 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Efficient Technique for Image Captioning using Deep Neural Network
Sep 05, 2020
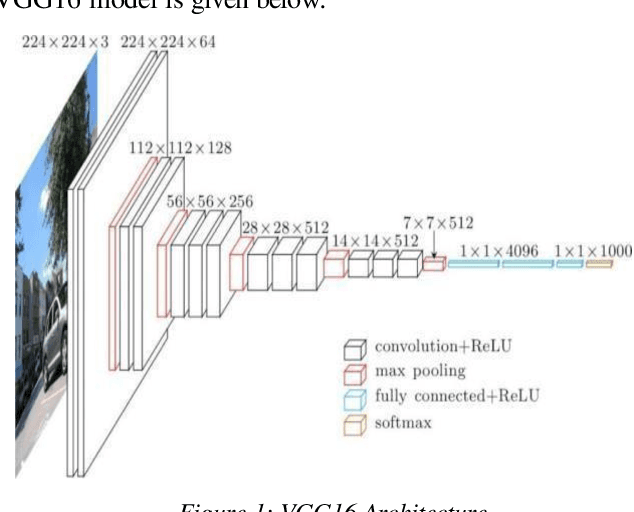
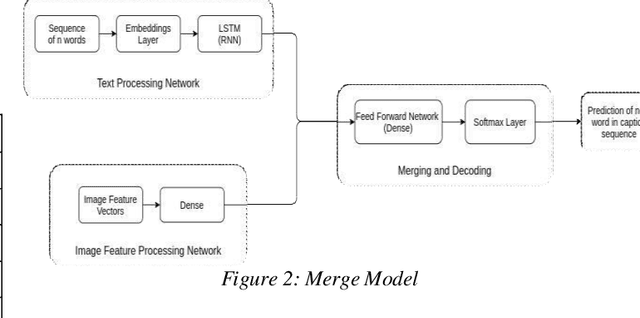
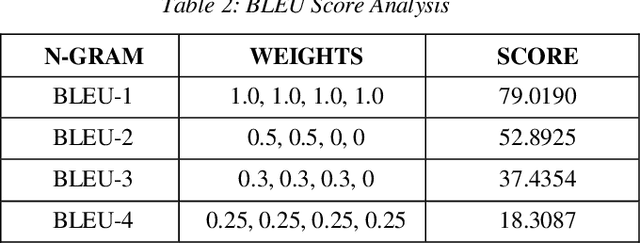
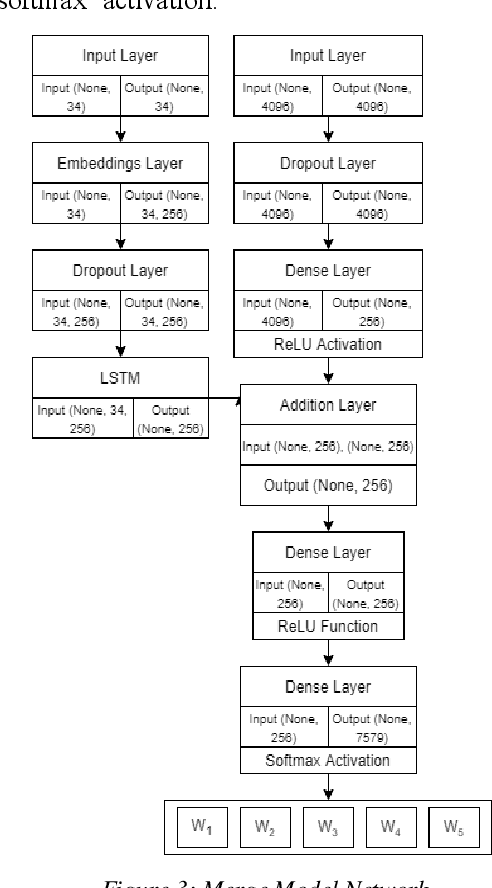
With the huge expansion of internet and trillions of gigabytes of data generated every single day, the needs for the development of various tools has become mandatory in order to maintain system adaptability to rapid changes. One of these tools is known as Image Captioning. Every entity in internet must be properly identified and managed and therefore in the case of image data, automatic captioning for identification is required. Similarly, content generation for missing labels, image classification and artificial languages all requires the process of Image Captioning. This paper discusses an efficient and unique way to perform automatic image captioning on individual image and discusses strategies to improve its performances and functionalities.
Multidimensional Belief Quantification for Label-Efficient Meta-Learning
Mar 23, 2022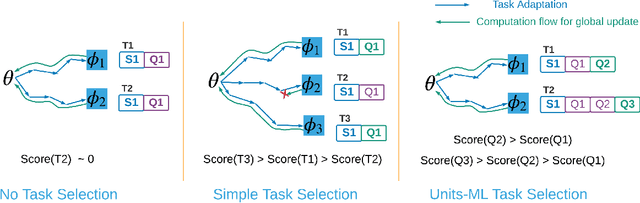
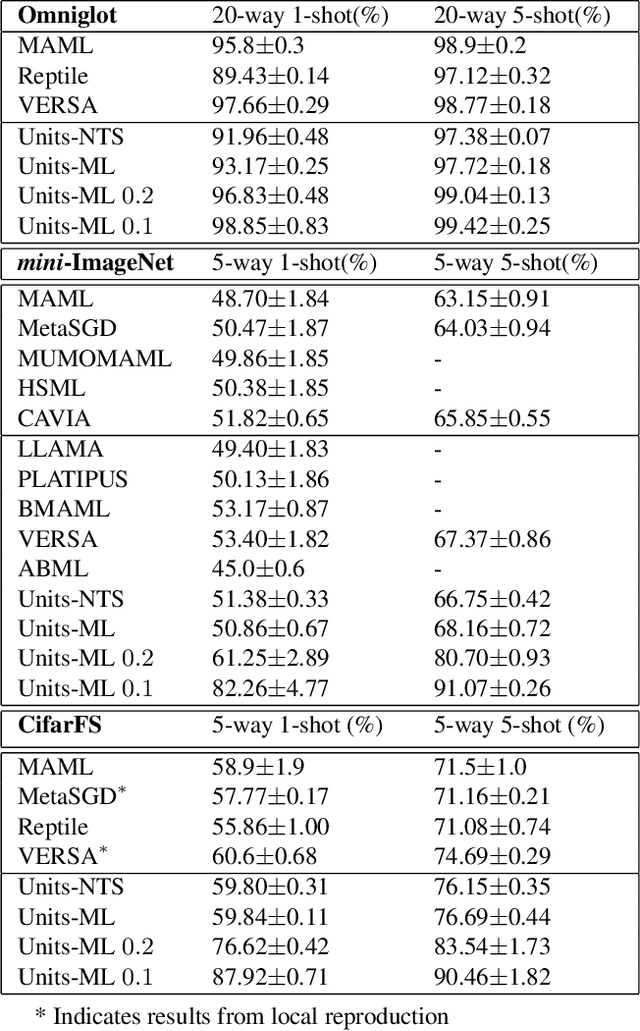
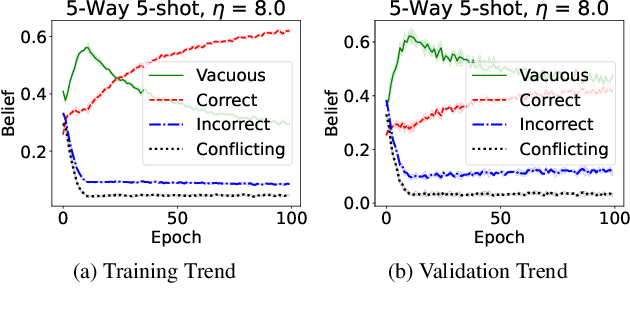
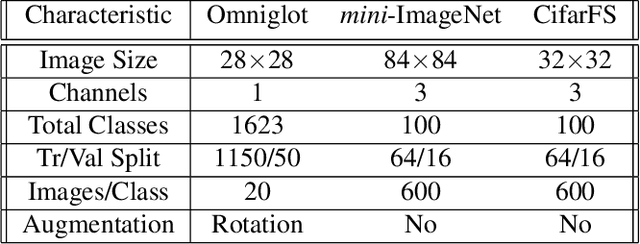
Optimization-based meta-learning offers a promising direction for few-shot learning that is essential for many real-world computer vision applications. However, learning from few samples introduces uncertainty, and quantifying model confidence for few-shot predictions is essential for many critical domains. Furthermore, few-shot tasks used in meta training are usually sampled randomly from a task distribution for an iterative model update, leading to high labeling costs and computational overhead in meta-training. We propose a novel uncertainty-aware task selection model for label efficient meta-learning. The proposed model formulates a multidimensional belief measure, which can quantify the known uncertainty and lower bound the unknown uncertainty of any given task. Our theoretical result establishes an important relationship between the conflicting belief and the incorrect belief. The theoretical result allows us to estimate the total uncertainty of a task, which provides a principled criterion for task selection. A novel multi-query task formulation is further developed to improve both the computational and labeling efficiency of meta-learning. Experiments conducted over multiple real-world few-shot image classification tasks demonstrate the effectiveness of the proposed model.
Adversarial Patterns: Building Robust Android Malware Classifiers
Mar 04, 2022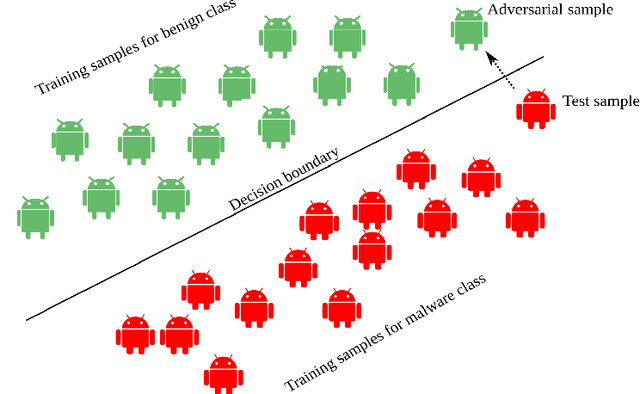

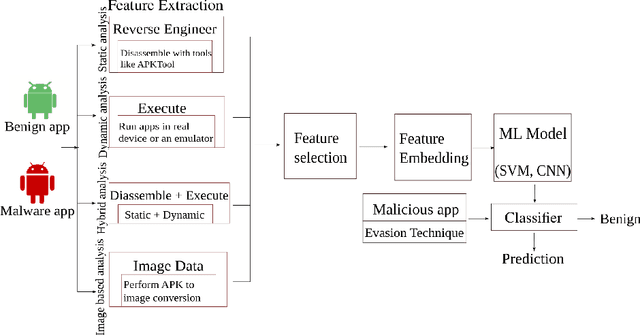
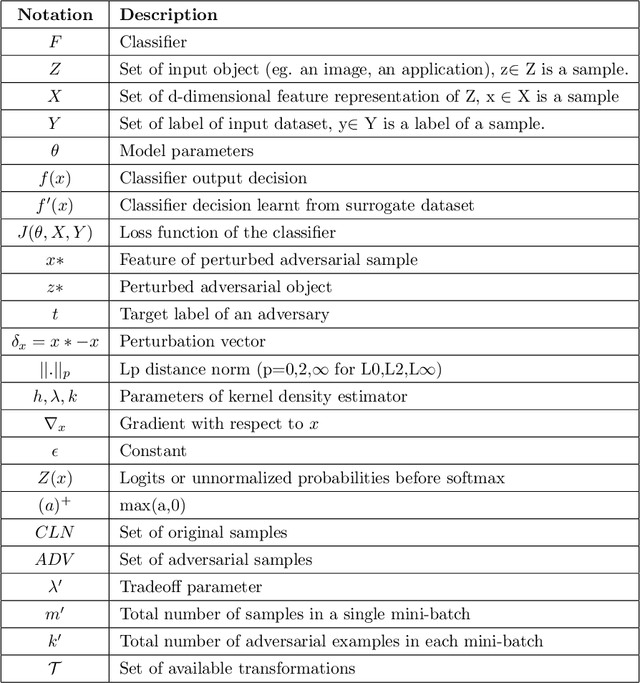
Deep learning-based classifiers have substantially improved recognition of malware samples. However, these classifiers can be vulnerable to adversarial input perturbations. Any vulnerability in malware classifiers poses significant threats to the platforms they defend. Therefore, to create stronger defense models against malware, we must understand the patterns in input perturbations caused by an adversary. This survey paper presents a comprehensive study on adversarial machine learning for android malware classifiers. We first present an extensive background in building a machine learning classifier for android malware, covering both image-based and text-based feature extraction approaches. Then, we examine the pattern and advancements in the state-of-the-art research in evasion attacks and defenses. Finally, we present guidelines for designing robust malware classifiers and enlist research directions for the future.
Are High-Resolution Event Cameras Really Needed?
Mar 28, 2022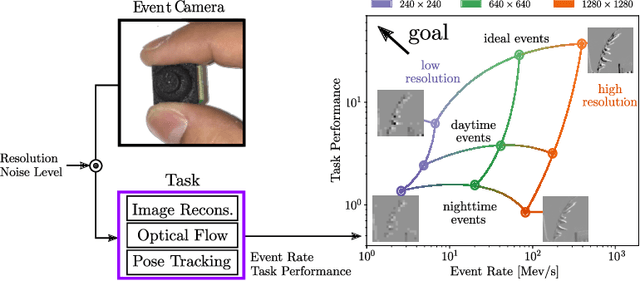
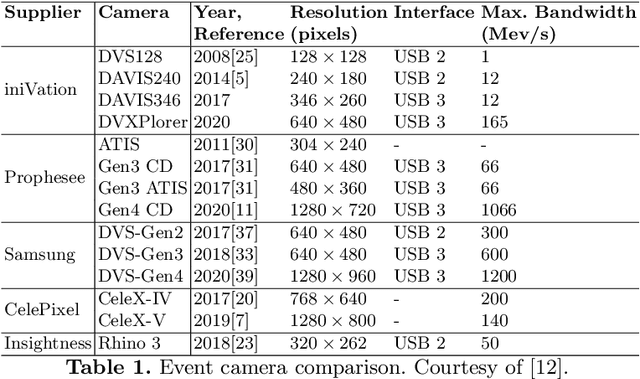
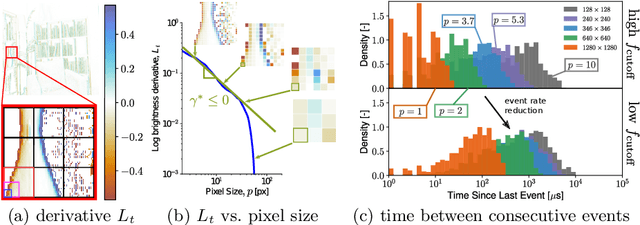
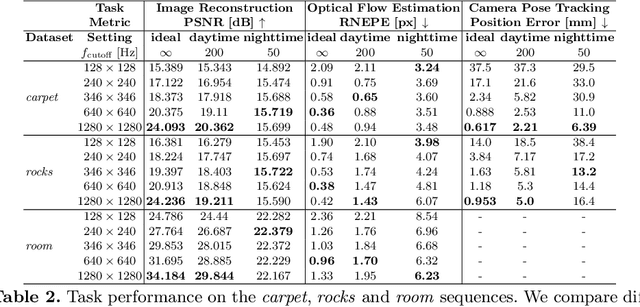
Due to their outstanding properties in challenging conditions, event cameras have become indispensable in a wide range of applications, ranging from automotive, computational photography, and SLAM. However, as further improvements are made to the sensor design, modern event cameras are trending toward higher and higher sensor resolutions, which result in higher bandwidth and computational requirements on downstream tasks. Despite this trend, the benefits of using high-resolution event cameras to solve standard computer vision tasks are still not clear. In this work, we report the surprising discovery that, in low-illumination conditions and at high speeds, low-resolution cameras can outperform high-resolution ones, while requiring a significantly lower bandwidth. We provide both empirical and theoretical evidence for this claim, which indicates that high-resolution event cameras exhibit higher per-pixel event rates, leading to higher temporal noise in low-illumination conditions and at high speeds. As a result, in most cases, high-resolution event cameras show a lower task performance, compared to lower resolution sensors in these conditions. We empirically validate our findings across several tasks, namely image reconstruction, optical flow estimation, and camera pose tracking, both on synthetic and real data. We believe that these findings will provide important guidelines for future trends in event camera development.
A study on joint modeling and data augmentation of multi-modalities for audio-visual scene classification
Mar 07, 2022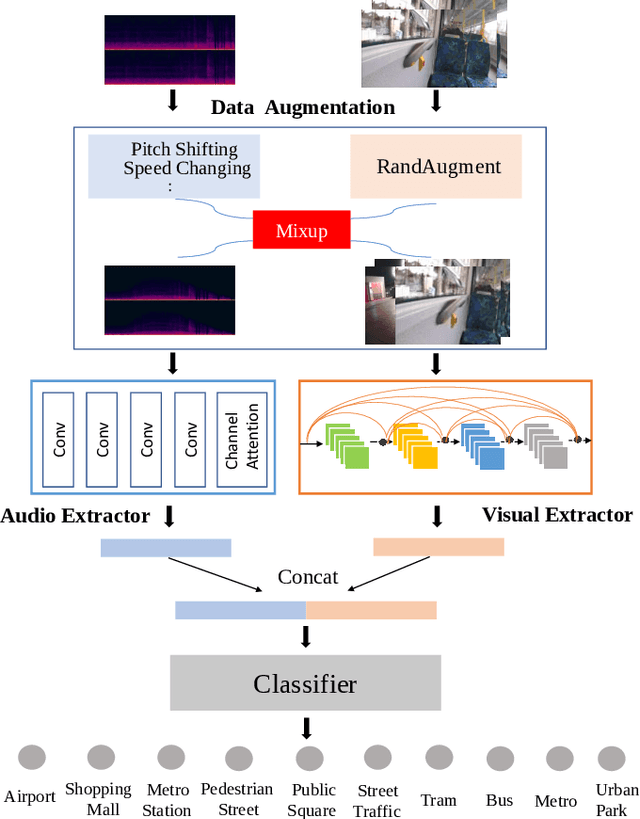
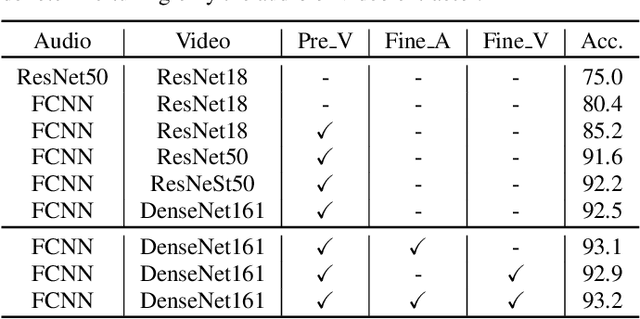
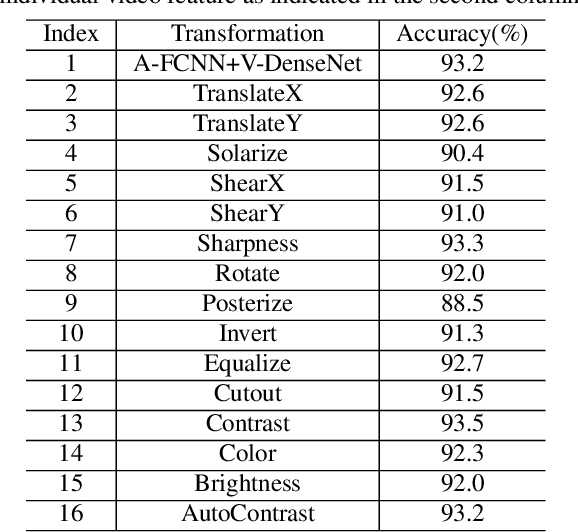
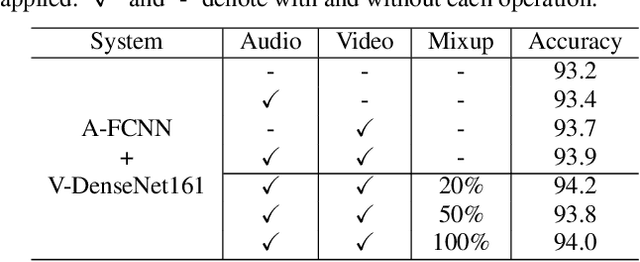
In this paper, we propose two techniques, namely joint modeling and data augmentation, to improve system performances for audio-visual scene classification (AVSC). We employ pre-trained networks trained only on image data sets to extract video embedding; whereas for audio embedding models, we decide to train them from scratch. We explore different neural network architectures for joint modeling to effectively combine the video and audio modalities. Moreover, data augmentation strategies are investigated to increase audio-visual training set size. For the video modality the effectiveness of several operations in RandAugment is verified. An audio-video joint mixup scheme is proposed to further improve AVSC performances. Evaluated on the development set of TAU Urban Audio Visual Scenes 2021, our final system can achieve the best accuracy of 94.2% among all single AVSC systems submitted to DCASE 2021 Task 1b.
SwapMix: Diagnosing and Regularizing the Over-Reliance on Visual Context in Visual Question Answering
Apr 05, 2022

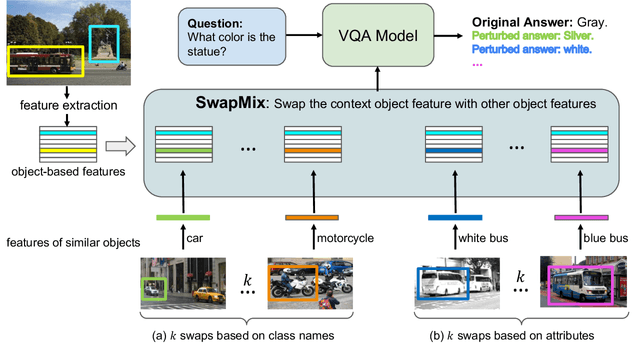
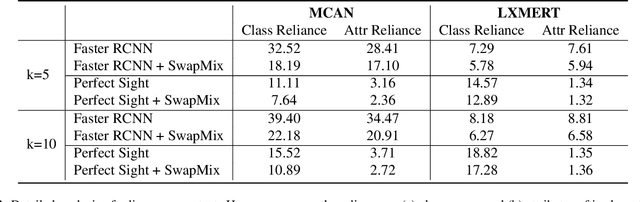
While Visual Question Answering (VQA) has progressed rapidly, previous works raise concerns about robustness of current VQA models. In this work, we study the robustness of VQA models from a novel perspective: visual context. We suggest that the models over-rely on the visual context, i.e., irrelevant objects in the image, to make predictions. To diagnose the model's reliance on visual context and measure their robustness, we propose a simple yet effective perturbation technique, SwapMix. SwapMix perturbs the visual context by swapping features of irrelevant context objects with features from other objects in the dataset. Using SwapMix we are able to change answers to more than 45 % of the questions for a representative VQA model. Additionally, we train the models with perfect sight and find that the context over-reliance highly depends on the quality of visual representations. In addition to diagnosing, SwapMix can also be applied as a data augmentation strategy during training in order to regularize the context over-reliance. By swapping the context object features, the model reliance on context can be suppressed effectively. Two representative VQA models are studied using SwapMix: a co-attention model MCAN and a large-scale pretrained model LXMERT. Our experiments on the popular GQA dataset show the effectiveness of SwapMix for both diagnosing model robustness and regularizing the over-reliance on visual context. The code for our method is available at https://github.com/vipulgupta1011/swapmix
Bayesian Low-rank Matrix Completion with Dual-graph Embedding: Prior Analysis and Tuning-free Inference
Mar 18, 2022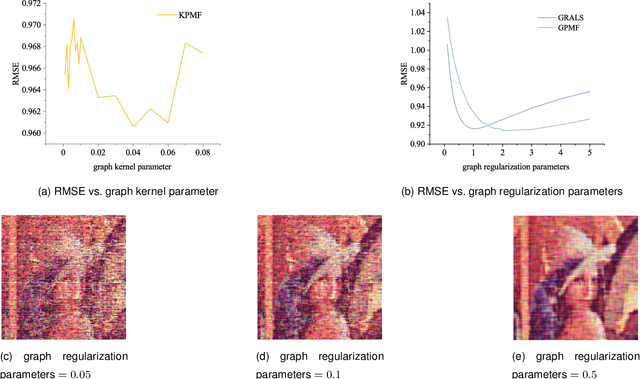
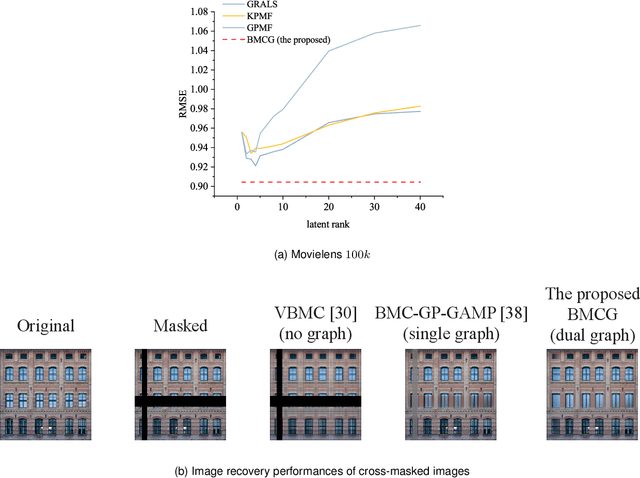
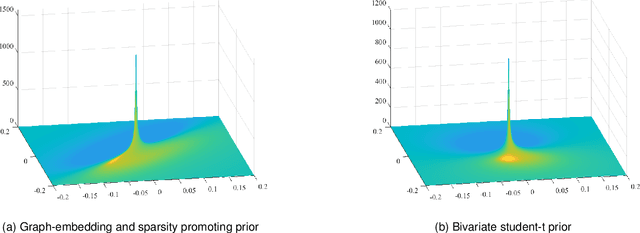
Recently, there is a revival of interest in low-rank matrix completion-based unsupervised learning through the lens of dual-graph regularization, which has significantly improved the performance of multidisciplinary machine learning tasks such as recommendation systems, genotype imputation and image inpainting. While the dual-graph regularization contributes a major part of the success, computational costly hyper-parameter tunning is usually involved. To circumvent such a drawback and improve the completion performance, we propose a novel Bayesian learning algorithm that automatically learns the hyper-parameters associated with dual-graph regularization, and at the same time, guarantees the low-rankness of matrix completion. Notably, a novel prior is devised to promote the low-rankness of the matrix and encode the dual-graph information simultaneously, which is more challenging than the single-graph counterpart. A nontrivial conditional conjugacy between the proposed priors and likelihood function is then explored such that an efficient algorithm is derived under variational inference framework. Extensive experiments using synthetic and real-world datasets demonstrate the state-of-the-art performance of the proposed learning algorithm for various data analysis tasks.
Meta Mask Correction for Nuclei Segmentation in Histopathological Image
Nov 24, 2021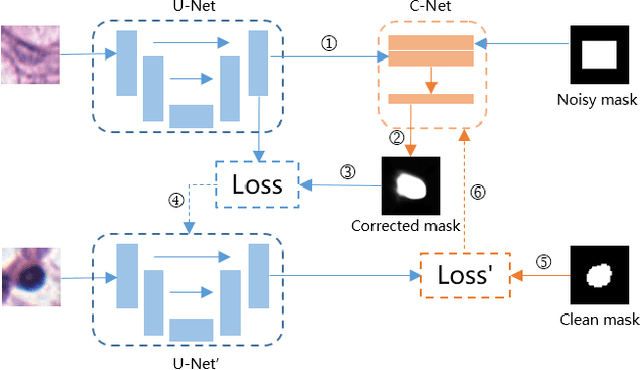

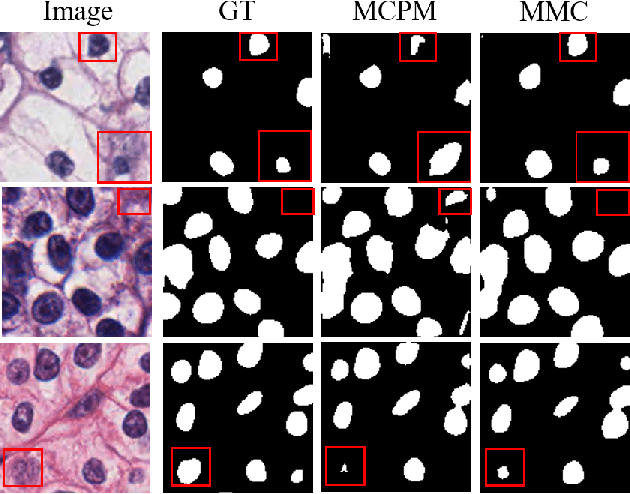
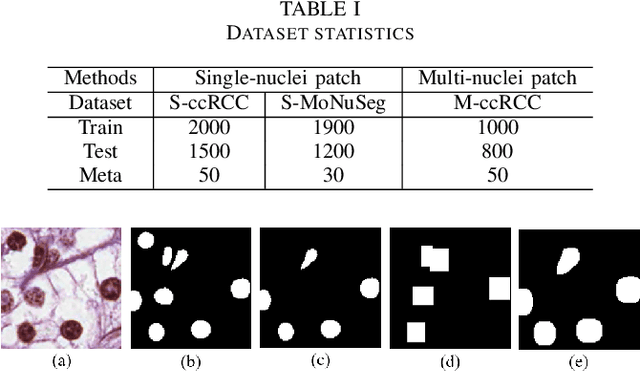
Nuclei segmentation is a fundamental task in digital pathology analysis and can be automated by deep learning-based methods. However, the development of such an automated method requires a large amount of data with precisely annotated masks which is hard to obtain. Training with weakly labeled data is a popular solution for reducing the workload of annotation. In this paper, we propose a novel meta-learning-based nuclei segmentation method which follows the label correction paradigm to leverage data with noisy masks. Specifically, we design a fully conventional meta-model that can correct noisy masks using a small amount of clean meta-data. Then the corrected masks can be used to supervise the training of the segmentation model. Meanwhile, a bi-level optimization method is adopted to alternately update the parameters of the main segmentation model and the meta-model in an end-to-end way. Extensive experimental results on two nuclear segmentation datasets show that our method achieves the state-of-the-art result. It even achieves comparable performance with the model training on supervised data in some noisy settings.
Guided Deep Decoder: Unsupervised Image Pair Fusion
Jul 23, 2020
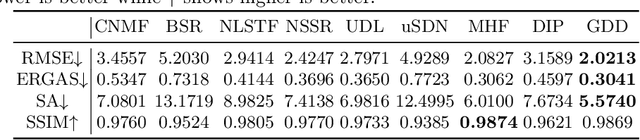
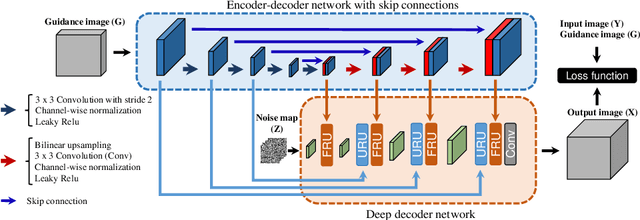
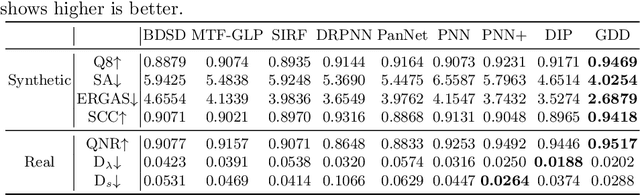
The fusion of input and guidance images that have a tradeoff in their information (e.g., hyperspectral and RGB image fusion or pansharpening) can be interpreted as one general problem. However, previous studies applied a task-specific handcrafted prior and did not address the problems with a unified approach. To address this limitation, in this study, we propose a guided deep decoder network as a general prior. The proposed network is composed of an encoder-decoder network that exploits multi-scale features of a guidance image and a deep decoder network that generates an output image. The two networks are connected by feature refinement units to embed the multi-scale features of the guidance image into the deep decoder network. The proposed network allows the network parameters to be optimized in an unsupervised way without training data. Our results show that the proposed network can achieve state-of-the-art performance in various image fusion problems.
A deep learning framework for the detection and quantification of drusen and reticular pseudodrusen on optical coherence tomography
Apr 05, 2022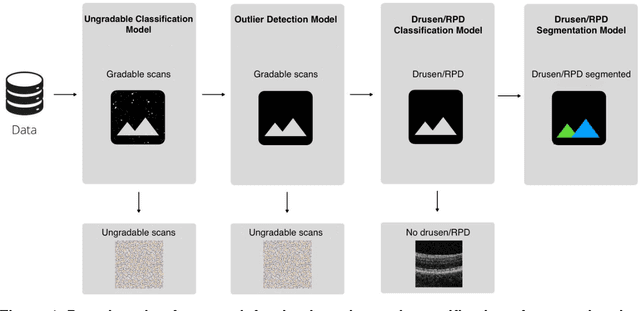
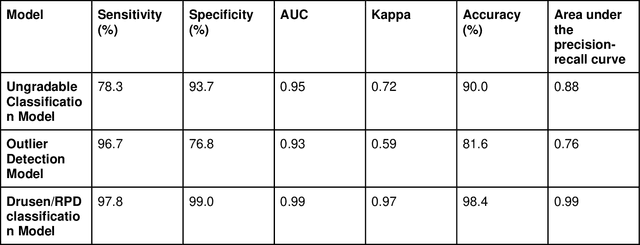
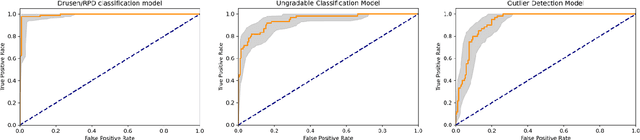

Purpose - To develop and validate a deep learning (DL) framework for the detection and quantification of drusen and reticular pseudodrusen (RPD) on optical coherence tomography scans. Design - Development and validation of deep learning models for classification and feature segmentation. Methods - A DL framework was developed consisting of a classification model and an out-of-distribution (OOD) detection model for the identification of ungradable scans; a classification model to identify scans with drusen or RPD; and an image segmentation model to independently segment lesions as RPD or drusen. Data were obtained from 1284 participants in the UK Biobank (UKBB) with a self-reported diagnosis of age-related macular degeneration (AMD) and 250 UKBB controls. Drusen and RPD were manually delineated by five retina specialists. The main outcome measures were sensitivity, specificity, area under the ROC curve (AUC), kappa, accuracy and intraclass correlation coefficient (ICC). Results - The classification models performed strongly at their respective tasks (0.95, 0.93, and 0.99 AUC, respectively, for the ungradable scans classifier, the OOD model, and the drusen and RPD classification model). The mean ICC for drusen and RPD area vs. graders was 0.74 and 0.61, respectively, compared with 0.69 and 0.68 for intergrader agreement. FROC curves showed that the model's sensitivity was close to human performance. Conclusions - The models achieved high classification and segmentation performance, similar to human performance. Application of this robust framework will further our understanding of RPD as a separate entity from drusen in both research and clinical settings.