 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-supervised Task-driven Data Augmentation for Medical Image Segmentation
Jul 09, 2020
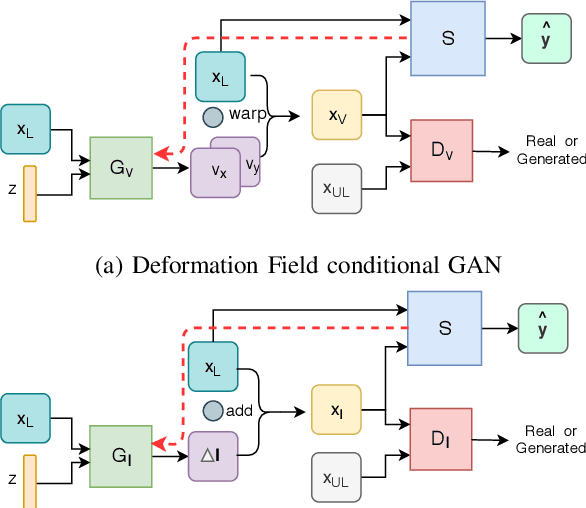
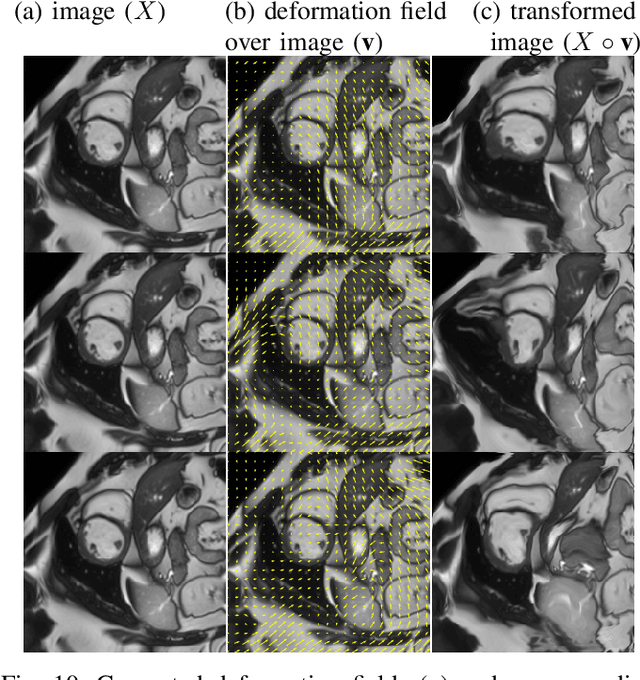
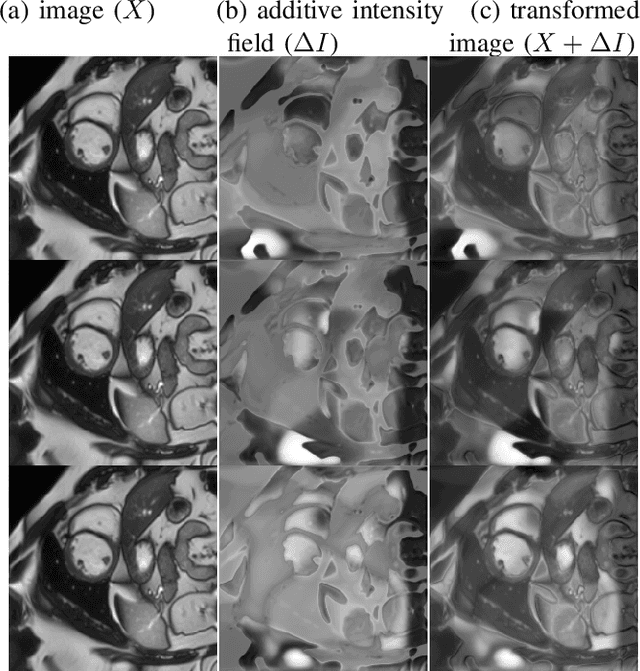
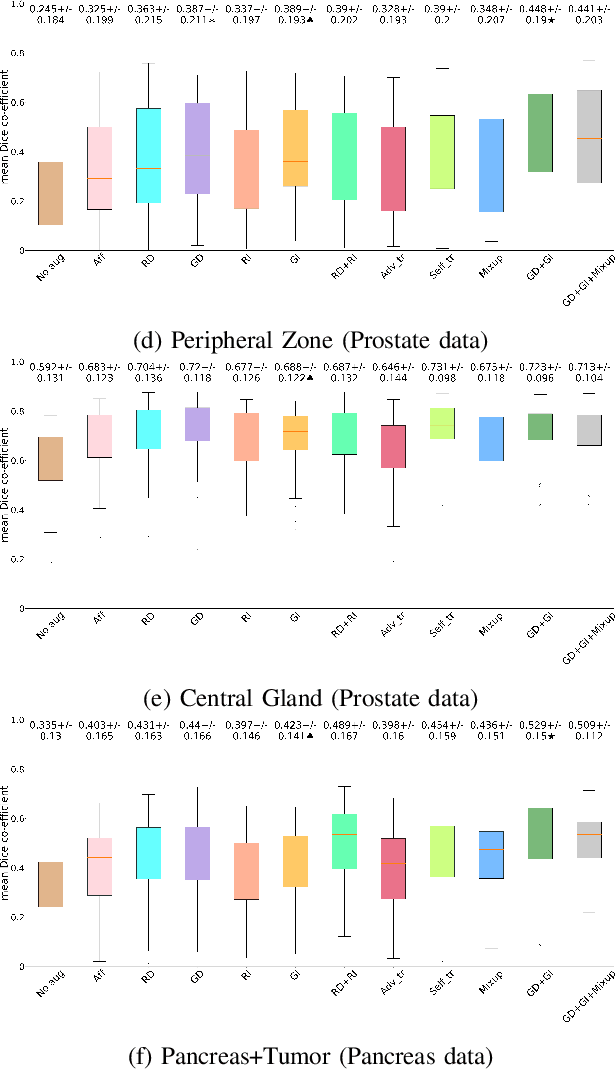
Supervised learning-based segmentation methods typically require a large number of annotated training data to generalize well at test time. In medical applications, curating such datasets is not a favourable option because acquiring a large number of annotated samples from experts is time-consuming and expensive. Consequently, numerous methods have been proposed in the literature for learning with limited annotated examples. Unfortunately, the proposed approaches in the literature have not yet yielded significant gains over random data augmentation for image segmentation, where random augmentations themselves do not yield high accuracy. In this work, we propose a novel task-driven data augmentation method for learning with limited labeled data where the synthetic data generator, is optimized for the segmentation task. The generator of the proposed method models intensity and shape variations using two sets of transformations, as additive intensity transformations and deformation fields. Both transformations are optimized using labeled as well as unlabeled examples in a semi-supervised framework. Our experiments on three medical datasets, namely cardic, prostate and pancreas, show that the proposed approach significantly outperforms standard augmentation and semi-supervised approaches for image segmentation in the limited annotation setting. The code is made publicly available at https://github.com/krishnabits001/task$\_$driven$\_$data$\_$augmentation.
Feature Identification and Matching for Hand Hygiene Pose
Aug 14, 2021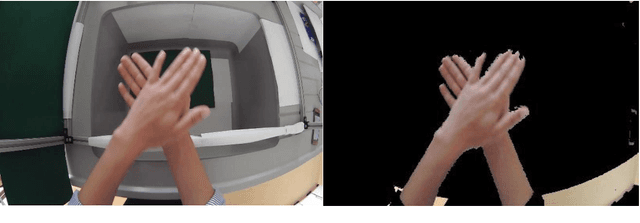
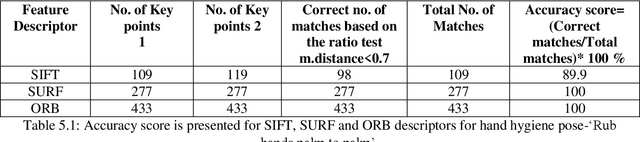


Three popular feature descriptors of computer vision such as SIFT, SURF, and ORB compared and evaluated. The number of correct features extracted and matched for the original hand hygiene pose-Rub hands palm to palm image and rotated image. An accuracy score calculated based on the total number of matches and the correct number of matches produced. The experiment demonstrated that ORB algorithm outperforms by giving the high number of correct matches in less amount of time. ORB feature detection technique applied over handwashing video recordings for feature extraction and hand hygiene pose classification as a future work. OpenCV utilized to apply the algorithms within python scripts.
ProxyFL: Decentralized Federated Learning through Proxy Model Sharing
Nov 22, 2021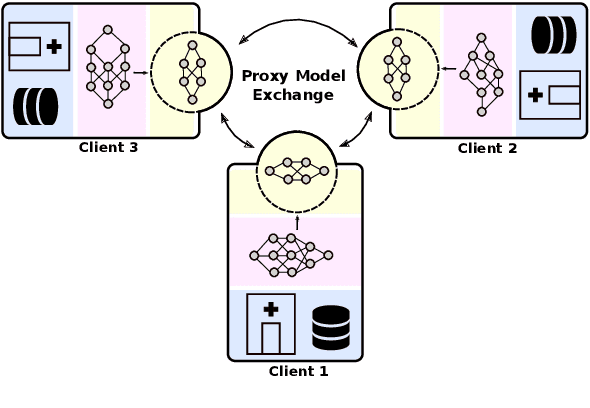
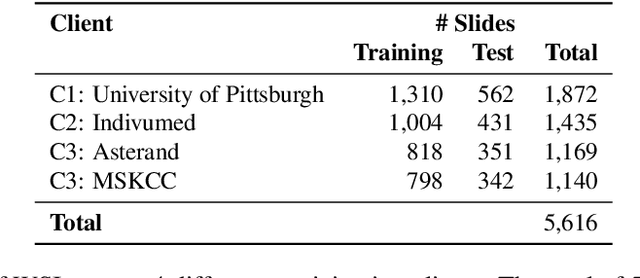
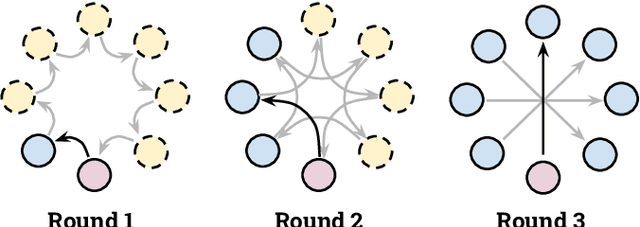
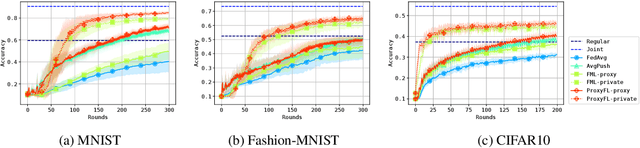
Institutions in highly regulated domains such as finance and healthcare often have restrictive rules around data sharing. Federated learning is a distributed learning framework that enables multi-institutional collaborations on decentralized data with improved protection for each collaborator's data privacy. In this paper, we propose a communication-efficient scheme for decentralized federated learning called ProxyFL, or proxy-based federated learning. Each participant in ProxyFL maintains two models, a private model, and a publicly shared proxy model designed to protect the participant's privacy. Proxy models allow efficient information exchange among participants using the PushSum method without the need of a centralized server. The proposed method eliminates a significant limitation of canonical federated learning by allowing model heterogeneity; each participant can have a private model with any architecture. Furthermore, our protocol for communication by proxy leads to stronger privacy guarantees using differential privacy analysis. Experiments on popular image datasets, and a pan-cancer diagnostic problem using over 30,000 high-quality gigapixel histology whole slide images, show that ProxyFL can outperform existing alternatives with much less communication overhead and stronger privacy.
Using Deep Learning for Visual Decoding and Reconstruction from Brain Activity: A Review
Aug 09, 2021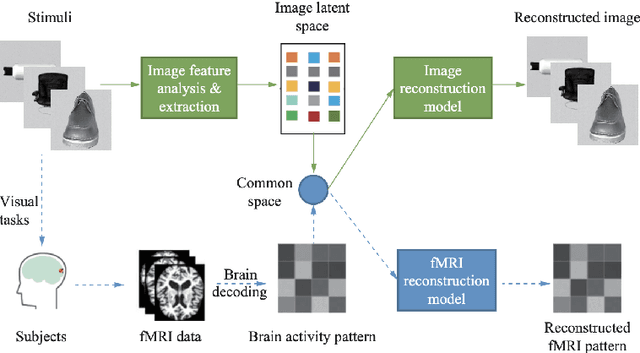
This literature review will discuss the use of deep learning methods for image reconstruction using fMRI data. More specifically, the quality of image reconstruction will be determined by the choice in decoding and reconstruction architectures. I will show that these structures can struggle with adaptability to various input stimuli due to complicated objects in images. Also, the significance of feature representation will be evaluated. This paper will conclude the use of deep learning within visual decoding and reconstruction is highly optimal when using variations of deep neural networks and will provide details of potential future work.
Turning old models fashion again: Recycling classical CNN networks using the Lattice Transformation
Sep 28, 2021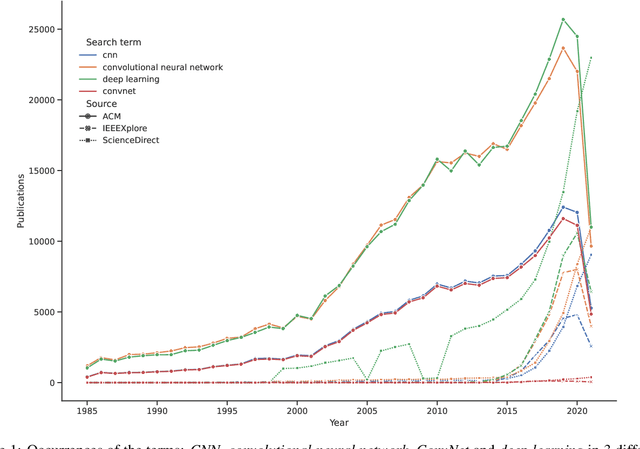
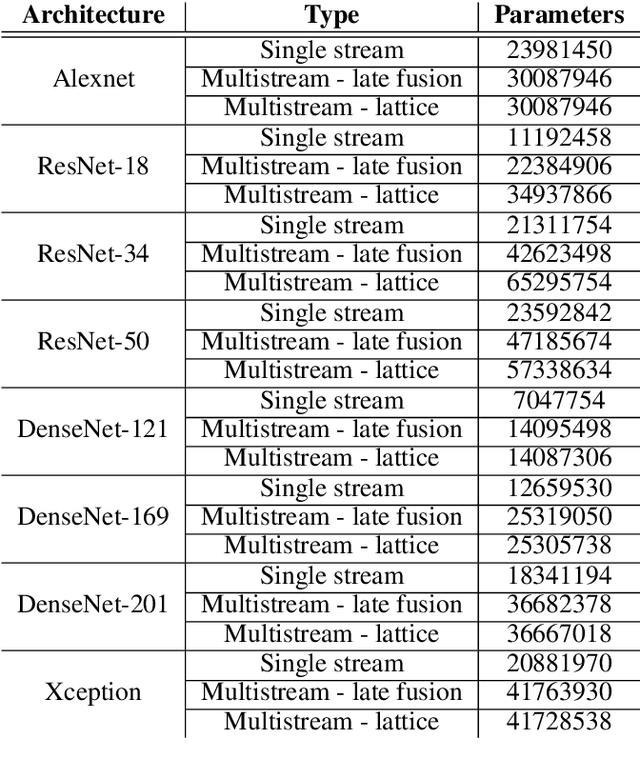
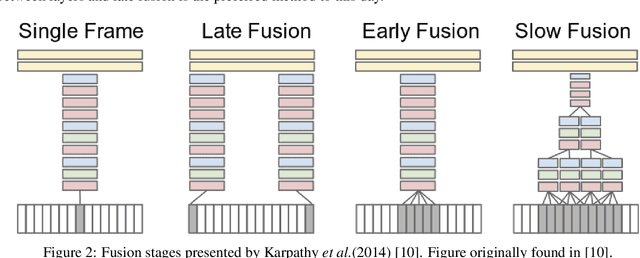
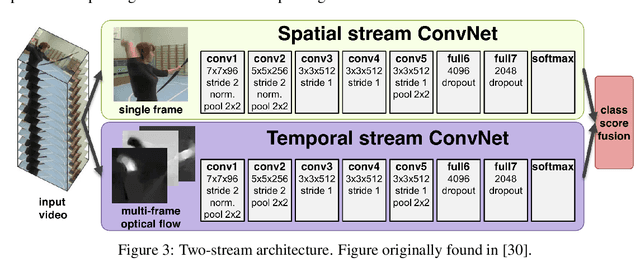
In the early 1990s, the first signs of life of the CNN era were given: LeCun et al. proposed a CNN model trained by the backpropagation algorithm to classify low-resolution images of handwritten digits. Undoubtedly, it was a breakthrough in the field of computer vision. But with the rise of other classification methods, it fell out fashion. That was until 2012, when Krizhevsky et al. revived the interest in CNNs by exhibiting considerably higher image classification accuracy on the ImageNet challenge. Since then, the complexity of the architectures are exponentially increasing and many structures are rapidly becoming obsolete. Using multistream networks as a base and the feature infusion precept, we explore the proposed LCNN cross-fusion strategy to use the backbones of former state-of-the-art networks on image classification in order to discover if the technique is able to put these designs back in the game. In this paper, we showed that we can obtain an increase of accuracy up to 63.21% on the NORB dataset we comparing with the original structure. However, no technique is definitive. While our goal is to try to reuse previous state-of-the-art architectures with few modifications, we also expose the disadvantages of our explored strategy.
Image compression optimized for 3D reconstruction by utilizing deep neural networks
Mar 27, 2020
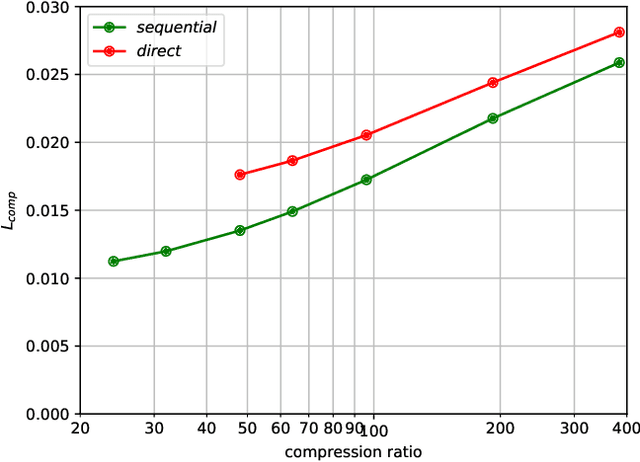
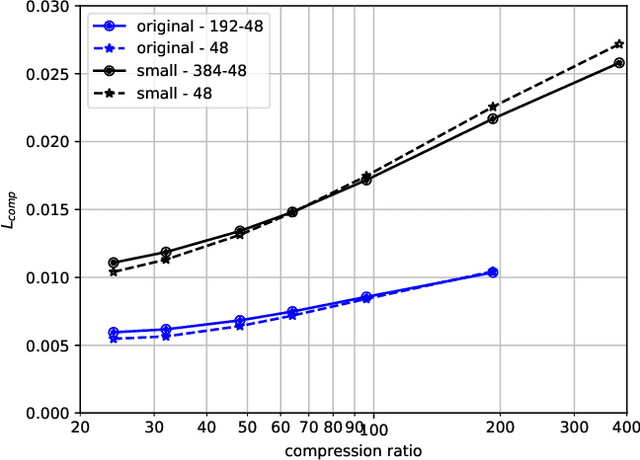
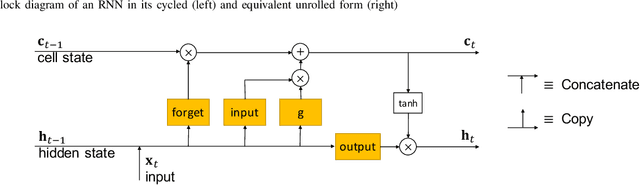
Computer vision tasks are often expected to be executed on compressed images. Classical image compression standards like JPEG 2000 are widely used. However, they do not account for the specific end-task at hand. Motivated by works on recurrent neural network (RNN)-based image compression and three-dimensional (3D) reconstruction, we propose unified network architectures to solve both tasks jointly. These joint models provide image compression tailored for the specific task of 3D reconstruction. Images compressed by our proposed models, yield 3D reconstruction performance superior as compared to using JPEG 2000 compression. Our models significantly extend the range of compression rates for which 3D reconstruction is possible. We also show that this can be done highly efficiently at almost no additional cost to obtain compression on top of the computation already required for performing the 3D reconstruction task.
Deep Relighting Networks for Image Light Source Manipulation
Aug 19, 2020

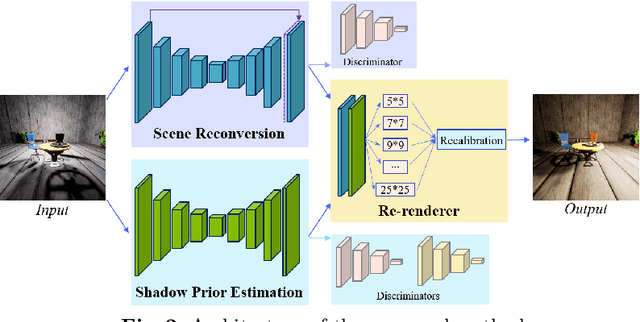
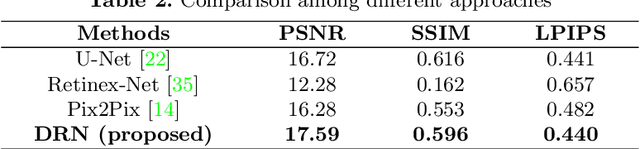
Manipulating the light source of given images is an interesting task and useful in various applications, including photography and cinematography. Existing methods usually require additional information like the geometric structure of the scene, which may not be available for most images. In this paper, we formulate the single image relighting task and propose a novel Deep Relighting Network (DRN) with three parts: 1) scene reconversion, which aims to reveal the primary scene structure through a deep auto-encoder network, 2) shadow prior estimation, to predict light effect from the new light direction through adversarial learning, and 3) re-renderer, to combine the primary structure with the reconstructed shadow view to form the required estimation under the target light source. Experimental results show that the proposed method outperforms other possible methods, both qualitatively and quantitatively. Specifically, the proposed DRN has achieved the best PSNR in the "AIM2020 - Any to one relighting challenge" of the 2020 ECCV conference.
SPViT: Enabling Faster Vision Transformers via Soft Token Pruning
Dec 27, 2021

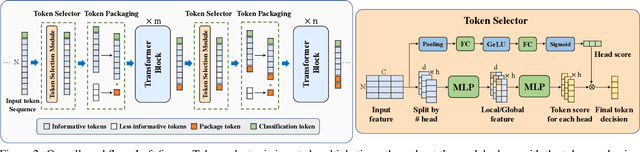
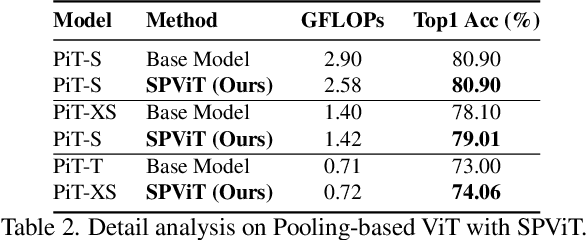
Recently, Vision Transformer (ViT) has continuously established new milestones in the computer vision field, while the high computation and memory cost makes its propagation in industrial production difficult. Pruning, a traditional model compression paradigm for hardware efficiency, has been widely applied in various DNN structures. Nevertheless, it stays ambiguous on how to perform exclusive pruning on the ViT structure. Considering three key points: the structural characteristics, the internal data pattern of ViTs, and the related edge device deployment, we leverage the input token sparsity and propose a computation-aware soft pruning framework, which can be set up on vanilla Transformers of both flatten and CNN-type structures, such as Pooling-based ViT (PiT). More concretely, we design a dynamic attention-based multi-head token selector, which is a lightweight module for adaptive instance-wise token selection. We further introduce a soft pruning technique, which integrates the less informative tokens generated by the selector module into a package token that will participate in subsequent calculations rather than being completely discarded. Our framework is bound to the trade-off between accuracy and computation constraints of specific edge devices through our proposed computation-aware training strategy. Experimental results show that our framework significantly reduces the computation cost of ViTs while maintaining comparable performance on image classification. Moreover, our framework can guarantee the identified model to meet resource specifications of mobile devices and FPGA, and even achieve the real-time execution of DeiT-T on mobile platforms. For example, our method reduces the latency of DeiT-T to 26 ms (26%$\sim $41% superior to existing works) on the mobile device with 0.25%$\sim $4% higher top-1 accuracy on ImageNet. Our code will be released soon.
A deep learned nanowire segmentation model using synthetic data augmentation
Sep 28, 2021
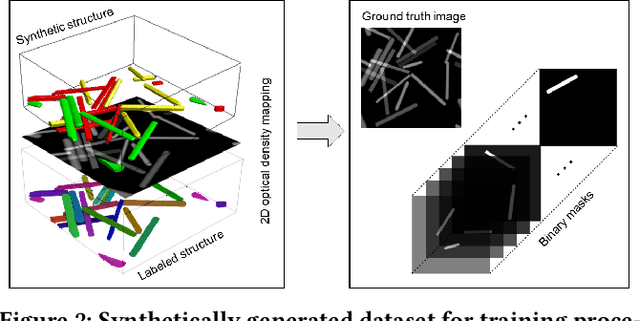
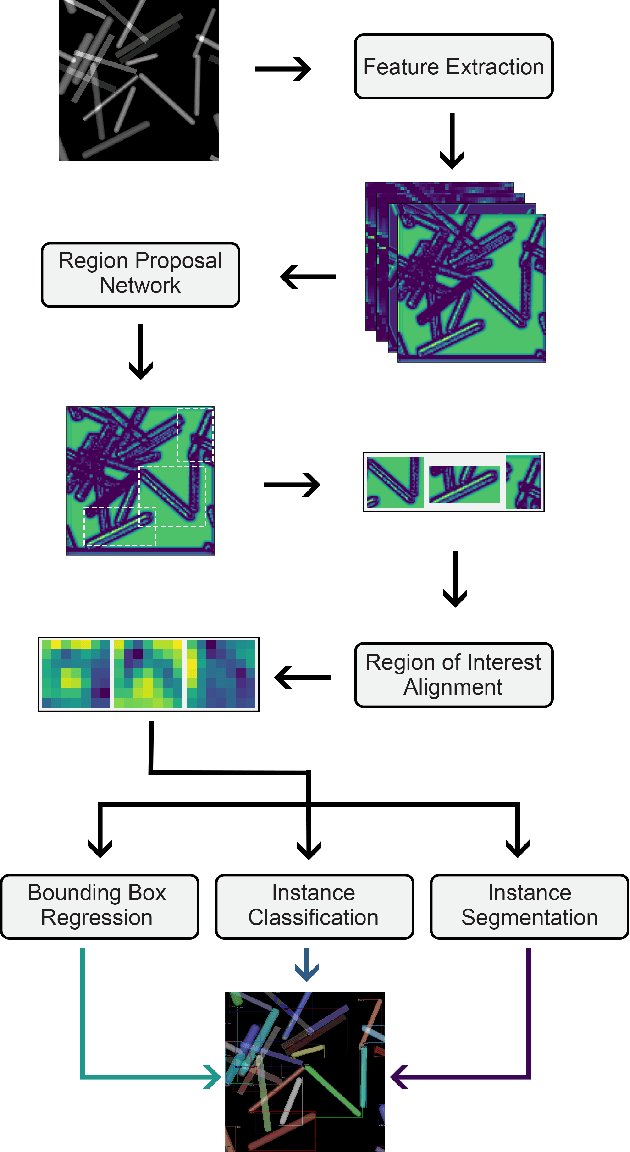
Automatized object identification and feature analysis of experimental image data are indispensable for data-driven material science; deep-learning-based segmentation algorithms have been shown to be a promising technique to achieve this goal. However, acquiring high-resolution experimental images and assigning labels in order to train such algorithms is challenging and costly in terms of both time and labor. In the present work, we apply synthetic images, which resemble the experimental image data in terms of geometrical and visual features, to train state-of-art deep learning-based Mask R-CNN algorithms to segment vanadium pentoxide (V2O5) nanowires, a canonical cathode material, within optical intensity-based images from spectromicroscopy. The performance evaluation demonstrates that even though the deep learning model is trained on pure synthetically generated structures, it can segment real optical intensity-based spectromicroscopy images of complex V2O5 nanowire structures in overlapped particle networks, thus providing reliable statistical information. The model can further be used to segment nanowires in scanning electron microscopy (SEM) images, which are fundamentally different from the training dataset known to the model. The proposed methodology of using a purely synthetic dataset to train the deep learning model can be extended to any optical intensity-based images of variable particle morphology, extent of agglomeration, material class, and beyond.
NudgeSeg: Zero-Shot Object Segmentation by Repeated Physical Interaction
Sep 22, 2021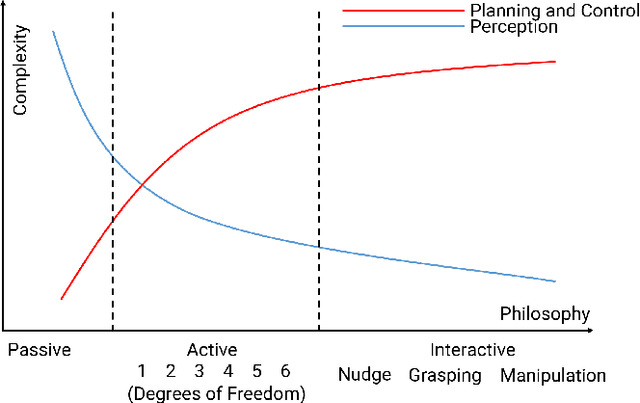
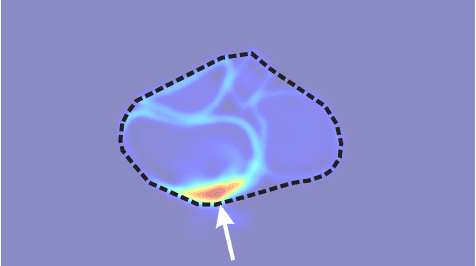
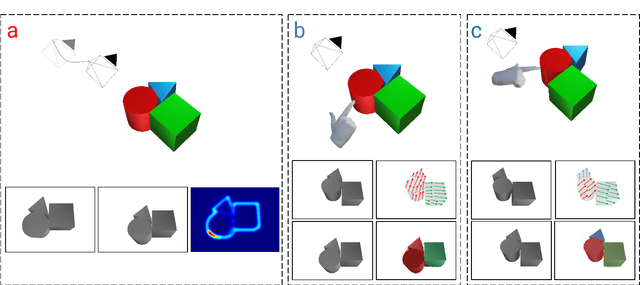

Recent advances in object segmentation have demonstrated that deep neural networks excel at object segmentation for specific classes in color and depth images. However, their performance is dictated by the number of classes and objects used for training, thereby hindering generalization to never seen objects or zero-shot samples. To exacerbate the problem further, object segmentation using image frames rely on recognition and pattern matching cues. Instead, we utilize the 'active' nature of a robot and their ability to 'interact' with the environment to induce additional geometric constraints for segmenting zero-shot samples. In this paper, we present the first framework to segment unknown objects in a cluttered scene by repeatedly 'nudging' at the objects and moving them to obtain additional motion cues at every step using only a monochrome monocular camera. We call our framework NudgeSeg. These motion cues are used to refine the segmentation masks. We successfully test our approach to segment novel objects in various cluttered scenes and provide an extensive study with image and motion segmentation methods. We show an impressive average detection rate of over 86% on zero-shot objects.
* 8 Pages, 7 Figures, 3 Tables