 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Label-Aware Distribution Calibration for Long-tailed Classification
Nov 09, 2021
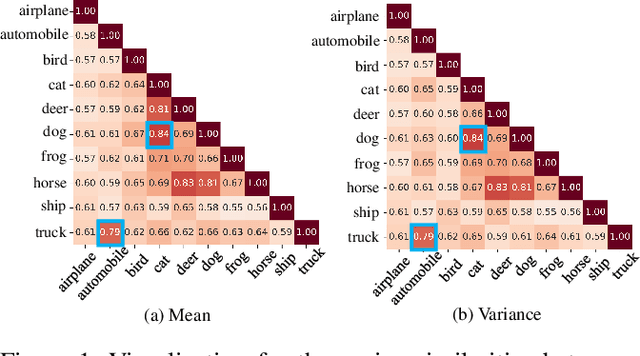

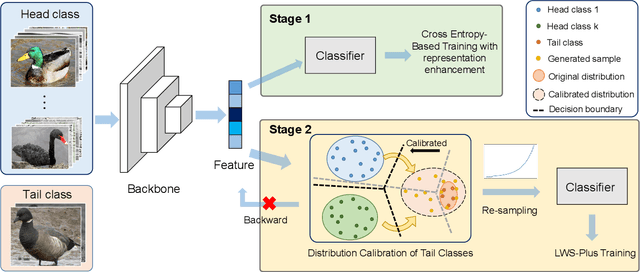
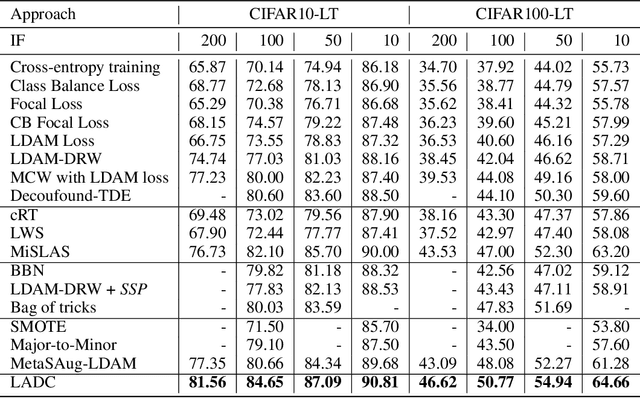
Real-world data usually present long-tailed distributions. Training on imbalanced data tends to render neural networks perform well on head classes while much worse on tail classes. The severe sparseness of training instances for the tail classes is the main challenge, which results in biased distribution estimation during training. Plenty of efforts have been devoted to ameliorating the challenge, including data re-sampling and synthesizing new training instances for tail classes. However, no prior research has exploited the transferable knowledge from head classes to tail classes for calibrating the distribution of tail classes. In this paper, we suppose that tail classes can be enriched by similar head classes and propose a novel distribution calibration approach named as label-Aware Distribution Calibration LADC. LADC transfers the statistics from relevant head classes to infer the distribution of tail classes. Sampling from calibrated distribution further facilitates re-balancing the classifier. Experiments on both image and text long-tailed datasets demonstrate that LADC significantly outperforms existing methods.The visualization also shows that LADC provides a more accurate distribution estimation.
PoseGAN: A Pose-to-Image Translation Framework for Camera Localization
Jun 23, 2020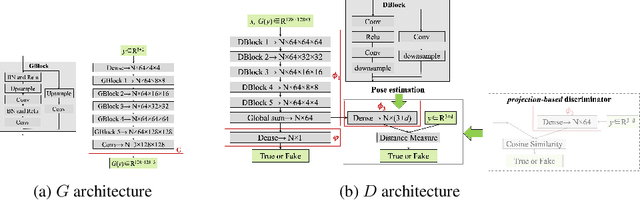
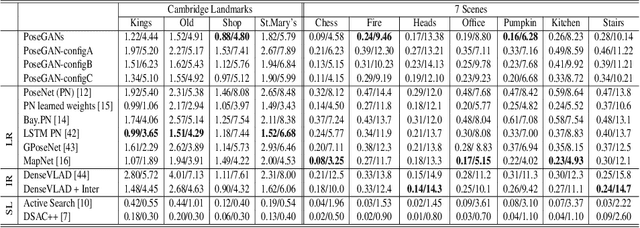


Camera localization is a fundamental requirement in robotics and computer vision. This paper introduces a pose-to-image translation framework to tackle the camera localization problem. We present PoseGANs, a conditional generative adversarial networks (cGANs) based framework for the implementation of pose-to-image translation. PoseGANs feature a number of innovations including a distance metric based conditional discriminator to conduct camera localization and a pose estimation technique for generated camera images as a stronger constraint to improve camera localization performance. Compared with learning-based regression methods such as PoseNet, PoseGANs can achieve better performance with model sizes that are 70% smaller. In addition, PoseGANs introduce the view synthesis technique to establish the correspondence between the 2D images and the scene, \textit{i.e.}, given a pose, PoseGANs are able to synthesize its corresponding camera images. Furthermore, we demonstrate that PoseGANs differ in principle from structure-based localization and learning-based regressions for camera localization, and show that PoseGANs exploit the geometric structures to accomplish the camera localization task, and is therefore more stable than and superior to learning-based regressions which rely on local texture features instead. In addition to camera localization and view synthesis, we also demonstrate that PoseGANs can be successfully used for other interesting applications such as moving object elimination and frame interpolation in video sequences.
Towards Using Clothes Style Transfer for Scenario-aware Person Video Generation
Oct 25, 2021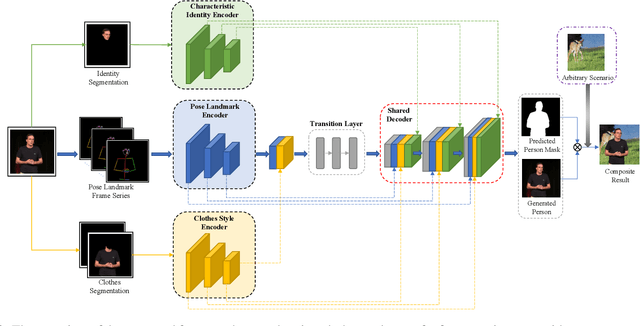
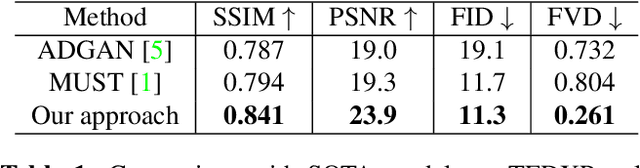
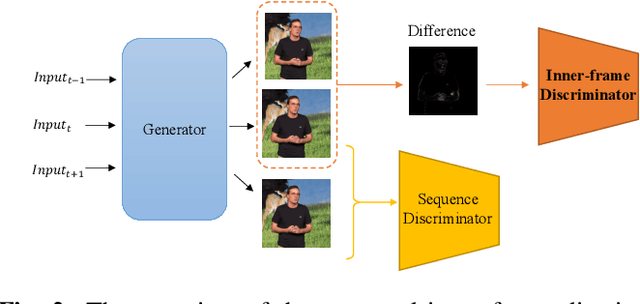
Clothes style transfer for person video generation is a challenging task, due to drastic variations of intra-person appearance and video scenarios. To tackle this problem, most recent AdaIN-based architectures are proposed to extract clothes and scenario features for generation. However, these approaches suffer from being short of fine-grained details and are prone to distort the origin person. To further improve the generation performance, we propose a novel framework with disentangled multi-branch encoders and a shared decoder. Moreover, to pursue the strong video spatio-temporal consistency, an inner-frame discriminator is delicately designed with input being cross-frame difference. Besides, the proposed framework possesses the property of scenario adaptation. Extensive experiments on the TEDXPeople benchmark demonstrate the superiority of our method over state-of-the-art approaches in terms of image quality and video coherence.
Hyperspectral Image Denoising with Log-Based Robust PCA
May 25, 2021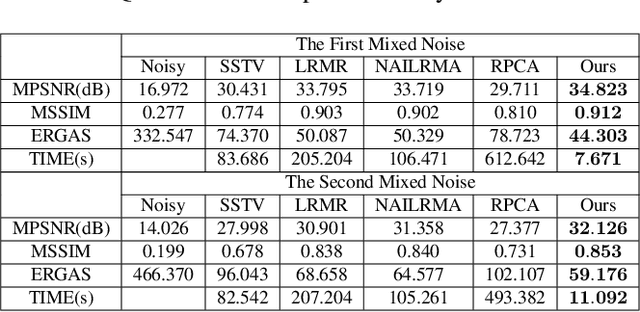


It is a challenging task to remove heavy and mixed types of noise from Hyperspectral images (HSIs). In this paper, we propose a novel nonconvex approach to RPCA for HSI denoising, which adopts the log-determinant rank approximation and a novel $\ell_{2,\log}$ norm, to restrict the low-rank or column-wise sparse properties for the component matrices, respectively.For the $\ell_{2,\log}$-regularized shrinkage problem, we develop an efficient, closed-form solution, which is named $\ell_{2,\log}$-shrinkage operator, which can be generally used in other problems. Extensive experiments on both simulated and real HSIs demonstrate the effectiveness of the proposed method in denoising HSIs.
Lymph Node Detection in T2 MRI with Transformers
Nov 09, 2021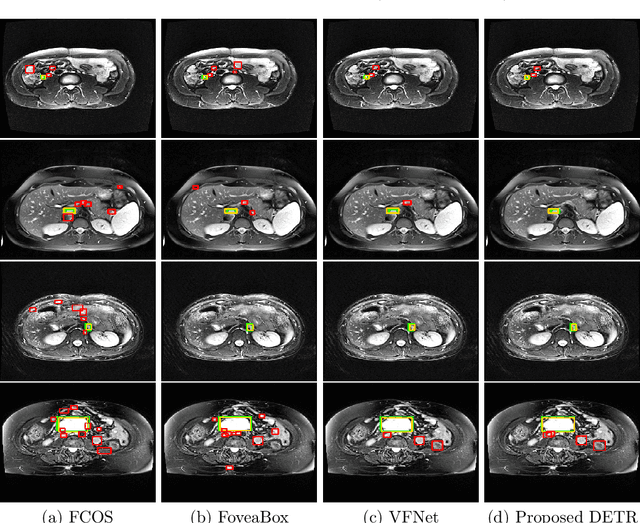
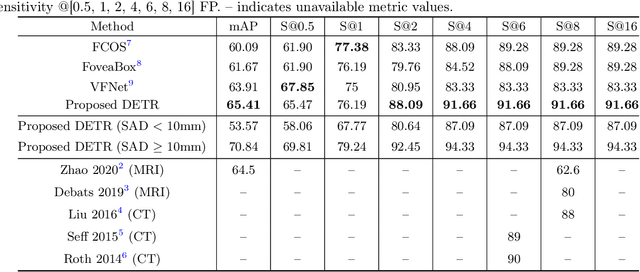
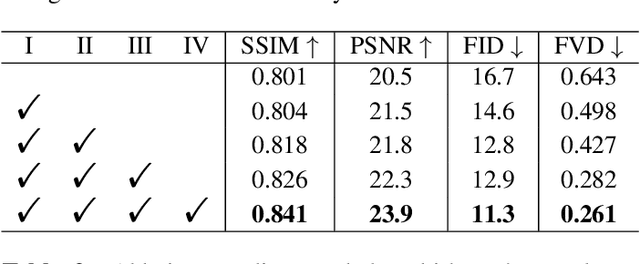
Identification of lymph nodes (LN) in T2 Magnetic Resonance Imaging (MRI) is an important step performed by radiologists during the assessment of lymphoproliferative diseases. The size of the nodes play a crucial role in their staging, and radiologists sometimes use an additional contrast sequence such as diffusion weighted imaging (DWI) for confirmation. However, lymph nodes have diverse appearances in T2 MRI scans, making it tough to stage for metastasis. Furthermore, radiologists often miss smaller metastatic lymph nodes over the course of a busy day. To deal with these issues, we propose to use the DEtection TRansformer (DETR) network to localize suspicious metastatic lymph nodes for staging in challenging T2 MRI scans acquired by different scanners and exam protocols. False positives (FP) were reduced through a bounding box fusion technique, and a precision of 65.41\% and sensitivity of 91.66\% at 4 FP per image was achieved. To the best of our knowledge, our results improve upon the current state-of-the-art for lymph node detection in T2 MRI scans.
Deep learning-based attenuation correction in the image domain for myocardial perfusion SPECT imaging
Feb 10, 2021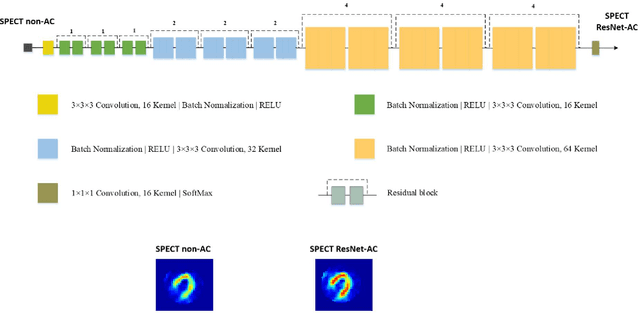
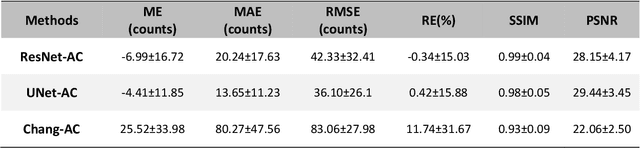
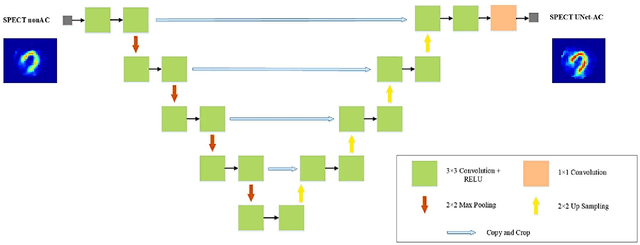
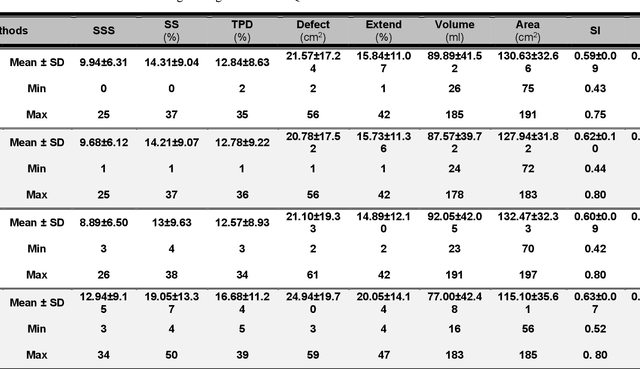
Objective: In this work, we set out to investigate the accuracy of direct attenuation correction (AC) in the image domain for the myocardial perfusion SPECT imaging (MPI-SPECT) using two residual (ResNet) and UNet deep convolutional neural networks. Methods: The MPI-SPECT 99mTc-sestamibi images of 99 participants were retrospectively examined. UNet and ResNet networks were trained using SPECT non-attenuation corrected images as input and CT-based attenuation corrected SPECT images (CT-AC) as reference. The Chang AC approach, considering a uniform attenuation coefficient within the body contour, was also implemented. Quantitative and clinical evaluation of the proposed methods were performed considering SPECT CT-AC images of 19 subjects as reference using the mean absolute error (MAE), structural similarity index (SSIM) metrics, as well as relevant clinical indices such as perfusion deficit (TPD). Results: Overall, the deep learning solution exhibited good agreement with the CT-based AC, noticeably outperforming the Chang method. The ResNet and UNet models resulted in the ME (count) of ${-6.99\pm16.72}$ and ${-4.41\pm11.8}$ and SSIM of ${0.99\pm0.04}$ and ${0.98\pm0.05}$, respectively. While the Change approach led to ME and SSIM of ${25.52\pm33.98}$ and ${0.93\pm0.09}$, respectively. Similarly, the clinical evaluation revealed a mean TPD of ${12.78\pm9.22}$ and ${12.57\pm8.93}$ for the ResNet and UNet models, respectively, compared to ${12.84\pm8.63}$ obtained from the reference SPECT CT-AC images. On the other hand, the Chang approach led to a mean TPD of ${16.68\pm11.24}$. Conclusion: We evaluated two deep convolutional neural networks to estimate SPECT-AC images directly from the non-attenuation corrected images. The deep learning solutions exhibited the promising potential to generate reliable attenuation corrected SPECT images without the use of transmission scanning.
Biometric Template Protection for Neural-Network-based Face Recognition Systems: A Survey of Methods and Evaluation Techniques
Oct 11, 2021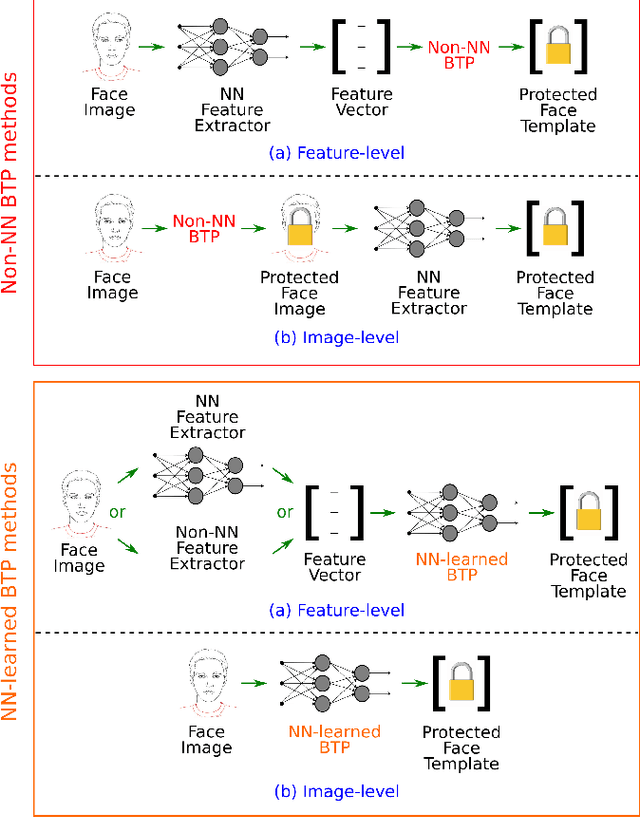
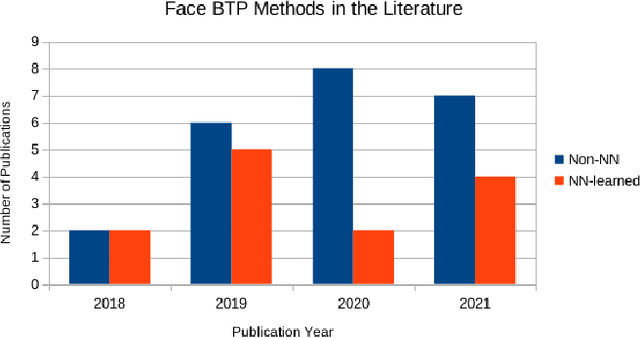


This paper presents a survey of biometric template protection (BTP) methods for securing face templates in neural-network-based face recognition systems. The BTP methods are categorised into two types: Non-NN and NN-learned. Non-NN methods use a neural network (NN) as a feature extractor, but the BTP part is based on a non-NN algorithm applied at image-level or feature-level. In contrast, NN-learned methods specifically employ a NN to learn a protected template from the unprotected face image/features. We present examples of Non-NN and NN-learned face BTP methods from the literature, along with a discussion of the two categories' comparative strengths and weaknesses. We also investigate the techniques used to evaluate these BTP methods, in terms of the three most common criteria: recognition accuracy, irreversibility, and renewability/unlinkability. As expected, the recognition accuracy of protected face recognition systems is generally evaluated using the same (empirical) techniques employed for evaluating standard (unprotected) biometric systems. On the contrary, most irreversibility and renewability/unlinkability evaluations are based on theoretical assumptions/estimates or verbal implications, with no empirical validation in a practical face recognition context. So, we recommend a greater focus on empirical evaluation strategies, to provide more concrete insights into the irreversibility and renewability/unlinkability of face BTP methods in practice. An exploration of the reproducibility of the studied BTP works, in terms of the public availability of their implementation code and evaluation datasets/procedures, suggests that it would currently be difficult for the BTP community to faithfully replicate (and thus validate) most of the reported findings. So, we advocate for a push towards reproducibility, in the hope of furthering our understanding of the face BTP research field.
Inter-Domain Alignment for Predicting High-Resolution Brain Networks Using Teacher-Student Learning
Oct 06, 2021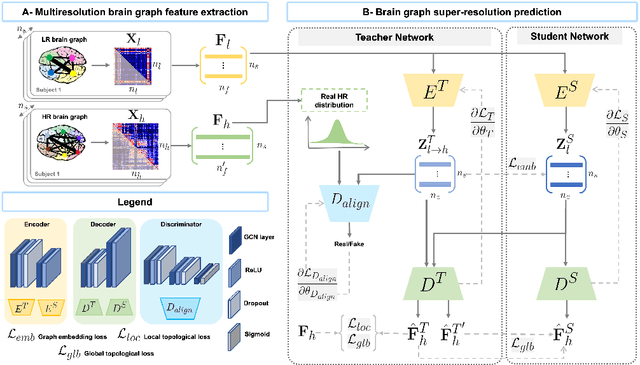

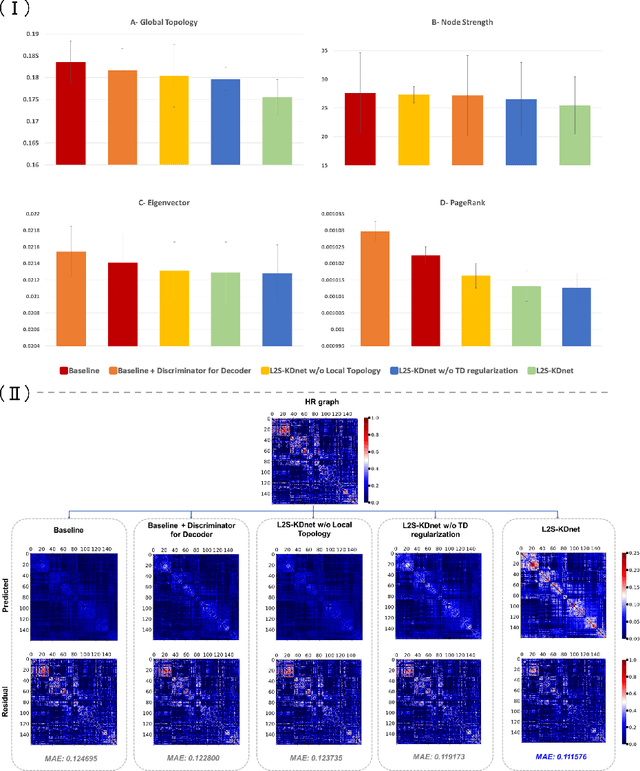
Accurate and automated super-resolution image synthesis is highly desired since it has the great potential to circumvent the need for acquiring high-cost medical scans and a time-consuming preprocessing pipeline of neuroimaging data. However, existing deep learning frameworks are solely designed to predict high-resolution (HR) image from a low-resolution (LR) one, which limits their generalization ability to brain graphs (i.e., connectomes). A small body of works has focused on superresolving brain graphs where the goal is to predict a HR graph from a single LR graph. Although promising, existing works mainly focus on superresolving graphs belonging to the same domain (e.g., functional), overlooking the domain fracture existing between multimodal brain data distributions (e.g., morphological and structural). To this aim, we propose a novel inter-domain adaptation framework namely, Learn to SuperResolve Brain Graphs with Knowledge Distillation Network (L2S-KDnet), which adopts a teacher-student paradigm to superresolve brain graphs. Our teacher network is a graph encoder-decoder that firstly learns the LR brain graph embeddings, and secondly learns how to align the resulting latent representations to the HR ground truth data distribution using an adversarial regularization. Ultimately, it decodes the HR graphs from the aligned embeddings. Next, our student network learns the knowledge of the aligned brain graphs as well as the topological structure of the predicted HR graphs transferred from the teacher. We further leverage the decoder of the teacher to optimize the student network. L2S-KDnet presents the first TS architecture tailored for brain graph super-resolution synthesis that is based on inter-domain alignment. Our experimental results demonstrate substantial performance gains over benchmark methods.
Beyond Point Clouds: A Knowledge-Aided High Resolution Imaging Radar Deep Detector for Autonomous Driving
Nov 01, 2021

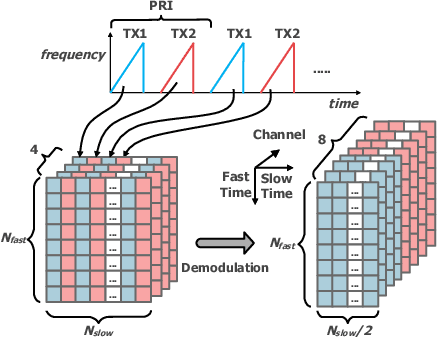
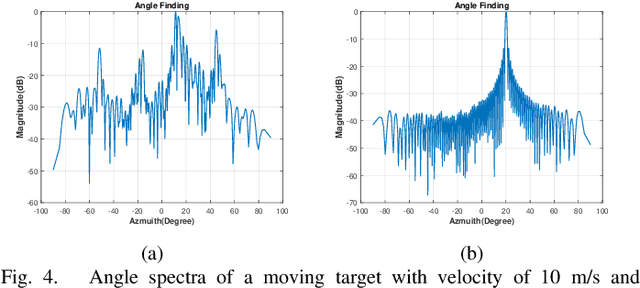
The potentials of automotive radar for autonomous driving have not been fully exploited. We present a multi-input multi-output (MIMO) radar transmit and receive signal processing chain, a knowledge-aided approach exploiting the radar domain knowledge and signal structure, to generate high resolution radar range-azimuth spectra for object detection and classification using deep neural networks. To achieve waveform orthogonality among a large number of transmit antennas cascaded by four automotive radar transceivers, we propose a staggered time division multiplexing (TDM) scheme and velocity unfolding algorithm using both Chinese remainder theorem and overlapped array. Field experiments with multi-modal sensors were conducted at The University of Alabama. High resolution radar spectra were obtained and labeled using the camera and LiDAR recordings. Initial experiments show promising performance of object detection using an image-oriented deep neural network with an average precision of 96.1% at an intersection of union (IoU) of typically 0.5 on 2,000 radar frames.
Segmentation of Lungs COVID Infected Regions by Attention Mechanism and Synthetic Data
Aug 19, 2021
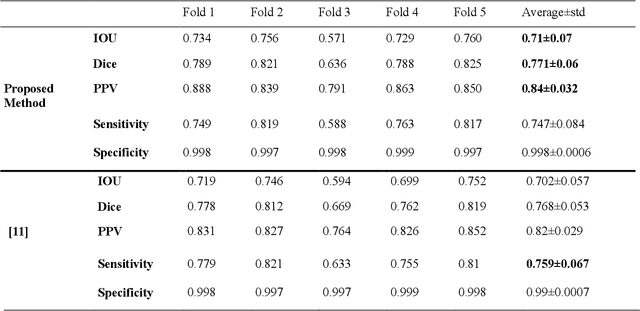
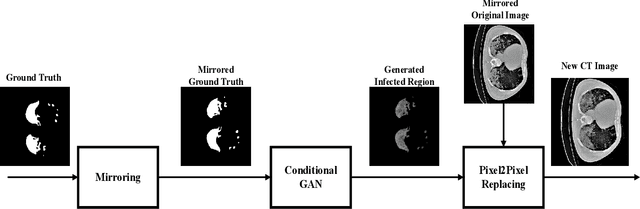
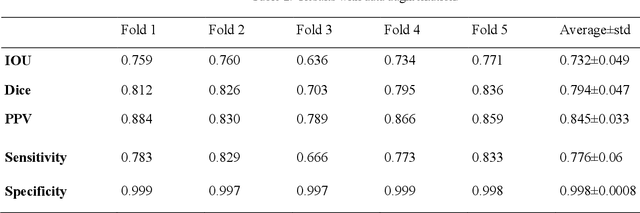
Coronavirus has caused hundreds of thousands of deaths. Fatalities could decrease if every patient could get suitable treatment by the healthcare system. Machine learning, especially computer vision methods based on deep learning, can help healthcare professionals diagnose and treat COVID-19 infected cases more efficiently. Hence, infected patients can get better service from the healthcare system and decrease the number of deaths caused by the coronavirus. This research proposes a method for segmenting infected lung regions in a CT image. For this purpose, a convolutional neural network with an attention mechanism is used to detect infected areas with complex patterns. Attention blocks improve the segmentation accuracy by focusing on informative parts of the image. Furthermore, a generative adversarial network generates synthetic images for data augmentation and expansion of small available datasets. Experimental results show the superiority of the proposed method compared to some existing procedures.