 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Universal Segmentation of 33 Anatomies
Mar 04, 2022
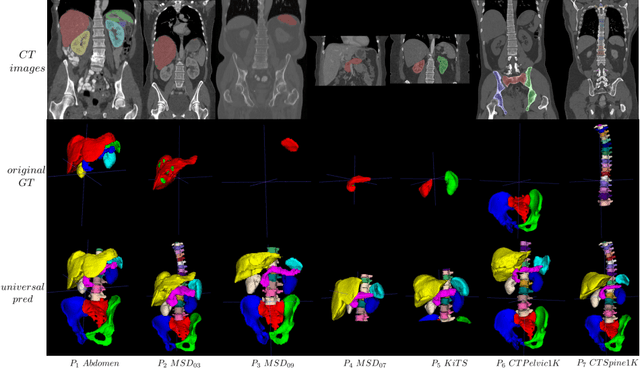
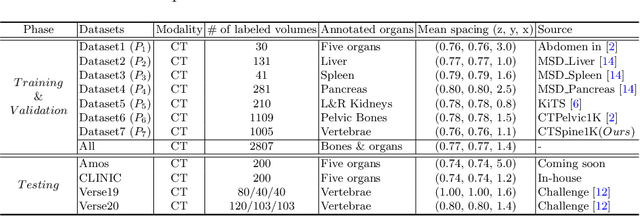
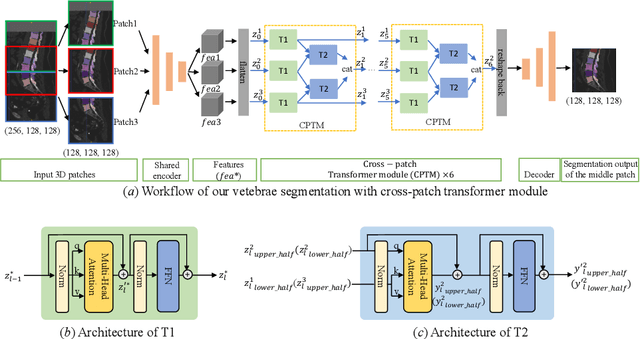
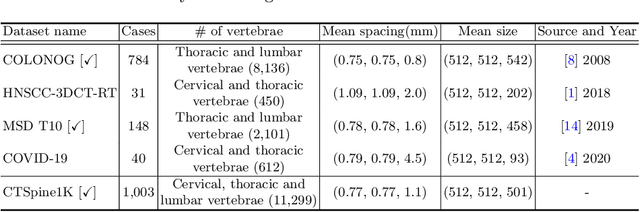
In the paper, we present an approach for learning a single model that universally segments 33 anatomical structures, including vertebrae, pelvic bones, and abdominal organs. Our model building has to address the following challenges. Firstly, while it is ideal to learn such a model from a large-scale, fully-annotated dataset, it is practically hard to curate such a dataset. Thus, we resort to learn from a union of multiple datasets, with each dataset containing the images that are partially labeled. Secondly, along the line of partial labelling, we contribute an open-source, large-scale vertebra segmentation dataset for the benefit of spine analysis community, CTSpine1K, boasting over 1,000 3D volumes and over 11K annotated vertebrae. Thirdly, in a 3D medical image segmentation task, due to the limitation of GPU memory, we always train a model using cropped patches as inputs instead a whole 3D volume, which limits the amount of contextual information to be learned. To this, we propose a cross-patch transformer module to fuse more information in adjacent patches, which enlarges the aggregated receptive field for improved segmentation performance. This is especially important for segmenting, say, the elongated spine. Based on 7 partially labeled datasets that collectively contain about 2,800 3D volumes, we successfully learn such a universal model. Finally, we evaluate the universal model on multiple open-source datasets, proving that our model has a good generalization performance and can potentially serve as a solid foundation for downstream tasks.
Mapping DNN Embedding Manifolds for Network Generalization Prediction
Feb 03, 2022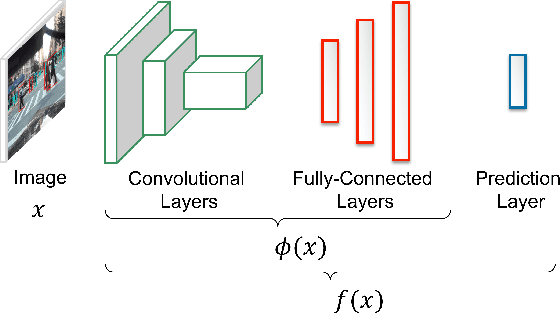
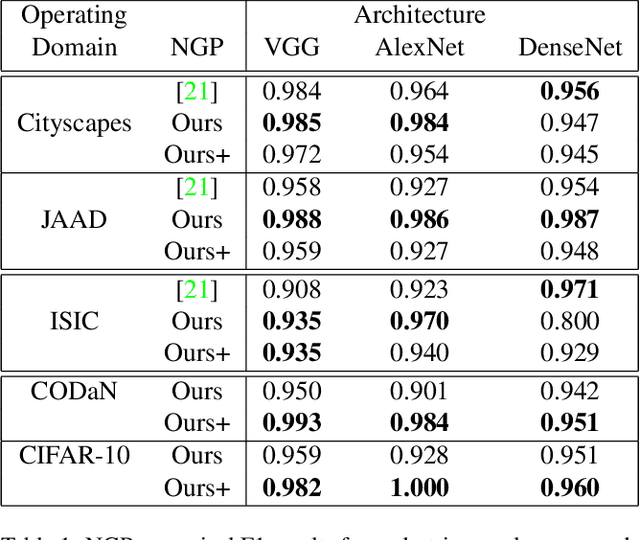

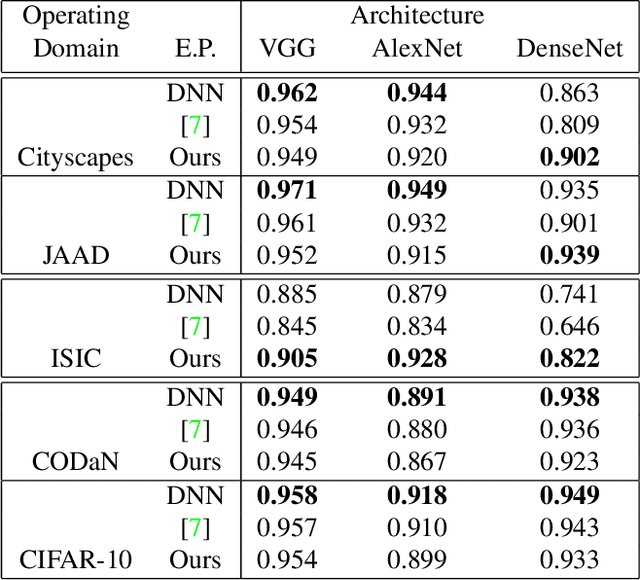
Understanding Deep Neural Network (DNN) performance in changing conditions is essential for deploying DNNs in safety critical applications with unconstrained environments, e.g., perception for self-driving vehicles or medical image analysis. Recently, the task of Network Generalization Prediction (NGP) has been proposed to predict how a DNN will generalize in a new operating domain. Previous NGP approaches have relied on labeled metadata and known distributions for the new operating domains. In this study, we propose the first NGP approach that predicts DNN performance based solely on how unlabeled images from an external operating domain map in the DNN embedding space. We demonstrate this technique for pedestrian, melanoma, and animal classification tasks and show state of the art NGP in 13 of 15 NGP tasks without requiring domain knowledge. Additionally, we show that our NGP embedding maps can be used to identify misclassified images when the DNN performance is poor.
Universal Model for Multi-Domain Medical Image Retrieval
Jul 14, 2020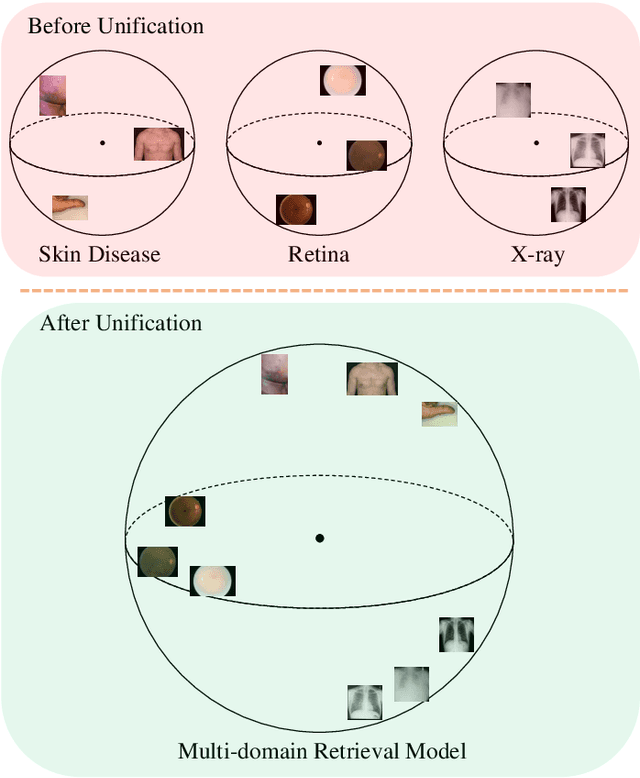
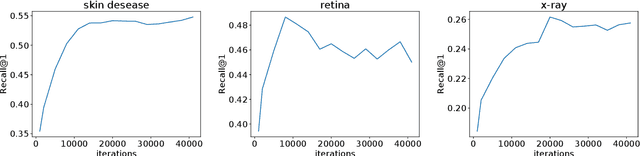
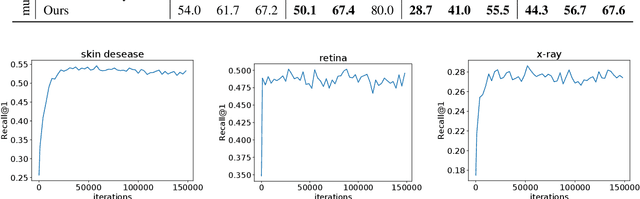
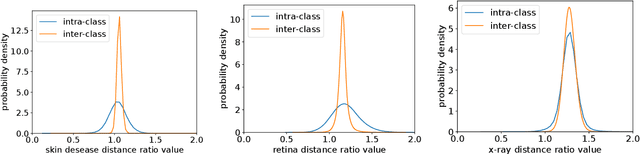
Medical Image Retrieval (MIR) helps doctors quickly find similar patients' data, which can considerably aid the diagnosis process. MIR is becoming increasingly helpful due to the wide use of digital imaging modalities and the growth of the medical image repositories. However, the popularity of various digital imaging modalities in hospitals also poses several challenges to MIR. Usually, one image retrieval model is only trained to handle images from one modality or one source. When there are needs to retrieve medical images from several sources or domains, multiple retrieval models need to be maintained, which is cost ineffective. In this paper, we study an important but unexplored task: how to train one MIR model that is applicable to medical images from multiple domains? Simply fusing the training data from multiple domains cannot solve this problem because some domains become over-fit sooner when trained together using existing methods. Therefore, we propose to distill the knowledge in multiple specialist MIR models into a single multi-domain MIR model via universal embedding to solve this problem. Using skin disease, x-ray, and retina image datasets, we validate that our proposed universal model can effectively accomplish multi-domain MIR.
Danish Airs and Grounds: A Dataset for Aerial-to-Street-Level Place Recognition and Localization
Feb 03, 2022


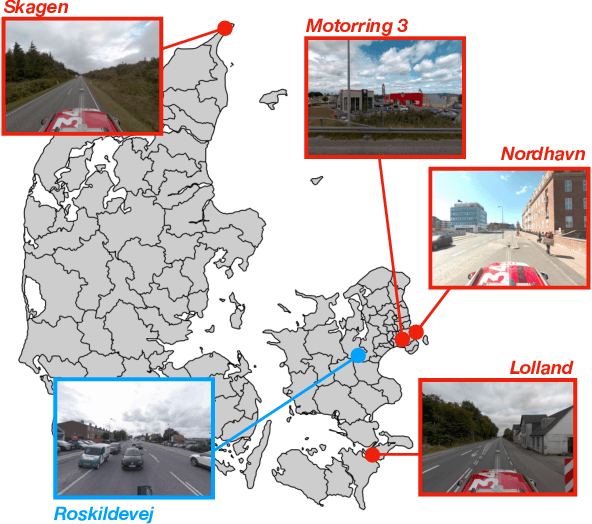
Place recognition and visual localization are particularly challenging in wide baseline configurations. In this paper, we contribute with the \emph{Danish Airs and Grounds} (DAG) dataset, a large collection of street-level and aerial images targeting such cases. Its main challenge lies in the extreme viewing-angle difference between query and reference images with consequent changes in illumination and perspective. The dataset is larger and more diverse than current publicly available data, including more than 50 km of road in urban, suburban and rural areas. All images are associated with accurate 6-DoF metadata that allows the benchmarking of visual localization methods. We also propose a map-to-image re-localization pipeline, that first estimates a dense 3D reconstruction from the aerial images and then matches query street-level images to street-level renderings of the 3D model. The dataset can be downloaded at: https://frederikwarburg.github.io/DAG
Transferability Estimation using Bhattacharyya Class Separability
Nov 24, 2021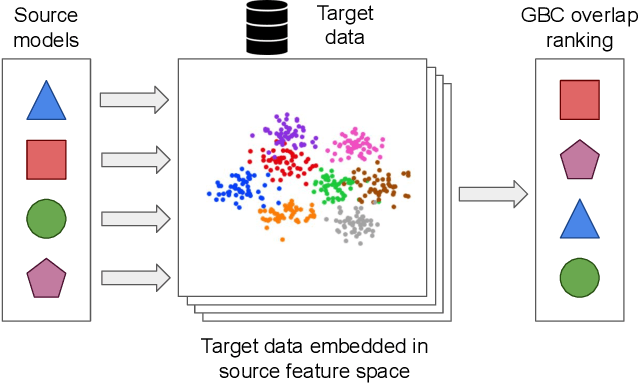

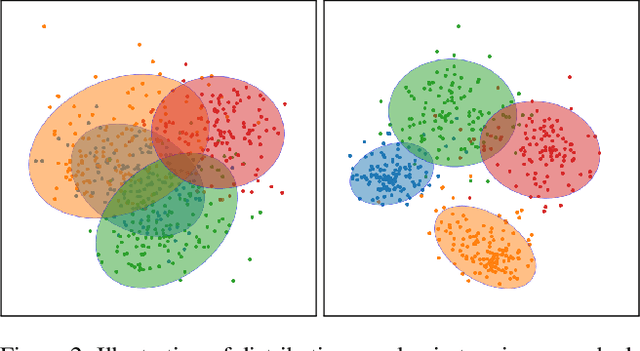
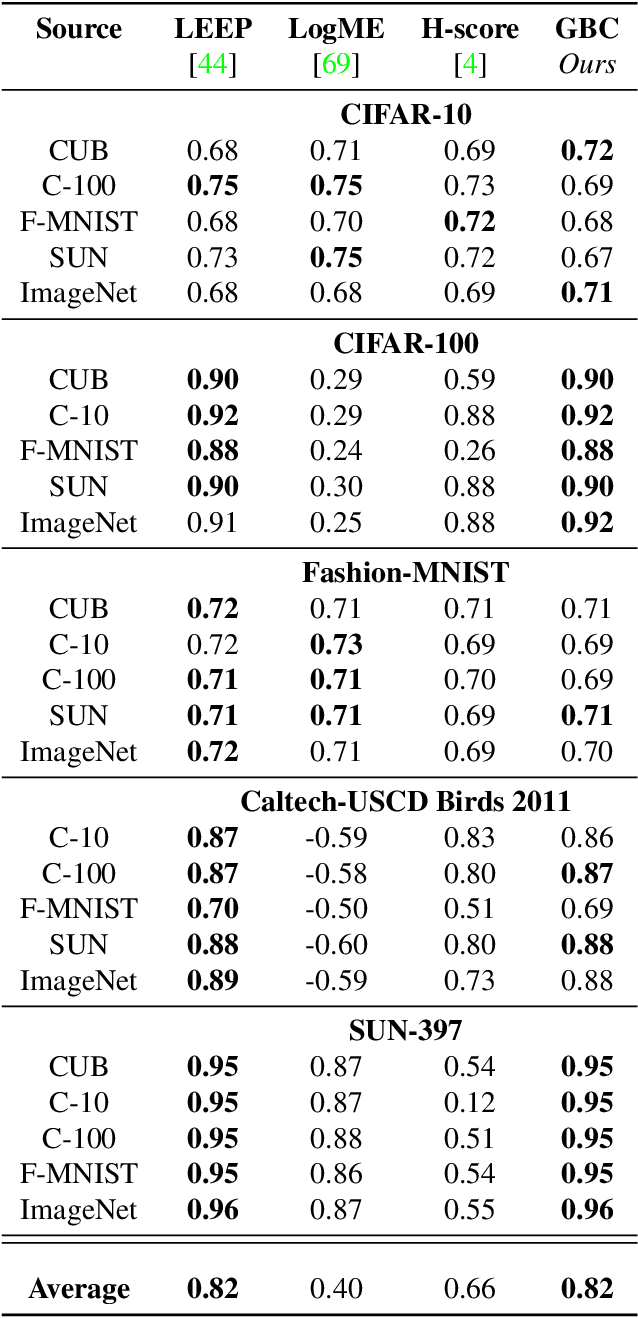
Transfer learning has become a popular method for leveraging pre-trained models in computer vision. However, without performing computationally expensive fine-tuning, it is difficult to quantify which pre-trained source models are suitable for a specific target task, or, conversely, to which tasks a pre-trained source model can be easily adapted to. In this work, we propose Gaussian Bhattacharyya Coefficient (GBC), a novel method for quantifying transferability between a source model and a target dataset. In a first step we embed all target images in the feature space defined by the source model, and represent them with per-class Gaussians. Then, we estimate their pairwise class separability using the Bhattacharyya coefficient, yielding a simple and effective measure of how well the source model transfers to the target task. We evaluate GBC on image classification tasks in the context of dataset and architecture selection. Further, we also perform experiments on the more complex semantic segmentation transferability estimation task. We demonstrate that GBC outperforms state-of-the-art transferability metrics on most evaluation criteria in the semantic segmentation settings, matches the performance of top methods for dataset transferability in image classification, and performs best on architecture selection problems for image classification.
High-level Prior-based Loss Functions for Medical Image Segmentation: A Survey
Nov 16, 2020
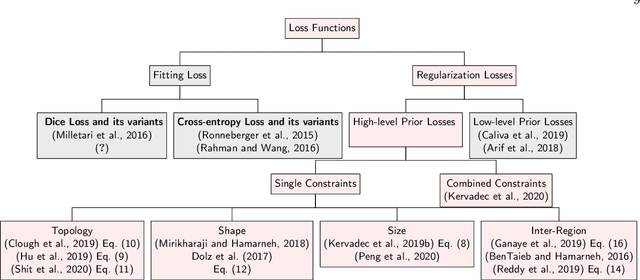
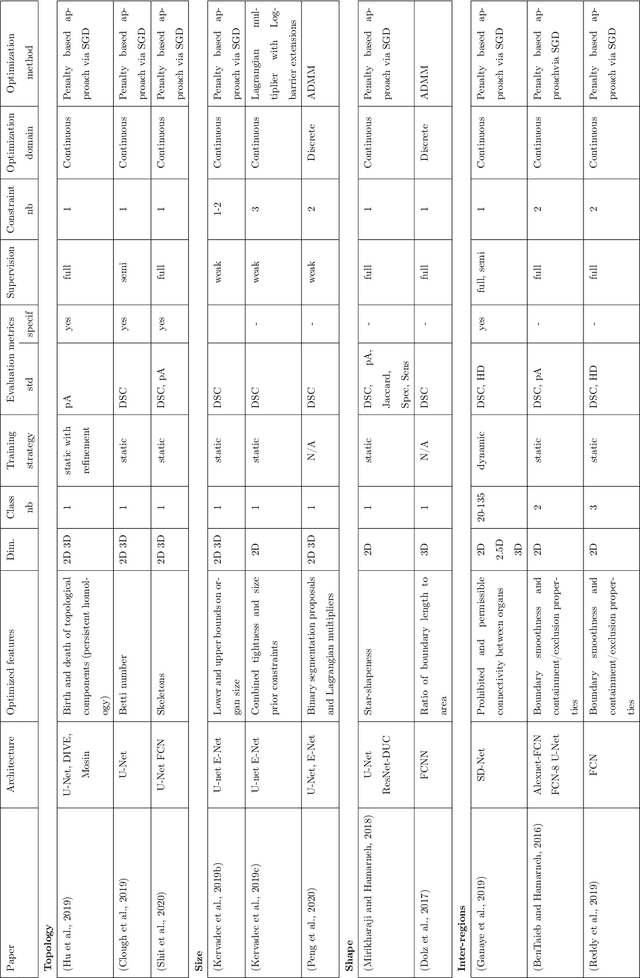
Today, deep convolutional neural networks (CNNs) have demonstrated state of the art performance for supervised medical image segmentation, across various imaging modalities and tasks. Despite early success, segmentation networks may still generate anatomically aberrant segmentations, with holes or inaccuracies near the object boundaries. To mitigate this effect, recent research works have focused on incorporating spatial information or prior knowledge to enforce anatomically plausible segmentation. If the integration of prior knowledge in image segmentation is not a new topic in classical optimization approaches, it is today an increasing trend in CNN based image segmentation, as shown by the growing literature on the topic. In this survey, we focus on high level prior, embedded at the loss function level. We categorize the articles according to the nature of the prior: the object shape, size, topology, and the inter-regions constraints. We highlight strengths and limitations of current approaches, discuss the challenge related to the design and the integration of prior-based losses, and the optimization strategies, and draw future research directions.
One-Shot Image Classification by Learning to Restore Prototypes
May 04, 2020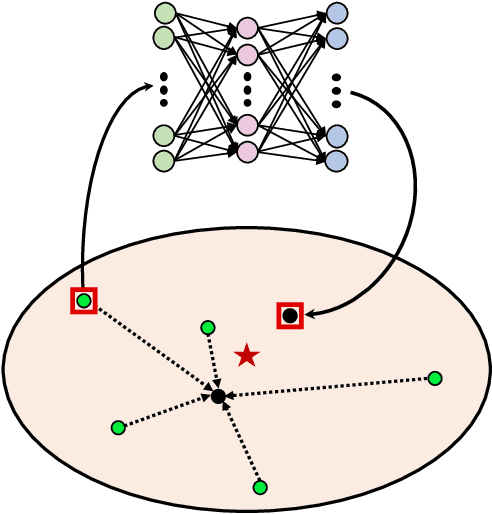


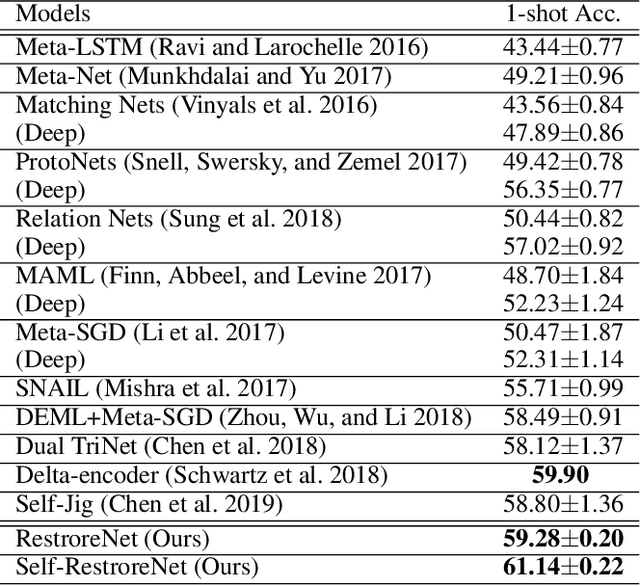
One-shot image classification aims to train image classifiers over the dataset with only one image per category. It is challenging for modern deep neural networks that typically require hundreds or thousands of images per class. In this paper, we adopt metric learning for this problem, which has been applied for few- and many-shot image classification by comparing the distance between the test image and the center of each class in the feature space. However, for one-shot learning, the existing metric learning approaches would suffer poor performance because the single training image may not be representative of the class. For example, if the image is far away from the class center in the feature space, the metric-learning based algorithms are unlikely to make correct predictions for the test images because the decision boundary is shifted by this noisy image. To address this issue, we propose a simple yet effective regression model, denoted by RestoreNet, which learns a class agnostic transformation on the image feature to move the image closer to the class center in the feature space. Experiments demonstrate that RestoreNet obtains superior performance over the state-of-the-art methods on a broad range of datasets. Moreover, RestoreNet can be easily combined with other methods to achieve further improvement.
A Note on the Implicit Bias Towards Minimal Depth of Deep Neural Networks
Feb 18, 2022
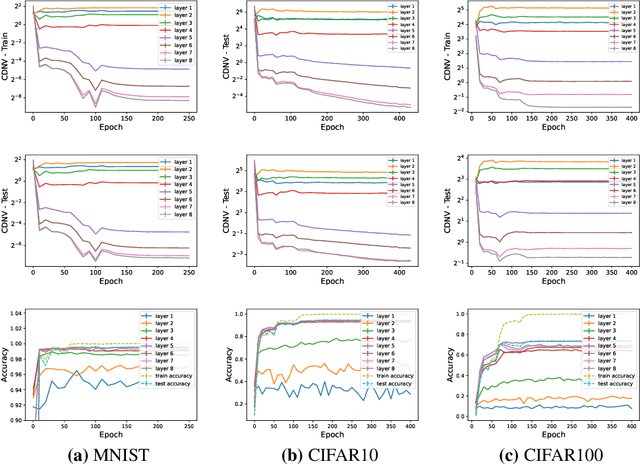
Deep learning systems have steadily advanced the state of the art in a wide variety of benchmarks, demonstrating impressive performance in tasks ranging from image classification \citep{taigman2014deepface,zhai2021scaling}, language processing \citep{devlin-etal-2019-bert,NEURIPS2020_1457c0d6}, open-ended environments \citep{SilverHuangEtAl16nature,arulkumaran2019alphastar}, to coding \citep{chen2021evaluating}. A central aspect that enables the success of these systems is the ability to train deep models instead of wide shallow ones \citep{7780459}. Intuitively, a neural network is decomposed into hierarchical representations from raw data to high-level, more abstract features. While training deep neural networks repetitively achieves superior performance against their shallow counterparts, an understanding of the role of depth in representation learning is still lacking. In this work, we suggest a new perspective on understanding the role of depth in deep learning. We hypothesize that {\bf\em SGD training of overparameterized neural networks exhibits an implicit bias that favors solutions of minimal effective depth}. Namely, SGD trains neural networks for which the top several layers are redundant. To evaluate the redundancy of layers, we revisit the recently discovered phenomenon of neural collapse \citep{Papyan24652,han2021neural}.
GuidedMix-Net: Semi-supervised Semantic Segmentation by Using Labeled Images as Reference
Dec 28, 2021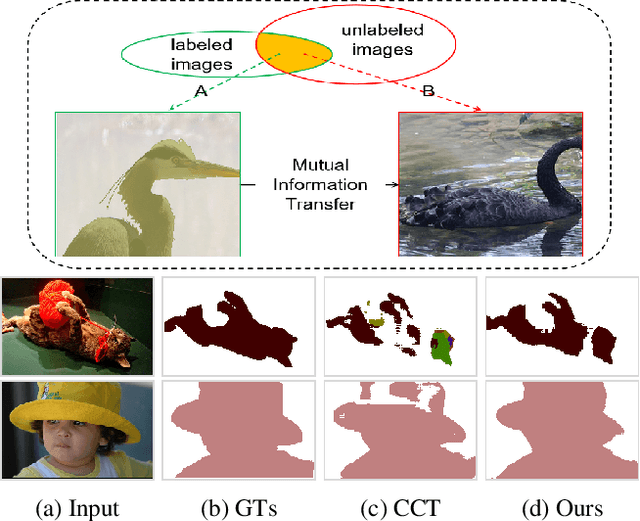
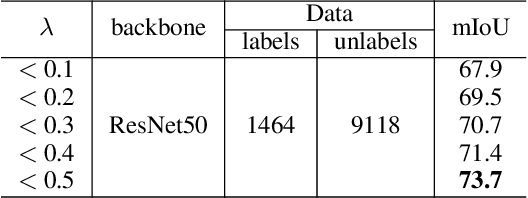
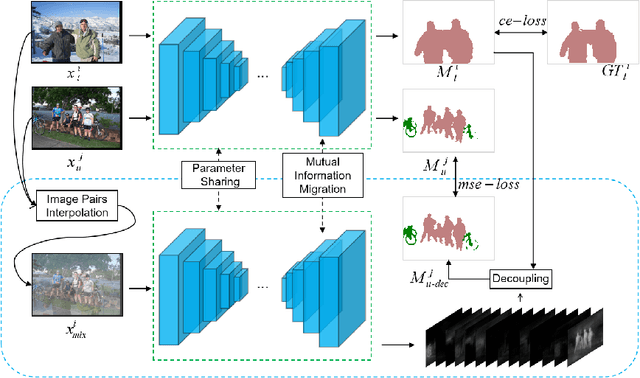
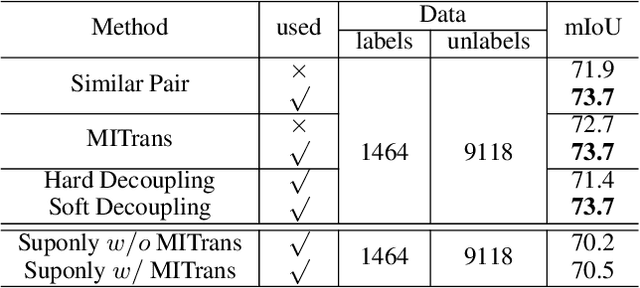
Semi-supervised learning is a challenging problem which aims to construct a model by learning from limited labeled examples. Numerous methods for this task focus on utilizing the predictions of unlabeled instances consistency alone to regularize networks. However, treating labeled and unlabeled data separately often leads to the discarding of mass prior knowledge learned from the labeled examples. %, and failure to mine the feature interaction between the labeled and unlabeled image pairs. In this paper, we propose a novel method for semi-supervised semantic segmentation named GuidedMix-Net, by leveraging labeled information to guide the learning of unlabeled instances. Specifically, GuidedMix-Net employs three operations: 1) interpolation of similar labeled-unlabeled image pairs; 2) transfer of mutual information; 3) generalization of pseudo masks. It enables segmentation models can learning the higher-quality pseudo masks of unlabeled data by transfer the knowledge from labeled samples to unlabeled data. Along with supervised learning for labeled data, the prediction of unlabeled data is jointly learned with the generated pseudo masks from the mixed data. Extensive experiments on PASCAL VOC 2012, and Cityscapes demonstrate the effectiveness of our GuidedMix-Net, which achieves competitive segmentation accuracy and significantly improves the mIoU by +7$\%$ compared to previous approaches.
Recurrent Feature Propagation and Edge Skip-Connections for Automatic Abdominal Organ Segmentation
Jan 02, 2022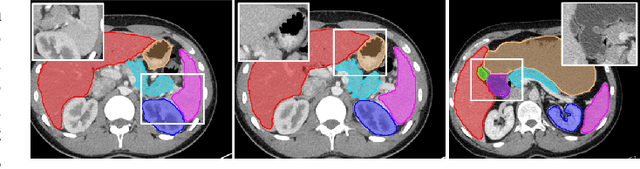
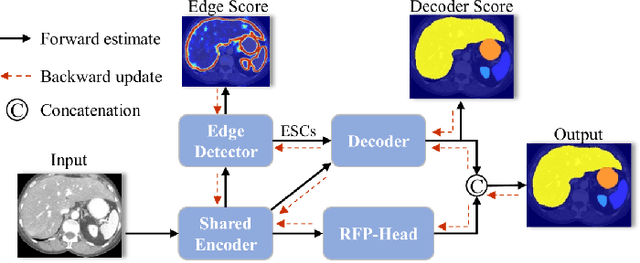
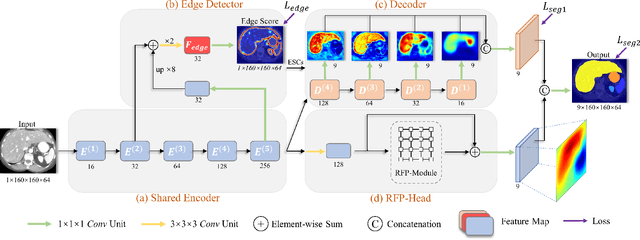

Automatic segmentation of abdominal organs in computed tomography (CT) images can support radiation therapy and image-guided surgery workflows. Developing of such automatic solutions remains challenging mainly owing to complex organ interactions and blurry boundaries in CT images. To address these issues, we focus on effective spatial context modeling and explicit edge segmentation priors. Accordingly, we propose a 3D network with four main components trained end-to-end including shared encoder, edge detector, decoder with edge skip-connections (ESCs) and recurrent feature propagation head (RFP-Head). To capture wide-range spatial dependencies, the RFP-Head propagates and harvests local features through directed acyclic graphs (DAGs) formulated with recurrent connections in an efficient slice-wise manner, with regard to spatial arrangement of image units. To leverage edge information, the edge detector learns edge prior knowledge specifically tuned for semantic segmentation by exploiting intermediate features from the encoder with the edge supervision. The ESCs then aggregate the edge knowledge with multi-level decoder features to learn a hierarchy of discriminative features explicitly modeling complementarity between organs' interiors and edges for segmentation. We conduct extensive experiments on two challenging abdominal CT datasets with eight annotated organs. Experimental results show that the proposed network outperforms several state-of-the-art models, especially for the segmentation of small and complicated structures (gallbladder, esophagus, stomach, pancreas and duodenum). The code will be publicly available.