 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-aware multimodal page classification of Brazilian legal documents
Jul 15, 2022
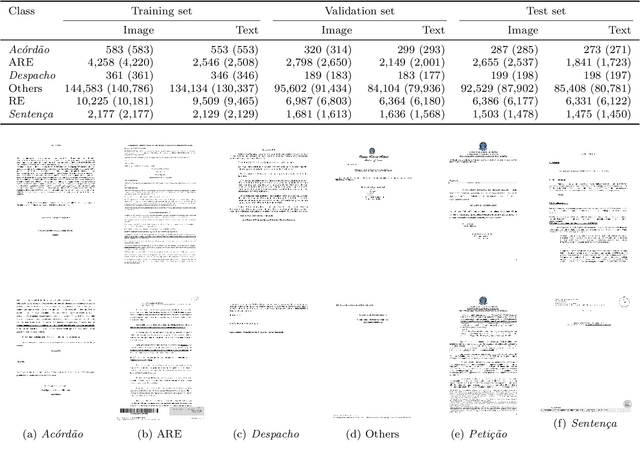
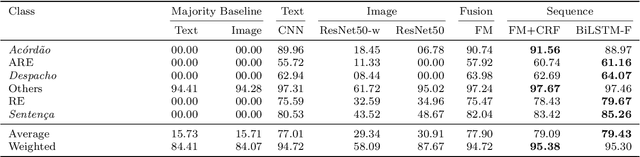
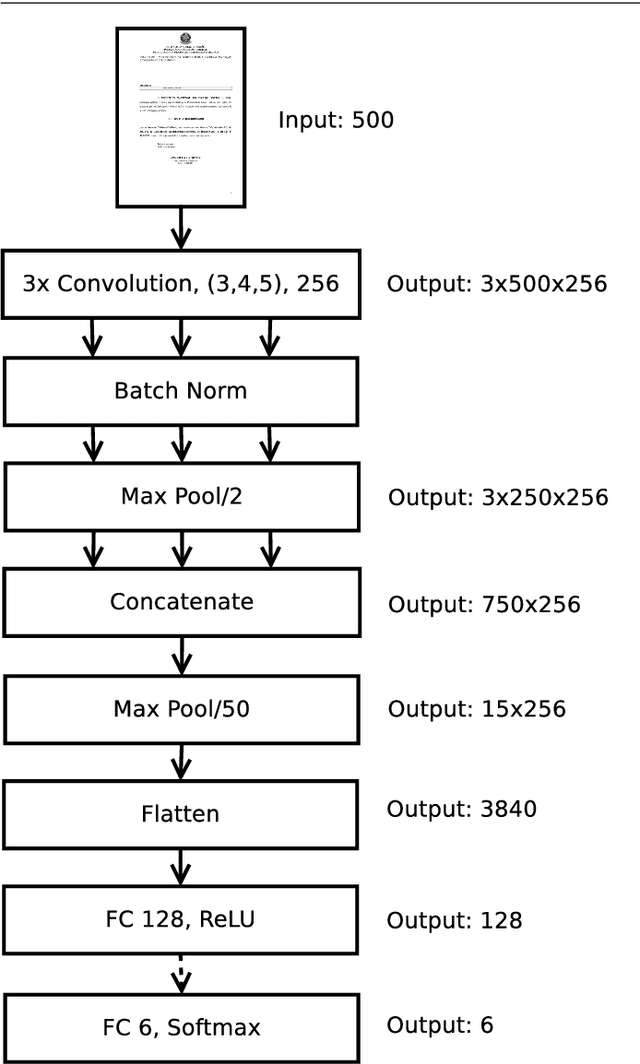
The Brazilian Supreme Court receives tens of thousands of cases each semester. Court employees spend thousands of hours to execute the initial analysis and classification of those cases -- which takes effort away from posterior, more complex stages of the case management workflow. In this paper, we explore multimodal classification of documents from Brazil's Supreme Court. We train and evaluate our methods on a novel multimodal dataset of 6,510 lawsuits (339,478 pages) with manual annotation assigning each page to one of six classes. Each lawsuit is an ordered sequence of pages, which are stored both as an image and as a corresponding text extracted through optical character recognition. We first train two unimodal classifiers: a ResNet pre-trained on ImageNet is fine-tuned on the images, and a convolutional network with filters of multiple kernel sizes is trained from scratch on document texts. We use them as extractors of visual and textual features, which are then combined through our proposed Fusion Module. Our Fusion Module can handle missing textual or visual input by using learned embeddings for missing data. Moreover, we experiment with bi-directional Long Short-Term Memory (biLSTM) networks and linear-chain conditional random fields to model the sequential nature of the pages. The multimodal approaches outperform both textual and visual classifiers, especially when leveraging the sequential nature of the pages.
* 11 pages, 6 figures. This preprint, which was originally written on 8 April 2021, has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this article is published in the International Journal on Document Analysis and Recognition, and is available online at https://doi.org/10.1007/s10032-022-00406-7 and https://rdcu.be/cRvvV
Turning old models fashion again: Recycling classical CNN networks using the Lattice Transformation
Sep 28, 2021
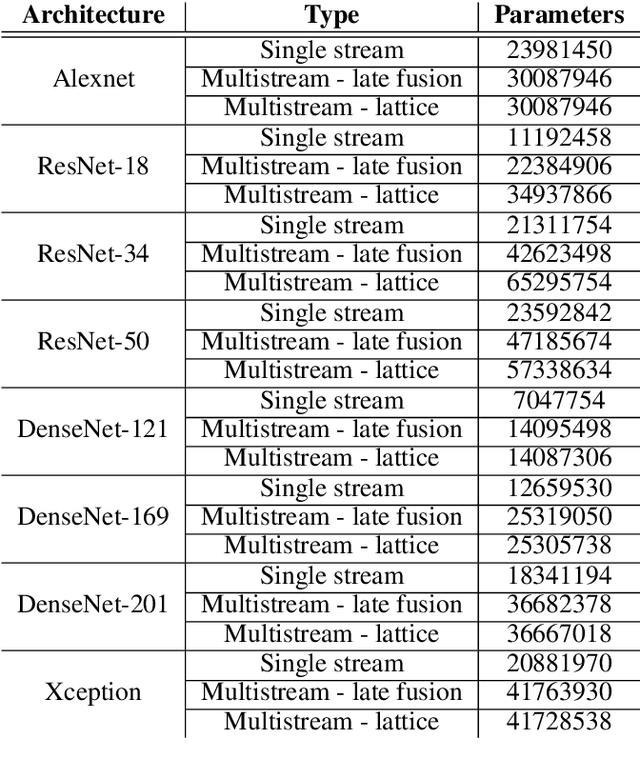
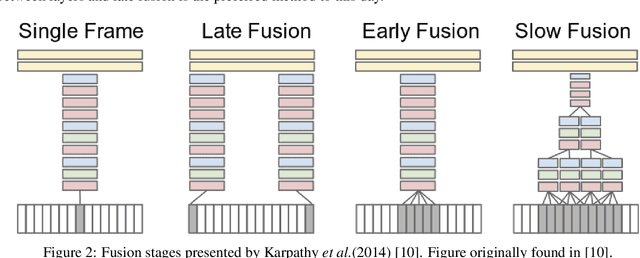
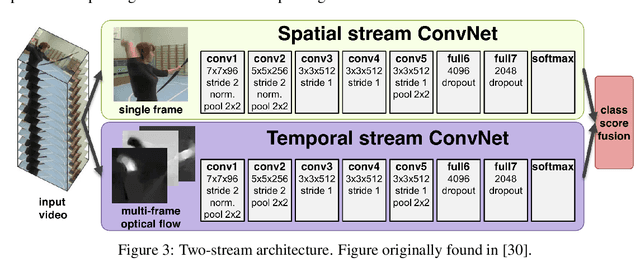
In the early 1990s, the first signs of life of the CNN era were given: LeCun et al. proposed a CNN model trained by the backpropagation algorithm to classify low-resolution images of handwritten digits. Undoubtedly, it was a breakthrough in the field of computer vision. But with the rise of other classification methods, it fell out fashion. That was until 2012, when Krizhevsky et al. revived the interest in CNNs by exhibiting considerably higher image classification accuracy on the ImageNet challenge. Since then, the complexity of the architectures are exponentially increasing and many structures are rapidly becoming obsolete. Using multistream networks as a base and the feature infusion precept, we explore the proposed LCNN cross-fusion strategy to use the backbones of former state-of-the-art networks on image classification in order to discover if the technique is able to put these designs back in the game. In this paper, we showed that we can obtain an increase of accuracy up to 63.21% on the NORB dataset we comparing with the original structure. However, no technique is definitive. While our goal is to try to reuse previous state-of-the-art architectures with few modifications, we also expose the disadvantages of our explored strategy.
L-CNN: A Lattice cross-fusion strategy for multistream convolutional neural networks
Aug 01, 2020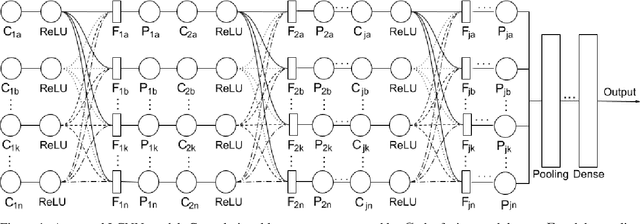
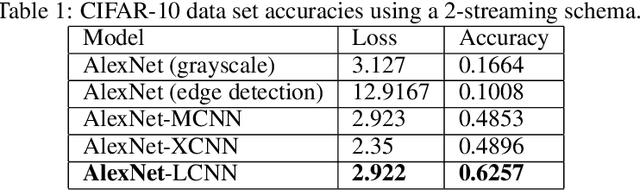
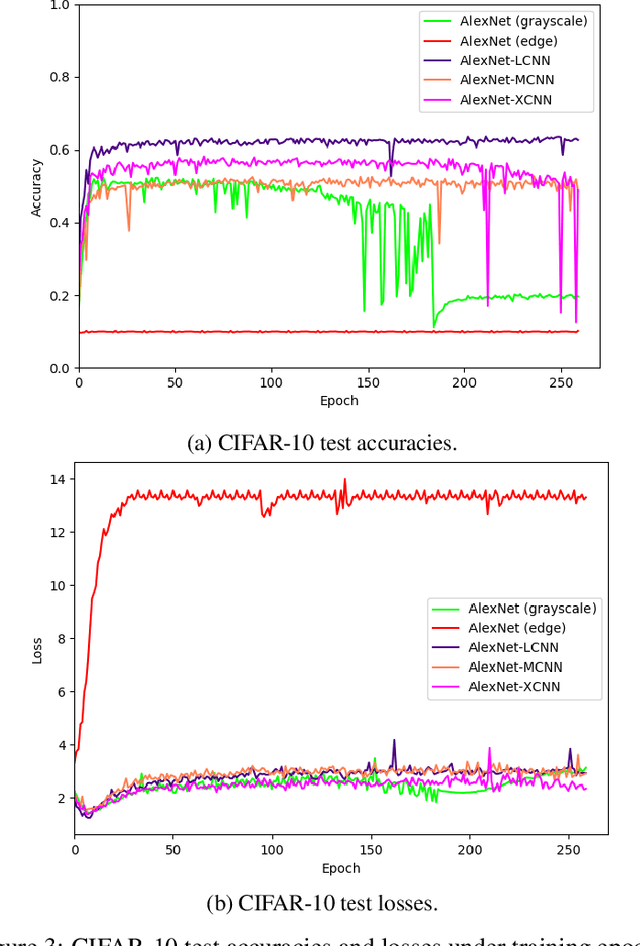
This paper proposes a fusion strategy for multistream convolutional networks, the Lattice Cross Fusion. This approach crosses signals from convolution layers performing mathematical operation-based fusions right before pooling layers. Results on a purposely worsened CIFAR-10, a popular image classification data set, with a modified AlexNet-LCNN version show that this novel method outperforms by 46% the baseline single stream network, with faster convergence, stability, and robustness.
* 5 pages, 3 figures