 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAPT: Attention Driven Adaptive Prompt Scheduling and InTerpolating Orthogonal Complements for Rare Concepts Generation
Mar 19, 2026Generating rare compositional concepts in text-to-image synthesis remains a challenge for diffusion models, particularly for attributes that are uncommon in the training data. While recent approaches, such as R2F, address this challenge by utilizing LLM for prompt scheduling, they suffer from inherent variance due to the randomness of language models and suboptimal guidance from iterative text embedding switching. To address these problems, we propose the ADAPT framework, a training-free framework that deterministically plans and semantically aligns prompt schedules, providing consistent guidance to enhance the composition of rare concepts. By leveraging attention scores and orthogonal components, ADAPT significantly enhances compositional generation of rare concepts in the RareBench benchmark without additional training or fine-tuning. Through comprehensive experiments, we demonstrate that ADAPT achieves superior performance in RareBench and accurately reflects the semantic information of rare attributes, providing deterministic and precise control over the generation of rare compositions without compromising visual integrity.
Adaptive Auxiliary Prompt Blending for Target-Faithful Diffusion Generation
Mar 19, 2026Diffusion-based text-to-image (T2I) models have made remarkable progress in generating photorealistic and semantically rich images. However, when the target concepts lie in low-density regions of the training distribution, these models often produce semantically misaligned or structurally inconsistent results. This limitation arises from the long-tailed nature of text-image datasets, where rare concepts or editing instructions are underrepresented. To address this, we introduce Adaptive Auxiliary Prompt Blending (AAPB) - a unified framework that stabilizes the diffusion process in low-density regions. AAPB leverages auxiliary anchor prompts to provide semantic support in rare concept generation and structural support in image editing, ensuring faithful guidance toward the target prompt. Unlike prior heuristic prompt alternation methods, AAPB derives a closed-form adaptive coefficient that optimally balances the influence between the auxiliary anchor and the target prompt at each diffusion step. Grounded in Tweedie's identity, our formulation provides a principled and training-free framework for adaptive prompt blending, ensuring stable and target-faithful generation. We demonstrate the effectiveness of adaptive interpolation over fixed interpolation through controlled experiments and empirically show consistent improvements on the RareBench and FlowEdit datasets, achieving superior semantic accuracy and structural fidelity compared to prior training-free baselines.
Follow the Saliency: Supervised Saliency for Retrieval-augmented Dense Video Captioning
Mar 12, 2026Existing retrieval-augmented approaches for Dense Video Captioning (DVC) often fail to achieve accurate temporal segmentation aligned with true event boundaries, as they rely on heuristic strategies that overlook ground truth event boundaries. The proposed framework, \textbf{STaRC}, overcomes this limitation by supervising frame-level saliency through a highlight detection module. Note that the highlight detection module is trained on binary labels derived directly from DVC ground truth annotations without the need for additional annotation. We also propose to utilize the saliency scores as a unified temporal signal that drives retrieval via saliency-guided segmentation and informs caption generation through explicit Saliency Prompts injected into the decoder. By enforcing saliency-constrained segmentation, our method produces temporally coherent segments that align closely with actual event transitions, leading to more accurate retrieval and contextually grounded caption generation. We conduct comprehensive evaluations on the YouCook2 and ViTT benchmarks, where STaRC achieves state-of-the-art performance across most of the metrics. Our code is available at https://github.com/ermitaju1/STaRC
SAIL: Similarity-Aware Guidance and Inter-Caption Augmentation-based Learning for Weakly-Supervised Dense Video Captioning
Mar 05, 2026Weakly-Supervised Dense Video Captioning aims to localize and describe events in videos trained only on caption annotations, without temporal boundaries. Prior work introduced an implicit supervision paradigm based on Gaussian masking and complementary captioning. However, existing method focuses merely on generating non-overlapping masks without considering their semantic relationship to corresponding events, resulting in simplistic, uniformly distributed masks that fail to capture semantically meaningful regions. Moreover, relying solely on ground-truth captions leads to sub-optimal performance due to the inherent sparsity of existing datasets. In this work, we propose SAIL, which constructs semantically-aware masks through cross-modal alignment. Our similarity aware training objective guides masks to emphasize video regions with high similarity to their corresponding event captions. Furthermore, to guide more accurate mask generation under sparse annotation settings, we introduce an LLM-based augmentation strategy that generates synthetic captions to provide additional alignment signals. These synthetic captions are incorporated through an inter-mask mechanism, providing auxiliary guidance for precise temporal localization without degrading the main objective. Experiments on ActivityNet Captions and YouCook2 demonstrate state-of-the-art performance on both captioning and localization metrics.
ScaleDiff: Higher-Resolution Image Synthesis via Efficient and Model-Agnostic Diffusion
Oct 29, 2025



Text-to-image diffusion models often exhibit degraded performance when generating images beyond their training resolution. Recent training-free methods can mitigate this limitation, but they often require substantial computation or are incompatible with recent Diffusion Transformer models. In this paper, we propose ScaleDiff, a model-agnostic and highly efficient framework for extending the resolution of pretrained diffusion models without any additional training. A core component of our framework is Neighborhood Patch Attention (NPA), an efficient mechanism that reduces computational redundancy in the self-attention layer with non-overlapping patches. We integrate NPA into an SDEdit pipeline and introduce Latent Frequency Mixing (LFM) to better generate fine details. Furthermore, we apply Structure Guidance to enhance global structure during the denoising process. Experimental results demonstrate that ScaleDiff achieves state-of-the-art performance among training-free methods in terms of both image quality and inference speed on both U-Net and Diffusion Transformer architectures.
Sali4Vid: Saliency-Aware Video Reweighting and Adaptive Caption Retrieval for Dense Video Captioning
Sep 04, 2025
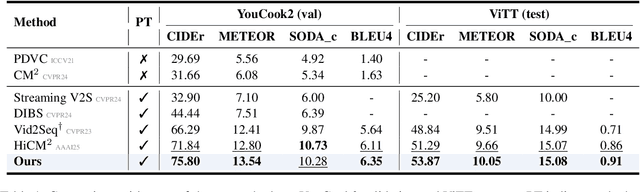
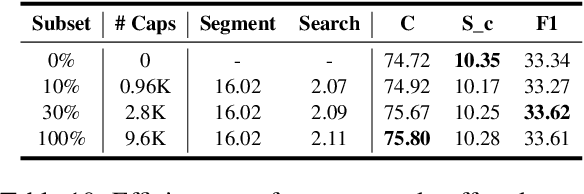
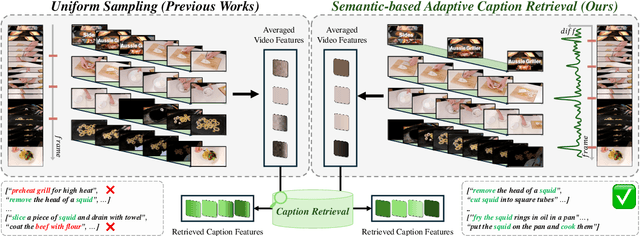
Dense video captioning aims to temporally localize events in video and generate captions for each event. While recent works propose end-to-end models, they suffer from two limitations: (1) applying timestamp supervision only to text while treating all video frames equally, and (2) retrieving captions from fixed-size video chunks, overlooking scene transitions. To address these, we propose Sali4Vid, a simple yet effective saliency-aware framework. We introduce Saliency-aware Video Reweighting, which converts timestamp annotations into sigmoid-based frame importance weights, and Semantic-based Adaptive Caption Retrieval, which segments videos by frame similarity to capture scene transitions and improve caption retrieval. Sali4Vid achieves state-of-the-art results on YouCook2 and ViTT, demonstrating the benefit of jointly improving video weighting and retrieval for dense video captioning
SIDA: Synthetic Image Driven Zero-shot Domain Adaptation
Jul 24, 2025



Zero-shot domain adaptation is a method for adapting a model to a target domain without utilizing target domain image data. To enable adaptation without target images, existing studies utilize CLIP's embedding space and text description to simulate target-like style features. Despite the previous achievements in zero-shot domain adaptation, we observe that these text-driven methods struggle to capture complex real-world variations and significantly increase adaptation time due to their alignment process. Instead of relying on text descriptions, we explore solutions leveraging image data, which provides diverse and more fine-grained style cues. In this work, we propose SIDA, a novel and efficient zero-shot domain adaptation method leveraging synthetic images. To generate synthetic images, we first create detailed, source-like images and apply image translation to reflect the style of the target domain. We then utilize the style features of these synthetic images as a proxy for the target domain. Based on these features, we introduce Domain Mix and Patch Style Transfer modules, which enable effective modeling of real-world variations. In particular, Domain Mix blends multiple styles to expand the intra-domain representations, and Patch Style Transfer assigns different styles to individual patches. We demonstrate the effectiveness of our method by showing state-of-the-art performance in diverse zero-shot adaptation scenarios, particularly in challenging domains. Moreover, our approach achieves high efficiency by significantly reducing the overall adaptation time.
SynC: Synthetic Image Caption Dataset Refinement with One-to-many Mapping for Zero-shot Image Captioning
Jul 24, 2025



Zero-shot Image Captioning (ZIC) increasingly utilizes synthetic datasets generated by text-to-image (T2I) models to mitigate the need for costly manual annotation. However, these T2I models often produce images that exhibit semantic misalignments with their corresponding input captions (e.g., missing objects, incorrect attributes), resulting in noisy synthetic image-caption pairs that can hinder model training. Existing dataset pruning techniques are largely designed for removing noisy text in web-crawled data. However, these methods are ill-suited for the distinct challenges of synthetic data, where captions are typically well-formed, but images may be inaccurate representations. To address this gap, we introduce SynC, a novel framework specifically designed to refine synthetic image-caption datasets for ZIC. Instead of conventional filtering or regeneration, SynC focuses on reassigning captions to the most semantically aligned images already present within the synthetic image pool. Our approach employs a one-to-many mapping strategy by initially retrieving multiple relevant candidate images for each caption. We then apply a cycle-consistency-inspired alignment scorer that selects the best image by verifying its ability to retrieve the original caption via image-to-text retrieval. Extensive evaluations demonstrate that SynC consistently and significantly improves performance across various ZIC models on standard benchmarks (MS-COCO, Flickr30k, NoCaps), achieving state-of-the-art results in several scenarios. SynC offers an effective strategy for curating refined synthetic data to enhance ZIC.
VerbDiff: Text-Only Diffusion Models with Enhanced Interaction Awareness
Mar 20, 2025



Recent large-scale text-to-image diffusion models generate photorealistic images but often struggle to accurately depict interactions between humans and objects due to their limited ability to differentiate various interaction words. In this work, we propose VerbDiff to address the challenge of capturing nuanced interactions within text-to-image diffusion models. VerbDiff is a novel text-to-image generation model that weakens the bias between interaction words and objects, enhancing the understanding of interactions. Specifically, we disentangle various interaction words from frequency-based anchor words and leverage localized interaction regions from generated images to help the model better capture semantics in distinctive words without extra conditions. Our approach enables the model to accurately understand the intended interaction between humans and objects, producing high-quality images with accurate interactions aligned with specified verbs. Extensive experiments on the HICO-DET dataset demonstrate the effectiveness of our method compared to previous approaches.
LensNet: Enhancing Real-time Microlensing Event Discovery with Recurrent Neural Networks in the Korea Microlensing Telescope Network
Jan 10, 2025Traditional microlensing event vetting methods require highly trained human experts, and the process is both complex and time-consuming. This reliance on manual inspection often leads to inefficiencies and constrains the ability to scale for widespread exoplanet detection, ultimately hindering discovery rates. To address the limits of traditional microlensing event vetting, we have developed LensNet, a machine learning pipeline specifically designed to distinguish legitimate microlensing events from false positives caused by instrumental artifacts, such as pixel bleed trails and diffraction spikes. Our system operates in conjunction with a preliminary algorithm that detects increasing trends in flux. These flagged instances are then passed to LensNet for further classification, allowing for timely alerts and follow-up observations. Tailored for the multi-observatory setup of the Korea Microlensing Telescope Network (KMTNet) and trained on a rich dataset of manually classified events, LensNet is optimized for early detection and warning of microlensing occurrences, enabling astronomers to organize follow-up observations promptly. The internal model of the pipeline employs a multi-branch Recurrent Neural Network (RNN) architecture that evaluates time-series flux data with contextual information, including sky background, the full width at half maximum of the target star, flux errors, PSF quality flags, and air mass for each observation. We demonstrate a classification accuracy above 87.5%, and anticipate further improvements as we expand our training set and continue to refine the algorithm.