 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
CReSt: A Comprehensive Benchmark for Retrieval-Augmented Generation with Complex Reasoning over Structured Documents
May 23, 2025



Large Language Models (LLMs) have made substantial progress in recent years, yet evaluating their capabilities in practical Retrieval-Augmented Generation (RAG) scenarios remains challenging. In practical applications, LLMs must demonstrate complex reasoning, refuse to answer appropriately, provide precise citations, and effectively understand document layout. These capabilities are crucial for advanced task handling, uncertainty awareness, maintaining reliability, and structural understanding. While some of the prior works address these aspects individually, there is a need for a unified framework that evaluates them collectively in practical RAG scenarios. To address this, we present CReSt (A Comprehensive Benchmark for Retrieval-Augmented Generation with Complex Reasoning over Structured Documents), a benchmark designed to assess these key dimensions holistically. CReSt comprises 2,245 human-annotated examples in English and Korean, designed to capture practical RAG scenarios that require complex reasoning over structured documents. It also introduces a tailored evaluation methodology to comprehensively assess model performance in these critical areas. Our evaluation shows that even advanced LLMs struggle to perform consistently across these dimensions, underscoring key areas for improvement. We release CReSt to support further research and the development of more robust RAG systems. The dataset and code are available at: https://github.com/UpstageAI/CReSt.
Domain Adversarial Training for Mitigating Gender Bias in Speech-based Mental Health Detection
May 06, 2025



Speech-based AI models are emerging as powerful tools for detecting depression and the presence of Post-traumatic stress disorder (PTSD), offering a non-invasive and cost-effective way to assess mental health. However, these models often struggle with gender bias, which can lead to unfair and inaccurate predictions. In this study, our study addresses this issue by introducing a domain adversarial training approach that explicitly considers gender differences in speech-based depression and PTSD detection. Specifically, we treat different genders as distinct domains and integrate this information into a pretrained speech foundation model. We then validate its effectiveness on the E-DAIC dataset to assess its impact on performance. Experimental results show that our method notably improves detection performance, increasing the F1-score by up to 13.29 percentage points compared to the baseline. This highlights the importance of addressing demographic disparities in AI-driven mental health assessment.
Gait-based Frailty Assessment using Image Representation of IMU Signals and Deep CNN
Oct 15, 2021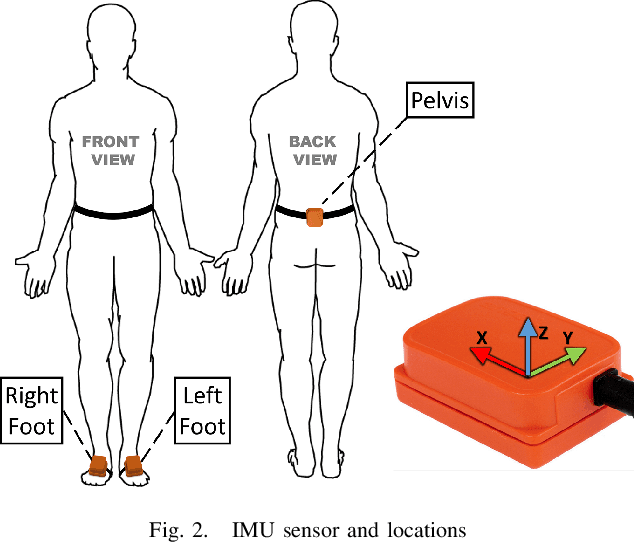
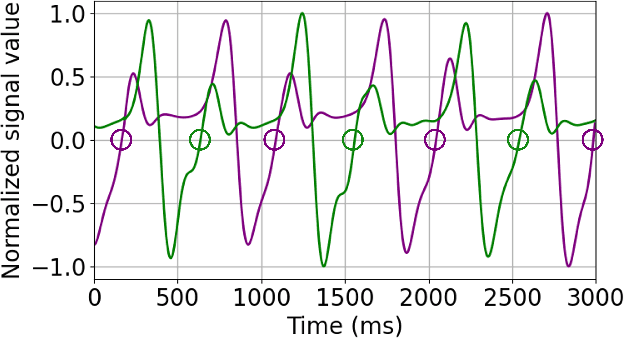
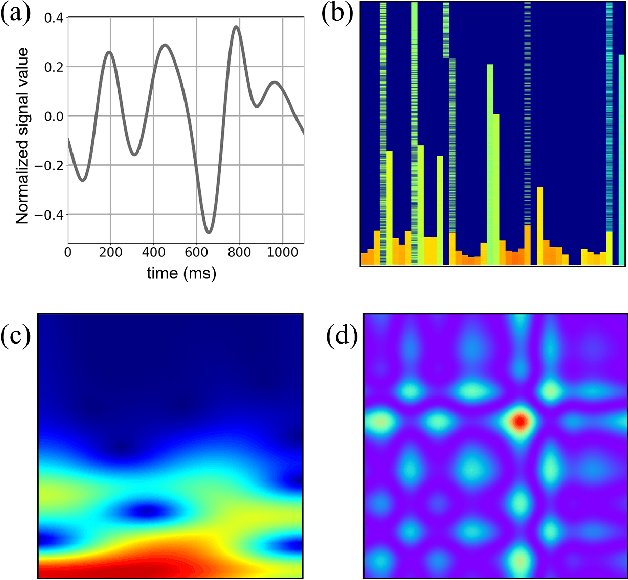
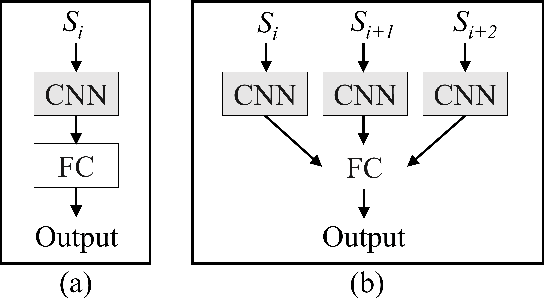
Frailty is a common and critical condition in elderly adults, which may lead to further deterioration of health. However, difficulties and complexities exist in traditional frailty assessments based on activity-related questionnaires. These can be overcome by monitoring the effects of frailty on the gait. In this paper, it is shown that by encoding gait signals as images, deep learning-based models can be utilized for the classification of gait type. Two deep learning models (a) SS-CNN, based on single stride input images, and (b) MS-CNN, based on 3 consecutive strides were proposed. It was shown that MS-CNN performs best with an accuracy of 85.1\%, while SS-CNN achieved an accuracy of 77.3\%. This is because MS-CNN can observe more features corresponding to stride-to-stride variations which is one of the key symptoms of frailty. Gait signals were encoded as images using STFT, CWT, and GAF. While the MS-CNN model using GAF images achieved the best overall accuracy and precision, CWT has a slightly better recall. This study demonstrates how image encoded gait data can be used to exploit the full potential of deep learning CNN models for the assessment of frailty.
Gait-based Human Identification through Minimum Gait-phases and Sensors
Oct 15, 2021
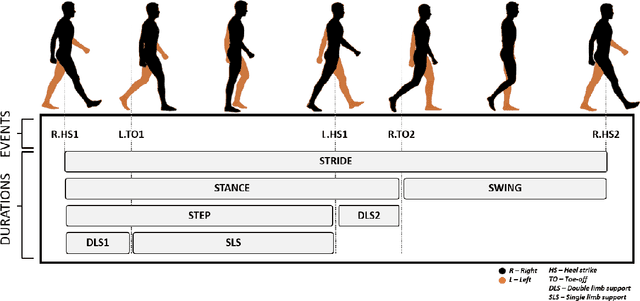
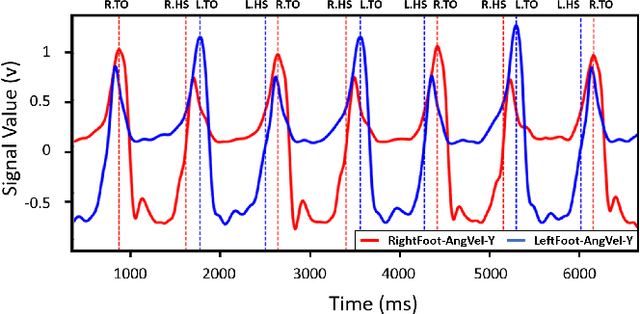
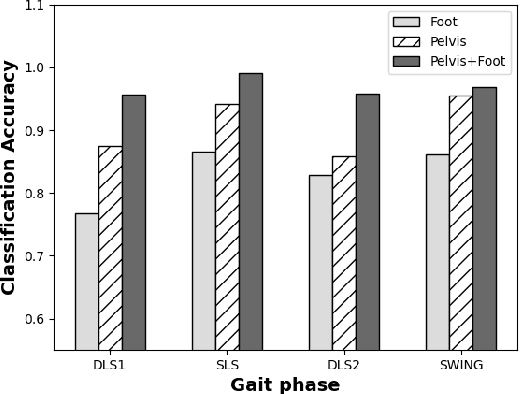
Human identification is one of the most common and critical tasks for condition monitoring, human-machine interaction, and providing assistive services in smart environments. Recently, human gait has gained new attention as a biometric for identification to achieve contactless identification from a distance robust to physical appearances. However, an important aspect of gait identification through wearables and image-based systems alike is accurate identification when limited information is available, for example, when only a fraction of the whole gait cycle or only a part of the subject body is visible. In this paper, we present a gait identification technique based on temporal and descriptive statistic parameters of different gait phases as the features and we investigate the performance of using only single gait phases for the identification task using a minimum number of sensors. It was shown that it is possible to achieve high accuracy of over 95.5 percent by monitoring a single phase of the whole gait cycle through only a single sensor. It was also shown that the proposed methodology could be used to achieve 100 percent identification accuracy when the whole gait cycle was monitored through pelvis and foot sensors combined. The ANN was found to be more robust to fewer data features compared to SVM and was concluded as the best machine algorithm for the purpose.
An Empirical Study of Tokenization Strategies for Various Korean NLP Tasks
Oct 06, 2020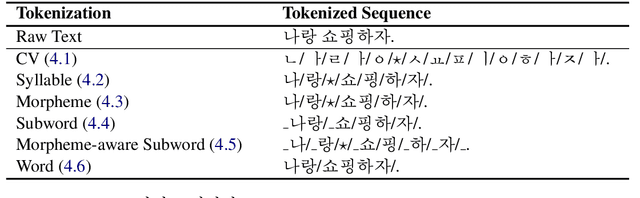
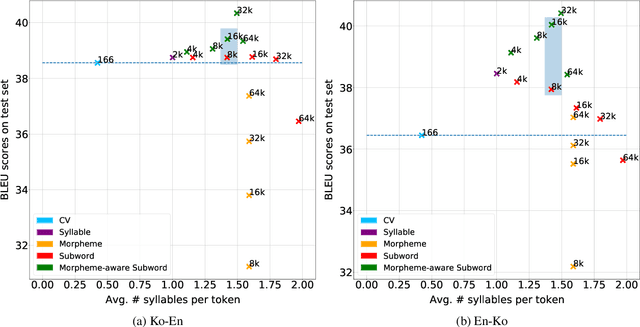
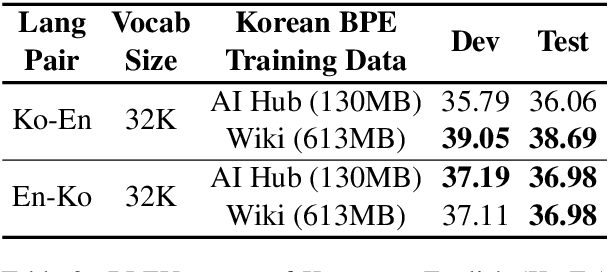
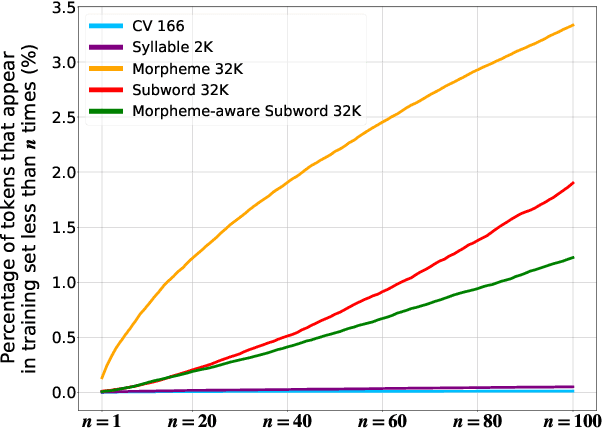
Typically, tokenization is the very first step in most text processing works. As a token serves as an atomic unit that embeds the contextual information of text, how to define a token plays a decisive role in the performance of a model.Even though Byte Pair Encoding (BPE) has been considered the de facto standard tokenization method due to its simplicity and universality, it still remains unclear whether BPE works best across all languages and tasks. In this paper, we test several tokenization strategies in order to answer our primary research question, that is, "What is the best tokenization strategy for Korean NLP tasks?" Experimental results demonstrate that a hybrid approach of morphological segmentation followed by BPE works best in Korean to/from English machine translation and natural language understanding tasks such as KorNLI, KorSTS, NSMC, and PAWS-X. As an exception, for KorQuAD, the Korean extension of SQuAD, BPE segmentation turns out to be the most effective.