 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mixed Differential Privacy in Computer Vision
Mar 28, 2022
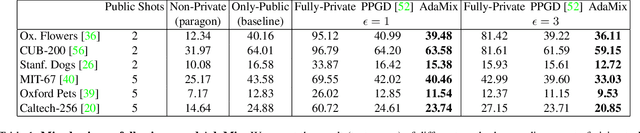
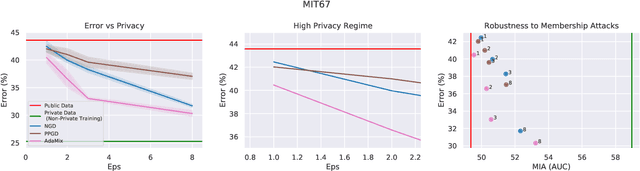
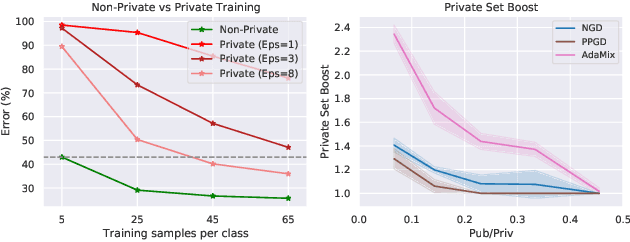
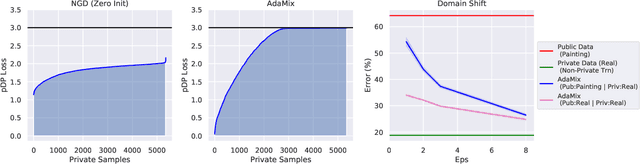
We introduce AdaMix, an adaptive differentially private algorithm for training deep neural network classifiers using both private and public image data. While pre-training language models on large public datasets has enabled strong differential privacy (DP) guarantees with minor loss of accuracy, a similar practice yields punishing trade-offs in vision tasks. A few-shot or even zero-shot learning baseline that ignores private data can outperform fine-tuning on a large private dataset. AdaMix incorporates few-shot training, or cross-modal zero-shot learning, on public data prior to private fine-tuning, to improve the trade-off. AdaMix reduces the error increase from the non-private upper bound from the 167-311\% of the baseline, on average across 6 datasets, to 68-92\% depending on the desired privacy level selected by the user. AdaMix tackles the trade-off arising in visual classification, whereby the most privacy sensitive data, corresponding to isolated points in representation space, are also critical for high classification accuracy. In addition, AdaMix comes with strong theoretical privacy guarantees and convergence analysis.
Coarse-to-Fine Feature Mining for Video Semantic Segmentation
Apr 07, 2022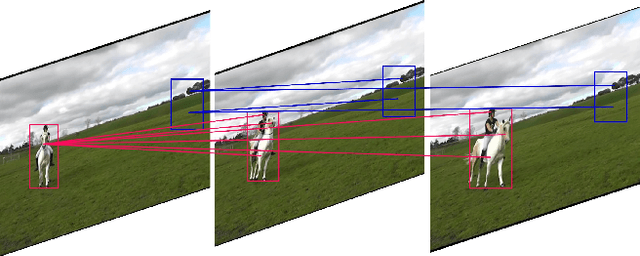
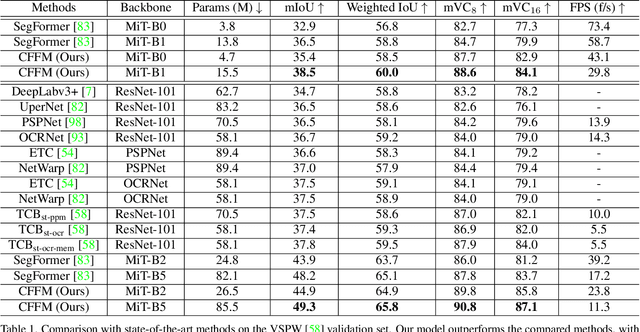
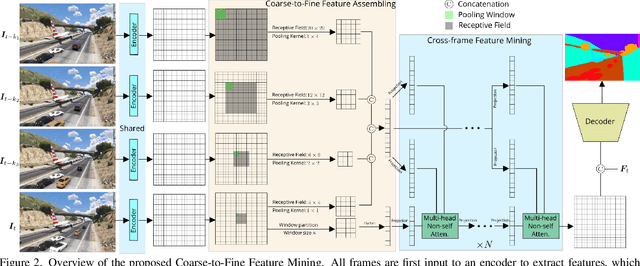
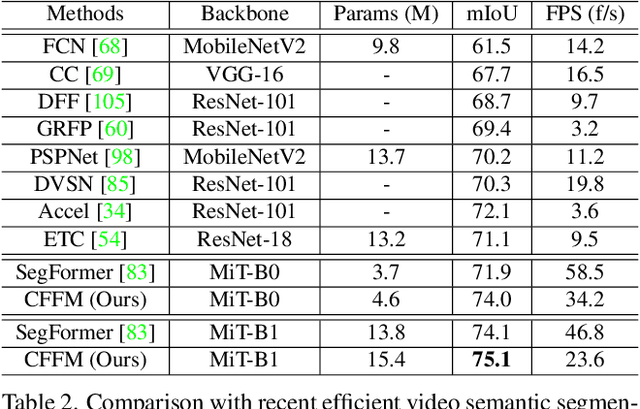
The contextual information plays a core role in semantic segmentation. As for video semantic segmentation, the contexts include static contexts and motional contexts, corresponding to static content and moving content in a video clip, respectively. The static contexts are well exploited in image semantic segmentation by learning multi-scale and global/long-range features. The motional contexts are studied in previous video semantic segmentation. However, there is no research about how to simultaneously learn static and motional contexts which are highly correlated and complementary to each other. To address this problem, we propose a Coarse-to-Fine Feature Mining (CFFM) technique to learn a unified presentation of static contexts and motional contexts. This technique consists of two parts: coarse-to-fine feature assembling and cross-frame feature mining. The former operation prepares data for further processing, enabling the subsequent joint learning of static and motional contexts. The latter operation mines useful information/contexts from the sequential frames to enhance the video contexts of the features of the target frame. The enhanced features can be directly applied for the final prediction. Experimental results on popular benchmarks demonstrate that the proposed CFFM performs favorably against state-of-the-art methods for video semantic segmentation. Our implementation is available at https://github.com/GuoleiSun/VSS-CFFM
CFPNet-M: A Light-Weight Encoder-Decoder Based Network for Multimodal Biomedical Image Real-Time Segmentation
May 10, 2021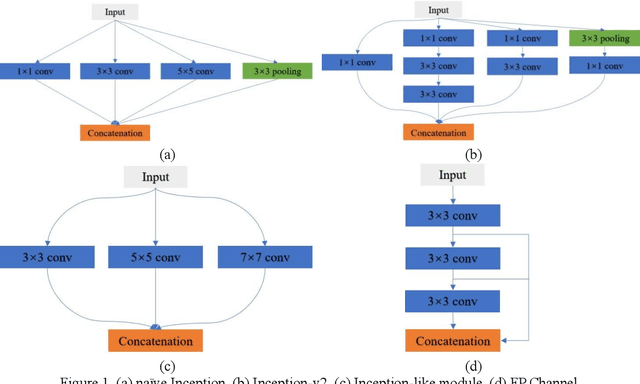
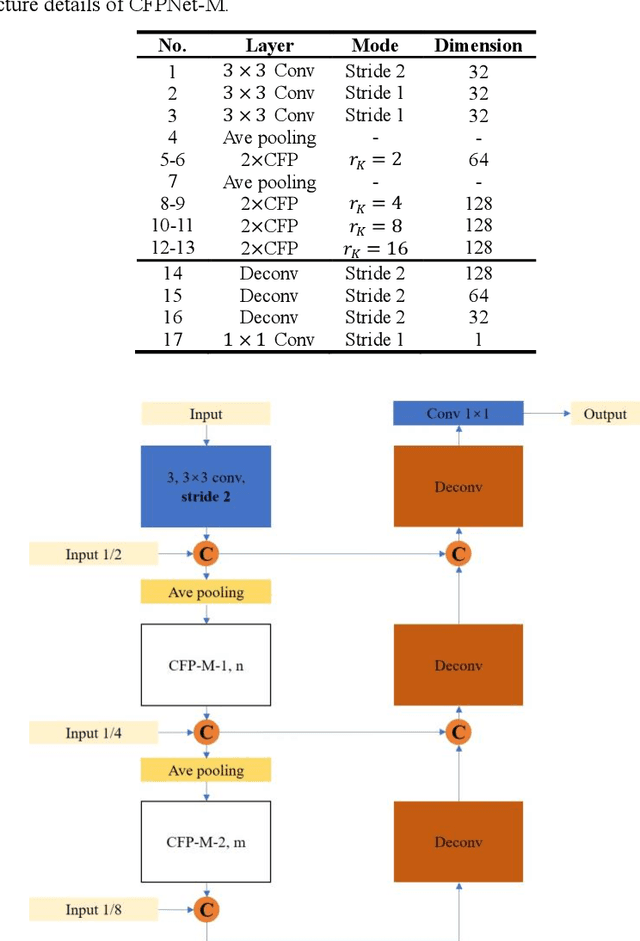
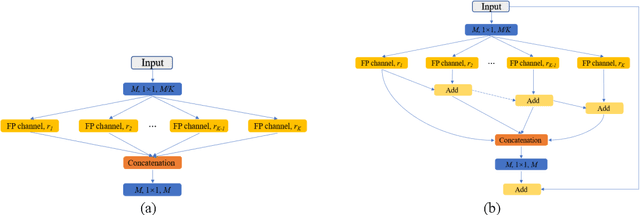

Currently, developments of deep learning techniques are providing instrumental to identify, classify, and quantify patterns in medical images. Segmentation is one of the important applications in medical image analysis. In this regard, U-Net is the predominant approach to medical image segmentation tasks. However, we found that those U-Net based models have limitations in several aspects, for example, millions of parameters in the U-Net consuming considerable computation resource and memory, lack of global information, and missing some tough objects. Therefore, we applied two modifications to improve the U-Net model: 1) designed and added the dilated channel-wise CNN module, 2) simplified the U shape network. Based on these two modifications, we proposed a novel light-weight architecture -- Channel-wise Feature Pyramid Network for Medicine (CFPNet-M). To evaluate our method, we selected five datasets with different modalities: thermography, electron microscopy, endoscopy, dermoscopy, and digital retinal images. And we compared its performance with several models having different parameter scales. This paper also involves our previous studies of DC-UNet and some commonly used light-weight neural networks. We applied the Tanimoto similarity instead of the Jaccard index for gray-level image measurements. By comparison, CFPNet-M achieves comparable segmentation results on all five medical datasets with only 0.65 million parameters, which is about 2% of U-Net, and 8.8 MB memory. Meanwhile, the inference speed can reach 80 FPS on a single RTX 2070Ti GPU with the 256 by 192 pixels input size.
U-Boost NAS: Utilization-Boosted Differentiable Neural Architecture Search
Mar 23, 2022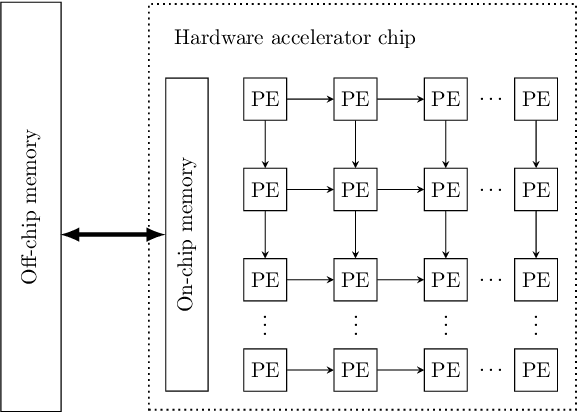

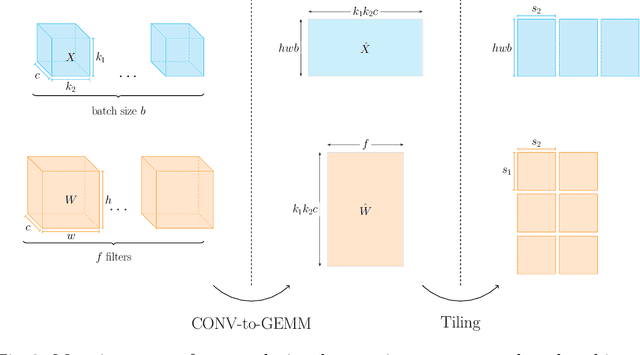
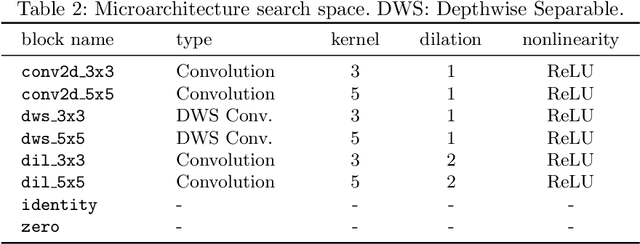
Optimizing resource utilization in target platforms is key to achieving high performance during DNN inference. While optimizations have been proposed for inference latency, memory footprint, and energy consumption, prior hardware-aware neural architecture search (NAS) methods have omitted resource utilization, preventing DNNs to take full advantage of the target inference platforms. Modeling resource utilization efficiently and accurately is challenging, especially for widely-used array-based inference accelerators such as Google TPU. In this work, we propose a novel hardware-aware NAS framework that does not only optimize for task accuracy and inference latency, but also for resource utilization. We also propose and validate a new computational model for resource utilization in inference accelerators. By using the proposed NAS framework and the proposed resource utilization model, we achieve 2.8 - 4x speedup for DNN inference compared to prior hardware-aware NAS methods while attaining similar or improved accuracy in image classification on CIFAR-10 and Imagenet-100 datasets.
SSR-HEF: Crowd Counting with Multi-Scale Semantic Refining and Hard Example Focusing
Apr 15, 2022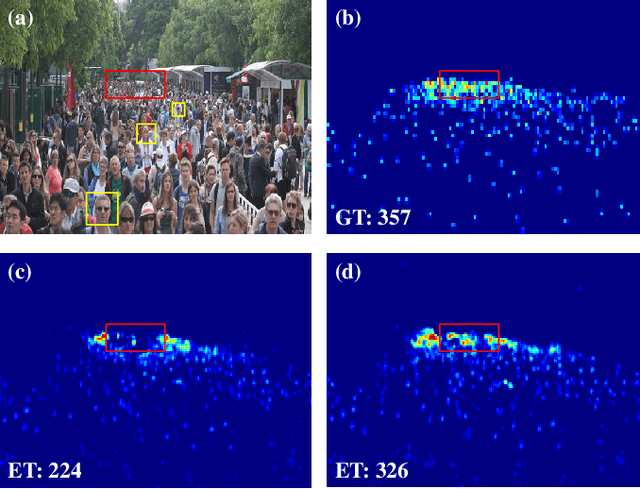
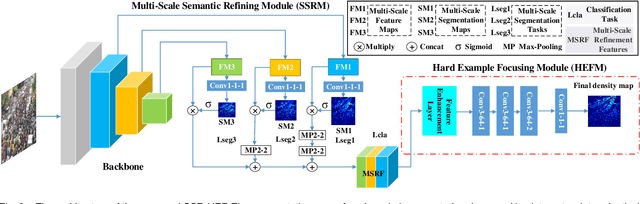
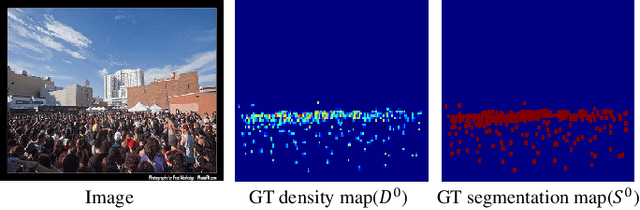
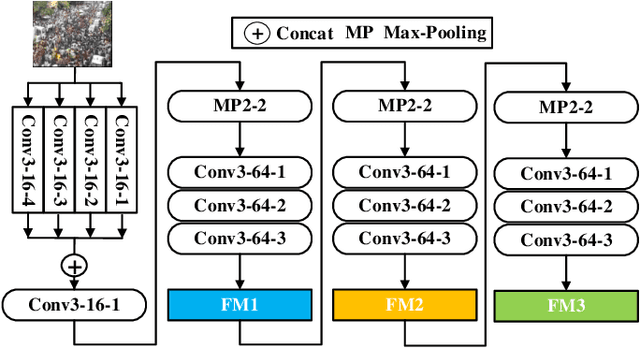
Crowd counting based on density maps is generally regarded as a regression task.Deep learning is used to learn the mapping between image content and crowd density distribution. Although great success has been achieved, some pedestrians far away from the camera are difficult to be detected. And the number of hard examples is often larger. Existing methods with simple Euclidean distance algorithm indiscriminately optimize the hard and easy examples so that the densities of hard examples are usually incorrectly predicted to be lower or even zero, which results in large counting errors. To address this problem, we are the first to propose the Hard Example Focusing(HEF) algorithm for the regression task of crowd counting. The HEF algorithm makes our model rapidly focus on hard examples by attenuating the contribution of easy examples.Then higher importance will be given to the hard examples with wrong estimations. Moreover, the scale variations in crowd scenes are large, and the scale annotations are labor-intensive and expensive. By proposing a multi-Scale Semantic Refining (SSR) strategy, lower layers of our model can break through the limitation of deep learning to capture semantic features of different scales to sufficiently deal with the scale variation. We perform extensive experiments on six benchmark datasets to verify the proposed method. Results indicate the superiority of our proposed method over the state-of-the-art methods. Moreover, our designed model is smaller and faster.
* Accepted by IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS
Multimodal Interactions Using Pretrained Unimodal Models for SIMMC 2.0
Dec 13, 2021


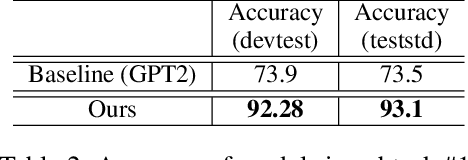
This paper presents our work on the Situated Interactive MultiModal Conversations 2.0 challenge held at Dialog State Tracking Challenge 10. SIMMC 2.0 includes 4 subtasks, and we introduce our multimodal approaches for the subtask \#1, \#2 and the generation of subtask \#4. SIMMC 2.0 dataset is a multimodal dataset containing image and text information, which is more challenging than the problem of only text-based conversations because it must be solved by understanding the relationship between image and text. Therefore, since there is a limit to solving only text models such as BERT or GPT2, we propose a multimodal model combining image and text. We first pretrain the multimodal model to understand the relationship between image and text, then finetune our model for each task. We achieve the 3rd best performance in subtask \#1, \#2 and a runner-up in the generation of subtask \#4. The source code is available at https://github.com/rungjoo/simmc2.0.
MONAI Label: A framework for AI-assisted Interactive Labeling of 3D Medical Images
Mar 23, 2022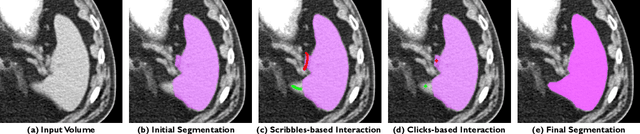
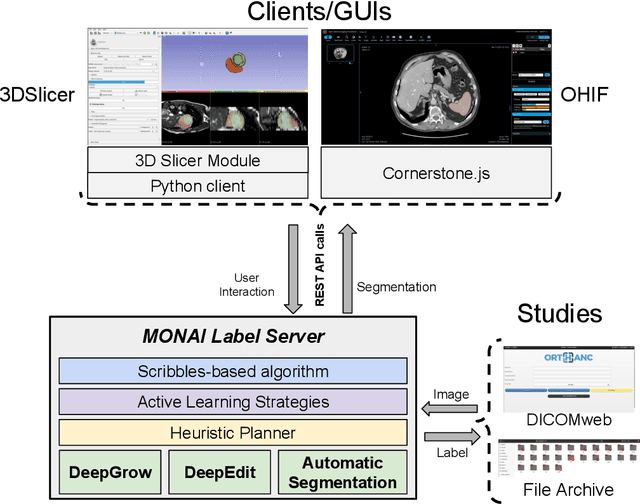
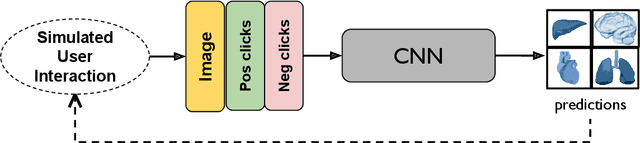
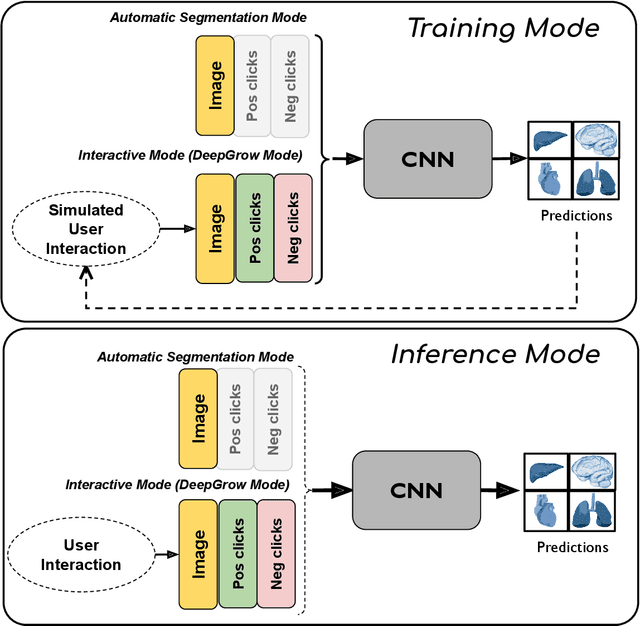
The lack of annotated datasets is a major challenge in training new task-specific supervised AI algorithms as manual annotation is expensive and time-consuming. To address this problem, we present MONAI Label, a free and open-source platform that facilitates the development of AI-based applications that aim at reducing the time required to annotate 3D medical image datasets. Through MONAI Label researchers can develop annotation applications focusing on their domain of expertise. It allows researchers to readily deploy their apps as services, which can be made available to clinicians via their preferred user-interface. Currently, MONAI Label readily supports locally installed (3DSlicer) and web-based (OHIF) frontends, and offers two Active learning strategies to facilitate and speed up the training of segmentation algorithms. MONAI Label allows researchers to make incremental improvements to their labeling apps by making them available to other researchers and clinicians alike. Lastly, MONAI Label provides sample labeling apps, namely DeepEdit and DeepGrow, demonstrating dramatically reduced annotation times.
SLOGAN: Handwriting Style Synthesis for Arbitrary-Length and Out-of-Vocabulary Text
Feb 23, 2022



Large amounts of labeled data are urgently required for the training of robust text recognizers. However, collecting handwriting data of diverse styles, along with an immense lexicon, is considerably expensive. Although data synthesis is a promising way to relieve data hunger, two key issues of handwriting synthesis, namely, style representation and content embedding, remain unsolved. To this end, we propose a novel method that can synthesize parameterized and controllable handwriting Styles for arbitrary-Length and Out-of-vocabulary text based on a Generative Adversarial Network (GAN), termed SLOGAN. Specifically, we propose a style bank to parameterize the specific handwriting styles as latent vectors, which are input to a generator as style priors to achieve the corresponding handwritten styles. The training of the style bank requires only the writer identification of the source images, rather than attribute annotations. Moreover, we embed the text content by providing an easily obtainable printed style image, so that the diversity of the content can be flexibly achieved by changing the input printed image. Finally, the generator is guided by dual discriminators to handle both the handwriting characteristics that appear as separated characters and in a series of cursive joins. Our method can synthesize words that are not included in the training vocabulary and with various new styles. Extensive experiments have shown that high-quality text images with great style diversity and rich vocabulary can be synthesized using our method, thereby enhancing the robustness of the recognizer.
Recursive Frequency Selective Reconstruction of Non-Regularly Sampled Video Data
Apr 07, 2022
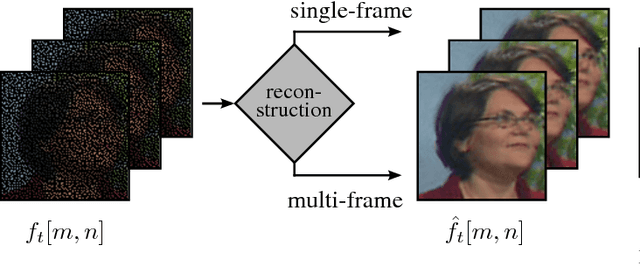
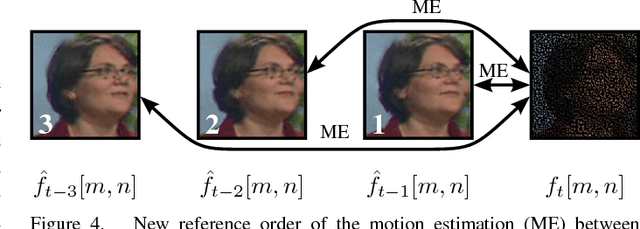
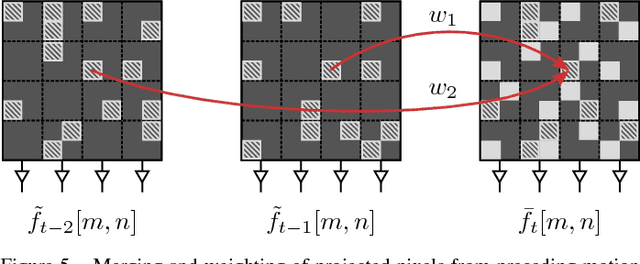
High resolution images can be acquired using a non-regular sampling sensor which consists of an underlying low resolution sensor that is covered with a non-regular sampling mask. The reconstructed high resolution image is then obtained during post-processing. Recently, it has been shown that the temporal correlation between neighboring frames can be exploited in order to enhance the reconstruction quality of non-regularly sampled video data. In this paper, a new recursive multi-frame reconstruction approach is proposed in order to further increase the reconstruction quality. By using a new reference order, previously reconstructed frames can be used for the subsequent motion estimation and a new weighting function allows for the incorporation of multiple pixels projected onto the same position. With the new recursive multi-frame approach, a visually noticeable average gain in PSNR of up to 1.13 dB with respect to a state-of-the-art single-frame reconstruction approach can be achieved. Compared to the existing multi-frame approach, a gain of 0.31 dB is possible. SSIM results show the same behavior as PSNR results. Additionally, the pre-reconstruction step of the existing multi-frame approach can be avoided and the new algorithm is, in general, capable of real-time processing.
Cycle-Consistent Counterfactuals by Latent Transformations
Mar 28, 2022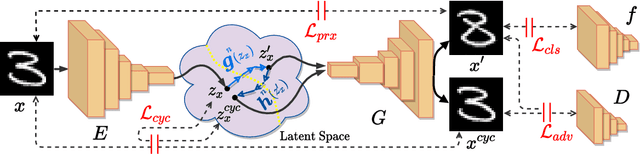



CounterFactual (CF) visual explanations try to find images similar to the query image that change the decision of a vision system to a specified outcome. Existing methods either require inference-time optimization or joint training with a generative adversarial model which makes them time-consuming and difficult to use in practice. We propose a novel approach, Cycle-Consistent Counterfactuals by Latent Transformations (C3LT), which learns a latent transformation that automatically generates visual CFs by steering in the latent space of generative models. Our method uses cycle consistency between the query and CF latent representations which helps our training to find better solutions. C3LT can be easily plugged into any state-of-the-art pretrained generative network. This enables our method to generate high-quality and interpretable CF images at high resolution such as those in ImageNet. In addition to several established metrics for evaluating CF explanations, we introduce a novel metric tailored to assess the quality of the generated CF examples and validate the effectiveness of our method on an extensive set of experiments.