 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGHGbench: A Unified Multi-Entity, Multi-Task Benchmark for Carbon Emission Prediction
May 13, 2026Open datasets and benchmarks for entity-level carbon-emission prediction remain fragmented across access, scale, granularity, and evaluation. We introduce GHGbench, an open dataset and benchmark for company- and building-level greenhouse-gas prediction. The company track contains 32,000+ company-year records from 12,000+ firms with Scope 1+2 and Scope 3 disclosures and financial/sectoral signals; the building track harmonises 491,591 building-year records from 13 open sources into a single schema across 26 metropolitan areas (10 U.S., 15 Australian, 1 Singaporean), with climate covariates and multimodal remote-sensing embeddings. GHGbench defines canonical splits with in-distribution and cross-region/city transfer as primary tasks and temporal hold-out plus short-horizon forecasting as supplementary appendix evidence; headline baselines span gradient-boosted trees, a tabular foundation model, MLP, FT-Transformer, and multimodal fusion, with an LLM panel as auxiliary, all evaluated under multi-seed paired-bootstrap tests. Three benchmark-level findings emerge: (i) building emissions are structurally harder than company emissions; (ii) the in-distribution to out-of-distribution gap dwarfs any within-model gap across both the company track and the building track, and a tabular foundation model is, to our knowledge, the first baseline to open a paired-bootstrap-significant gap over tuned trees on a multi-city building-emissions task; (iii) multimodal remote-sensing embeddings help precisely where tabular generalisation breaks. GHGbench also exposes catastrophic city transfer and the sector-factor lookup ceiling as systematic failure modes. Code and reconstruction recipes are available at GHGbench.
Aligning Language Models for Lyric-to-Melody Generation with Rule-Based Musical Constraints
Apr 20, 2026Large Language Models (LLMs) show promise in lyric-to-melody generation, but models trained with Supervised Fine-Tuning (SFT) often produce musically implausible melodies with issues like poor rhythm and unsuitable vocal ranges, a phenomenon we term "constraint violation". To address this, we propose a novel alignment framework that instills musical knowledge without human annotation. We define rule-based musical constraints to automatically generate a preference dataset from an SFT model's outputs. The model is then aligned through a sequential process, first using Direct Preference Optimization (DPO) on paired preference data, followed by Kahneman-Tversky Optimization (KTO) on unpaired negative samples. Experimental results demonstrate that our aligned model substantially reduces rule violations and outperforms strong baselines in both objective and subjective evaluations, generating melodies with substantially improved musicality and coherence. An interactive demo with audio comparisons is available at https://arain233.github.io/AligningMelody-demo.
Evaluation of Large Language Models in Legal Applications: Challenges, Methods, and Future Directions
Jan 21, 2026Large language models (LLMs) are being increasingly integrated into legal applications, including judicial decision support, legal practice assistance, and public-facing legal services. While LLMs show strong potential in handling legal knowledge and tasks, their deployment in real-world legal settings raises critical concerns beyond surface-level accuracy, involving the soundness of legal reasoning processes and trustworthy issues such as fairness and reliability. Systematic evaluation of LLM performance in legal tasks has therefore become essential for their responsible adoption. This survey identifies key challenges in evaluating LLMs for legal tasks grounded in real-world legal practice. We analyze the major difficulties involved in assessing LLM performance in the legal domain, including outcome correctness, reasoning reliability, and trustworthiness. Building on these challenges, we review and categorize existing evaluation methods and benchmarks according to their task design, datasets, and evaluation metrics. We further discuss the extent to which current approaches address these challenges, highlight their limitations, and outline future research directions toward more realistic, reliable, and legally grounded evaluation frameworks for LLMs in legal domains.
A study on joint modeling and data augmentation of multi-modalities for audio-visual scene classification
Mar 31, 2022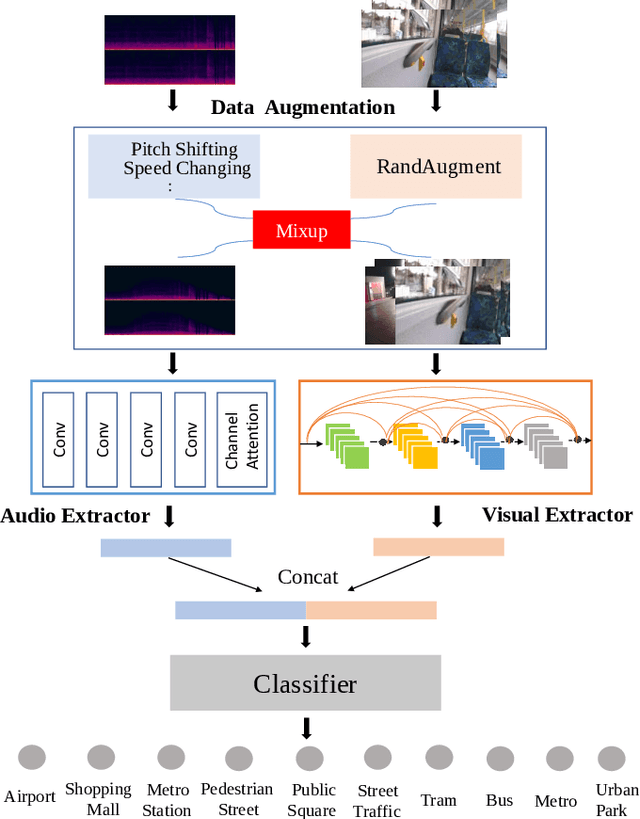
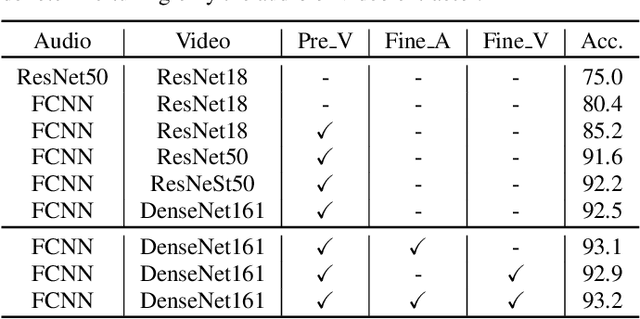
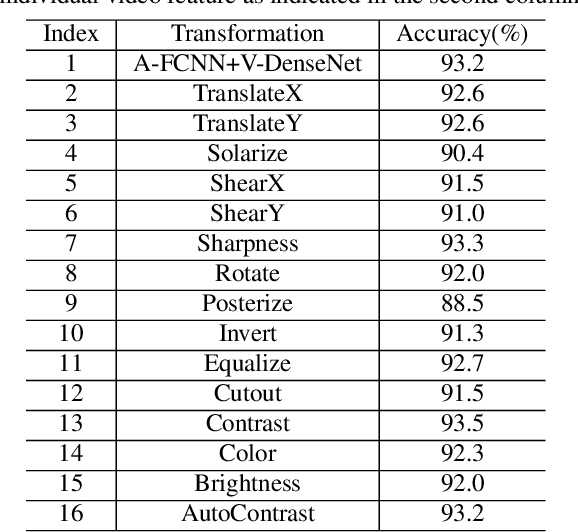
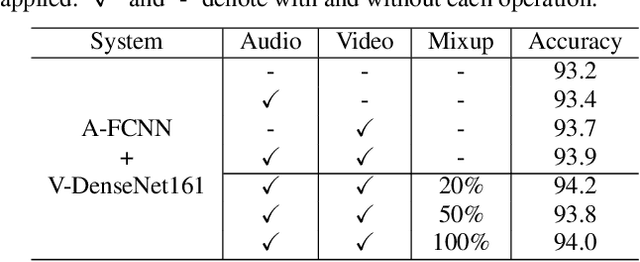
In this paper, we propose two techniques, namely joint modeling and data augmentation, to improve system performances for audio-visual scene classification (AVSC). We employ pre-trained networks trained only on image data sets to extract video embedding; whereas for audio embedding models, we decide to train them from scratch. We explore different neural network architectures for joint modeling to effectively combine the video and audio modalities. Moreover, data augmentation strategies are investigated to increase audio-visual training set size. For the video modality the effectiveness of several operations in RandAugment is verified. An audio-video joint mixup scheme is proposed to further improve AVSC performances. Evaluated on the development set of TAU Urban Audio Visual Scenes 2021, our final system can achieve the best accuracy of 94.2% among all single AVSC systems submitted to DCASE 2021 Task 1b.