 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Stratification of carotid atheromatous plaque using interpretable deep learning methods on B-mode ultrasound images
Feb 04, 2022
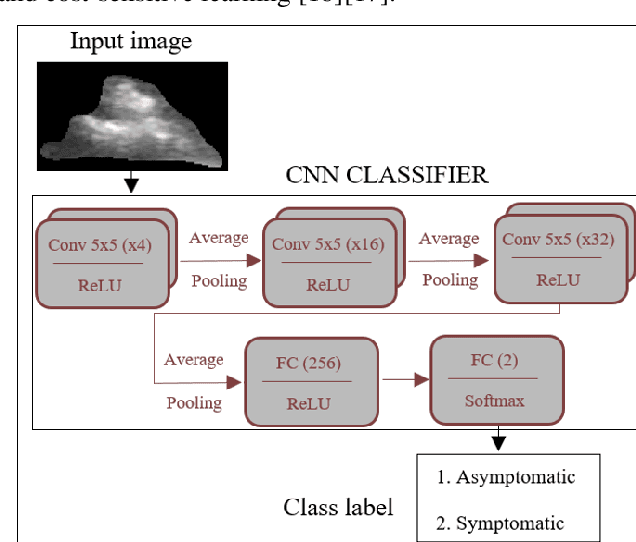
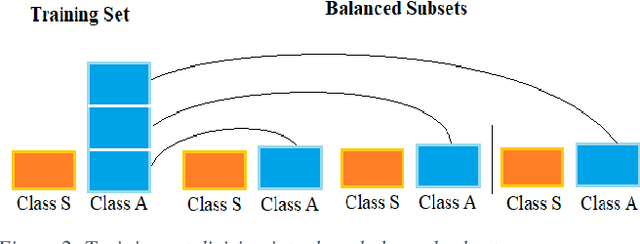
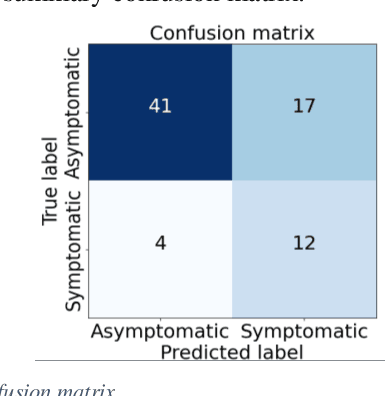
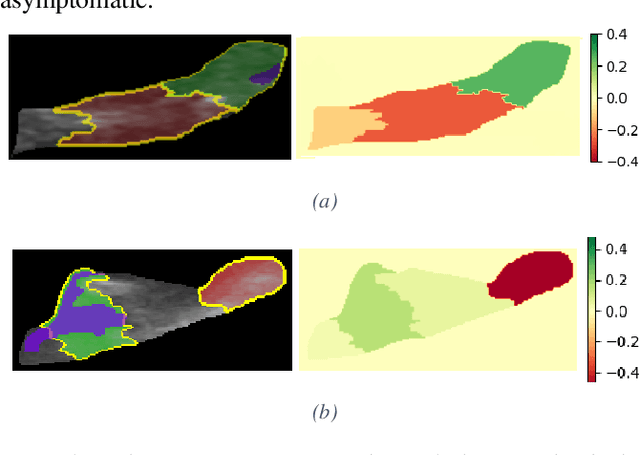
Carotid atherosclerosis is the major cause of ischemic stroke resulting in significant rates of mortality and disability annually. Early diagnosis of such cases is of great importance, since it enables clinicians to apply a more effective treatment strategy. This paper introduces an interpretable classification approach of carotid ultrasound images for the risk assessment and stratification of patients with carotid atheromatous plaque. To address the highly imbalanced distribution of patients between the symptomatic and asymptomatic classes (16 vs 58, respectively), an ensemble learning scheme based on a sub-sampling approach was applied along with a two-phase, cost-sensitive strategy of learning, that uses the original and a resampled data set. Convolutional Neural Networks (CNNs) were utilized for building the primary models of the ensemble. A six-layer deep CNN was used to automatically extract features from the images, followed by a classification stage of two fully connected layers. The obtained results (Area Under the ROC Curve (AUC): 73%, sensitivity: 75%, specificity: 70%) indicate that the proposed approach achieved acceptable discrimination performance. Finally, interpretability methods were applied on the model's predictions in order to reveal insights on the model's decision process as well as to enable the identification of novel image biomarkers for the stratification of patients with carotid atheromatous plaque.Clinical Relevance-The integration of interpretability methods with deep learning strategies can facilitate the identification of novel ultrasound image biomarkers for the stratification of patients with carotid atheromatous plaque.
Classifications of Skull Fractures using CT Scan Images via CNN with Lazy Learning Approach
Mar 21, 2022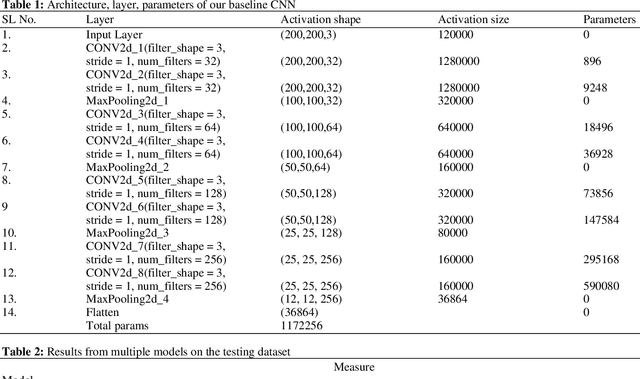
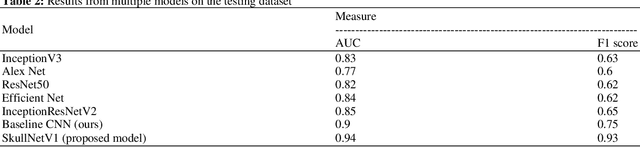
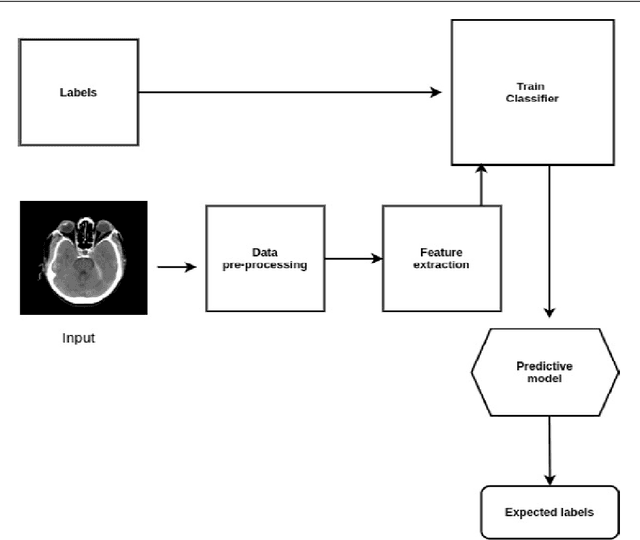
Classification of skull fracture is a challenging task for both radiologists and researchers. Skull fractures result in broken pieces of bone, which can cut into the brain and cause bleeding and other injury types. So it is vital to detect and classify the fracture very early. In real world, often fractures occur at multiple sites. This makes it harder to detect the fracture type where many fracture types might summarize a skull fracture. Unfortunately, manual detection of skull fracture and the classification process is time-consuming, threatening a patient's life. Because of the emergence of deep learning, this process could be automated. Convolutional Neural Networks (CNNs) are the most widely used deep learning models for image categorization because they deliver high accuracy and outstanding outcomes compared to other models. We propose a new model called SkullNetV1 comprising a novel CNN by taking advantage of CNN for feature extraction and lazy learning approach which acts as a classifier for classification of skull fractures from brain CT images to classify five fracture types. Our suggested model achieved a subset accuracy of 88%, an F1 score of 93%, the Area Under the Curve (AUC) of 0.89 to 0.98, a Hamming score of 92% and a Hamming loss of 0.04 for this seven-class multi-labeled classification.
Medical Image Segmentation Using Deep Learning: A Survey
Sep 28, 2020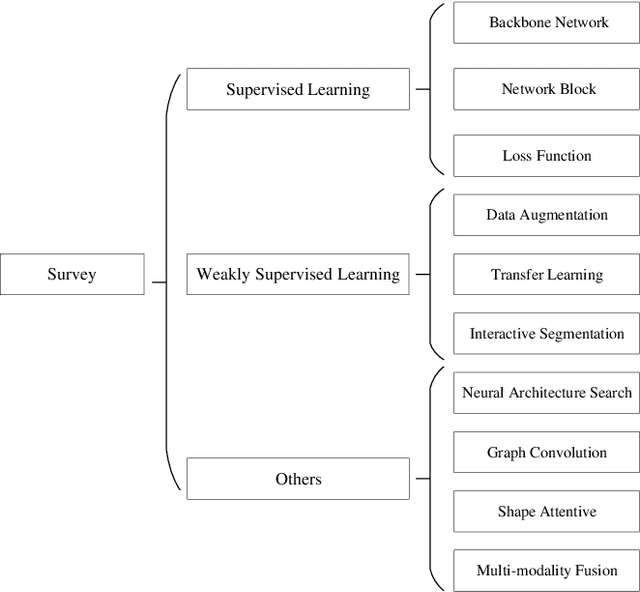
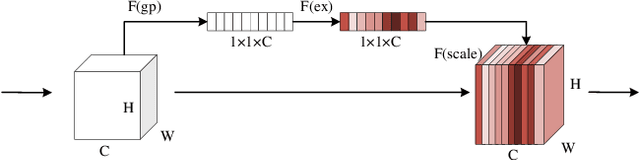
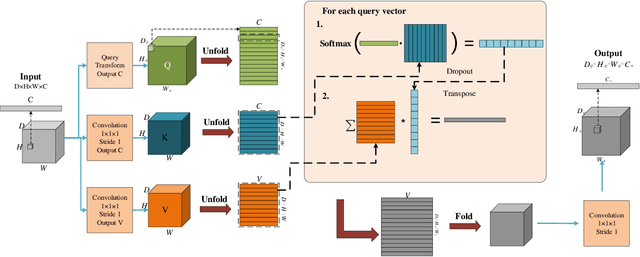
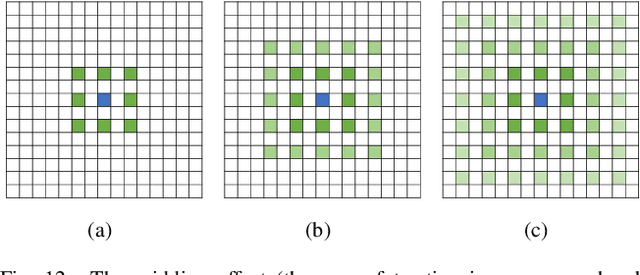
Deep learning has been widely used for medical image segmentation and a large number of papers has been presented recording the success of deep learning in the field. In this paper, we present a comprehensive thematic survey on medical image segmentation using deep learning techniques. This paper makes two original contributions. Firstly, compared to traditional surveys that directly divide literatures of deep learning on medical image segmentation into many groups and introduce literatures in detail for each group, we classify currently popular literatures according to a multi-level structure from coarse to fine. Secondly, this paper focuses on supervised and weakly supervised learning approaches, without including unsupervised approaches since they have been introduced in many old surveys and they are not popular currently. For supervised learning approaches, we analyze literatures in three aspects: the selection of backbone networks, the design of network blocks, and the improvement of loss functions. For weakly supervised learning approaches, we investigate literature according to data augmentation, transfer learning, and interactive segmentation, separately. Compared to existing surveys, this survey classifies the literatures very differently from before and is more convenient for readers to understand the relevant rationale and will guide them to think of appropriate improvements in medical image segmentation based on deep learning approaches.
Rethinking Image Deraining via Rain Streaks and Vapors
Aug 03, 2020
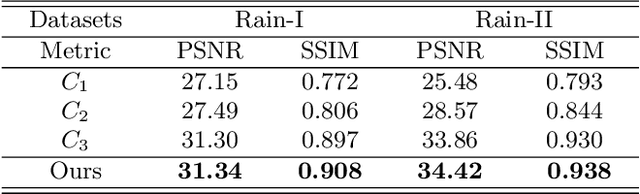
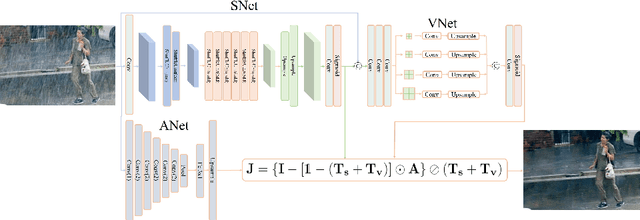

Single image deraining regards an input image as a fusion of a background image, a transmission map, rain streaks, and atmosphere light. While advanced models are proposed for image restoration (i.e., background image generation), they regard rain streaks with the same properties as background rather than transmission medium. As vapors (i.e., rain streaks accumulation or fog-like rain) are conveyed in the transmission map to model the veiling effect, the fusion of rain streaks and vapors do not naturally reflect the rain image formation. In this work, we reformulate rain streaks as transmission medium together with vapors to model rain imaging. We propose an encoder-decoder CNN named as SNet to learn the transmission map of rain streaks. As rain streaks appear with various shapes and directions, we use ShuffleNet units within SNet to capture their anisotropic representations. As vapors are brought by rain streaks, we propose a VNet containing spatial pyramid pooling (SSP) to predict the transmission map of vapors in multi-scales based on that of rain streaks. Meanwhile, we use an encoder CNN named ANet to estimate atmosphere light. The SNet, VNet, and ANet are jointly trained to predict transmission maps and atmosphere light for rain image restoration. Extensive experiments on the benchmark datasets demonstrate the effectiveness of the proposed visual model to predict rain streaks and vapors. The proposed deraining method performs favorably against state-of-the-art deraining approaches.
SSCAN: A Spatial-spectral Cross Attention Network for Hyperspectral Image Denoising
May 23, 2021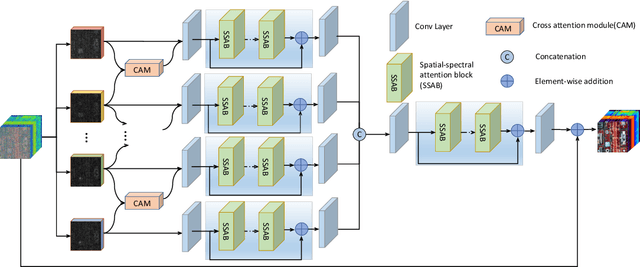
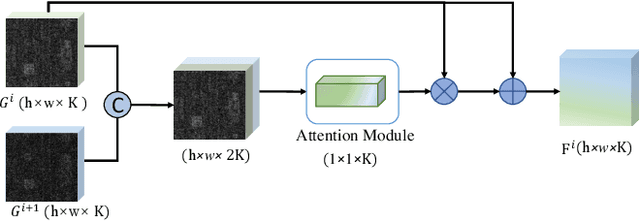
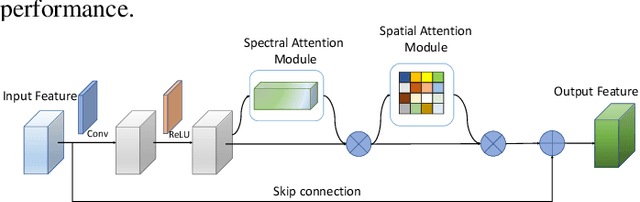
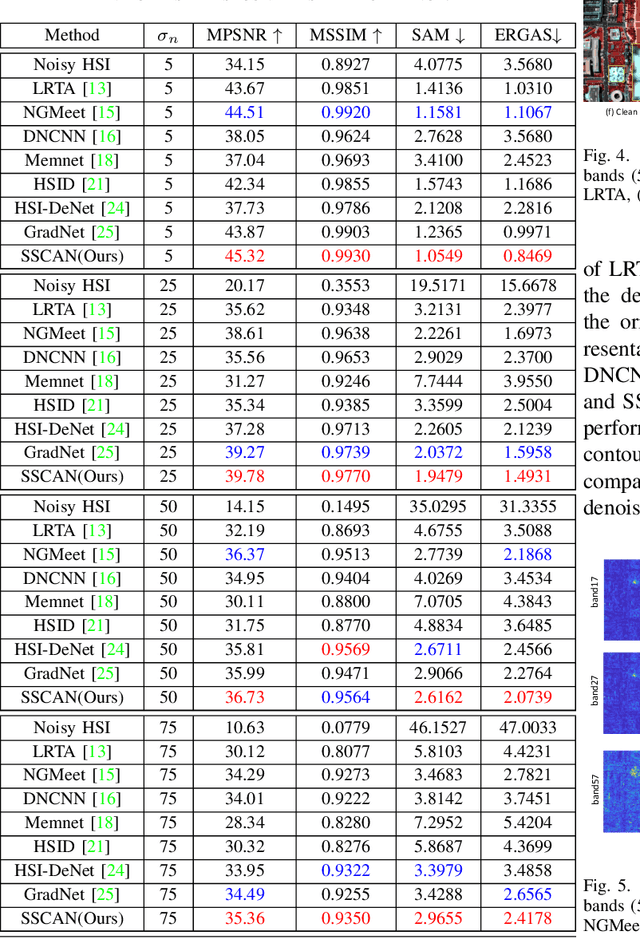
Hyperspectral images (HSIs) have been widely used in a variety of applications thanks to the rich spectral information they are able to provide. Among all HSI processing tasks, HSI denoising is a crucial step. Recently, deep learning-based image denoising methods have made great progress and achieved great performance. However, existing methods tend to ignore the correlations between adjacent spectral bands, leading to problems such as spectral distortion and blurred edges in denoised results. In this study, we propose a novel HSI denoising network, termed SSCAN, that combines group convolutions and attention modules. Specifically, we use a group convolution with a spatial attention module to facilitate feature extraction by directing models' attention to band-wise important features. We propose a spectral-spatial attention block (SSAB) to exploit the spatial and spectral information in hyperspectral images in an effective manner. In addition, we adopt residual learning operations with skip connections to ensure training stability. The experimental results indicate that the proposed SSCAN outperforms several state-of-the-art HSI denoising algorithms.
MonoJSG: Joint Semantic and Geometric Cost Volume for Monocular 3D Object Detection
Mar 16, 2022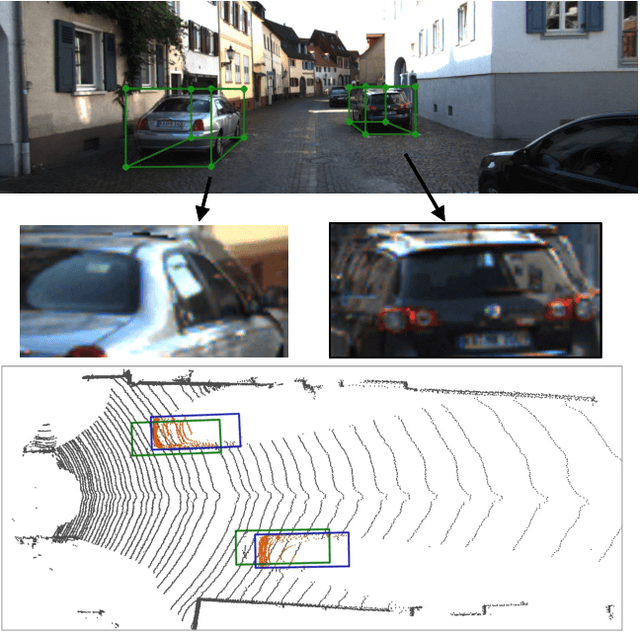
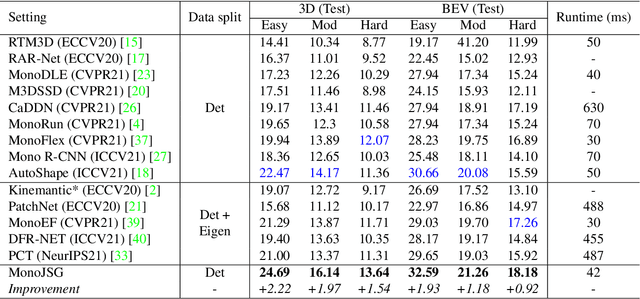
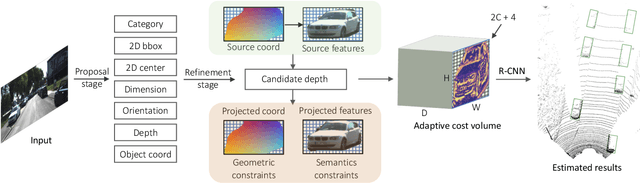
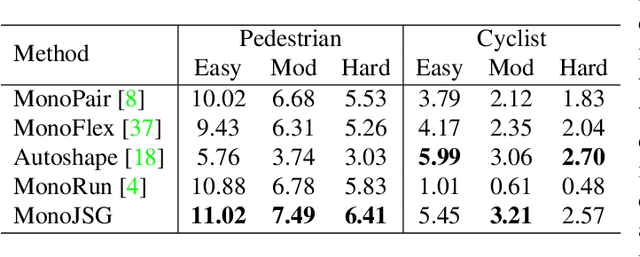
Due to the inherent ill-posed nature of 2D-3D projection, monocular 3D object detection lacks accurate depth recovery ability. Although the deep neural network (DNN) enables monocular depth-sensing from high-level learned features, the pixel-level cues are usually omitted due to the deep convolution mechanism. To benefit from both the powerful feature representation in DNN and pixel-level geometric constraints, we reformulate the monocular object depth estimation as a progressive refinement problem and propose a joint semantic and geometric cost volume to model the depth error. Specifically, we first leverage neural networks to learn the object position, dimension, and dense normalized 3D object coordinates. Based on the object depth, the dense coordinates patch together with the corresponding object features is reprojected to the image space to build a cost volume in a joint semantic and geometric error manner. The final depth is obtained by feeding the cost volume to a refinement network, where the distribution of semantic and geometric error is regularized by direct depth supervision. Through effectively mitigating depth error by the refinement framework, we achieve state-of-the-art results on both the KITTI and Waymo datasets.
Is it all a cluster game? -- Exploring Out-of-Distribution Detection based on Clustering in the Embedding Space
Mar 16, 2022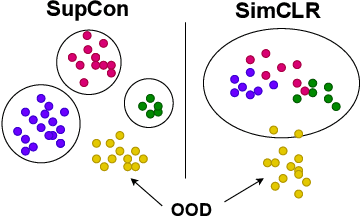
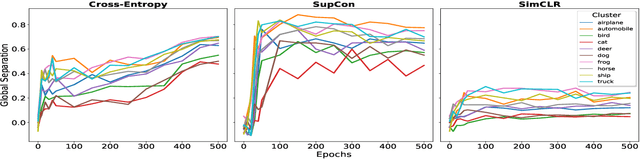
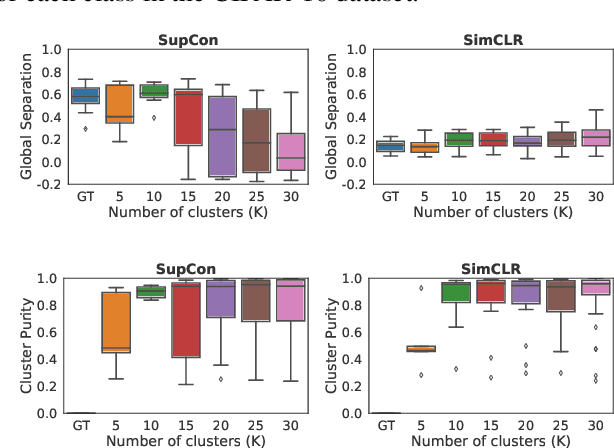
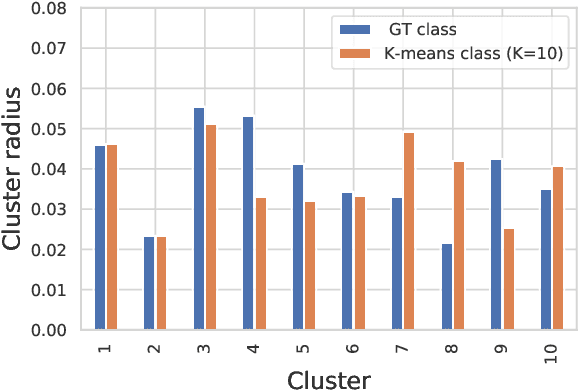
It is essential for safety-critical applications of deep neural networks to determine when new inputs are significantly different from the training distribution. In this paper, we explore this out-of-distribution (OOD) detection problem for image classification using clusters of semantically similar embeddings of the training data and exploit the differences in distance relationships to these clusters between in- and out-of-distribution data. We study the structure and separation of clusters in the embedding space and find that supervised contrastive learning leads to well-separated clusters while its self-supervised counterpart fails to do so. In our extensive analysis of different training methods, clustering strategies, distance metrics, and thresholding approaches, we observe that there is no clear winner. The optimal approach depends on the model architecture and selected datasets for in- and out-of-distribution. While we could reproduce the outstanding results for contrastive training on CIFAR-10 as in-distribution data, we find standard cross-entropy paired with cosine similarity outperforms all contrastive training methods when training on CIFAR-100 instead. Cross-entropy provides competitive results as compared to expensive contrastive training methods.
Robust Semi-supervised Federated Learning for Images Automatic Recognition in Internet of Drones
Jan 03, 2022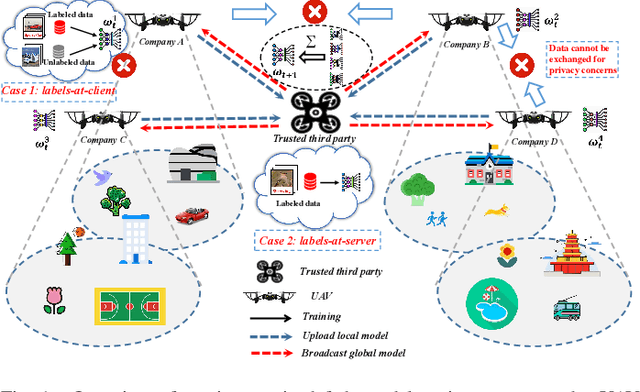
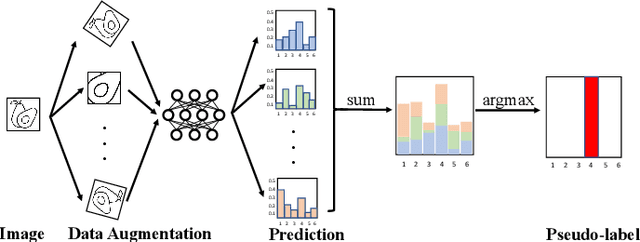
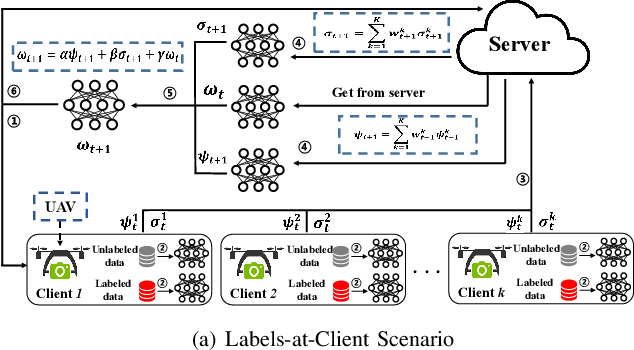
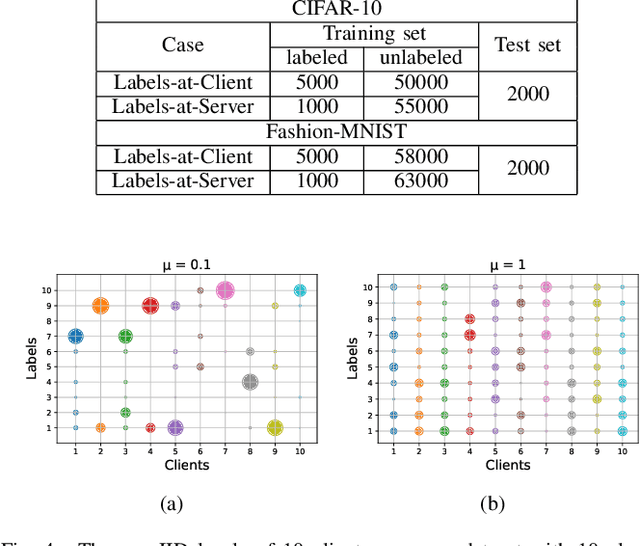
Air access networks have been recognized as a significant driver of various Internet of Things (IoT) services and applications. In particular, the aerial computing network infrastructure centered on the Internet of Drones has set off a new revolution in automatic image recognition. This emerging technology relies on sharing ground truth labeled data between Unmanned Aerial Vehicle (UAV) swarms to train a high-quality automatic image recognition model. However, such an approach will bring data privacy and data availability challenges. To address these issues, we first present a Semi-supervised Federated Learning (SSFL) framework for privacy-preserving UAV image recognition. Specifically, we propose model parameters mixing strategy to improve the naive combination of FL and semi-supervised learning methods under two realistic scenarios (labels-at-client and labels-at-server), which is referred to as Federated Mixing (FedMix). Furthermore, there are significant differences in the number, features, and distribution of local data collected by UAVs using different camera modules in different environments, i.e., statistical heterogeneity. To alleviate the statistical heterogeneity problem, we propose an aggregation rule based on the frequency of the client's participation in training, namely the FedFreq aggregation rule, which can adjust the weight of the corresponding local model according to its frequency. Numerical results demonstrate that the performance of our proposed method is significantly better than those of the current baseline and is robust to different non-IID levels of client data.
Content-based Image Retrieval and the Semantic Gap in the Deep Learning Era
Nov 12, 2020

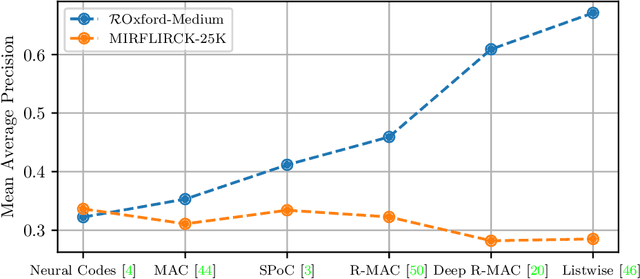
Content-based image retrieval has seen astonishing progress over the past decade, especially for the task of retrieving images of the same object that is depicted in the query image. This scenario is called instance or object retrieval and requires matching fine-grained visual patterns between images. Semantics, however, do not play a crucial role. This brings rise to the question: Do the recent advances in instance retrieval transfer to more generic image retrieval scenarios? To answer this question, we first provide a brief overview of the most relevant milestones of instance retrieval. We then apply them to a semantic image retrieval task and find that they perform inferior to much less sophisticated and more generic methods in a setting that requires image understanding. Following this, we review existing approaches to closing this so-called semantic gap by integrating prior world knowledge. We conclude that the key problem for the further advancement of semantic image retrieval lies in the lack of a standardized task definition and an appropriate benchmark dataset.
DeepFace-EMD: Re-ranking Using Patch-wise Earth Mover's Distance Improves Out-Of-Distribution Face Identification
Dec 07, 2021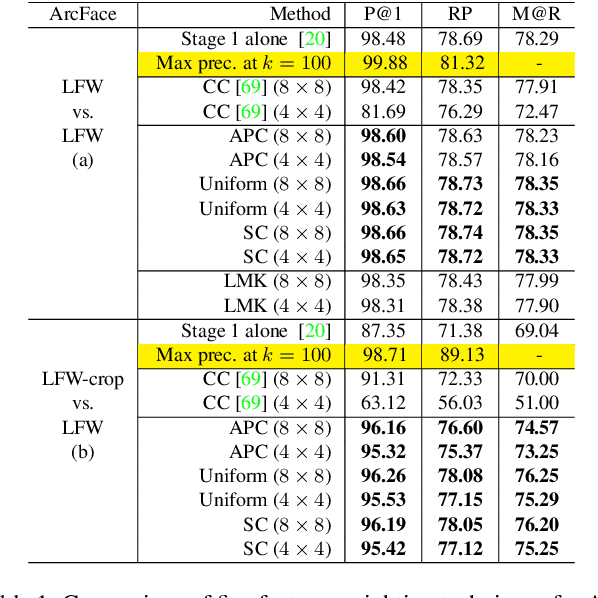
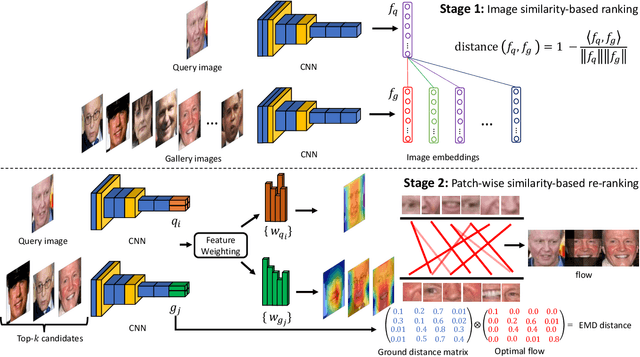
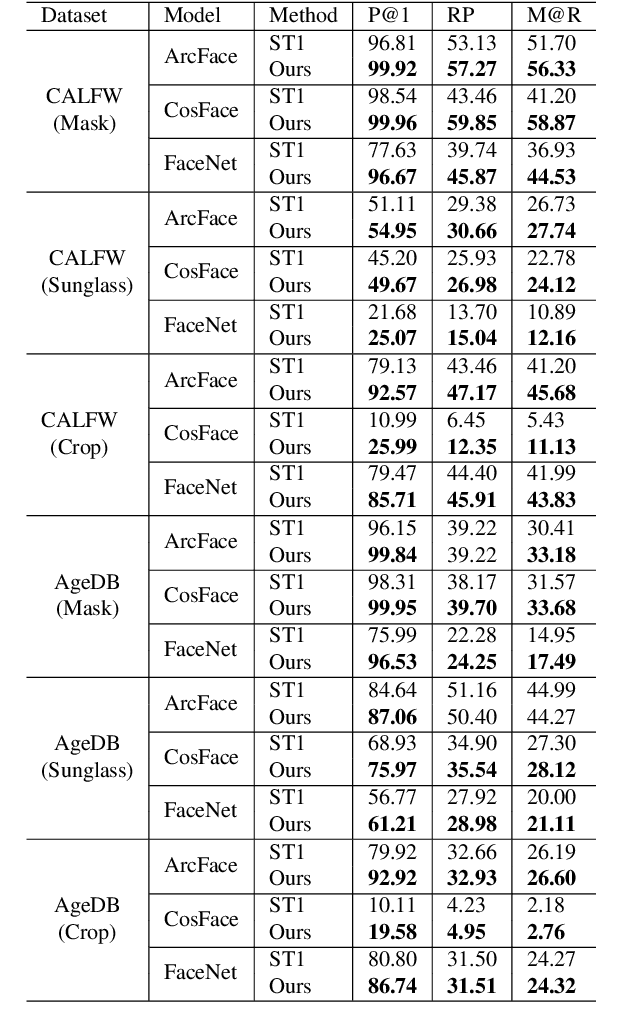

Face identification (FI) is ubiquitous and drives many high-stake decisions made by law enforcement. State-of-the-art FI approaches compare two images by taking the cosine similarity between their image embeddings. Yet, such an approach suffers from poor out-of-distribution (OOD) generalization to new types of images (e.g., when a query face is masked, cropped, or rotated) not included in the training set or the gallery. Here, we propose a re-ranking approach that compares two faces using the Earth Mover's Distance on the deep, spatial features of image patches. Our extra comparison stage explicitly examines image similarity at a fine-grained level (e.g., eyes to eyes) and is more robust to OOD perturbations and occlusions than traditional FI. Interestingly, without finetuning feature extractors, our method consistently improves the accuracy on all tested OOD queries: masked, cropped, rotated, and adversarial while obtaining similar results on in-distribution images.