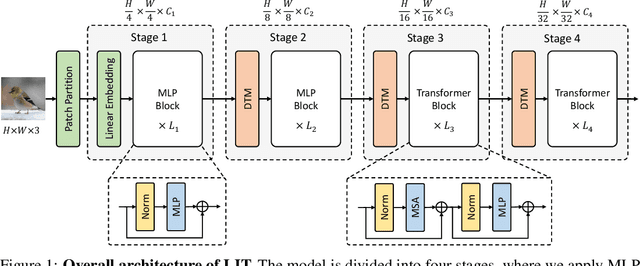
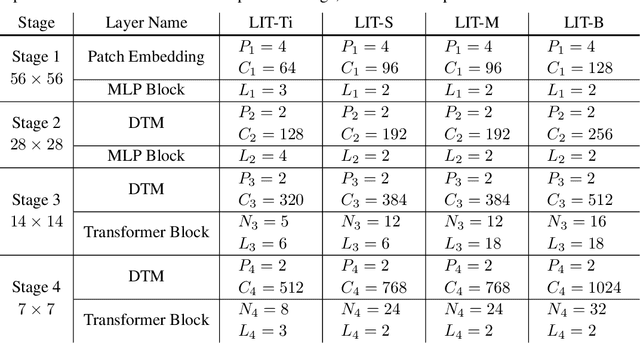
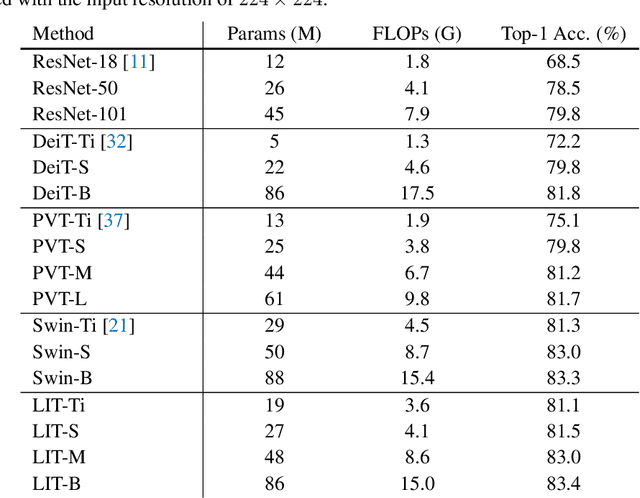

Transformers have become one of the dominant architectures in deep learning, particularly as a powerful alternative to convolutional neural networks (CNNs) in computer vision. However, Transformer training and inference in previous works can be prohibitively expensive due to the quadratic complexity of self-attention over a long sequence of representations, especially for high-resolution dense prediction tasks. To this end, we present a novel Less attention vIsion Transformer (LIT), building upon the fact that convolutions, fully-connected (FC) layers, and self-attentions have almost equivalent mathematical expressions for processing image patch sequences. Specifically, we propose a hierarchical Transformer where we use pure multi-layer perceptrons (MLPs) to encode rich local patterns in the early stages while applying self-attention modules to capture longer dependencies in deeper layers. Moreover, we further propose a learned deformable token merging module to adaptively fuse informative patches in a non-uniform manner. The proposed LIT achieves promising performance on image recognition tasks, including image classification, object detection and instance segmentation, serving as a strong backbone for many vision tasks.
Robust Image Reconstruction with Misaligned Structural Information
Apr 01, 2020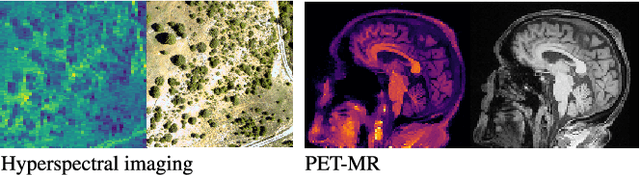
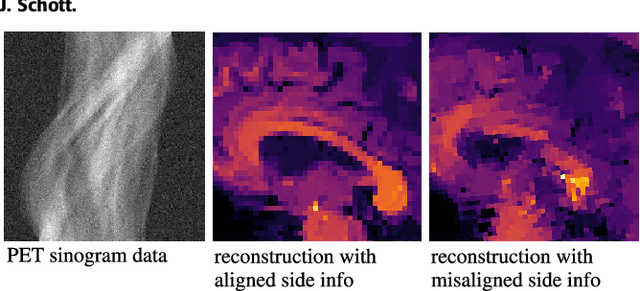
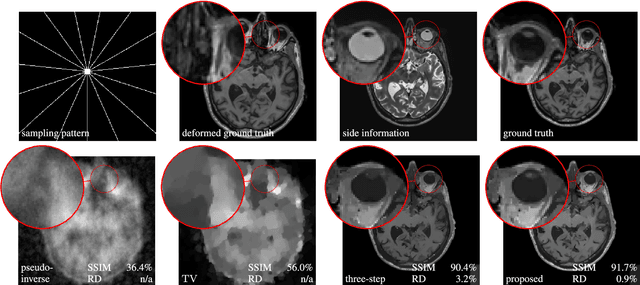
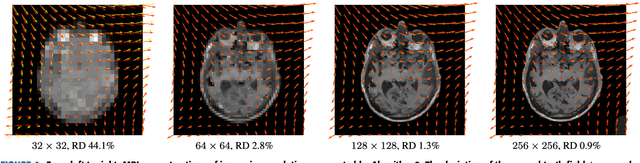
Multi-modality (or multi-channel) imaging is becoming increasingly important and more widely available, e.g. hyperspectral imaging in remote sensing, spectral CT in material sciences as well as multi-contrast MRI and PET-MR in medicine. Research in the last decades resulted in a plethora of mathematical methods to combine data from several modalities. State-of-the-art methods, often formulated as variational regularization, have shown to significantly improve image reconstruction both quantitatively and qualitatively. Almost all of these models rely on the assumption that the modalities are perfectly registered, which is not the case in most real world applications. We propose a variational framework which jointly performs reconstruction and registration, thereby overcoming this hurdle. Numerical results show the potential of the proposed strategy for various applications for hyperspectral imaging, PET-MR and multi-contrast MRI: typical misalignments between modalities such as rotations, translations, zooms can be effectively corrected during the reconstruction process. Therefore the proposed framework allows the robust exploitation of shared information across multiple modalities under real conditions.
Voxel-wise Cross-Volume Representation Learning for 3D Neuron Reconstruction
Aug 14, 2021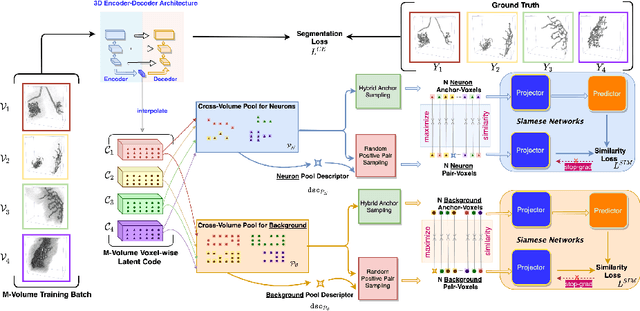
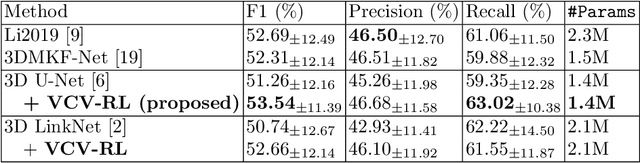

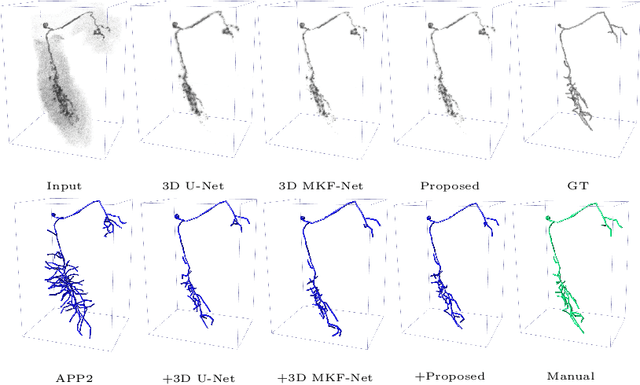
Automatic 3D neuron reconstruction is critical for analysing the morphology and functionality of neurons in brain circuit activities. However, the performance of existing tracing algorithms is hinged by the low image quality. Recently, a series of deep learning based segmentation methods have been proposed to improve the quality of raw 3D optical image stacks by removing noises and restoring neuronal structures from low-contrast background. Due to the variety of neuron morphology and the lack of large neuron datasets, most of current neuron segmentation models rely on introducing complex and specially-designed submodules to a base architecture with the aim of encoding better feature representations. Though successful, extra burden would be put on computation during inference. Therefore, rather than modifying the base network, we shift our focus to the dataset itself. The encoder-decoder backbone used in most neuron segmentation models attends only intra-volume voxel points to learn structural features of neurons but neglect the shared intrinsic semantic features of voxels belonging to the same category among different volumes, which is also important for expressive representation learning. Hence, to better utilise the scarce dataset, we propose to explicitly exploit such intrinsic features of voxels through a novel voxel-level cross-volume representation learning paradigm on the basis of an encoder-decoder segmentation model. Our method introduces no extra cost during inference. Evaluated on 42 3D neuron images from BigNeuron project, our proposed method is demonstrated to improve the learning ability of the original segmentation model and further enhancing the reconstruction performance.
SALYPATH: A Deep-Based Architecture for visual attention prediction
Jun 29, 2021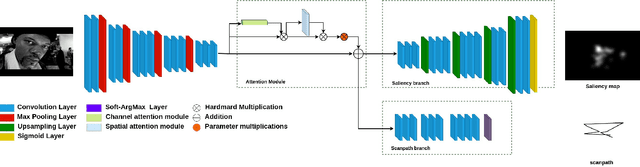


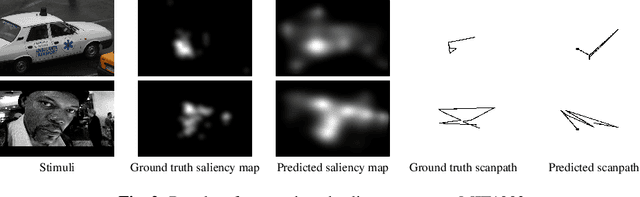
Human vision is naturally more attracted by some regions within their field of view than others. This intrinsic selectivity mechanism, so-called visual attention, is influenced by both high- and low-level factors; such as the global environment (illumination, background texture, etc.), stimulus characteristics (color, intensity, orientation, etc.), and some prior visual information. Visual attention is useful for many computer vision applications such as image compression, recognition, and captioning. In this paper, we propose an end-to-end deep-based method, so-called SALYPATH (SALiencY and scanPATH), that efficiently predicts the scanpath of an image through features of a saliency model. The idea is predict the scanpath by exploiting the capacity of a deep-based model to predict the saliency. The proposed method was evaluated through 2 well-known datasets. The results obtained showed the relevance of the proposed framework comparing to state-of-the-art models.
Auto White-Balance Correction for Mixed-Illuminant Scenes
Sep 17, 2021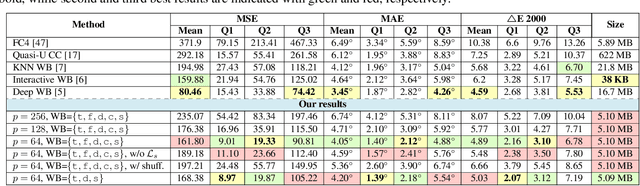

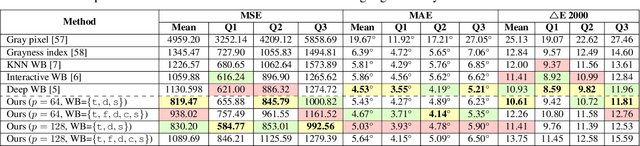

Auto white balance (AWB) is applied by camera hardware at capture time to remove the color cast caused by the scene illumination. The vast majority of white-balance algorithms assume a single light source illuminates the scene; however, real scenes often have mixed lighting conditions. This paper presents an effective AWB method to deal with such mixed-illuminant scenes. A unique departure from conventional AWB, our method does not require illuminant estimation, as is the case in traditional camera AWB modules. Instead, our method proposes to render the captured scene with a small set of predefined white-balance settings. Given this set of rendered images, our method learns to estimate weighting maps that are used to blend the rendered images to generate the final corrected image. Through extensive experiments, we show this proposed method produces promising results compared to other alternatives for single- and mixed-illuminant scene color correction. Our source code and trained models are available at https://github.com/mahmoudnafifi/mixedillWB.