 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast and Real-time End to End Control in Autonomous Racing Cars Through Representation Learning
Nov 30, 2021
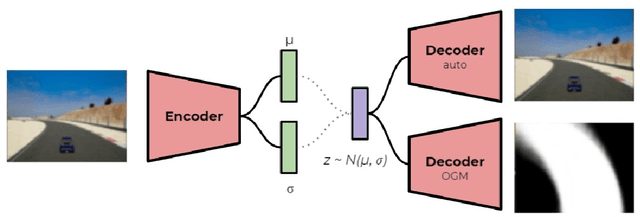

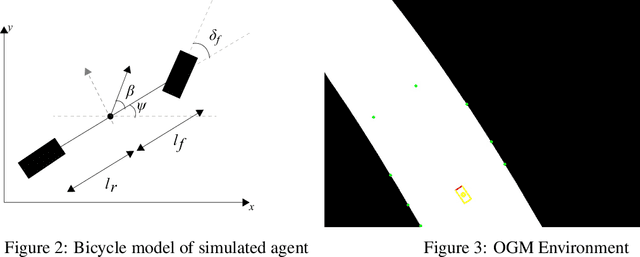
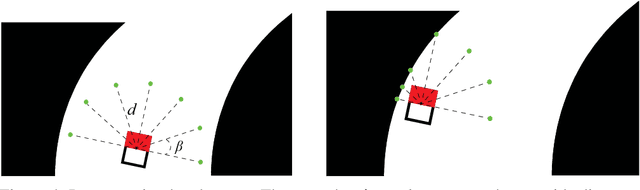
The challenges presented in an autonomous racing situation are distinct from those faced in regular autonomous driving and require faster end-to-end algorithms and consideration of a longer horizon in determining optimal current actions keeping in mind upcoming maneuvers and situations. In this paper, we propose an end-to-end method for autonomous racing that takes in as inputs video information from an onboard camera and determines final steering and throttle control actions. We use the following split to construct such a method (1) learning a low dimensional representation of the scene, (2) pre-generating the optimal trajectory for the given scene, and (3) tracking the predicted trajectory using a classical control method. In learning a low-dimensional representation of the scene, we use intermediate representations with a novel unsupervised trajectory planner to generate expert trajectories, and hence utilize them to directly predict race lines from a given front-facing input image. Thus, the proposed algorithm employs the best of two worlds - the robustness of learning-based approaches to perception and the accuracy of optimization-based approaches for trajectory generation in an end-to-end learning-based framework. We deploy and demonstrate our framework on CARLA, a photorealistic simulator for testing self-driving cars in realistic environments.
Learning ordered pooling weights in image classification
Jul 02, 2020


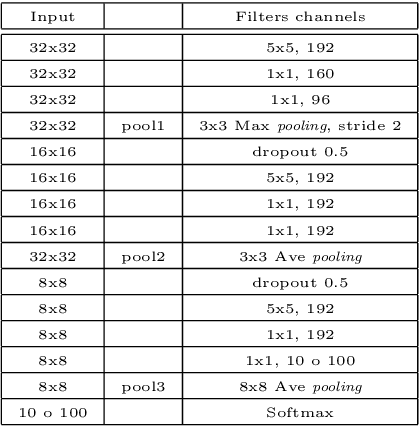
Spatial pooling is an important step in computer vision systems like Convolutional Neural Networks or the Bag-of-Words method. The spatial pooling purpose is to combine neighbouring descriptors to obtain a single descriptor for a given region (local or global). The resultant combined vector must be as discriminant as possible, in other words, must contain relevant information, while removing irrelevant and confusing details. Maximum and average are the most common aggregation functions used in the pooling step. To improve the aggregation of relevant information without degrading their discriminative power for image classification, we introduce a simple but effective scheme based on Ordered Weighted Average (OWA) aggregation operators. We present a method to learn the weights of the OWA aggregation operator in a Bag-of-Words framework and in Convolutional Neural Networks, and provide an extensive evaluation showing that OWA based pooling outperforms classical aggregation operators.
Single-Modal Entropy based Active Learning for Visual Question Answering
Nov 18, 2021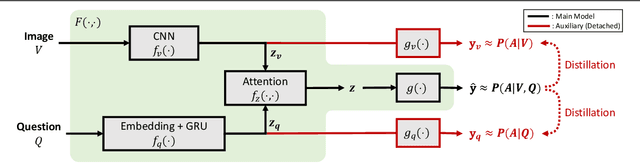
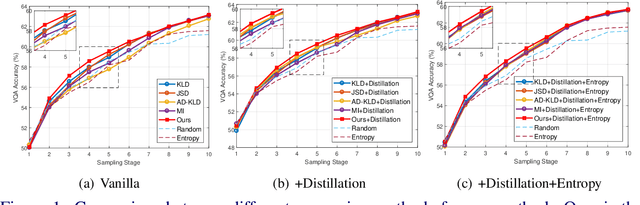
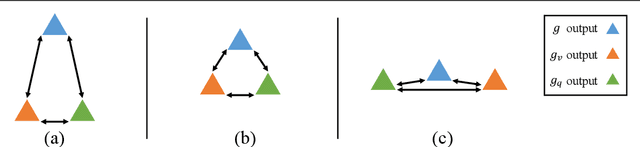
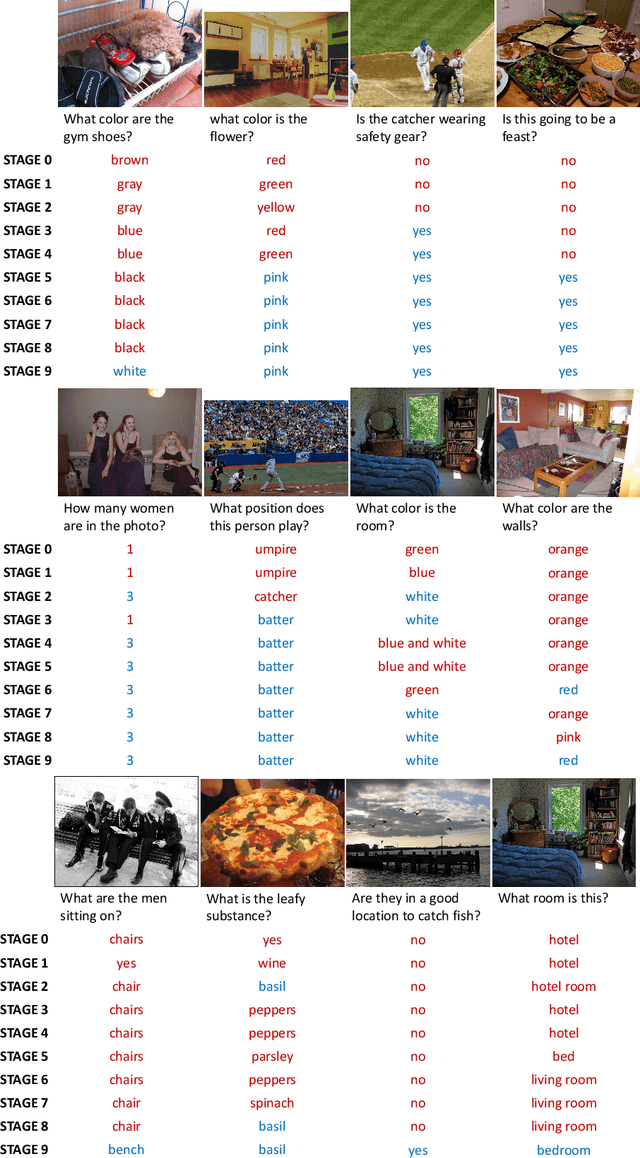
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.
Deep Learning for Fitness
Sep 03, 2021
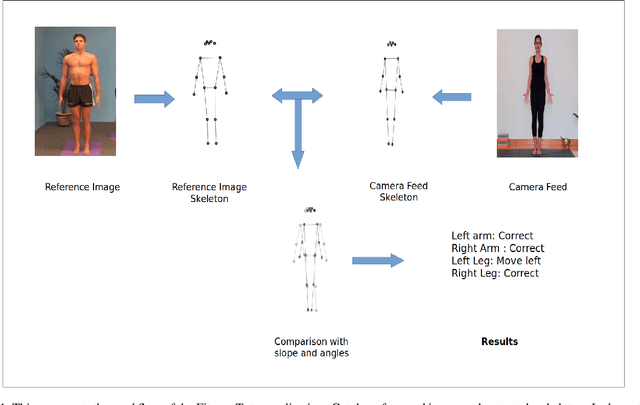

We present Fitness tutor, an application for maintaining correct posture during workout exercises or doing yoga. Current work on fitness focuses on suggesting food supplements, accessing workouts, workout wearables does a great job in improving the fitness. Meanwhile, the current situation is making difficult to monitor workouts by trainee. Inspired by healthcare innovations like robotic surgery, we design a novel application Fitness tutor which can guide the workouts using pose estimation. Pose estimation can be deployed on the reference image for gathering data and guide the user with the data. This allow Fitness tutor to guide the workouts (both exercise and yoga) in remote conditions with a single reference posture as image. We use posenet model in tensorflow with p5js for developing skeleton. Fitness tutor is an application of pose estimation model in bringing a realtime teaching experience in fitness. Our experiments shows that it can leverage potential of pose estimation models by providing guidance in realtime.
Medical Image Harmonization Using Deep Learning Based Canonical Mapping: Toward Robust and Generalizable Learning in Imaging
Oct 11, 2020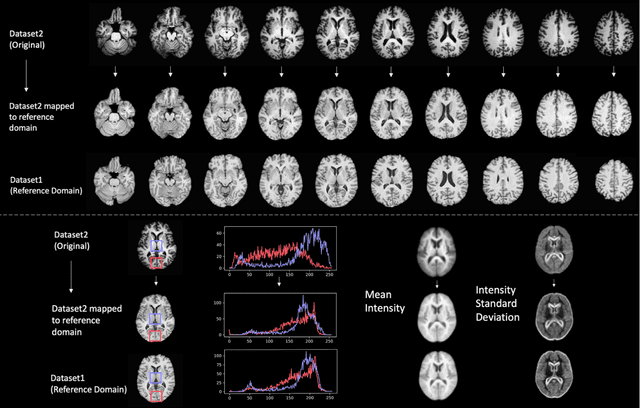

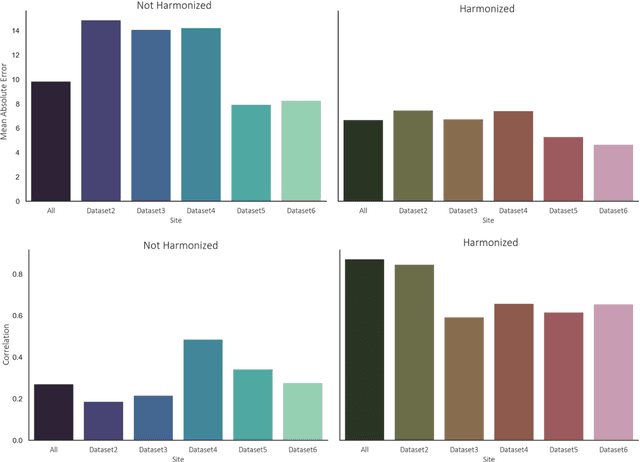
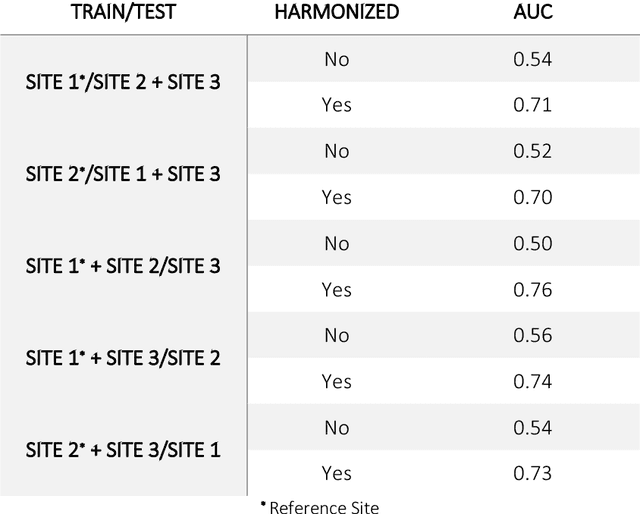
Conventional and deep learning-based methods have shown great potential in the medical imaging domain, as means for deriving diagnostic, prognostic, and predictive biomarkers, and by contributing to precision medicine. However, these methods have yet to see widespread clinical adoption, in part due to limited generalization performance across various imaging devices, acquisition protocols, and patient populations. In this work, we propose a new paradigm in which data from a diverse range of acquisition conditions are "harmonized" to a common reference domain, where accurate model learning and prediction can take place. By learning an unsupervised image to image canonical mapping from diverse datasets to a reference domain using generative deep learning models, we aim to reduce confounding data variation while preserving semantic information, thereby rendering the learning task easier in the reference domain. We test this approach on two example problems, namely MRI-based brain age prediction and classification of schizophrenia, leveraging pooled cohorts of neuroimaging MRI data spanning 9 sites and 9701 subjects. Our results indicate a substantial improvement in these tasks in out-of-sample data, even when training is restricted to a single site.
ImageCHD: A 3D Computed Tomography Image Dataset for Classification of Congenital Heart Disease
Jan 26, 2021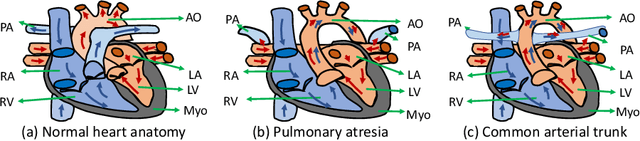
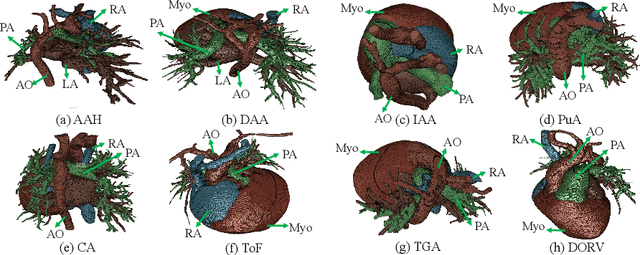
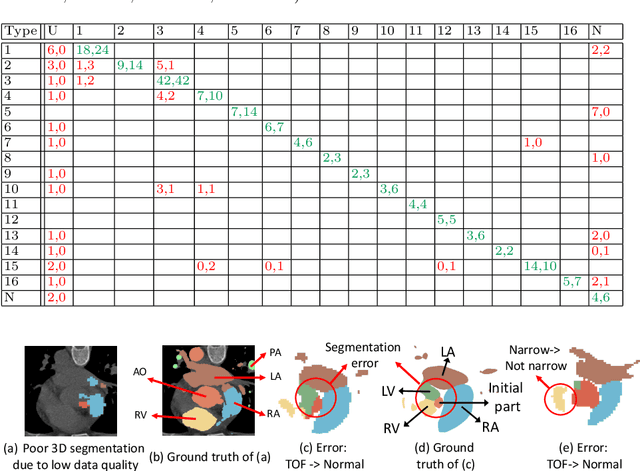
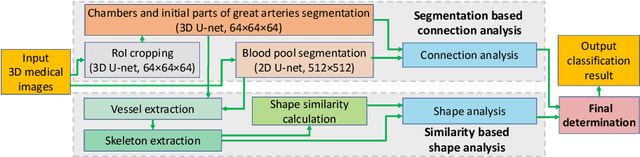
Congenital heart disease (CHD) is the most common type of birth defect, which occurs 1 in every 110 births in the United States. CHD usually comes with severe variations in heart structure and great artery connections that can be classified into many types. Thus highly specialized domain knowledge and the time-consuming human process is needed to analyze the associated medical images. On the other hand, due to the complexity of CHD and the lack of dataset, little has been explored on the automatic diagnosis (classification) of CHDs. In this paper, we present ImageCHD, the first medical image dataset for CHD classification. ImageCHD contains 110 3D Computed Tomography (CT) images covering most types of CHD, which is of decent size Classification of CHDs requires the identification of large structural changes without any local tissue changes, with limited data. It is an example of a larger class of problems that are quite difficult for current machine-learning-based vision methods to solve. To demonstrate this, we further present a baseline framework for the automatic classification of CHD, based on a state-of-the-art CHD segmentation method. Experimental results show that the baseline framework can only achieve a classification accuracy of 82.0\% under a selective prediction scheme with 88.4\% coverage, leaving big room for further improvement. We hope that ImageCHD can stimulate further research and lead to innovative and generic solutions that would have an impact in multiple domains. Our dataset is released to the public compared with existing medical imaging datasets.
Guided Generative Models using Weak Supervision for Detecting Object Spatial Arrangement in Overhead Images
Dec 10, 2021
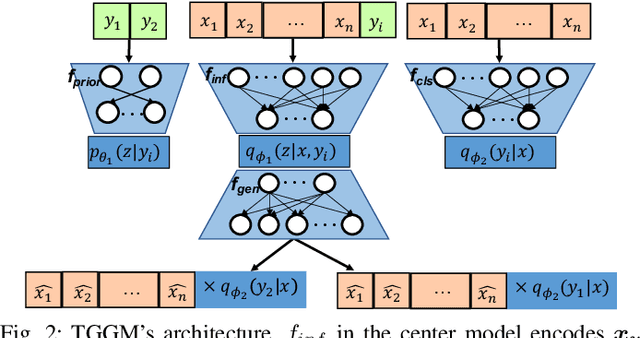
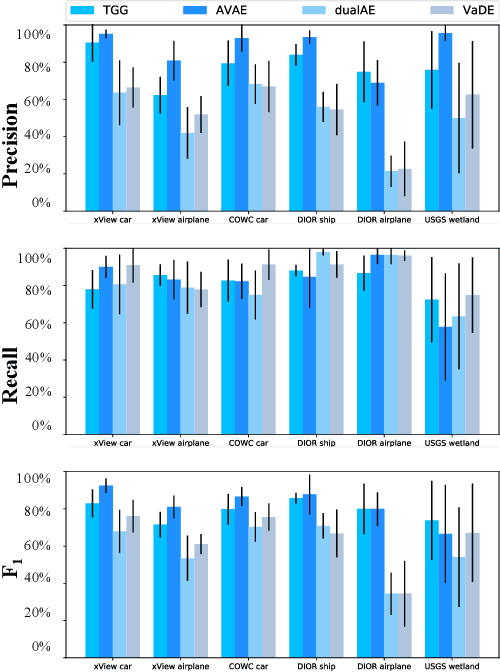

The increasing availability and accessibility of numerous overhead images allows us to estimate and assess the spatial arrangement of groups of geospatial target objects, which can benefit many applications, such as traffic monitoring and agricultural monitoring. Spatial arrangement estimation is the process of identifying the areas which contain the desired objects in overhead images. Traditional supervised object detection approaches can estimate accurate spatial arrangement but require large amounts of bounding box annotations. Recent semi-supervised clustering approaches can reduce manual labeling but still require annotations for all object categories in the image. This paper presents the target-guided generative model (TGGM), under the Variational Auto-encoder (VAE) framework, which uses Gaussian Mixture Models (GMM) to estimate the distributions of both hidden and decoder variables in VAE. Modeling both hidden and decoder variables by GMM reduces the required manual annotations significantly for spatial arrangement estimation. Unlike existing approaches that the training process can only update the GMM as a whole in the optimization iterations (e.g., a "minibatch"), TGGM allows the update of individual GMM components separately in the same optimization iteration. Optimizing GMM components separately allows TGGM to exploit the semantic relationships in spatial data and requires only a few labels to initiate and guide the generative process. Our experiments shows that TGGM achieves results comparable to the state-of-the-art semi-supervised methods and outperforms unsupervised methods by 10% based on the $F_{1}$ scores, while requiring significantly fewer labeled data.
Finding Original Image Of A Sub Image Using CNNs
Jun 21, 2018



Convolututional Neural Networks have achieved state of the art in image classification, object detection and other image related tasks. In this paper I present another use of CNNs i.e. if given a set of images and then giving a single test image the network identifies that the test image is part of which image from the images given before. This is a task somehow similar to measuring image similarity and can be done using a simple CNN. Doing this task manually by looping can be quite a time consuming problem and won't be a generalizable solution. The task is quite similar to doing object detection but for that lots training data should be given or in the case of sliding window it takes lot of time and my algorithm can work with much fewer examples, is totally unsupervised and works much efficiently. Also, I explain that how unsupervised algorithm like K-Means or supervised algorithm like K-NN are not good enough to perform this task. The basic idea is that image encodings are collected for each image from a CNN, when a test image comes it is replaced by a part of original image, the encoding is generated using the same network, the frobenius norm is calculated and if it comes under a tolerance level then the test image is said to be the part of the original image.
NAS-Bench-360: Benchmarking Diverse Tasks for Neural Architecture Search
Oct 16, 2021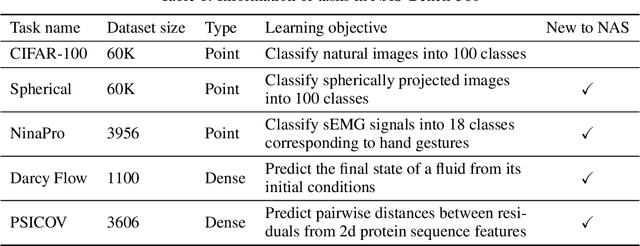
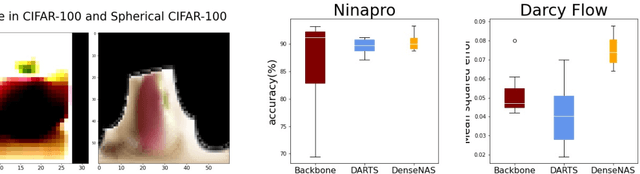
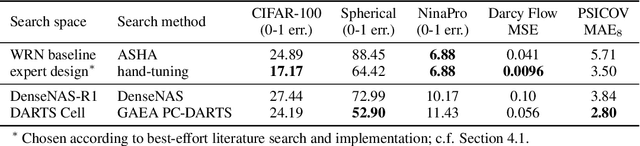
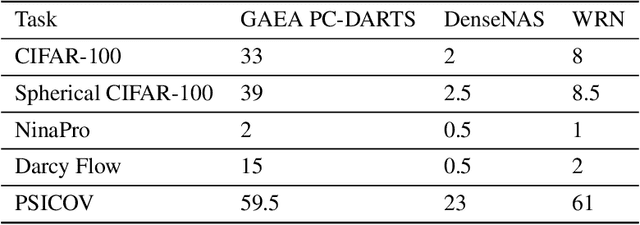
Most existing neural architecture search (NAS) benchmarks and algorithms prioritize performance on well-studied tasks, e.g., image classification on CIFAR and ImageNet. This makes the applicability of NAS approaches in more diverse areas inadequately understood. In this paper, we present NAS-Bench-360, a benchmark suite for evaluating state-of-the-art NAS methods for convolutional neural networks (CNNs). To construct it, we curate a collection of ten tasks spanning a diverse array of application domains, dataset sizes, problem dimensionalities, and learning objectives. By carefully selecting tasks that can both interoperate with modern CNN-based search methods but that are also far-afield from their original development domain, we can use NAS-Bench-360 to investigate the following central question: do existing state-of-the-art NAS methods perform well on diverse tasks? Our experiments show that a modern NAS procedure designed for image classification can indeed find good architectures for tasks with other dimensionalities and learning objectives; however, the same method struggles against more task-specific methods and performs catastrophically poorly on classification in non-vision domains. The case for NAS robustness becomes even more dire in a resource-constrained setting, where a recent NAS method provides little-to-no benefit over much simpler baselines. These results demonstrate the need for a benchmark such as NAS-Bench-360 to help develop NAS approaches that work well on a variety of tasks, a crucial component of a truly robust and automated pipeline. We conclude with a demonstration of the kind of future research our suite of tasks will enable. All data and code is made publicly available.
Volumetric Attention for 3D Medical Image Segmentation and Detection
Apr 04, 2020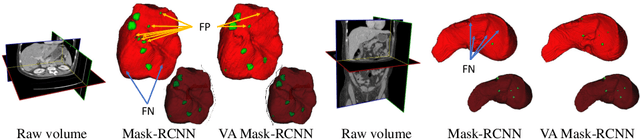
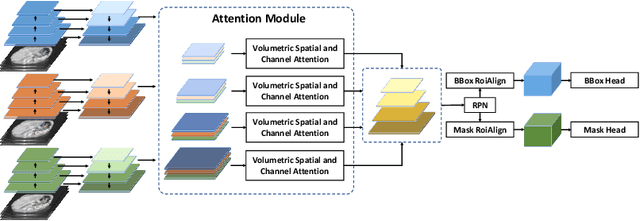
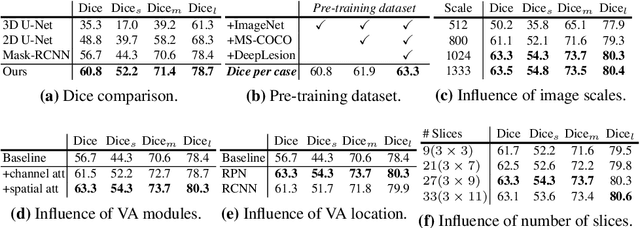
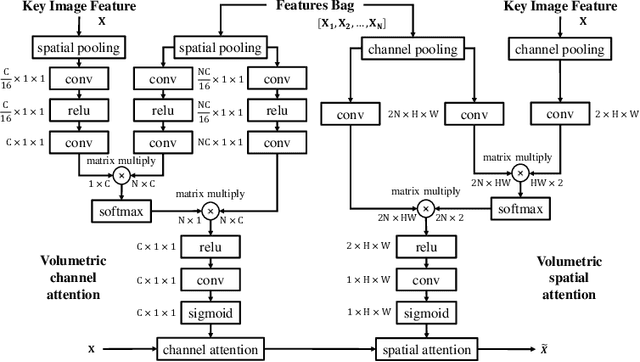
A volumetric attention(VA) module for 3D medical image segmentation and detection is proposed. VA attention is inspired by recent advances in video processing, enables 2.5D networks to leverage context information along the z direction, and allows the use of pretrained 2D detection models when training data is limited, as is often the case for medical applications. Its integration in the Mask R-CNN is shown to enable state-of-the-art performance on the Liver Tumor Segmentation (LiTS) Challenge, outperforming the previous challenge winner by 3.9 points and achieving top performance on the LiTS leader board at the time of paper submission. Detection experiments on the DeepLesion dataset also show that the addition of VA to existing object detectors enables a 69.1 sensitivity at 0.5 false positive per image, outperforming the best published results by 6.6 points.
* Accepted by MICCAI 2019