 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookWhere? Efficient Visual Recognition by Learning Where to Look and What to See from Self-Supervision
May 23, 2025Vision transformers are ever larger, more accurate, and more expensive to compute. The expense is even more extreme at high resolution as the number of tokens grows quadratically with the image size. We turn to adaptive computation to cope with this cost by learning to predict where to compute. Our LookWhere method divides the computation between a low-resolution selector and a high-resolution extractor without ever processing the full high-resolution input. We jointly pretrain the selector and extractor without task supervision by distillation from a self-supervised teacher, in effect, learning where and what to compute simultaneously. Unlike prior token reduction methods, which pay to save by pruning already-computed tokens, and prior token selection methods, which require complex and expensive per-task optimization, LookWhere economically and accurately selects and extracts transferrable representations of images. We show that LookWhere excels at sparse recognition on high-resolution inputs (Traffic Signs), maintaining accuracy while reducing FLOPs by up to 34x and time by 6x. It also excels at standard recognition tasks that are global (ImageNet classification) or local (ADE20K segmentation), improving accuracy while reducing time by 1.36x.
An MRP Formulation for Supervised Learning: Generalized Temporal Difference Learning Models
Apr 23, 2024



In traditional statistical learning, data points are usually assumed to be independently and identically distributed (i.i.d.) following an unknown probability distribution. This paper presents a contrasting viewpoint, perceiving data points as interconnected and employing a Markov reward process (MRP) for data modeling. We reformulate the typical supervised learning as an on-policy policy evaluation problem within reinforcement learning (RL), introducing a generalized temporal difference (TD) learning algorithm as a resolution. Theoretically, our analysis draws connections between the solutions of linear TD learning and ordinary least squares (OLS). We also show that under specific conditions, particularly when noises are correlated, the TD's solution proves to be a more effective estimator than OLS. Furthermore, we establish the convergence of our generalized TD algorithms under linear function approximation. Empirical studies verify our theoretical results, examine the vital design of our TD algorithm and show practical utility across various datasets, encompassing tasks such as regression and image classification with deep learning.
Find Your Friends: Personalized Federated Learning with the Right Collaborators
Oct 14, 2022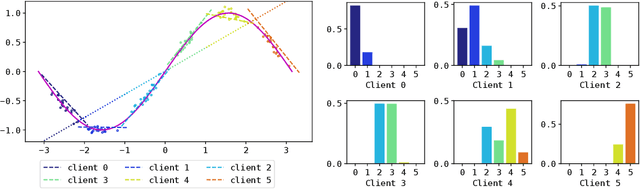


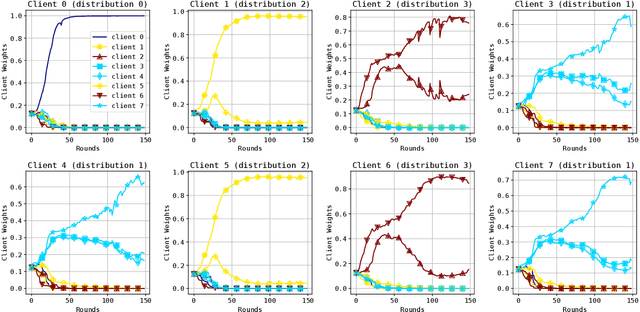
In the traditional federated learning setting, a central server coordinates a network of clients to train one global model. However, the global model may serve many clients poorly due to data heterogeneity. Moreover, there may not exist a trusted central party that can coordinate the clients to ensure that each of them can benefit from others. To address these concerns, we present a novel decentralized framework, FedeRiCo, where each client can learn as much or as little from other clients as is optimal for its local data distribution. Based on expectation-maximization, FedeRiCo estimates the utilities of other participants' models on each client's data so that everyone can select the right collaborators for learning. As a result, our algorithm outperforms other federated, personalized, and/or decentralized approaches on several benchmark datasets, being the only approach that consistently performs better than training with local data only.
A Parametric Class of Approximate Gradient Updates for Policy Optimization
Jun 17, 2022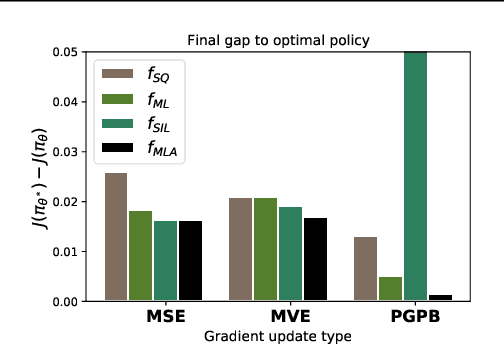

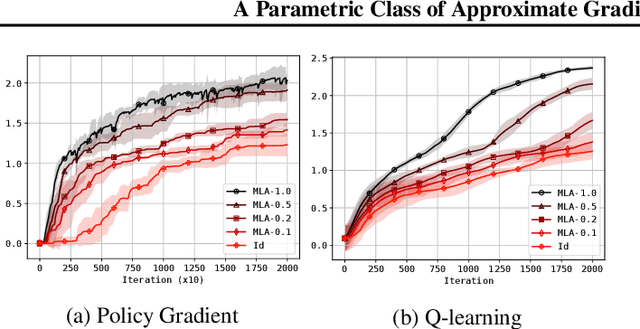
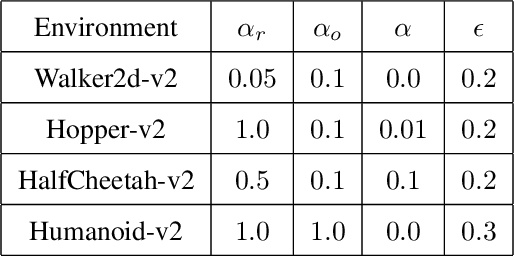
Approaches to policy optimization have been motivated from diverse principles, based on how the parametric model is interpreted (e.g. value versus policy representation) or how the learning objective is formulated, yet they share a common goal of maximizing expected return. To better capture the commonalities and identify key differences between policy optimization methods, we develop a unified perspective that re-expresses the underlying updates in terms of a limited choice of gradient form and scaling function. In particular, we identify a parameterized space of approximate gradient updates for policy optimization that is highly structured, yet covers both classical and recent examples, including PPO. As a result, we obtain novel yet well motivated updates that generalize existing algorithms in a way that can deliver benefits both in terms of convergence speed and final result quality. An experimental investigation demonstrates that the additional degrees of freedom provided in the parameterized family of updates can be leveraged to obtain non-trivial improvements both in synthetic domains and on popular deep RL benchmarks.
ProxyFL: Decentralized Federated Learning through Proxy Model Sharing
Nov 22, 2021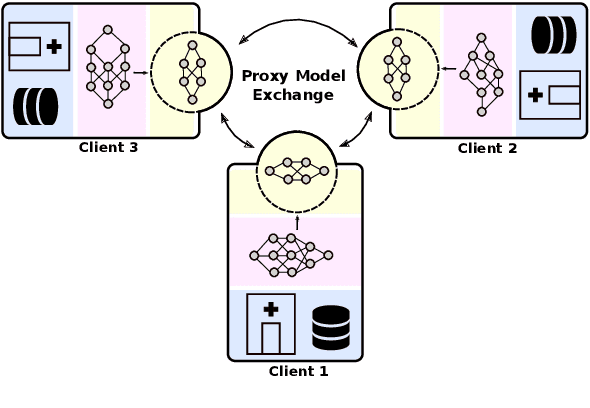
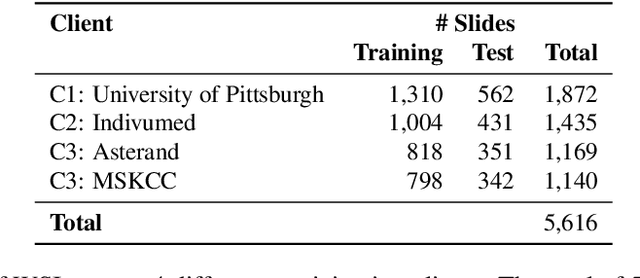
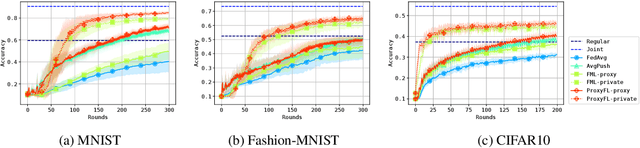
Institutions in highly regulated domains such as finance and healthcare often have restrictive rules around data sharing. Federated learning is a distributed learning framework that enables multi-institutional collaborations on decentralized data with improved protection for each collaborator's data privacy. In this paper, we propose a communication-efficient scheme for decentralized federated learning called ProxyFL, or proxy-based federated learning. Each participant in ProxyFL maintains two models, a private model, and a publicly shared proxy model designed to protect the participant's privacy. Proxy models allow efficient information exchange among participants using the PushSum method without the need of a centralized server. The proposed method eliminates a significant limitation of canonical federated learning by allowing model heterogeneity; each participant can have a private model with any architecture. Furthermore, our protocol for communication by proxy leads to stronger privacy guarantees using differential privacy analysis. Experiments on popular image datasets, and a pan-cancer diagnostic problem using over 30,000 high-quality gigapixel histology whole slide images, show that ProxyFL can outperform existing alternatives with much less communication overhead and stronger privacy.
Characterizing the Gap Between Actor-Critic and Policy Gradient
Jun 13, 2021
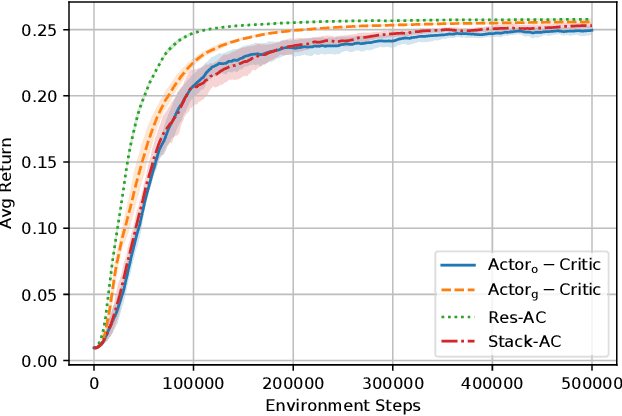
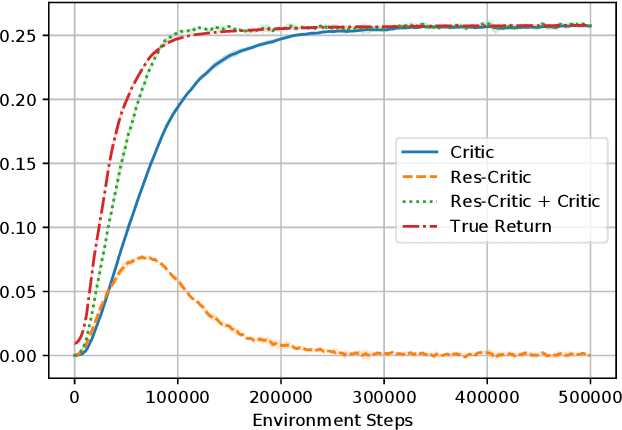
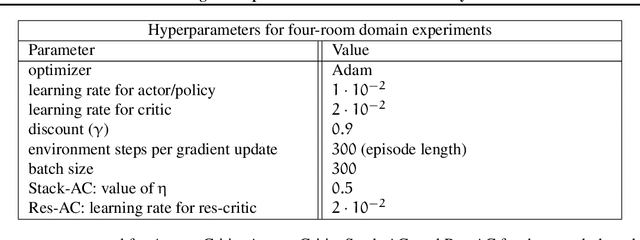
Actor-critic (AC) methods are ubiquitous in reinforcement learning. Although it is understood that AC methods are closely related to policy gradient (PG), their precise connection has not been fully characterized previously. In this paper, we explain the gap between AC and PG methods by identifying the exact adjustment to the AC objective/gradient that recovers the true policy gradient of the cumulative reward objective (PG). Furthermore, by viewing the AC method as a two-player Stackelberg game between the actor and critic, we show that the Stackelberg policy gradient can be recovered as a special case of our more general analysis. Based on these results, we develop practical algorithms, Residual Actor-Critic and Stackelberg Actor-Critic, for estimating the correction between AC and PG and use these to modify the standard AC algorithm. Experiments on popular tabular and continuous environments show the proposed corrections can improve both the sample efficiency and final performance of existing AC methods.
Batch Stationary Distribution Estimation
Mar 02, 2020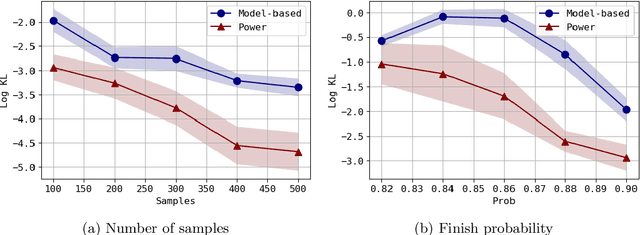
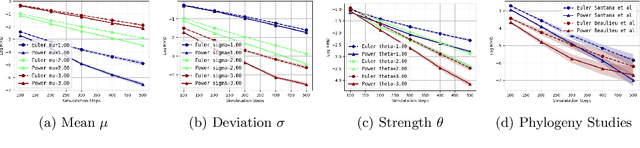
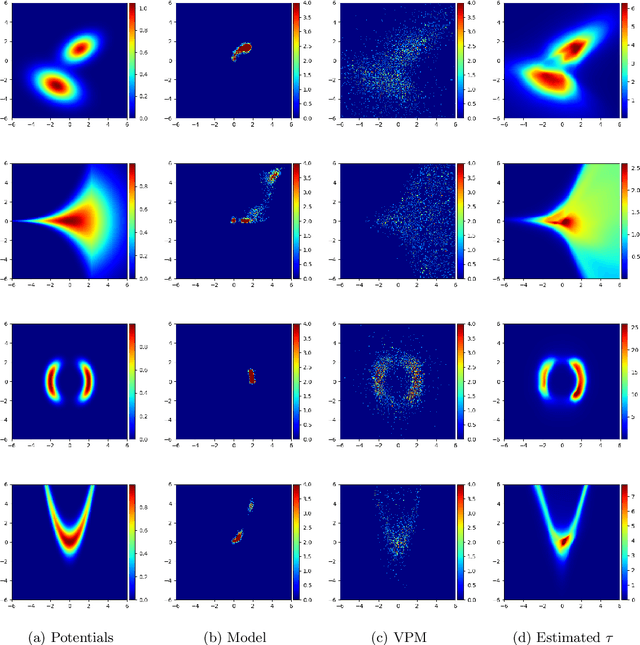
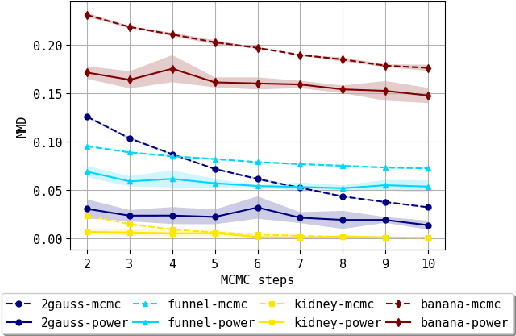
We consider the problem of approximating the stationary distribution of an ergodic Markov chain given a set of sampled transitions. Classical simulation-based approaches assume access to the underlying process so that trajectories of sufficient length can be gathered to approximate stationary sampling. Instead, we consider an alternative setting where a fixed set of transitions has been collected beforehand, by a separate, possibly unknown procedure. The goal is still to estimate properties of the stationary distribution, but without additional access to the underlying system. We propose a consistent estimator that is based on recovering a correction ratio function over the given data. In particular, we develop a variational power method (VPM) that provides provably consistent estimates under general conditions. In addition to unifying a number of existing approaches from different subfields, we also find that VPM yields significantly better estimates across a range of problems, including queueing, stochastic differential equations, post-processing MCMC, and off-policy evaluation.
Universal Successor Features for Transfer Reinforcement Learning
Jan 05, 2020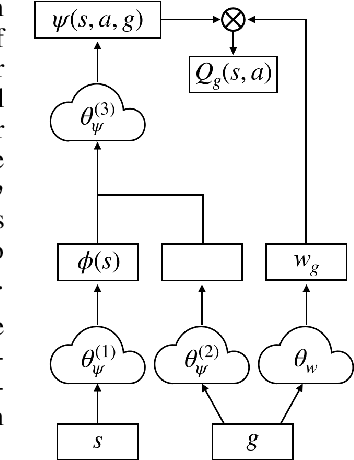
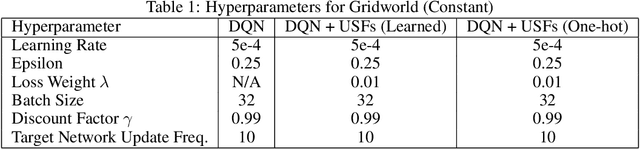
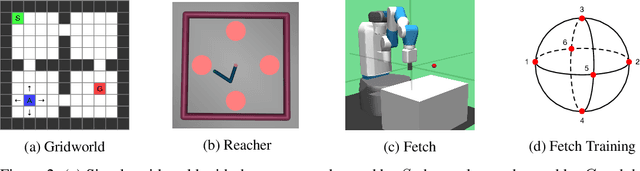
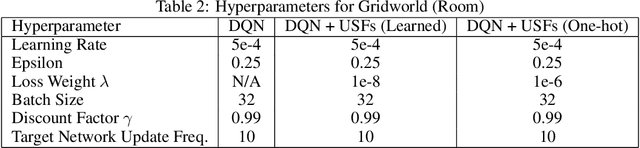
Transfer in Reinforcement Learning (RL) refers to the idea of applying knowledge gained from previous tasks to solving related tasks. Learning a universal value function (Schaul et al., 2015), which generalizes over goals and states, has previously been shown to be useful for transfer. However, successor features are believed to be more suitable than values for transfer (Dayan, 1993; Barreto et al.,2017), even though they cannot directly generalize to new goals. In this paper, we propose (1) Universal Successor Features (USFs) to capture the underlying dynamics of the environment while allowing generalization to unseen goals and (2) a flexible end-to-end model of USFs that can be trained by interacting with the environment. We show that learning USFs is compatible with any RL algorithm that learns state values using a temporal difference method. Our experiments in a simple gridworld and with two MuJoCo environments show that USFs can greatly accelerate training when learning multiple tasks and can effectively transfer knowledge to new tasks.
Domain Aggregation Networks for Multi-Source Domain Adaptation
Sep 25, 2019
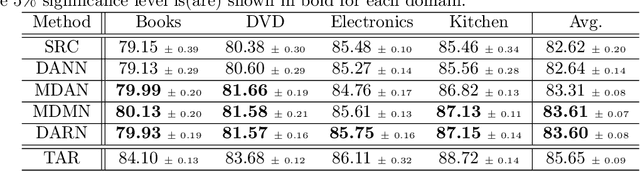
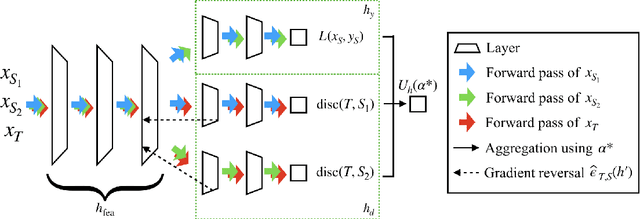
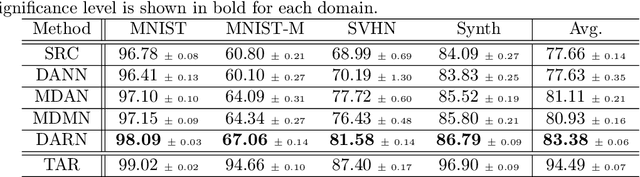
In many real-world applications, we want to exploit multiple source datasets of similar tasks to learn a model for a different but related target dataset -- e.g., recognizing characters of a new font using a set of different fonts. While most recent research has considered ad-hoc combination rules to address this problem, we extend previous work on domain discrepancy minimization to develop a finite-sample generalization bound, and accordingly propose a theoretically justified optimization procedure. The algorithm we develop, Domain AggRegation Network (DARN), is able to effectively adjust the weight of each source domain during training to ensure relevant domains are given more importance for adaptation. We evaluate the proposed method on real-world sentiment analysis and digit recognition datasets and show that DARN can significantly outperform the state-of-the-art alternatives.
Few-Shot Self Reminder to Overcome Catastrophic Forgetting
Dec 03, 2018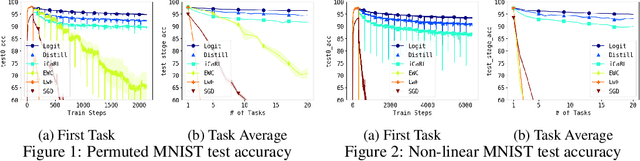
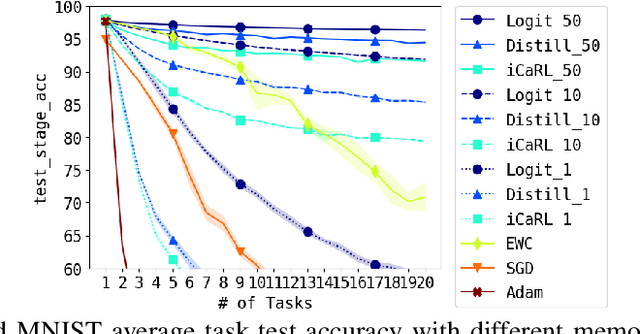
Deep neural networks are known to suffer the catastrophic forgetting problem, where they tend to forget the knowledge from the previous tasks when sequentially learning new tasks. Such failure hinders the application of deep learning based vision system in continual learning settings. In this work, we present a simple yet surprisingly effective way of preventing catastrophic forgetting. Our method, called Few-shot Self Reminder (FSR), regularizes the neural net from changing its learned behaviour by performing logit matching on selected samples kept in episodic memory from the old tasks. Surprisingly, this simplistic approach only requires to retrain a small amount of data in order to outperform previous methods in knowledge retention. We demonstrate the superiority of our method to the previous ones in two different continual learning settings on popular benchmarks, as well as a new continual learning problem where tasks are designed to be more dissimilar.