 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FMD-cGAN: Fast Motion Deblurring using Conditional Generative Adversarial Networks
Dec 09, 2021

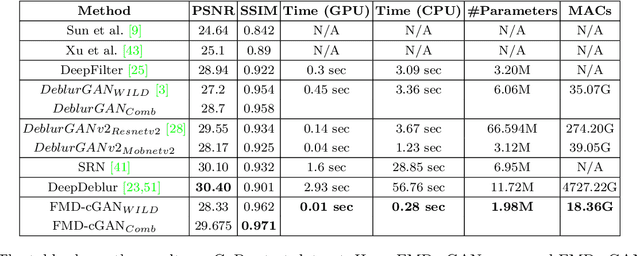


In this paper, we present a Fast Motion Deblurring-Conditional Generative Adversarial Network (FMD-cGAN) that helps in blind motion deblurring of a single image. FMD-cGAN delivers impressive structural similarity and visual appearance after deblurring an image. Like other deep neural network architectures, GANs also suffer from large model size (parameters) and computations. It is not easy to deploy the model on resource constraint devices such as mobile and robotics. With the help of MobileNet based architecture that consists of depthwise separable convolution, we reduce the model size and inference time, without losing the quality of the images. More specifically, we reduce the model size by 3-60x compare to the nearest competitor. The resulting compressed Deblurring cGAN faster than its closest competitors and even qualitative and quantitative results outperform various recently proposed state-of-the-art blind motion deblurring models. We can also use our model for real-time image deblurring tasks. The current experiment on the standard datasets shows the effectiveness of the proposed method.
6-DoF Pose Estimation of Household Objects for Robotic Manipulation: An Accessible Dataset and Benchmark
Mar 11, 2022
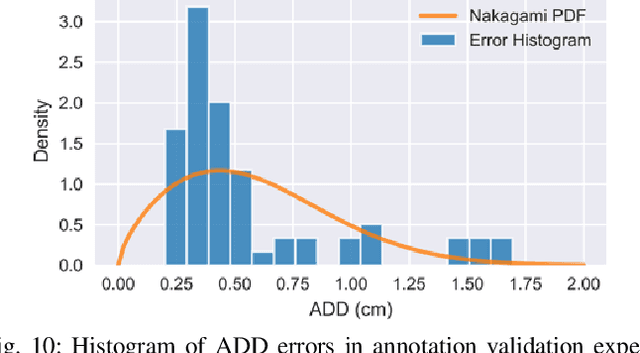
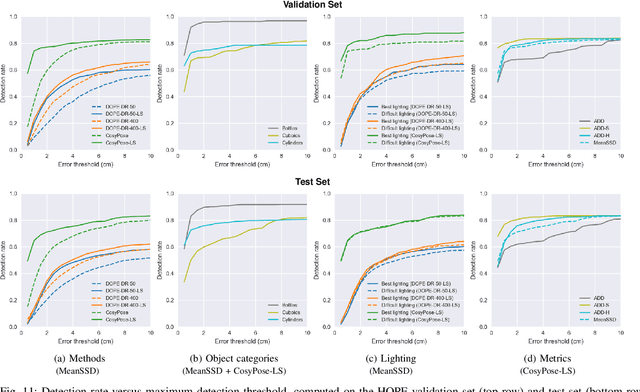
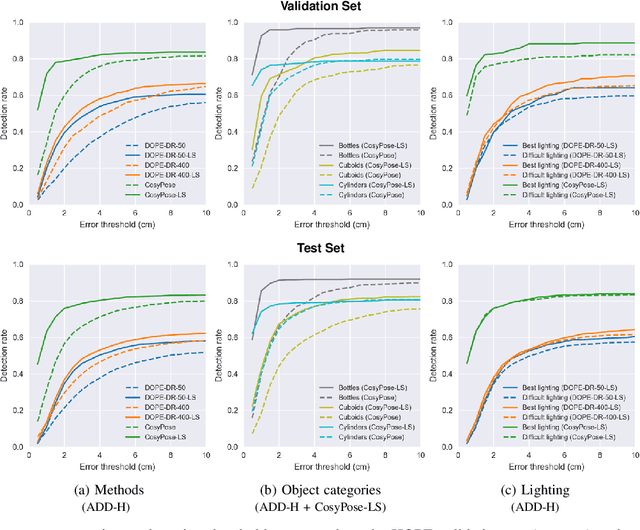
We present a new dataset for 6-DoF pose estimation of known objects, with a focus on robotic manipulation research. We propose a set of toy grocery objects, whose physical instantiations are readily available for purchase and are appropriately sized for robotic grasping and manipulation. We provide 3D scanned textured models of these objects, suitable for generating synthetic training data, as well as RGBD images of the objects in challenging, cluttered scenes exhibiting partial occlusion, extreme lighting variations, multiple instances per image, and a large variety of poses. Using semi-automated RGBD-to-model texture correspondences, the images are annotated with ground truth poses that were verified empirically to be accurate to within a few millimeters. We also propose a new pose evaluation metric called {ADD-H} based upon the Hungarian assignment algorithm that is robust to symmetries in object geometry without requiring their explicit enumeration. We share pre-trained pose estimators for all the toy grocery objects, along with their baseline performance on both validation and test sets. We offer this dataset to the community to help connect the efforts of computer vision researchers with the needs of roboticists.
Chromatic and spatial analysis of one-pixel attacks against an image classifier
May 28, 2021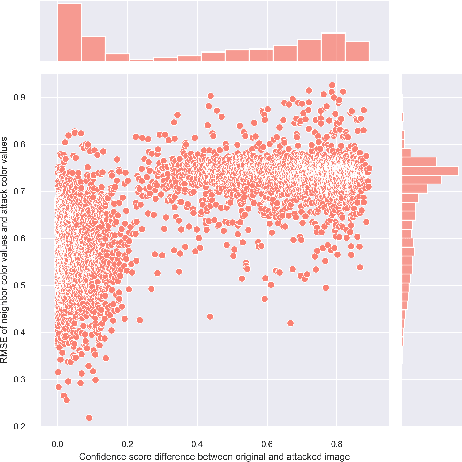
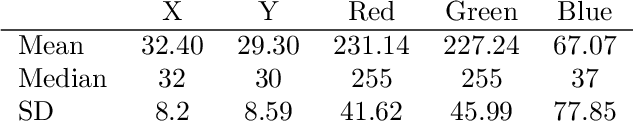
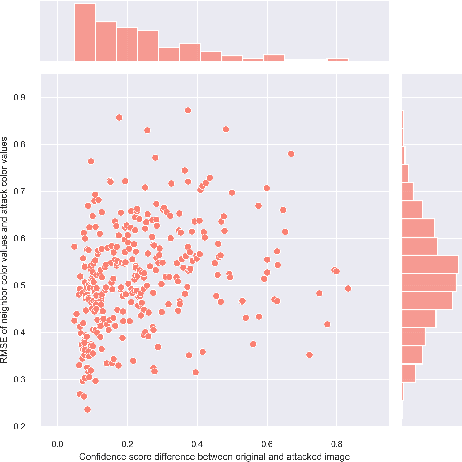
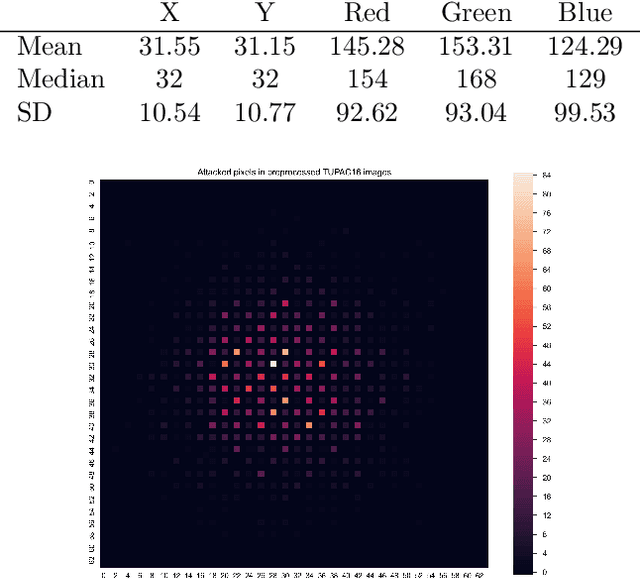
One-pixel attack is a curious way of deceiving neural network classifier by changing only one pixel in the input image. The full potential and boundaries of this attack method are not yet fully understood. In this research, the successful and unsuccessful attacks are studied in more detail to illustrate the working mechanisms of a one-pixel attack. The data comes from our earlier studies where we applied the attack against medical imaging. We used a real breast cancer tissue dataset and a real classifier as the attack target. This research presents ways to analyze chromatic and spatial distributions of one-pixel attacks. In addition, we present one-pixel attack confidence maps to illustrate the behavior of the target classifier. We show that the more effective attacks change the color of the pixel more, and that the successful attacks are situated at the center of the images. This kind of analysis is not only useful for understanding the behavior of the attack but also the qualities of the classifying neural network.
An Improved Iterative Neural Network for High-Quality Image-Domain Material Decomposition in Dual-Energy CT
Dec 02, 2020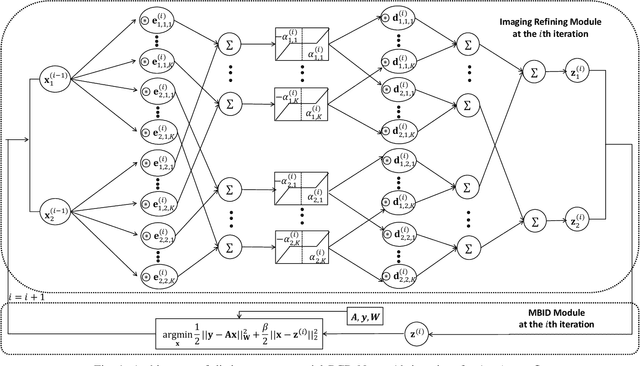
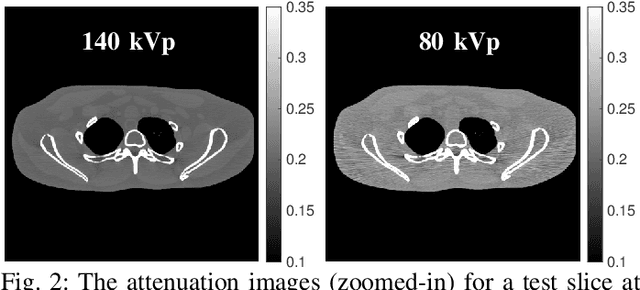
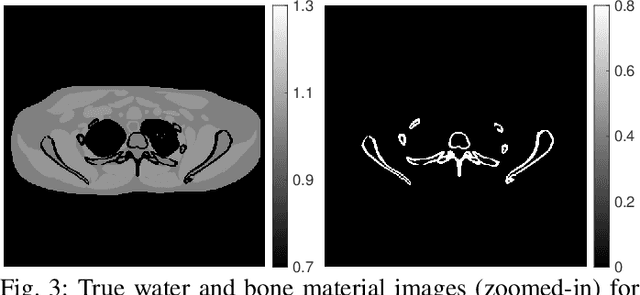
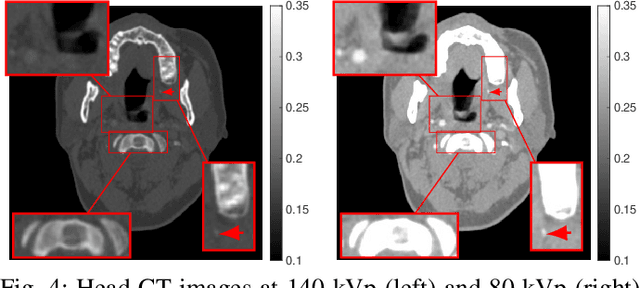
Dual-energy computed tomography (DECT) has been widely used in many applications that need material decomposition. Image-domain methods directly decompose material images from high- and low-energy attenuation images, and thus, are susceptible to noise and artifacts on attenuation images. To obtain high-quality material images, various data-driven methods have been proposed. Iterative neural network (INN) methods combine regression NNs and model-based image reconstruction algorithm. INNs reduced the generalization error of (noniterative) deep regression NNs, and achieved high-quality reconstruction in diverse medical imaging applications. BCD-Net is a recent INN architecture that incorporates imaging refining NNs into the block coordinate descent (BCD) model-based image reconstruction algorithm. We propose a new INN architecture, distinct cross-material BCD-Net, for DECT material decomposition. The proposed INN architecture uses distinct cross-material convolutional neural network (CNN) in image refining modules, and uses image decomposition physics in image reconstruction modules. The distinct cross-material CNN refiners incorporate distinct encoding-decoding filters and cross-material model that captures correlations between different materials. We interpret the distinct cross-material CNN refiner with patch perspective. Numerical experiments with extended cardiactorso (XCAT) phantom and clinical data show that proposed distinct cross-material BCD-Net significantly improves the image quality over several image-domain material decomposition methods, including a conventional model-based image decomposition (MBID) method using an edge-preserving regularizer, a state-of-the-art MBID method using pre-learned material-wise sparsifying transforms, and a noniterative deep CNN denoiser.
One Network Doesn't Rule Them All: Moving Beyond Handcrafted Architectures in Self-Supervised Learning
Mar 15, 2022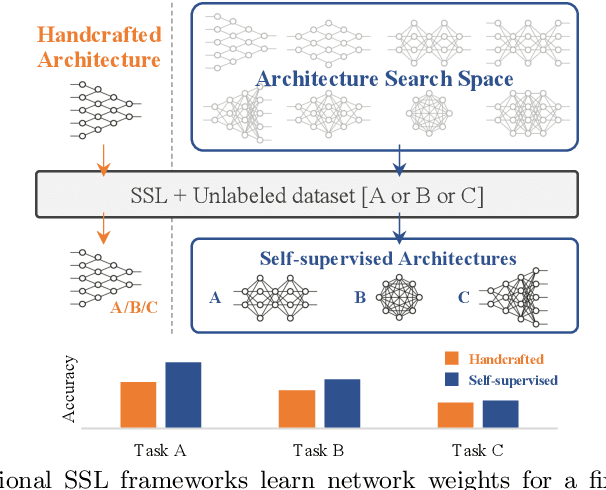
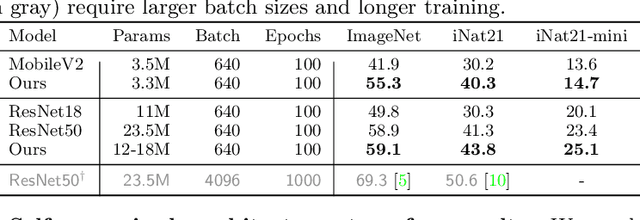
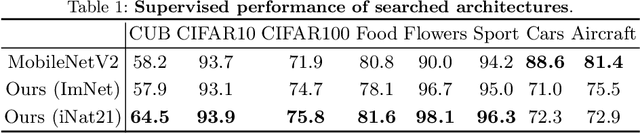
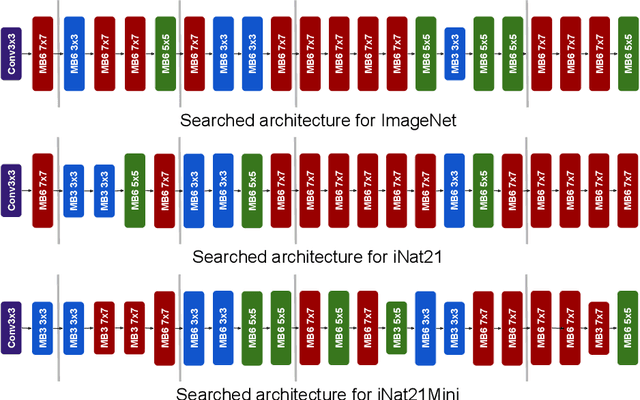
The current literature on self-supervised learning (SSL) focuses on developing learning objectives to train neural networks more effectively on unlabeled data. The typical development process involves taking well-established architectures, e.g., ResNet demonstrated on ImageNet, and using them to evaluate newly developed objectives on downstream scenarios. While convenient, this does not take into account the role of architectures which has been shown to be crucial in the supervised learning literature. In this work, we establish extensive empirical evidence showing that a network architecture plays a significant role in SSL. We conduct a large-scale study with over 100 variants of ResNet and MobileNet architectures and evaluate them across 11 downstream scenarios in the SSL setting. We show that there is no one network that performs consistently well across the scenarios. Based on this, we propose to learn not only network weights but also architecture topologies in the SSL regime. We show that "self-supervised architectures" outperform popular handcrafted architectures (ResNet18 and MobileNetV2) while performing competitively with the larger and computationally heavy ResNet50 on major image classification benchmarks (ImageNet-1K, iNat2021, and more). Our results suggest that it is time to consider moving beyond handcrafted architectures in SSL and start thinking about incorporating architecture search into self-supervised learning objectives.
EDIT: Exemplar-Domain Aware Image-to-Image Translation
Nov 24, 2019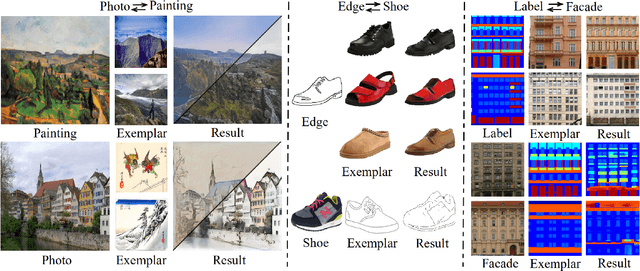
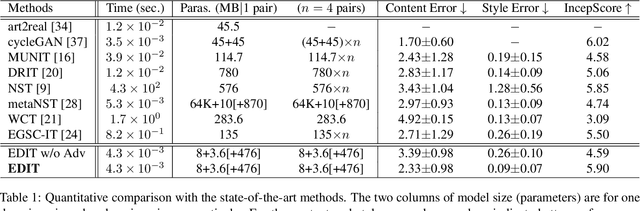
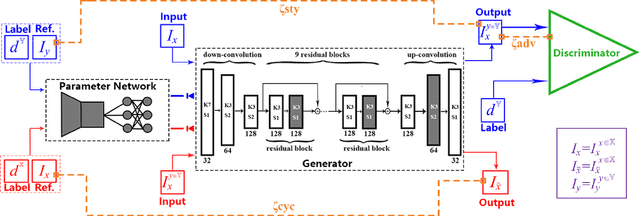
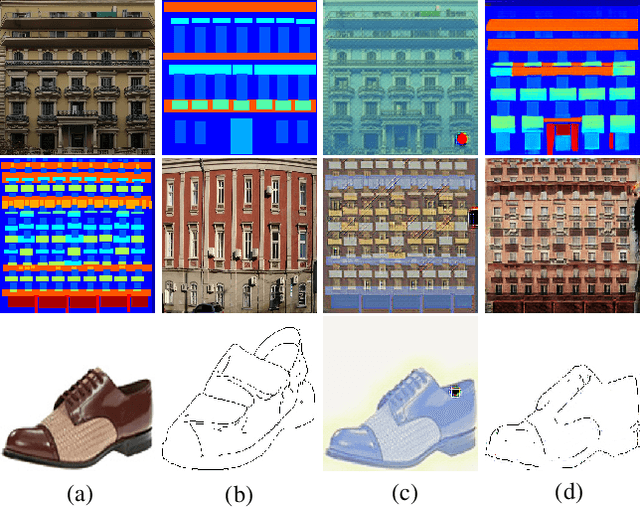
Image-to-image translation is to convert an image of the certain style to another of the target style with the content preserved. A desired translator should be capable to generate diverse results in a controllable (many-to-many) fashion. To this end, we design a novel generative adversarial network, namely exemplar-domain aware image-to-image translator (EDIT for short). The principle behind is that, for images from multiple domains, the content features can be obtained by a uniform extractor, while (re-)stylization is achieved by mapping the extracted features specifically to different purposes (domains and exemplars). The generator of our EDIT comprises of a part of blocks configured by shared parameters, and the rest by varied parameters exported by an exemplar-domain aware parameter network. In addition, a discriminator is equipped during the training phase to guarantee the output satisfying the distribution of the target domain. Our EDIT can flexibly and effectively work on multiple domains and arbitrary exemplars in a unified neat model. We conduct experiments to show the efficacy of our design, and reveal its advances over other state-of-the-art methods both quantitatively and qualitatively.
Robust Self-Ensembling Network for Hyperspectral Image Classification
Apr 08, 2021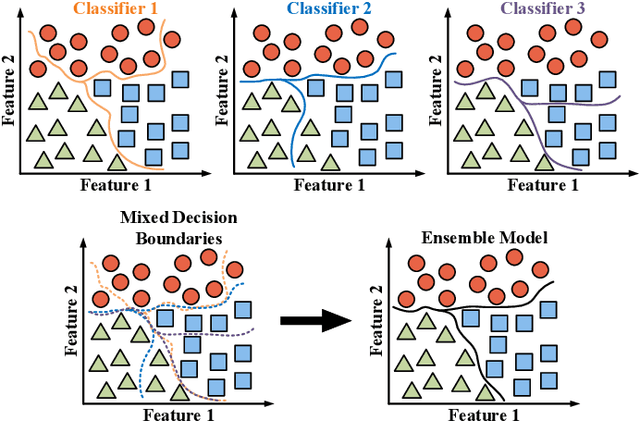
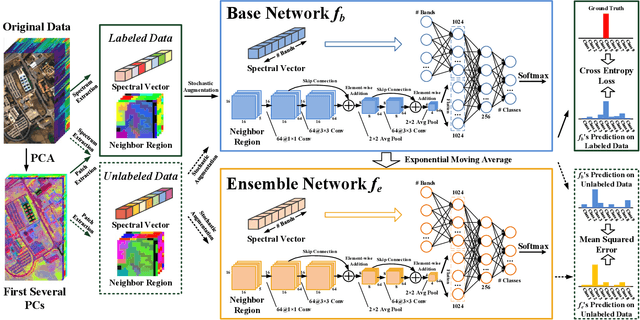
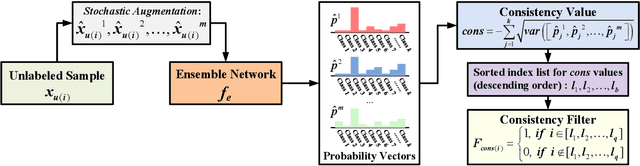
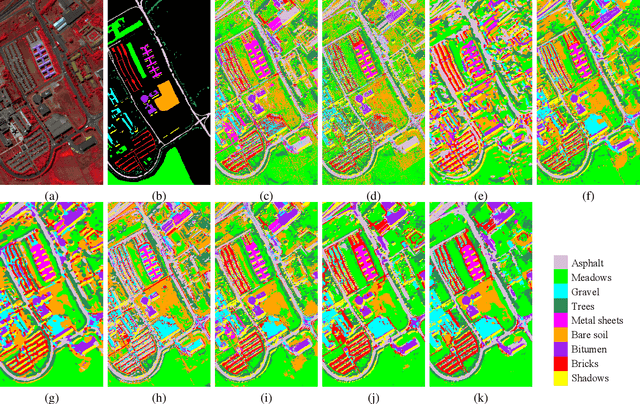
Recent research has shown the great potential of deep learning algorithms in the hyperspectral image (HSI) classification task. Nevertheless, training these models usually requires a large amount of labeled data. Since the collection of pixel-level annotations for HSI is laborious and time-consuming, developing algorithms that can yield good performance in the small sample size situation is of great significance. In this study, we propose a robust self-ensembling network (RSEN) to address this problem. The proposed RSEN consists of two subnetworks including a base network and an ensemble network. With the constraint of both the supervised loss from the labeled data and the unsupervised loss from the unlabeled data, the base network and the ensemble network can learn from each other, achieving the self-ensembling mechanism. To the best of our knowledge, the proposed method is the first attempt to introduce the self-ensembling technique into the HSI classification task, which provides a different view on how to utilize the unlabeled data in HSI to assist the network training. We further propose a novel consistency filter to increase the robustness of self-ensembling learning. Extensive experiments on three benchmark HSI datasets demonstrate that the proposed algorithm can yield competitive performance compared with the state-of-the-art methods.
When Accuracy Meets Privacy: Two-Stage Federated Transfer Learning Framework in Classification of Medical Images on Limited Data: A COVID-19 Case Study
Mar 24, 2022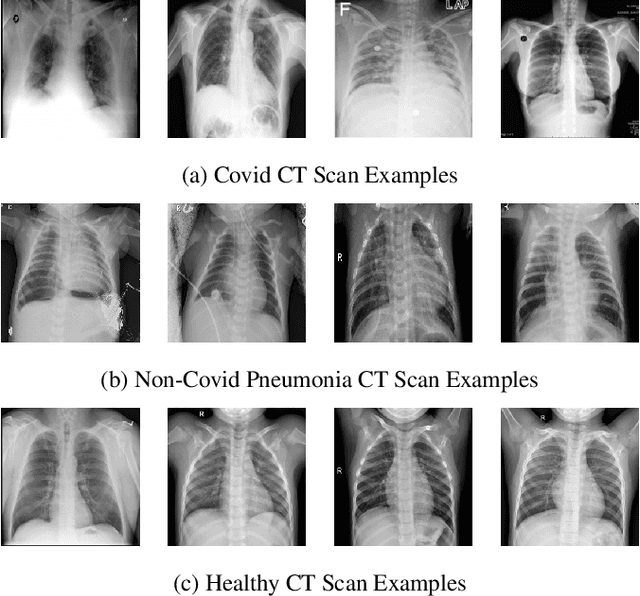
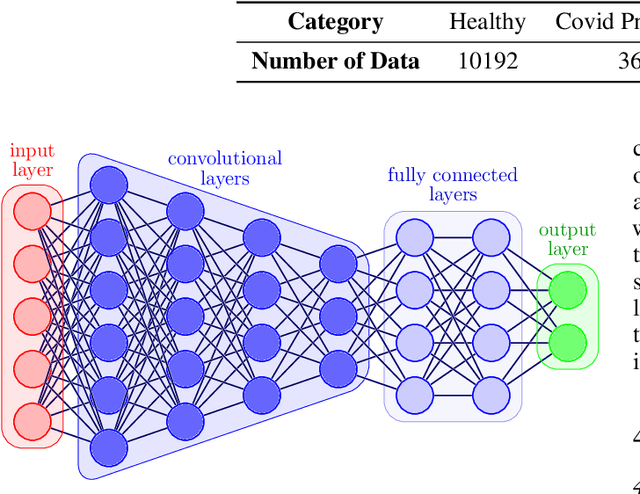
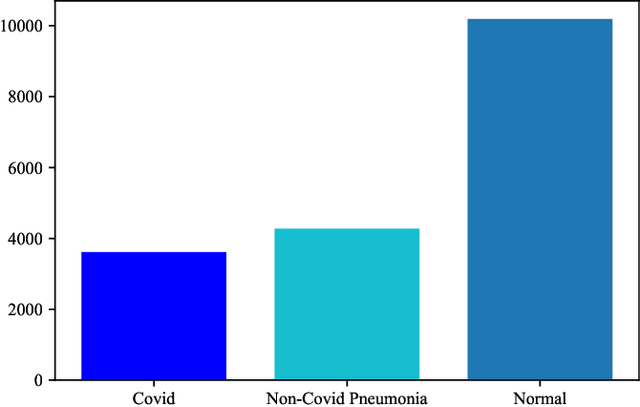

COVID-19 pandemic has spread rapidly and caused a shortage of global medical resources. The efficiency of COVID-19 diagnosis has become highly significant. As deep learning and convolutional neural network (CNN) has been widely utilized and been verified in analyzing medical images, it has become a powerful tool for computer-assisted diagnosis. However, there are two most significant challenges in medical image classification with the help of deep learning and neural networks, one of them is the difficulty of acquiring enough samples, which may lead to model overfitting. Privacy concerns mainly bring the other challenge since medical-related records are often deemed patients' private information and protected by laws such as GDPR and HIPPA. Federated learning can ensure the model training is decentralized on different devices and no data is shared among them, which guarantees privacy. However, with data located on different devices, the accessible data of each device could be limited. Since transfer learning has been verified in dealing with limited data with good performance, therefore, in this paper, We made a trial to implement federated learning and transfer learning techniques using CNNs to classify COVID-19 using lung CT scans. We also explored the impact of dataset distribution at the client-side in federated learning and the number of training epochs a model is trained. Finally, we obtained very high performance with federated learning, demonstrating our success in leveraging accuracy and privacy.
Benchmarking and Comparing Multi-exposure Image Fusion Algorithms
Jul 30, 2020
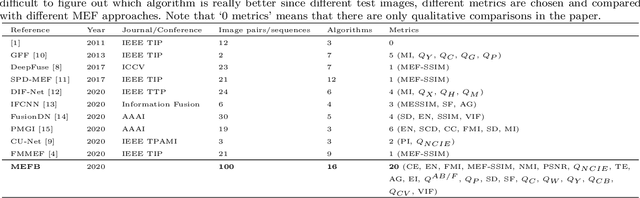

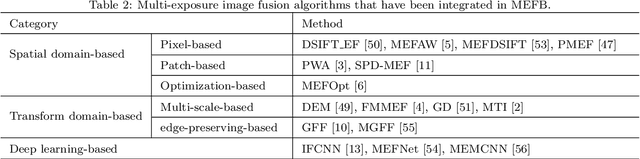
Multi-exposure image fusion (MEF) is an important area in computer vision and has attracted increasing interests in recent years. Apart from conventional algorithms, deep learning techniques have also been applied to multi-exposure image fusion. However, although much efforts have been made on developing MEF algorithms, the lack of benchmark makes it difficult to perform fair and comprehensive performance comparison among MEF algorithms, thus significantly hindering the development of this field. In this paper, we fill this gap by proposing a benchmark for multi-exposure image fusion (MEFB) which consists of a test set of 100 image pairs, a code library of 16 algorithms, 20 evaluation metrics, 1600 fused images and a software toolkit. To the best of our knowledge, this is the first benchmark in the field of multi-exposure image fusion. Extensive experiments have been conducted using MEFB for comprehensive performance evaluation and for identifying effective algorithms. We expect that MEFB will serve as an effective platform for researchers to compare performances and investigate MEF algorithms.
Event-based Video Reconstruction via Potential-assisted Spiking Neural Network
Jan 25, 2022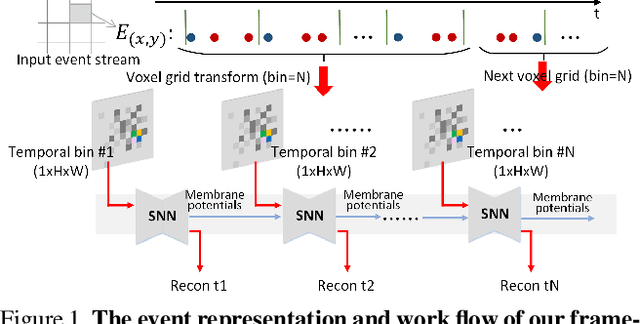
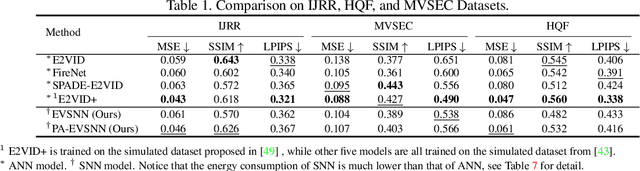
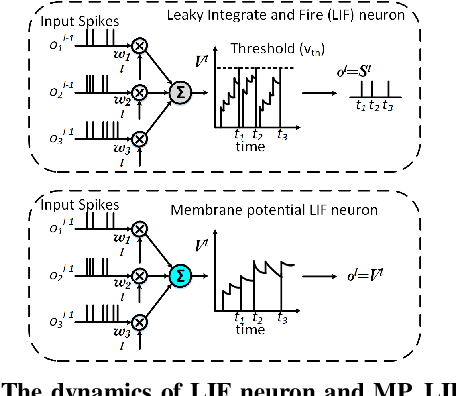
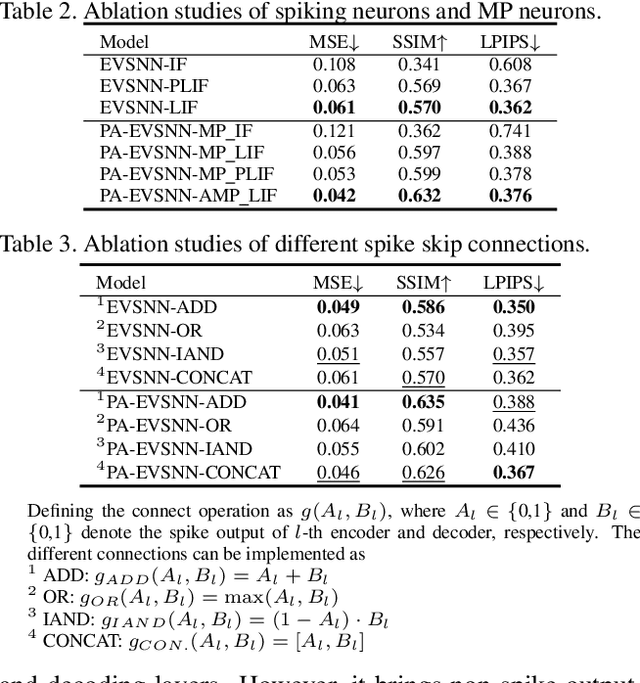
Neuromorphic vision sensor is a new bio-inspired imaging paradigm that reports asynchronous, continuously per-pixel brightness changes called `events' with high temporal resolution and high dynamic range. So far, the event-based image reconstruction methods are based on artificial neural networks (ANN) or hand-crafted spatiotemporal smoothing techniques. In this paper, we first implement the image reconstruction work via fully spiking neural network (SNN) architecture. As the bio-inspired neural networks, SNNs operating with asynchronous binary spikes distributed over time, can potentially lead to greater computational efficiency on event-driven hardware. We propose a novel Event-based Video reconstruction framework based on a fully Spiking Neural Network (EVSNN), which utilizes Leaky-Integrate-and-Fire (LIF) neuron and Membrane Potential (MP) neuron. We find that the spiking neurons have the potential to store useful temporal information (memory) to complete such time-dependent tasks. Furthermore, to better utilize the temporal information, we propose a hybrid potential-assisted framework (PA-EVSNN) using the membrane potential of spiking neuron. The proposed neuron is referred as Adaptive Membrane Potential (AMP) neuron, which adaptively updates the membrane potential according to the input spikes. The experimental results demonstrate that our models achieve comparable performance to ANN-based models on IJRR, MVSEC, and HQF datasets. The energy consumptions of EVSNN and PA-EVSNN are 19.36$\times$ and 7.75$\times$ more computationally efficient than their ANN architectures, respectively.