 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-PhyRLHF: Reinforcement Learning Framework for Multimodal Physics Question-Answering
Apr 19, 2024



Recent advancements in LLMs have shown their significant potential in tasks like text summarization and generation. Yet, they often encounter difficulty while solving complex physics problems that require arithmetic calculation and a good understanding of concepts. Moreover, many physics problems include images that contain important details required to understand the problem's context. We propose an LMM-based chatbot to answer multimodal physics MCQs. For domain adaptation, we utilize the MM-PhyQA dataset comprising Indian high school-level multimodal physics problems. To improve the LMM's performance, we experiment with two techniques, RLHF (Reinforcement Learning from Human Feedback) and Image Captioning. In image captioning, we add a detailed explanation of the diagram in each image, minimizing hallucinations and image processing errors. We further explore the integration of Reinforcement Learning from Human Feedback (RLHF) methodology inspired by the ranking approach in RLHF to enhance the human-like problem-solving abilities of the models. The RLHF approach incorporates human feedback into the learning process of LLMs, improving the model's problem-solving skills, truthfulness, and reasoning capabilities, minimizing the hallucinations in the answers, and improving the quality instead of using vanilla-supervised fine-tuned models. We employ the LLaVA open-source model to answer multimodal physics MCQs and compare the performance with and without using RLHF.
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Apr 19, 2024The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called "MathQuest" sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
* 10 pages, 3 figures, NeurIPS 2023 Workshop on Generative AI for Education (GAIED)
FMD-cGAN: Fast Motion Deblurring using Conditional Generative Adversarial Networks
Dec 09, 2021
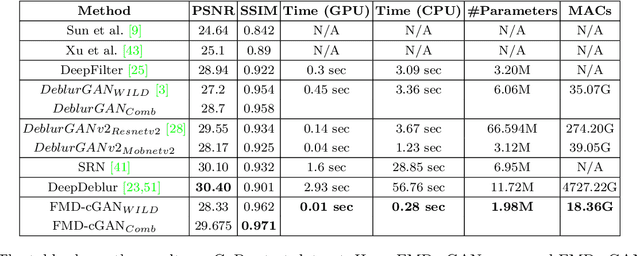


In this paper, we present a Fast Motion Deblurring-Conditional Generative Adversarial Network (FMD-cGAN) that helps in blind motion deblurring of a single image. FMD-cGAN delivers impressive structural similarity and visual appearance after deblurring an image. Like other deep neural network architectures, GANs also suffer from large model size (parameters) and computations. It is not easy to deploy the model on resource constraint devices such as mobile and robotics. With the help of MobileNet based architecture that consists of depthwise separable convolution, we reduce the model size and inference time, without losing the quality of the images. More specifically, we reduce the model size by 3-60x compare to the nearest competitor. The resulting compressed Deblurring cGAN faster than its closest competitors and even qualitative and quantitative results outperform various recently proposed state-of-the-art blind motion deblurring models. We can also use our model for real-time image deblurring tasks. The current experiment on the standard datasets shows the effectiveness of the proposed method.