 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDA: Text-Augmented Defense Framework for Robust Vision-Language Models against Adversarial Image Attacks
Apr 01, 2026Vision-language models (VLMs) are vulnerable to adversarial image perturbations. Existing works based on adversarial training against task-specific adversarial examples are computationally expensive and often fail to generalize to unseen attack types. To address these limitations, we introduce Paraphrase-Decomposition-Aggregation (PDA), a training-free defense framework that leverages text augmentation to enhance VLM robustness under diverse adversarial image attacks. PDA performs prompt paraphrasing, question decomposition, and consistency aggregation entirely at test time, thus requiring no modification on the underlying models. To balance robustness and efficiency, we instantiate PDA as invariants that reduce the inference cost while retaining most of its robustness gains. Experiments on multiple VLM architectures and benchmarks for visual question answering, classification, and captioning show that PDA achieves consistent robustness gains against various adversarial perturbations while maintaining competitive clean accuracy, establishing a generic, strong and practical defense framework for VLMs during inference.
CPNet: Exploiting CLIP-based Attention Condenser and Probability Map Guidance for High-fidelity Talking Face Generation
May 23, 2023



Recently, talking face generation has drawn ever-increasing attention from the research community in computer vision due to its arduous challenges and widespread application scenarios, e.g. movie animation and virtual anchor. Although persevering efforts have been undertaken to enhance the fidelity and lip-sync quality of generated talking face videos, there is still large room for further improvements of synthesis quality and efficiency. Actually, these attempts somewhat ignore the explorations of fine-granularity feature extraction/integration and the consistency between probability distributions of landmarks, thereby recurring the issues of local details blurring and degraded fidelity. To mitigate these dilemmas, in this paper, a novel CLIP-based Attention and Probability Map Guided Network (CPNet) is delicately designed for inferring high-fidelity talking face videos. Specifically, considering the demands of fine-grained feature recalibration, a clip-based attention condenser is exploited to transfer knowledge with rich semantic priors from the prevailing CLIP model. Moreover, to guarantee the consistency in probability space and suppress the landmark ambiguity, we creatively propose the density map of facial landmark as auxiliary supervisory signal to guide the landmark distribution learning of generated frame. Extensive experiments on the widely-used benchmark dataset demonstrate the superiority of our CPNet against state of the arts in terms of image and lip-sync quality. In addition, a cohort of studies are also conducted to ablate the impacts of the individual pivotal components.
Towards Using Clothes Style Transfer for Scenario-aware Person Video Generation
Oct 25, 2021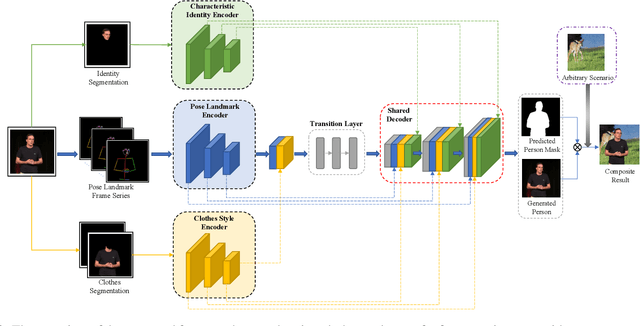
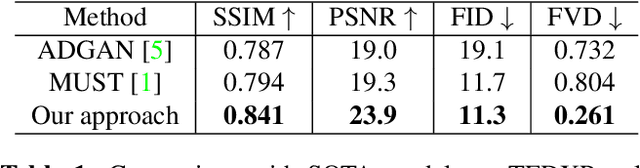
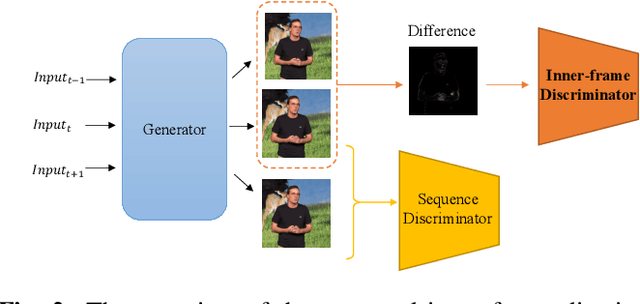
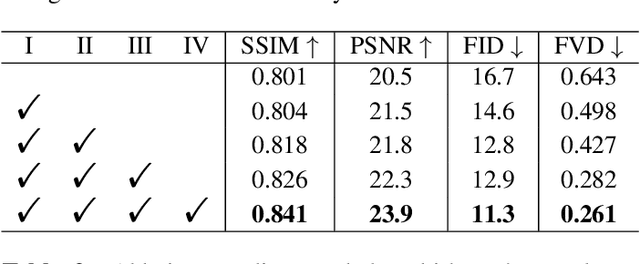
Clothes style transfer for person video generation is a challenging task, due to drastic variations of intra-person appearance and video scenarios. To tackle this problem, most recent AdaIN-based architectures are proposed to extract clothes and scenario features for generation. However, these approaches suffer from being short of fine-grained details and are prone to distort the origin person. To further improve the generation performance, we propose a novel framework with disentangled multi-branch encoders and a shared decoder. Moreover, to pursue the strong video spatio-temporal consistency, an inner-frame discriminator is delicately designed with input being cross-frame difference. Besides, the proposed framework possesses the property of scenario adaptation. Extensive experiments on the TEDXPeople benchmark demonstrate the superiority of our method over state-of-the-art approaches in terms of image quality and video coherence.