 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Answer-Me: Multi-Task Open-Vocabulary Visual Question Answering
May 02, 2022

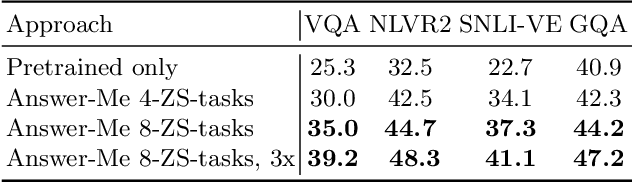
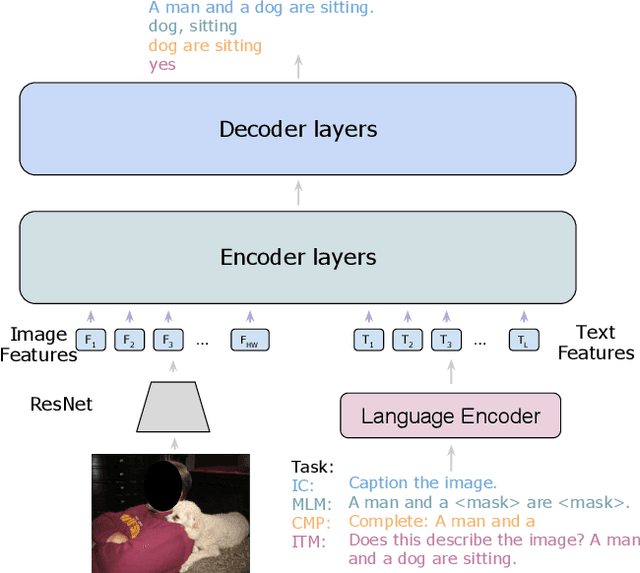
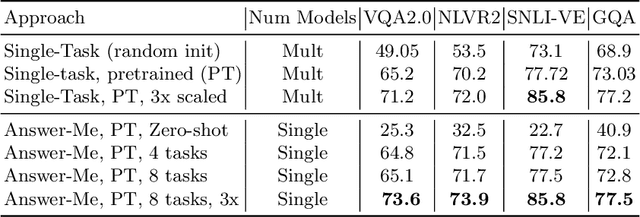
We present Answer-Me, a task-aware multi-task framework which unifies a variety of question answering tasks, such as, visual question answering, visual entailment, visual reasoning. In contrast to previous works using contrastive or generative captioning training, we propose a novel and simple recipe to pre-train a vision-language joint model, which is multi-task as well. The pre-training uses only noisy image captioning data, and is formulated to use the entire architecture end-to-end with both a strong language encoder and decoder. Our results show state-of-the-art performance, zero-shot generalization, robustness to forgetting, and competitive single-task results across a variety of question answering tasks. Our multi-task mixture training learns from tasks of various question intents and thus generalizes better, including on zero-shot vision-language tasks. We conduct experiments in the challenging multi-task and open-vocabulary settings and across a variety of datasets and tasks, such as VQA2.0, SNLI-VE, NLVR2, GQA, VizWiz. We observe that the proposed approach is able to generalize to unseen tasks and that more diverse mixtures lead to higher accuracy in both known and novel tasks.
Federated Learning with Partial Model Personalization
Apr 08, 2022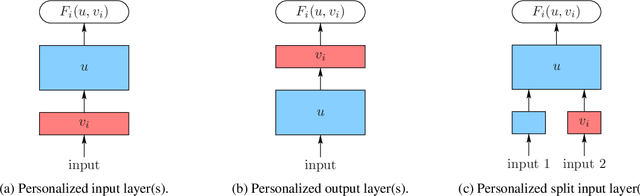

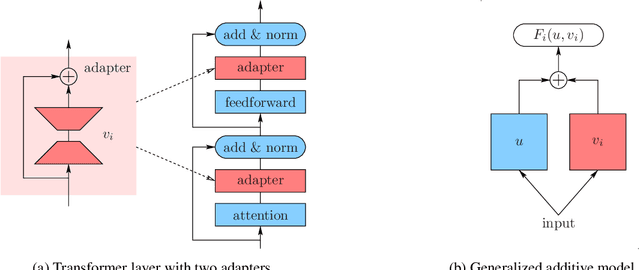

We consider two federated learning algorithms for training partially personalized models, where the shared and personal parameters are updated either simultaneously or alternately on the devices. Both algorithms have been proposed in the literature, but their convergence properties are not fully understood, especially for the alternating variant. We provide convergence analyses of both algorithms in the general nonconvex setting with partial participation and delineate the regime where one dominates the other. Our experiments on real-world image, text, and speech datasets demonstrate that (a) partial personalization can obtain most of the benefits of full model personalization with a small fraction of personal parameters, and, (b) the alternating update algorithm often outperforms the simultaneous update algorithm.
Cross-Modal Contrastive Learning for Text-to-Image Generation
Jan 15, 2021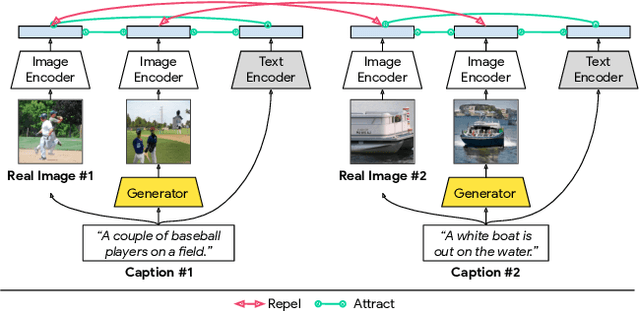
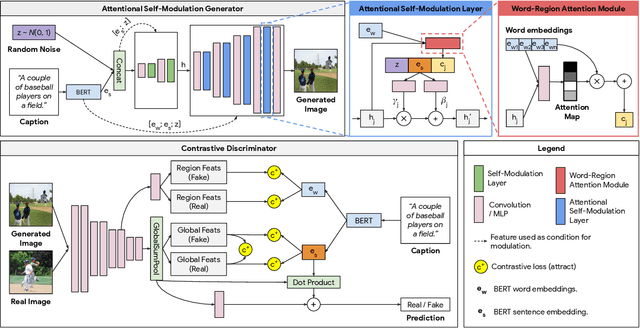
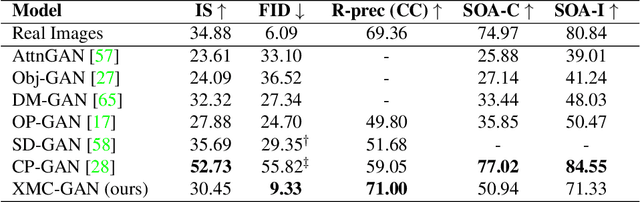
The output of text-to-image synthesis systems should be coherent, clear, photo-realistic scenes with high semantic fidelity to their conditioned text descriptions. Our Cross-Modal Contrastive Generative Adversarial Network (XMC-GAN) addresses this challenge by maximizing the mutual information between image and text. It does this via multiple contrastive losses which capture inter-modality and intra-modality correspondences. XMC-GAN uses an attentional self-modulation generator, which enforces strong text-image correspondence, and a contrastive discriminator, which acts as a critic as well as a feature encoder for contrastive learning. The quality of XMC-GAN's output is a major step up from previous models, as we show on three challenging datasets. On MS-COCO, not only does XMC-GAN improve state-of-the-art FID from 24.70 to 9.33, but--more importantly--people prefer XMC-GAN by 77.3 for image quality and 74.1 for image-text alignment, compared to three other recent models. XMC-GAN also generalizes to the challenging Localized Narratives dataset (which has longer, more detailed descriptions), improving state-of-the-art FID from 48.70 to 14.12. Lastly, we train and evaluate XMC-GAN on the challenging Open Images data, establishing a strong benchmark FID score of 26.91.
Describe What to Change: A Text-guided Unsupervised Image-to-Image Translation Approach
Aug 10, 2020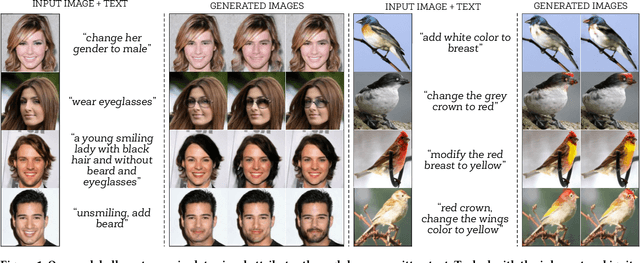
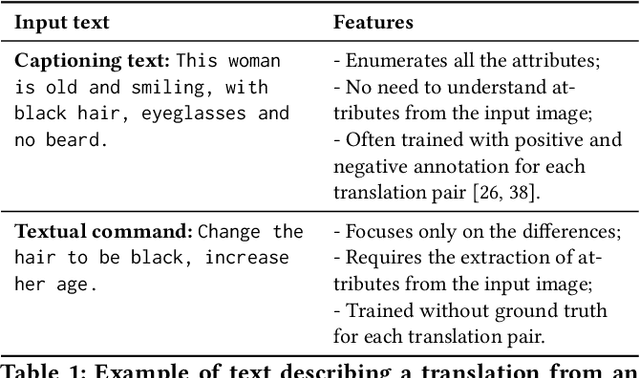
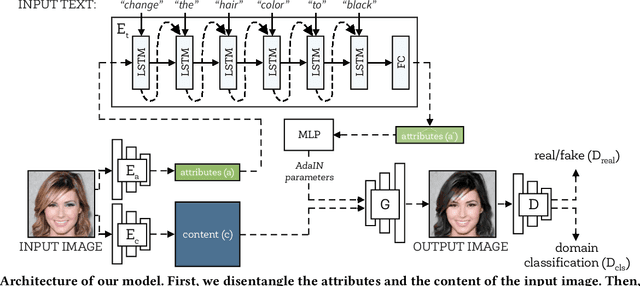

Manipulating visual attributes of images through human-written text is a very challenging task. On the one hand, models have to learn the manipulation without the ground truth of the desired output. On the other hand, models have to deal with the inherent ambiguity of natural language. Previous research usually requires either the user to describe all the characteristics of the desired image or to use richly-annotated image captioning datasets. In this work, we propose a novel unsupervised approach, based on image-to-image translation, that alters the attributes of a given image through a command-like sentence such as "change the hair color to black". Contrarily to state-of-the-art approaches, our model does not require a human-annotated dataset nor a textual description of all the attributes of the desired image, but only those that have to be modified. Our proposed model disentangles the image content from the visual attributes, and it learns to modify the latter using the textual description, before generating a new image from the content and the modified attribute representation. Because text might be inherently ambiguous (blond hair may refer to different shadows of blond, e.g. golden, icy, sandy), our method generates multiple stochastic versions of the same translation. Experiments show that the proposed model achieves promising performances on two large-scale public datasets: CelebA and CUB. We believe our approach will pave the way to new avenues of research combining textual and speech commands with visual attributes.
Sketch-QNet: A Quadruplet ConvNet for Color Sketch-based Image Retrieval
Apr 22, 2021
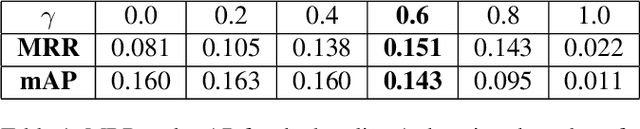
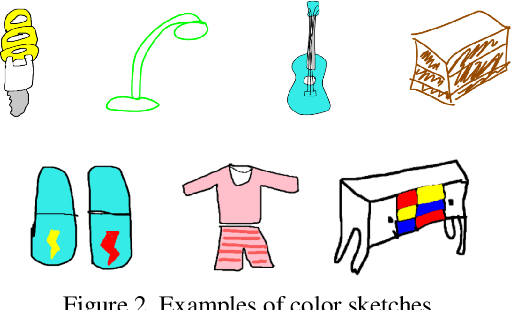
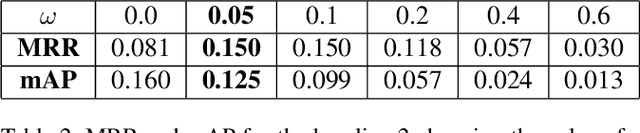
Architectures based on siamese networks with triplet loss have shown outstanding performance on the image-based similarity search problem. This approach attempts to discriminate between positive (relevant) and negative (irrelevant) items. However, it undergoes a critical weakness. Given a query, it cannot discriminate weakly relevant items, for instance, items of the same type but different color or texture as the given query, which could be a serious limitation for many real-world search applications. Therefore, in this work, we present a quadruplet-based architecture that overcomes the aforementioned weakness. Moreover, we present an instance of this quadruplet network, which we call Sketch-QNet, to deal with the color sketch-based image retrieval (CSBIR) problem, achieving new state-of-the-art results.
Improving Multimodal Speech Recognition by Data Augmentation and Speech Representations
Apr 27, 2022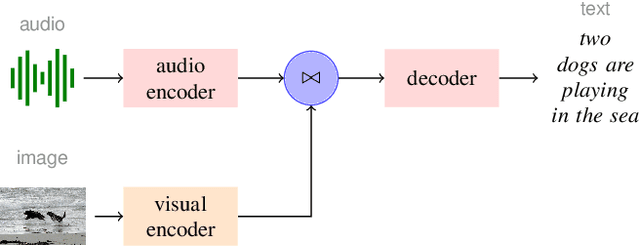
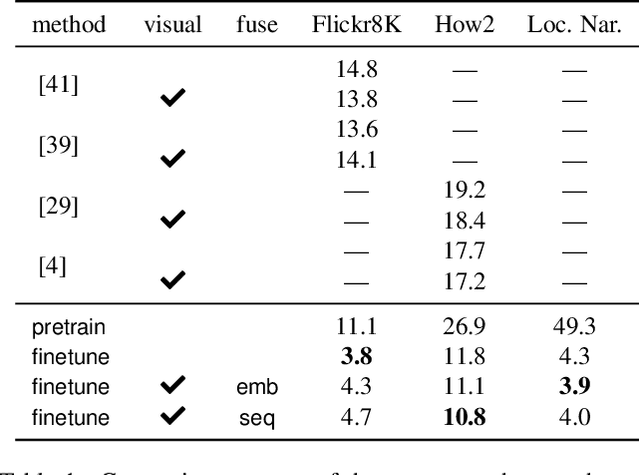
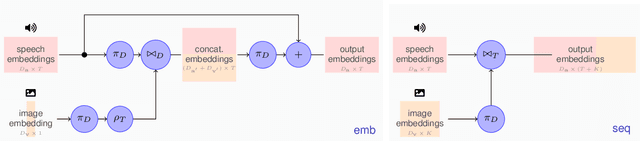
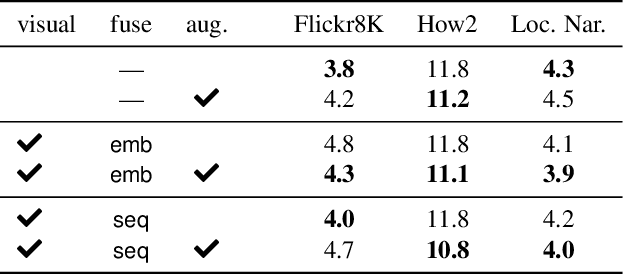
Multimodal speech recognition aims to improve the performance of automatic speech recognition (ASR) systems by leveraging additional visual information that is usually associated to the audio input. While previous approaches make crucial use of strong visual representations, e.g. by finetuning pretrained image recognition networks, significantly less attention has been paid to its counterpart: the speech component. In this work, we investigate ways of improving the base speech recognition system by following similar techniques to the ones used for the visual encoder, namely, transferring representations and data augmentation. First, we show that starting from a pretrained ASR significantly improves the state-of-the-art performance; remarkably, even when building upon a strong unimodal system, we still find gains by including the visual modality. Second, we employ speech data augmentation techniques to encourage the multimodal system to attend to the visual stimuli. This technique replaces previously used word masking and comes with the benefits of being conceptually simpler and yielding consistent improvements in the multimodal setting. We provide empirical results on three multimodal datasets, including the newly introduced Localized Narratives.
COVID-19 Detection Using CT Image Based On YOLOv5 Network
Jan 24, 2022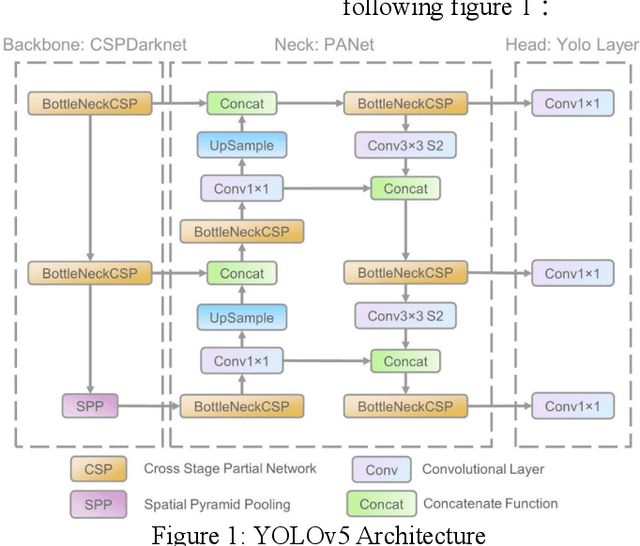
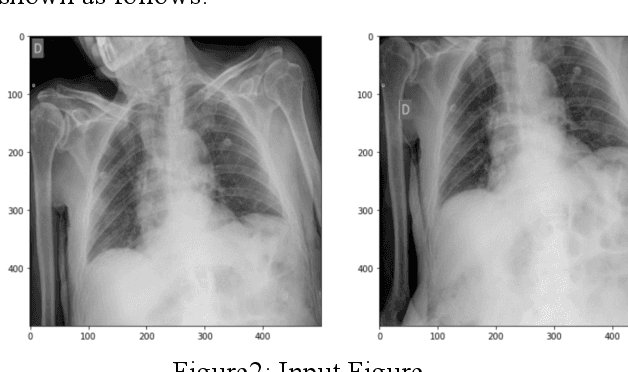
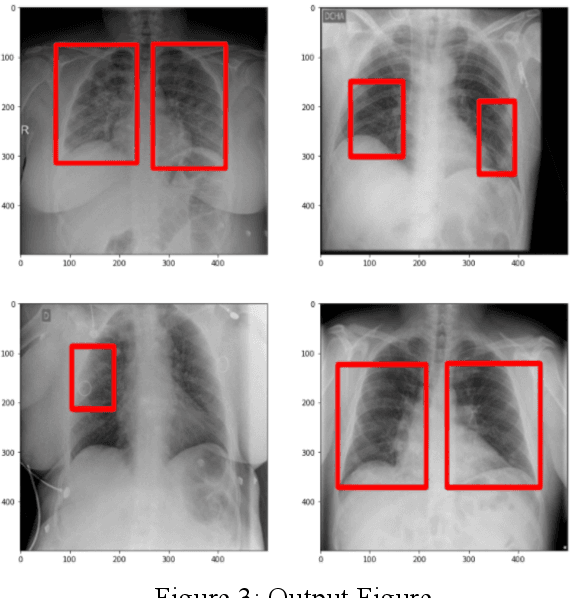

Computer aided diagnosis (CAD) increases diagnosis efficiency, helping doctors providing a quick and confident diagnosis, it has played an important role in the treatment of COVID19. In our task, we solve the problem about abnormality detection and classification. The dataset provided by Kaggle platform and we choose YOLOv5 as our model. We introduce some methods on objective detection in the related work section, the objection detection can be divided into two streams: onestage and two stage. The representational model are Faster RCNN and YOLO series. Then we describe the YOLOv5 model in the detail. Compared Experiments and results are shown in section IV. We choose mean average precision (mAP) as our experiments' metrics, and the higher (mean) mAP is, the better result the model will gain. mAP@0.5 of our YOLOv5s is 0.623 which is 0.157 and 0.101 higher than Faster RCNN and EfficientDet respectively.
Towards Precise and Efficient Image Guided Depth Completion
Mar 01, 2021



Image guided depth completion is the task of generating a dense depth map from a sparse depth map and a high quality image. In this task, how to fuse the color and depth modalities plays an important role in achieving good performance. This paper proposes a two-branch backbone that consists of a color-dominant branch and a depth-dominant branch to exploit and fuse two modalities thoroughly. More specifically, one branch inputs a color image and a sparse depth map to predict a dense depth map. The other branch takes as inputs the sparse depth map and the previously predicted depth map, and outputs a dense depth map as well. The depth maps predicted from two branches are complimentary to each other and therefore they are adaptively fused. In addition, we also propose a simple geometric convolutional layer to encode 3D geometric cues. The geometric encoded backbone conducts the fusion of different modalities at multiple stages, leading to good depth completion results. We further implement a dilated and accelerated CSPN++ to refine the fused depth map efficiently. The proposed full model ranks 1st in the KITTI depth completion online leaderboard at the time of submission. It also infers much faster than most of the top ranked methods. The code of this work will be available at https://github.com/JUGGHM/PENet_ICRA2021.
Efficient Gesture Recognition for the Assistance of Visually Impaired People using Multi-Head Neural Networks
May 14, 2022
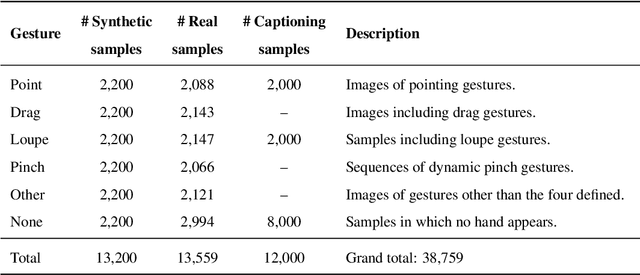
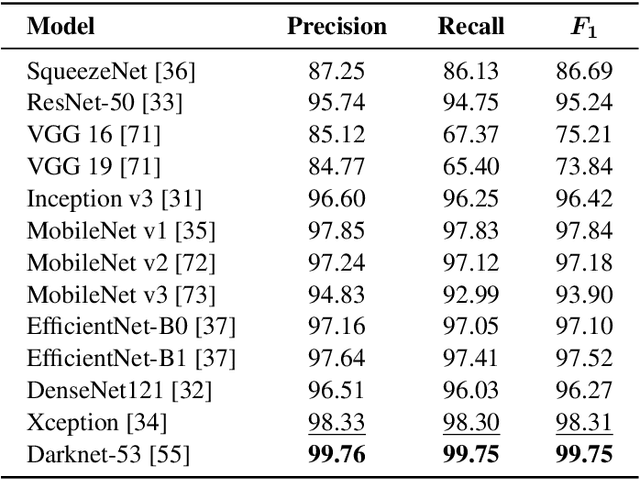
This paper proposes an interactive system for mobile devices controlled by hand gestures aimed at helping people with visual impairments. This system allows the user to interact with the device by making simple static and dynamic hand gestures. Each gesture triggers a different action in the system, such as object recognition, scene description or image scaling (e.g., pointing a finger at an object will show a description of it). The system is based on a multi-head neural network architecture, which initially detects and classifies the gestures, and subsequently, depending on the gesture detected, performs a second stage that carries out the corresponding action. This multi-head architecture optimizes the resources required to perform different tasks simultaneously, and takes advantage of the information obtained from an initial backbone to perform different processes in a second stage. To train and evaluate the system, a dataset with about 40k images was manually compiled and labeled including different types of hand gestures, backgrounds (indoors and outdoors), lighting conditions, etc. This dataset contains synthetic gestures (whose objective is to pre-train the system in order to improve the results) and real images captured using different mobile phones. The results obtained and the comparison made with the state of the art show competitive results as regards the different actions performed by the system, such as the accuracy of classification and localization of gestures, or the generation of descriptions for objects and scenes.
Differentiable Patch Selection for Image Recognition
Apr 07, 2021
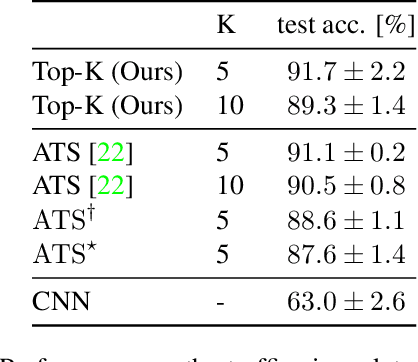
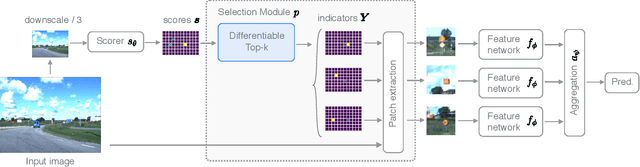
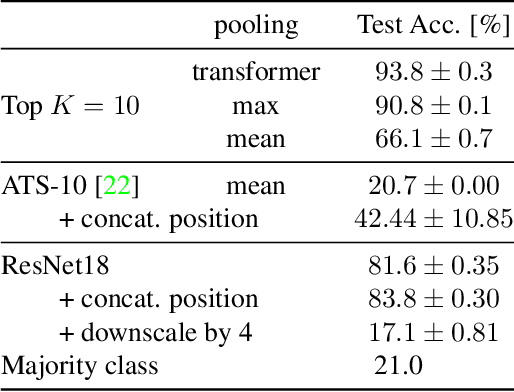
Neural Networks require large amounts of memory and compute to process high resolution images, even when only a small part of the image is actually informative for the task at hand. We propose a method based on a differentiable Top-K operator to select the most relevant parts of the input to efficiently process high resolution images. Our method may be interfaced with any downstream neural network, is able to aggregate information from different patches in a flexible way, and allows the whole model to be trained end-to-end using backpropagation. We show results for traffic sign recognition, inter-patch relationship reasoning, and fine-grained recognition without using object/part bounding box annotations during training.