 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Dark Knowledge: Mixup-Based Distillation for Reliable Predictions
Jun 10, 2026Knowledge Distillation (KD) and mixup have proven effective at inducing smoothness in class boundaries; KD captures inherent class relationships in probability distributions, and mixup enforces them through convex combinations of inputs. Their interaction, however, remains poorly understood, particularly when mixup is applied only during student training. In this setting, the teacher is queried on inputs drawn from a vicinal distribution it never saw during training, a controlled mismatch whose effect on knowledge transfer has not been characterised. We show that this mismatch causes the teacher's supervisory signal to be dominated by distributional confusion rather than inter-class structure. Despite it, the student does not merely imitate the teacher: it independently acquires greater linearity in the vicinal region, a structural property that the teacher lacks, and goes beyond dark-knowledge transfer. KD with mixup consistently improves student accuracy and reduces overconfidence by an order of magnitude relative to the baseline, across CIFAR and ImageNet with varying-capacity teachers. Crucially, calibration propagates from teacher to student independently of accuracy transfer, and temperature scaling governs a measurable accuracy-calibration trade-off that becomes more pronounced under vicinal training. These results reframe mixup distillation not as a degraded version of standard KD, but as a richer transfer channel that simultaneously shapes discriminative performance, uncertainty estimation, and representational geometry.
Spectral-Spatial Contrastive Learning Framework for Regression on Hyperspectral Data
Feb 11, 2026Contrastive learning has demonstrated great success in representation learning, especially for image classification tasks. However, there is still a shortage in studies targeting regression tasks, and more specifically applications on hyperspectral data. In this paper, we propose a spectral-spatial contrastive learning framework for regression tasks for hyperspectral data, in a model-agnostic design allowing to enhance backbones such as 3D convolutional and transformer-based networks. Moreover, we provide a collection of transformations relevant for augmenting hyperspectral data. Experiments on synthetic and real datasets show that the proposed framework and transformations significantly improve the performance of all studied backbone models.
Universal Domain Adaptation Benchmark for Time Series Data Representation
May 23, 2025Deep learning models have significantly improved the ability to detect novelties in time series (TS) data. This success is attributed to their strong representation capabilities. However, due to the inherent variability in TS data, these models often struggle with generalization and robustness. To address this, a common approach is to perform Unsupervised Domain Adaptation, particularly Universal Domain Adaptation (UniDA), to handle domain shifts and emerging novel classes. While extensively studied in computer vision, UniDA remains underexplored for TS data. This work provides a comprehensive implementation and comparison of state-of-the-art TS backbones in a UniDA framework. We propose a reliable protocol to evaluate their robustness and generalization across different domains. The goal is to provide practitioners with a framework that can be easily extended to incorporate future advancements in UniDA and TS architectures. Our results highlight the critical influence of backbone selection in UniDA performance and enable a robustness analysis across various datasets and architectures.
Optimal Transport and Adaptive Thresholding for Universal Domain Adaptation on Time Series
Mar 14, 2025



Universal Domain Adaptation (UniDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain, even when their classes are not fully shared. Few dedicated UniDA methods exist for Time Series (TS), which remains a challenging case. In general, UniDA approaches align common class samples and detect unknown target samples from emerging classes. Such detection often results from thresholding a discriminability metric. The threshold value is typically either a fine-tuned hyperparameter or a fixed value, which limits the ability of the model to adapt to new data. Furthermore, discriminability metrics exhibit overconfidence for unknown samples, leading to misclassifications. This paper introduces UniJDOT, an optimal-transport-based method that accounts for the unknown target samples in the transport cost. Our method also proposes a joint decision space to improve the discriminability of the detection module. In addition, we use an auto-thresholding algorithm to reduce the dependence on fixed or fine-tuned thresholds. Finally, we rely on a Fourier transform-based layer inspired by the Fourier Neural Operator for better TS representation. Experiments on TS benchmarks demonstrate the discriminability, robustness, and state-of-the-art performance of UniJDOT.
Mamba base PKD for efficient knowledge compression
Mar 03, 2025Deep neural networks (DNNs) have remarkably succeeded in various image processing tasks. However, their large size and computational complexity present significant challenges for deploying them in resource-constrained environments. This paper presents an innovative approach for integrating Mamba Architecture within a Progressive Knowledge Distillation (PKD) process to address the challenge of reducing model complexity while maintaining accuracy in image classification tasks. The proposed framework distills a large teacher model into progressively smaller student models, designed using Mamba blocks. Each student model is trained using Selective-State-Space Models (S-SSM) within the Mamba blocks, focusing on important input aspects while reducing computational complexity. The work's preliminary experiments use MNIST and CIFAR-10 as datasets to demonstrate the effectiveness of this approach. For MNIST, the teacher model achieves 98% accuracy. A set of seven student models as a group retained 63% of the teacher's FLOPs, approximating the teacher's performance with 98% accuracy. The weak student used only 1% of the teacher's FLOPs and maintained 72% accuracy. Similarly, for CIFAR-10, the students achieved 1% less accuracy compared to the teacher, with the small student retaining 5% of the teacher's FLOPs to achieve 50% accuracy. These results confirm the flexibility and scalability of Mamba Architecture, which can be integrated into PKD, succeeding in the process of finding students as weak learners. The framework provides a solution for deploying complex neural networks in real-time applications with a reduction in computational cost.
SynWoodScape: Synthetic Surround-view Fisheye Camera Dataset for Autonomous Driving
Mar 09, 2022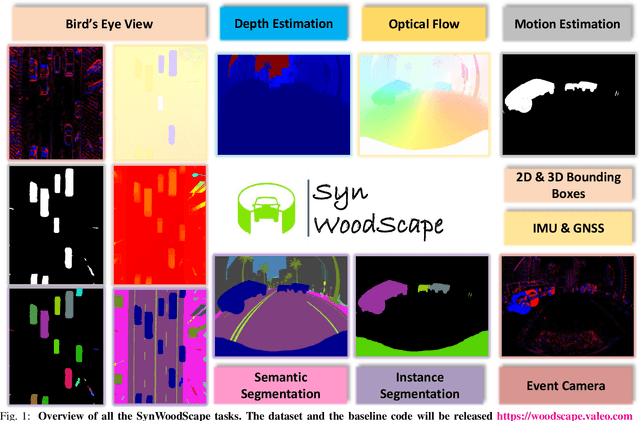
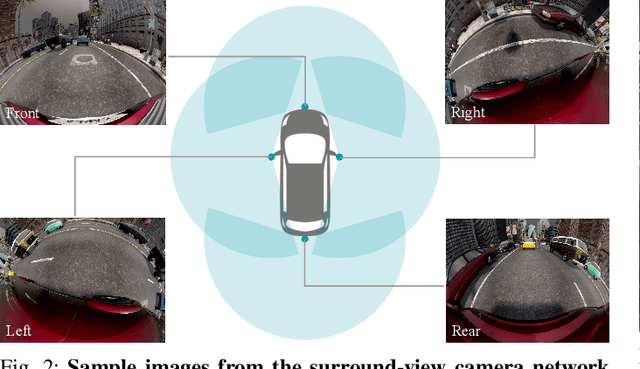
Surround-view cameras are a primary sensor for automated driving, used for near field perception. It is one of the most commonly used sensors in commercial vehicles. Four fisheye cameras with a 190{\deg} field of view cover the 360{\deg} around the vehicle. Due to its high radial distortion, the standard algorithms do not extend easily. Previously, we released the first public fisheye surround-view dataset named WoodScape. In this work, we release a synthetic version of the surround-view dataset, covering many of its weaknesses and extending it. Firstly, it is not possible to obtain ground truth for pixel-wise optical flow and depth. Secondly, WoodScape did not have all four cameras simultaneously in order to sample diverse frames. However, this means that multi-camera algorithms cannot be designed, which is enabled in the new dataset. We implemented surround-view fisheye geometric projections in CARLA Simulator matching WoodScape's configuration and created SynWoodScape. We release 80k images from the synthetic dataset with annotations for 10+ tasks. We also release the baseline code and supporting scripts.
Effect of Prior-based Losses on Segmentation Performance: A Benchmark
Jan 12, 2022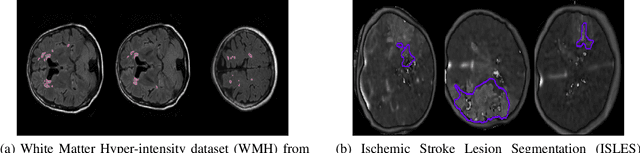
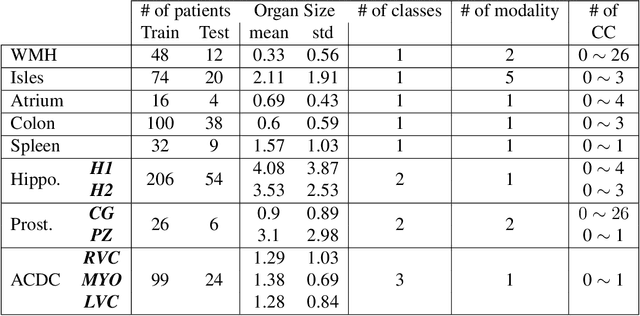

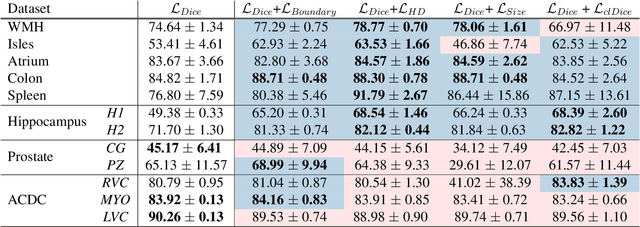
Today, deep convolutional neural networks (CNNs) have demonstrated state-of-the-art performance for medical image segmentation, on various imaging modalities and tasks. Despite early success, segmentation networks may still generate anatomically aberrant segmentations, with holes or inaccuracies near the object boundaries. To enforce anatomical plausibility, recent research studies have focused on incorporating prior knowledge such as object shape or boundary, as constraints in the loss function. Prior integrated could be low-level referring to reformulated representations extracted from the ground-truth segmentations, or high-level representing external medical information such as the organ's shape or size. Over the past few years, prior-based losses exhibited a rising interest in the research field since they allow integration of expert knowledge while still being architecture-agnostic. However, given the diversity of prior-based losses on different medical imaging challenges and tasks, it has become hard to identify what loss works best for which dataset. In this paper, we establish a benchmark of recent prior-based losses for medical image segmentation. The main objective is to provide intuition onto which losses to choose given a particular task or dataset. To this end, four low-level and high-level prior-based losses are selected. The considered losses are validated on 8 different datasets from a variety of medical image segmentation challenges including the Decathlon, the ISLES and the WMH challenge. Results show that whereas low-level prior-based losses can guarantee an increase in performance over the Dice loss baseline regardless of the dataset characteristics, high-level prior-based losses can increase anatomical plausibility as per data characteristics.
Breaking the Limits of Message Passing Graph Neural Networks
Jun 08, 2021
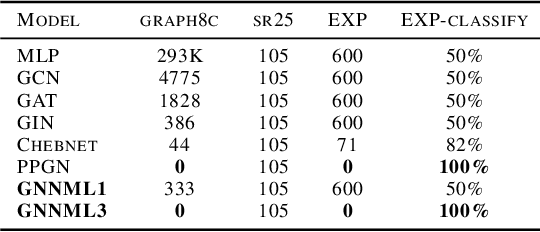
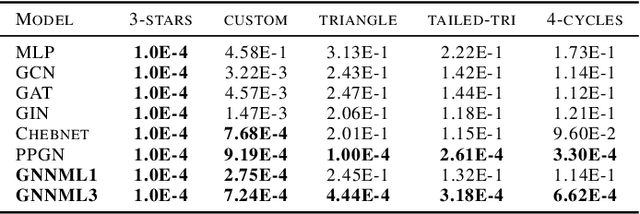
Since the Message Passing (Graph) Neural Networks (MPNNs) have a linear complexity with respect to the number of nodes when applied to sparse graphs, they have been widely implemented and still raise a lot of interest even though their theoretical expressive power is limited to the first order Weisfeiler-Lehman test (1-WL). In this paper, we show that if the graph convolution supports are designed in spectral-domain by a non-linear custom function of eigenvalues and masked with an arbitrary large receptive field, the MPNN is theoretically more powerful than the 1-WL test and experimentally as powerful as a 3-WL existing models, while remaining spatially localized. Moreover, by designing custom filter functions, outputs can have various frequency components that allow the convolution process to learn different relationships between a given input graph signal and its associated properties. So far, the best 3-WL equivalent graph neural networks have a computational complexity in $\mathcal{O}(n^3)$ with memory usage in $\mathcal{O}(n^2)$, consider non-local update mechanism and do not provide the spectral richness of output profile. The proposed method overcomes all these aforementioned problems and reaches state-of-the-art results in many downstream tasks.
High-level Prior-based Loss Functions for Medical Image Segmentation: A Survey
Nov 22, 2020
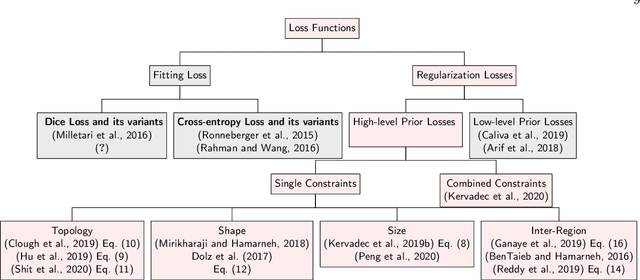
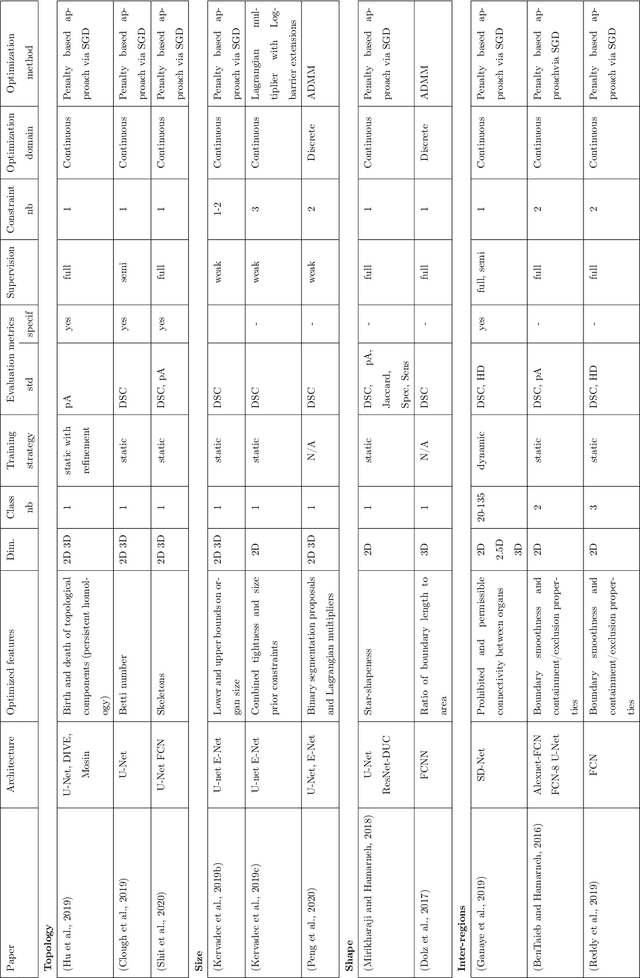
Today, deep convolutional neural networks (CNNs) have demonstrated state of the art performance for supervised medical image segmentation, across various imaging modalities and tasks. Despite early success, segmentation networks may still generate anatomically aberrant segmentations, with holes or inaccuracies near the object boundaries. To mitigate this effect, recent research works have focused on incorporating spatial information or prior knowledge to enforce anatomically plausible segmentation. If the integration of prior knowledge in image segmentation is not a new topic in classical optimization approaches, it is today an increasing trend in CNN based image segmentation, as shown by the growing literature on the topic. In this survey, we focus on high level prior, embedded at the loss function level. We categorize the articles according to the nature of the prior: the object shape, size, topology, and the inter-regions constraints. We highlight strengths and limitations of current approaches, discuss the challenge related to the design and the integration of prior-based losses, and the optimization strategies, and draw future research directions.
Statistical learning for sensor localization in wireless networks
May 11, 2020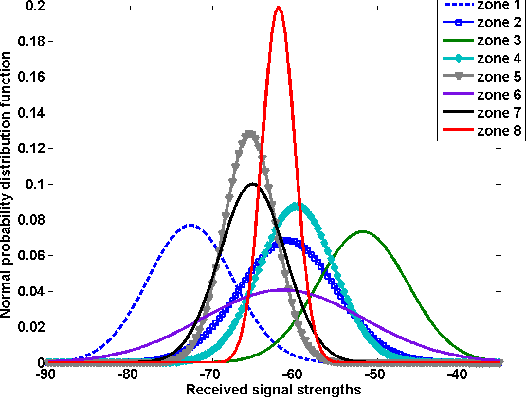
Indoor localization has become an important issue for wireless sensor networks. This paper presents a zoning-based localization technique that uses WiFi signals and works efficiently in indoor environments. The targeted area is composed of several zones, the objective being to determine the zone of the sensor using an observation model based on statistical learning.