 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwritten image augmentation
Aug 26, 2023



In this paper, we introduce Handwritten augmentation, a new data augmentation for handwritten character images. This method focuses on augmenting handwritten image data by altering the shape of input characters in training. The proposed handwritten augmentation is similar to position augmentation, color augmentation for images but a deeper focus on handwritten characters. Handwritten augmentation is data-driven, easy to implement, and can be integrated with CNN-based optical character recognition models. Handwritten augmentation can be implemented along with commonly used data augmentation techniques such as cropping, rotating, and yields better performance of models for handwritten image datasets developed using optical character recognition methods.
Squeeze aggregated excitation network
Aug 25, 2023Convolutional neural networks have spatial representations which read patterns in the vision tasks. Squeeze and excitation links the channel wise representations by explicitly modeling on channel level. Multi layer perceptrons learn global representations and in most of the models it is used often at the end after all convolutional layers to gather all the information learned before classification. We propose a method of inducing the global representations within channels to have better performance of the model. We propose SaEnet, Squeeze aggregated excitation network, for learning global channelwise representation in between layers. The proposed module takes advantage of passing important information after squeeze by having aggregated excitation before regaining its shape. We also introduce a new idea of having a multibranch linear(dense) layer in the network. This learns global representations from the condensed information which enhances the representational power of the network. The proposed module have undergone extensive experiments by using Imagenet and CIFAR100 datasets and compared with closely related architectures. The analyzes results that proposed models outputs are comparable and in some cases better than existing state of the art architectures.
Memory visualization tool for training neural network
Oct 25, 2021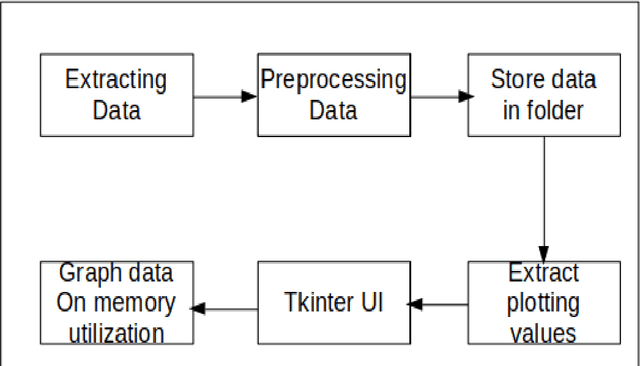
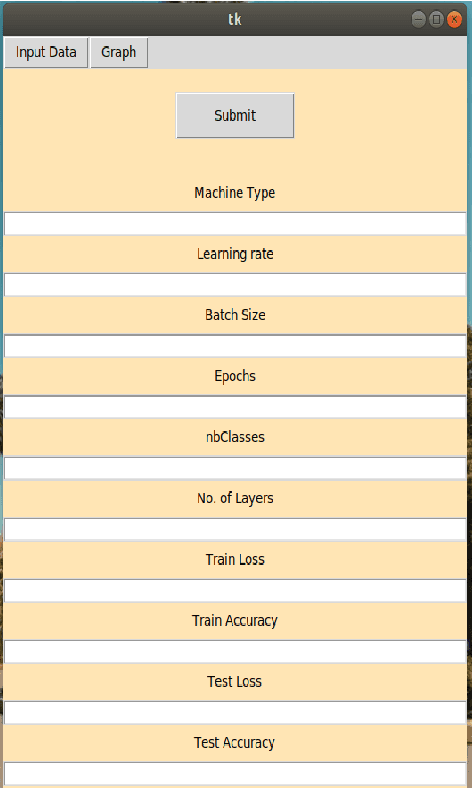
Software developed helps world a better place ranging from system software, open source, application software and so on. Software engineering does have neural network models applied to code suggestion, bug report summarizing and so on to demonstrate their effectiveness at a real SE task. Software and machine learning algorithms combine to make software give better solutions and understanding of environment. In software, there are both generalized applications which helps solve problems for entire world and also some specific applications which helps one particular community. To address the computational challenge in deep learning, many tools exploit hardware features such as multi-core CPUs and many-core GPUs to shorten the training time. Machine learning algorithms have a greater impact in the world but there is a considerable amount of memory utilization during the process. We propose a new tool for analysis of memory utilized for developing and training deep learning models. Our tool results in visual utilization of memory concurrently. Various parameters affecting the memory utilization are analysed while training. This tool helps in knowing better idea of processes or models which consumes more memory.
Analysis of memory consumption by neural networks based on hyperparameters
Oct 21, 2021



Deep learning models are trained and deployed in multiple domains. Increasing usage of deep learning models alarms the usage of memory consumed while computation by deep learning models. Existing approaches for reducing memory consumption like model compression, hardware changes are specific. We propose a generic analysis of memory consumption while training deep learning models in comparison with hyperparameters used for training. Hyperparameters which includes the learning rate, batchsize, number of hidden layers and depth of layers decide the model performance, accuracy of the model. We assume the optimizers and type of hidden layers as a known values. The change in hyperparamaters and the number of hidden layers are the variables considered in this proposed approach. For better understanding of the computation cost, this proposed analysis studies the change in memory consumption with respect to hyperparameters as main focus. This results in general analysis of memory consumption changes during training when set of hyperparameters are altered.
Deep Learning for Fitness
Sep 03, 2021
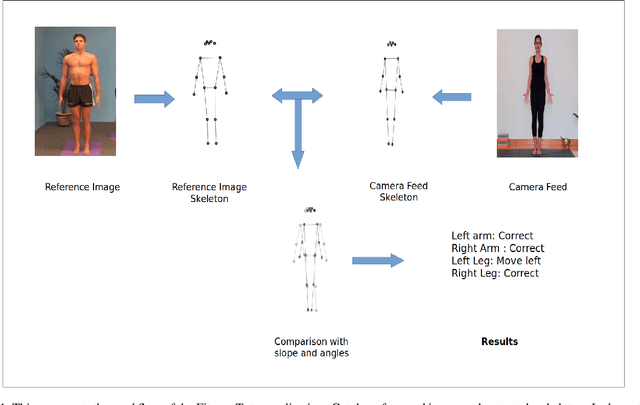
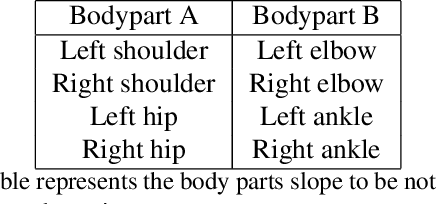

We present Fitness tutor, an application for maintaining correct posture during workout exercises or doing yoga. Current work on fitness focuses on suggesting food supplements, accessing workouts, workout wearables does a great job in improving the fitness. Meanwhile, the current situation is making difficult to monitor workouts by trainee. Inspired by healthcare innovations like robotic surgery, we design a novel application Fitness tutor which can guide the workouts using pose estimation. Pose estimation can be deployed on the reference image for gathering data and guide the user with the data. This allow Fitness tutor to guide the workouts (both exercise and yoga) in remote conditions with a single reference posture as image. We use posenet model in tensorflow with p5js for developing skeleton. Fitness tutor is an application of pose estimation model in bringing a realtime teaching experience in fitness. Our experiments shows that it can leverage potential of pose estimation models by providing guidance in realtime.