 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSToRM: Supervised Token Reduction for Multi-modal LLMs toward efficient end-to-end autonomous driving
Feb 12, 2026In autonomous driving, end-to-end (E2E) driving systems that predict control commands directly from sensor data have achieved significant advancements. For safe driving in unexpected scenarios, these systems may additionally rely on human interventions such as natural language instructions. Using a multi-modal large language model (MLLM) facilitates human-vehicle interaction and can improve performance in such scenarios. However, this approach requires substantial computational resources due to its reliance on an LLM and numerous visual tokens from sensor inputs, which are limited in autonomous vehicles. Many MLLM studies have explored reducing visual tokens, but often suffer end-task performance degradation compared to using all tokens. To enable efficient E2E driving while maintaining performance comparable to using all tokens, this paper proposes the first Supervised Token Reduction framework for multi-modal LLMs (SToRM). The proposed framework consists of three key elements. First, a lightweight importance predictor with short-term sliding windows estimates token importance scores. Second, a supervised training approach uses an auxiliary path to obtain pseudo-supervision signals from an all-token LLM pass. Third, an anchor-context merging module partitions tokens into anchors and context tokens, and merges context tokens into relevant anchors to reduce redundancy while minimizing information loss. Experiments on the LangAuto benchmark show that SToRM outperforms state-of-the-art E2E driving MLLMs under the same reduced-token budget, maintaining all-token performance while reducing computational cost by up to 30x.
Equilibrium contrastive learning for imbalanced image classification
Feb 10, 2026Contrastive learning (CL) is a predominant technique in image classification, but they showed limited performance with an imbalanced dataset. Recently, several supervised CL methods have been proposed to promote an ideal regular simplex geometric configuration in the representation space-characterized by intra-class feature collapse and uniform inter-class mean spacing, especially for imbalanced datasets. In particular, existing prototype-based methods include class prototypes, as additional samples to consider all classes. However, the existing CL methods suffer from two limitations. First, they do not consider the alignment between the class means/prototypes and classifiers, which could lead to poor generalization. Second, existing prototype-based methods treat prototypes as only one additional sample per class, making their influence depend on the number of class instances in a batch and causing unbalanced contributions across classes. To address these limitations, we propose Equilibrium Contrastive Learning (ECL), a supervised CL framework designed to promote geometric equilibrium, where class features, means, and classifiers are harmoniously balanced under data imbalance. The proposed ECL framework uses two main components. First, ECL promotes the representation geometric equilibrium (i.e., a regular simplex geometry characterized by collapsed class samples and uniformly distributed class means), while balancing the contributions of class-average features and class prototypes. Second, ECL establishes a classifier-class center geometric equilibrium by aligning classifier weights and class prototypes. We ran experiments with three long-tailed datasets, the CIFAR-10(0)-LT, ImageNet-LT, and the two imbalanced medical datasets, the ISIC 2019 and our constructed LCCT dataset. Results show that ECL outperforms existing SOTA supervised CL methods designed for imbalanced classification.
MoTDiff: High-resolution Motion Trajectory estimation from a single blurred image using Diffusion models
Oct 30, 2025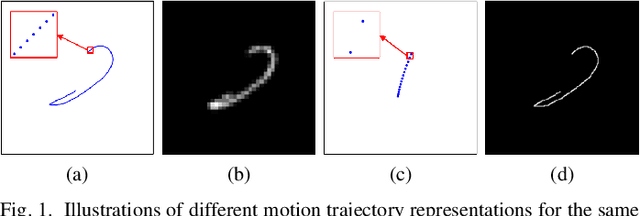
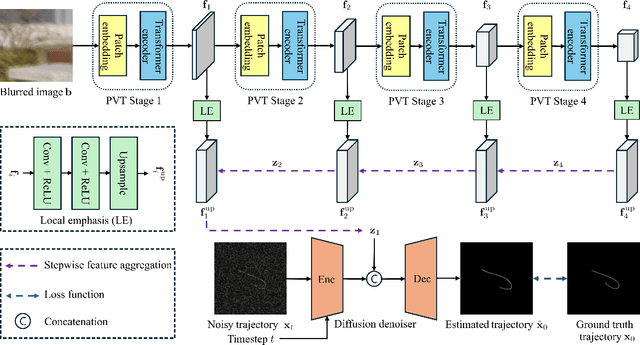


Accurate estimation of motion information is crucial in diverse computational imaging and computer vision applications. Researchers have investigated various methods to extract motion information from a single blurred image, including blur kernels and optical flow. However, existing motion representations are often of low quality, i.e., coarse-grained and inaccurate. In this paper, we propose the first high-resolution (HR) Motion Trajectory estimation framework using Diffusion models (MoTDiff). Different from existing motion representations, we aim to estimate an HR motion trajectory with high-quality from a single motion-blurred image. The proposed MoTDiff consists of two key components: 1) a new conditional diffusion framework that uses multi-scale feature maps extracted from a single blurred image as a condition, and 2) a new training method that can promote precise identification of a fine-grained motion trajectory, consistent estimation of overall shape and position of a motion path, and pixel connectivity along a motion trajectory. Our experiments demonstrate that the proposed MoTDiff can outperform state-of-the-art methods in both blind image deblurring and coded exposure photography applications.
Autoregression-free video prediction using diffusion model for mitigating error propagation
May 28, 2025Existing long-term video prediction methods often rely on an autoregressive video prediction mechanism. However, this approach suffers from error propagation, particularly in distant future frames. To address this limitation, this paper proposes the first AutoRegression-Free (ARFree) video prediction framework using diffusion models. Different from an autoregressive video prediction mechanism, ARFree directly predicts any future frame tuples from the context frame tuple. The proposed ARFree consists of two key components: 1) a motion prediction module that predicts a future motion using motion feature extracted from the context frame tuple; 2) a training method that improves motion continuity and contextual consistency between adjacent future frame tuples. Our experiments with two benchmark datasets show that the proposed ARFree video prediction framework outperforms several state-of-the-art video prediction methods.
MAMS: Model-Agnostic Module Selection Framework for Video Captioning
Jan 30, 2025



Multi-modal transformers are rapidly gaining attention in video captioning tasks. Existing multi-modal video captioning methods typically extract a fixed number of frames, which raises critical challenges. When a limited number of frames are extracted, important frames with essential information for caption generation may be missed. Conversely, extracting an excessive number of frames includes consecutive frames, potentially causing redundancy in visual tokens extracted from consecutive video frames. To extract an appropriate number of frames for each video, this paper proposes the first model-agnostic module selection framework in video captioning that has two main functions: (1) selecting a caption generation module with an appropriate size based on visual tokens extracted from video frames, and (2) constructing subsets of visual tokens for the selected caption generation module. Furthermore, we propose a new adaptive attention masking scheme that enhances attention on important visual tokens. Our experiments on three different benchmark datasets demonstrate that the proposed framework significantly improves the performance of three recent video captioning models.
LaB-CL: Localized and Balanced Contrastive Learning for improving parking slot detection
Oct 10, 2024



Parking slot detection is an essential technology in autonomous parking systems. In general, the classification problem of parking slot detection consists of two tasks, a task determining whether localized candidates are junctions of parking slots or not, and the other that identifies a shape of detected junctions. Both classification tasks can easily face biased learning toward the majority class, degrading classification performances. Yet, the data imbalance issue has been overlooked in parking slot detection. We propose the first supervised contrastive learning framework for parking slot detection, Localized and Balanced Contrastive Learning for improving parking slot detection (LaB-CL). The proposed LaB-CL framework uses two main approaches. First, we propose to include class prototypes to consider representations from all classes in every mini batch, from the local perspective. Second, we propose a new hard negative sampling scheme that selects local representations with high prediction error. Experiments with the benchmark dataset demonstrate that the proposed LaB-CL framework can outperform existing parking slot detection methods.
DX2CT: Diffusion Model for 3D CT Reconstruction from Bi or Mono-planar 2D X-ray(s)
Sep 13, 2024Computational tomography (CT) provides high-resolution medical imaging, but it can expose patients to high radiation. X-ray scanners have low radiation exposure, but their resolutions are low. This paper proposes a new conditional diffusion model, DX2CT, that reconstructs three-dimensional (3D) CT volumes from bi or mono-planar X-ray image(s). Proposed DX2CT consists of two key components: 1) modulating feature maps extracted from two-dimensional (2D) X-ray(s) with 3D positions of CT volume using a new transformer and 2) effectively using the modulated 3D position-aware feature maps as conditions of DX2CT. In particular, the proposed transformer can provide conditions with rich information of a target CT slice to the conditional diffusion model, enabling high-quality CT reconstruction. Our experiments with the bi or mono-planar X-ray(s) benchmark datasets show that proposed DX2CT outperforms several state-of-the-art methods. Our codes and model will be available at: https://www.github.com/intyeger/DX2CT.
Improving Neural Radiance Field using Near-Surface Sampling with Point Cloud Generation
Oct 06, 2023Neural radiance field (NeRF) is an emerging view synthesis method that samples points in a three-dimensional (3D) space and estimates their existence and color probabilities. The disadvantage of NeRF is that it requires a long training time since it samples many 3D points. In addition, if one samples points from occluded regions or in the space where an object is unlikely to exist, the rendering quality of NeRF can be degraded. These issues can be solved by estimating the geometry of 3D scene. This paper proposes a near-surface sampling framework to improve the rendering quality of NeRF. To this end, the proposed method estimates the surface of a 3D object using depth images of the training set and sampling is performed around there only. To obtain depth information on a novel view, the paper proposes a 3D point cloud generation method and a simple refining method for projected depth from a point cloud. Experimental results show that the proposed near-surface sampling NeRF framework can significantly improve the rendering quality, compared to the original NeRF and a state-of-the-art depth-based NeRF method. In addition, one can significantly accelerate the training time of a NeRF model with the proposed near-surface sampling framework.
End-to-End Driving via Self-Supervised Imitation Learning Using Camera and LiDAR Data
Aug 28, 2023



In autonomous driving, the end-to-end (E2E) driving approach that predicts vehicle control signals directly from sensor data is rapidly gaining attention. To learn a safe E2E driving system, one needs an extensive amount of driving data and human intervention. Vehicle control data is constructed by many hours of human driving, and it is challenging to construct large vehicle control datasets. Often, publicly available driving datasets are collected with limited driving scenes, and collecting vehicle control data is only available by vehicle manufacturers. To address these challenges, this paper proposes the first self-supervised learning framework, self-supervised imitation learning (SSIL), that can learn E2E driving networks without using driving command data. To construct pseudo steering angle data, proposed SSIL predicts a pseudo target from the vehicle's poses at the current and previous time points that are estimated with light detection and ranging sensors. Our numerical experiments demonstrate that the proposed SSIL framework achieves comparable E2E driving accuracy with the supervised learning counterpart. In addition, our qualitative analyses using a conventional visual explanation tool show that trained NNs by proposed SSIL and the supervision counterpart attend similar objects in making predictions.
Self-supervised regression learning using domain knowledge: Applications to improving self-supervised denoising in imaging
May 10, 2022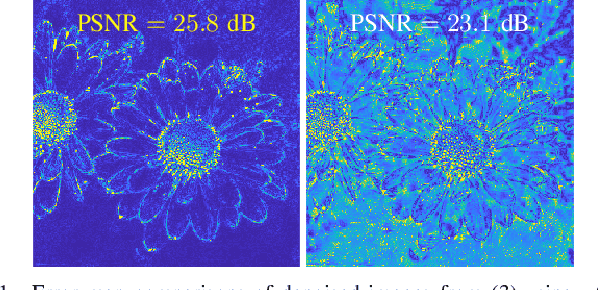
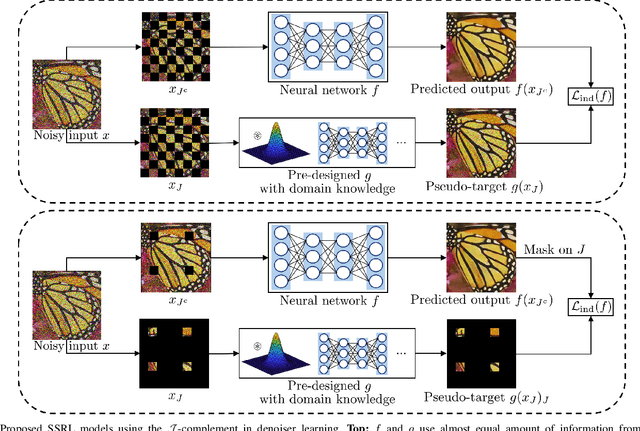
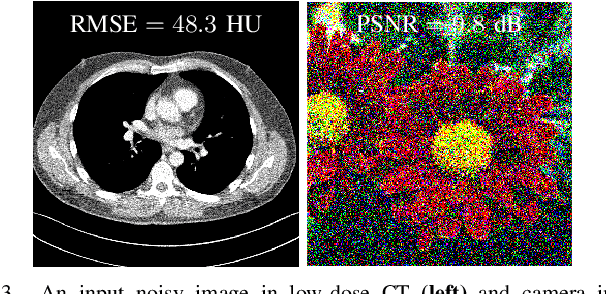
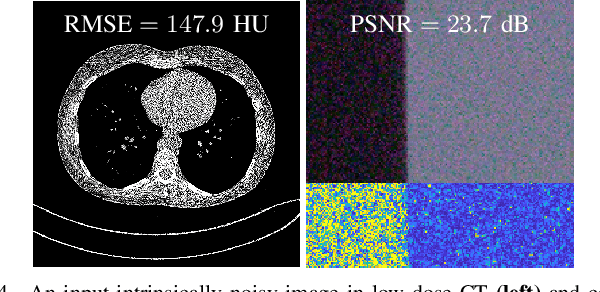
Regression that predicts continuous quantity is a central part of applications using computational imaging and computer vision technologies. Yet, studying and understanding self-supervised learning for regression tasks - except for a particular regression task, image denoising - have lagged behind. This paper proposes a general self-supervised regression learning (SSRL) framework that enables learning regression neural networks with only input data (but without ground-truth target data), by using a designable pseudo-predictor that encapsulates domain knowledge of a specific application. The paper underlines the importance of using domain knowledge by showing that under different settings, the better pseudo-predictor can lead properties of SSRL closer to those of ordinary supervised learning. Numerical experiments for low-dose computational tomography denoising and camera image denoising demonstrate that proposed SSRL significantly improves the denoising quality over several existing self-supervised denoising methods.