 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Noisy Data and LLM Pretraining Loss Divergence
Feb 02, 2026Large-scale pretraining datasets drive the success of large language models (LLMs). However, these web-scale corpora inevitably contain large amounts of noisy data due to unregulated web content or randomness inherent in data. Although LLM pretrainers often speculate that such noise contributes to instabilities in large-scale LLM pretraining and, in the worst cases, loss divergence, this phenomenon remains poorly understood.In this work, we present a systematic empirical study of whether noisy data causes LLM pretraining divergences and how it does so. By injecting controlled synthetic uniformly random noise into otherwise clean datasets, we analyze training dynamics across model sizes ranging from 480M to 5.2B parameters. We show that noisy data indeed induces training loss divergence, and that the probability of divergence depends strongly on the noise type, amount of noise, and model scale. We further find that noise-induced divergences exhibit activation patterns distinct from those caused by high learning rates, and we provide diagnostics that differentiate these two failure modes. Together, these results provide a large-scale, controlled characterization of how noisy data affects loss divergence in LLM pretraining.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Effective Long-Context Scaling of Foundation Models
Sep 27, 2023



We present a series of long-context LLMs that support effective context windows of up to 32,768 tokens. Our model series are built through continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled. We perform extensive evaluation on language modeling, synthetic context probing tasks, and a wide range of research benchmarks. On research benchmarks, our models achieve consistent improvements on most regular tasks and significant improvements on long-context tasks over Llama 2. Notably, with a cost-effective instruction tuning procedure that does not require human-annotated long instruction data, the 70B variant can already surpass gpt-3.5-turbo-16k's overall performance on a suite of long-context tasks. Alongside these results, we provide an in-depth analysis on the individual components of our method. We delve into Llama's position encodings and discuss its limitation in modeling long dependencies. We also examine the impact of various design choices in the pretraining process, including the data mix and the training curriculum of sequence lengths -- our ablation experiments suggest that having abundant long texts in the pretrain dataset is not the key to achieving strong performance, and we empirically verify that long context continual pretraining is more efficient and similarly effective compared to pretraining from scratch with long sequences.
Where to Begin? On the Impact of Pre-Training and Initialization in Federated Learning
Oct 14, 2022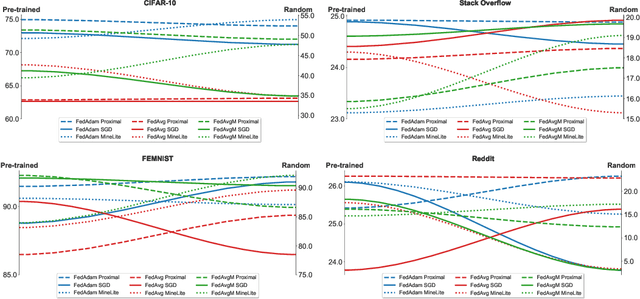

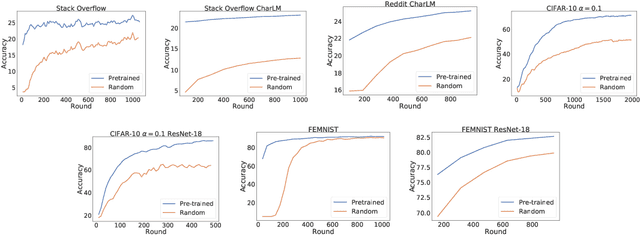
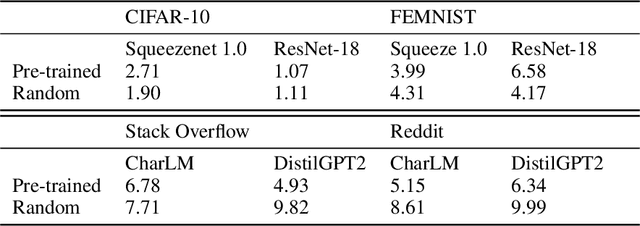
An oft-cited challenge of federated learning is the presence of heterogeneity. \emph{Data heterogeneity} refers to the fact that data from different clients may follow very different distributions. \emph{System heterogeneity} refers to the fact that client devices have different system capabilities. A considerable number of federated optimization methods address this challenge. In the literature, empirical evaluations usually start federated training from random initialization. However, in many practical applications of federated learning, the server has access to proxy data for the training task that can be used to pre-train a model before starting federated training. We empirically study the impact of starting from a pre-trained model in federated learning using four standard federated learning benchmark datasets. Unsurprisingly, starting from a pre-trained model reduces the training time required to reach a target error rate and enables the training of more accurate models (up to 40\%) than is possible when starting from random initialization. Surprisingly, we also find that starting federated learning from a pre-trained initialization reduces the effect of both data and system heterogeneity. We recommend that future work proposing and evaluating federated optimization methods evaluate the performance when starting from random and pre-trained initializations. We also believe this study raises several questions for further work on understanding the role of heterogeneity in federated optimization.
Where to Begin? Exploring the Impact of Pre-Training and Initialization in Federated Learning
Jun 30, 2022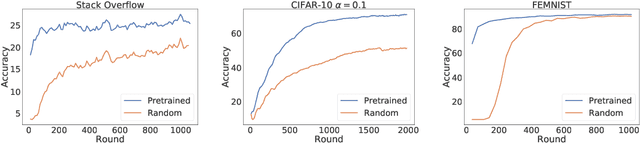



An oft-cited challenge of federated learning is the presence of data heterogeneity -- the data at different clients may follow very different distributions. Several federated optimization methods have been proposed to address these challenges. In the literature, empirical evaluations usually start federated training from a random initialization. However, in many practical applications of federated learning, the server has access to proxy data for the training task which can be used to pre-train a model before starting federated training. We empirically study the impact of starting from a pre-trained model in federated learning using four common federated learning benchmark datasets. Unsurprisingly, starting from a pre-trained model reduces the training time required to reach a target error rate and enables training more accurate models (by up to 40\%) than is possible than when starting from a random initialization. Surprisingly, we also find that the effect of data heterogeneity is much less significant when starting federated training from a pre-trained initialization. Rather, when starting from a pre-trained model, using an adaptive optimizer at the server, such as \textsc{FedAdam}, consistently leads to the best accuracy. We recommend that future work proposing and evaluating federated optimization methods consider the performance when starting both random and pre-trained initializations. We also believe this study raises several questions for further work on understanding the role of heterogeneity in federated optimization.
Federated Learning with Partial Model Personalization
Apr 08, 2022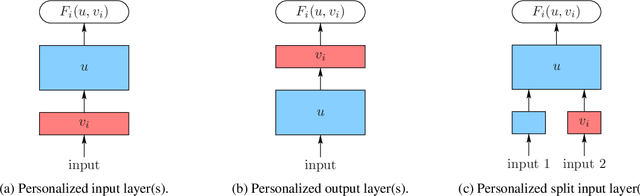

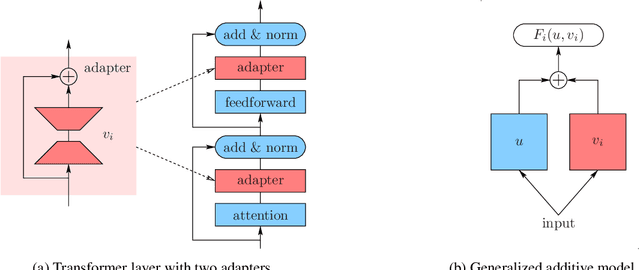

We consider two federated learning algorithms for training partially personalized models, where the shared and personal parameters are updated either simultaneously or alternately on the devices. Both algorithms have been proposed in the literature, but their convergence properties are not fully understood, especially for the alternating variant. We provide convergence analyses of both algorithms in the general nonconvex setting with partial participation and delineate the regime where one dominates the other. Our experiments on real-world image, text, and speech datasets demonstrate that (a) partial personalization can obtain most of the benefits of full model personalization with a small fraction of personal parameters, and, (b) the alternating update algorithm often outperforms the simultaneous update algorithm.
FedSynth: Gradient Compression via Synthetic Data in Federated Learning
Apr 04, 2022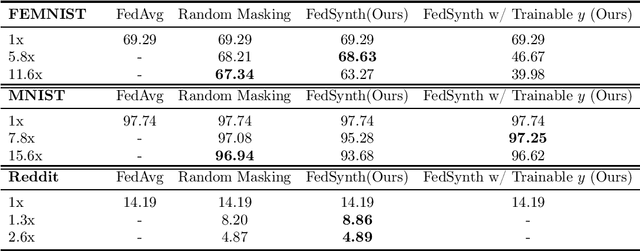
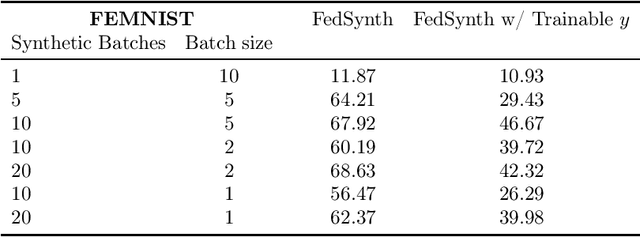

Model compression is important in federated learning (FL) with large models to reduce communication cost. Prior works have been focusing on sparsification based compression that could desparately affect the global model accuracy. In this work, we propose a new scheme for upstream communication where instead of transmitting the model update, each client learns and transmits a light-weight synthetic dataset such that using it as the training data, the model performs similarly well on the real training data. The server will recover the local model update via the synthetic data and apply standard aggregation. We then provide a new algorithm FedSynth to learn the synthetic data locally. Empirically, we find our method is comparable/better than random masking baselines in all three common federated learning benchmark datasets.
Papaya: Practical, Private, and Scalable Federated Learning
Nov 08, 2021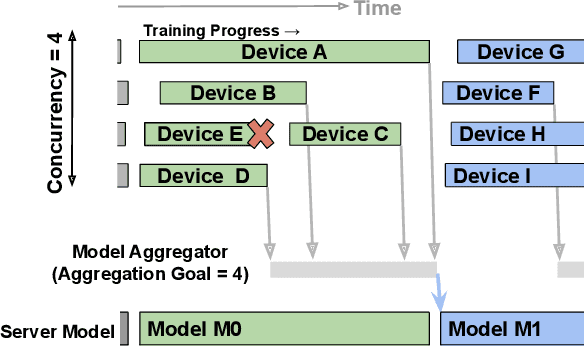
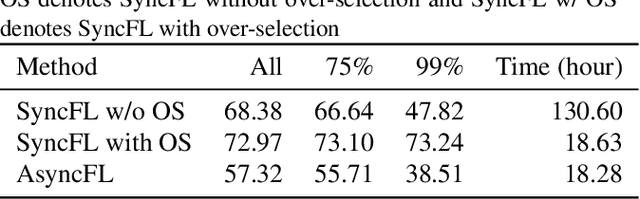
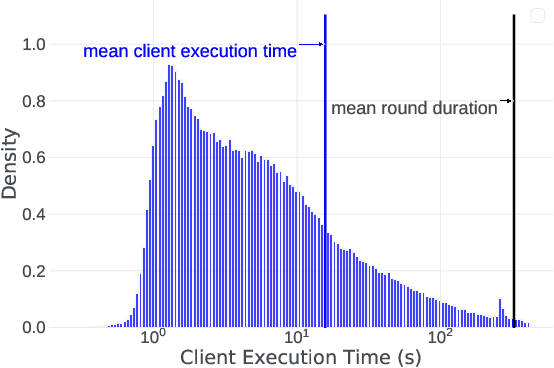
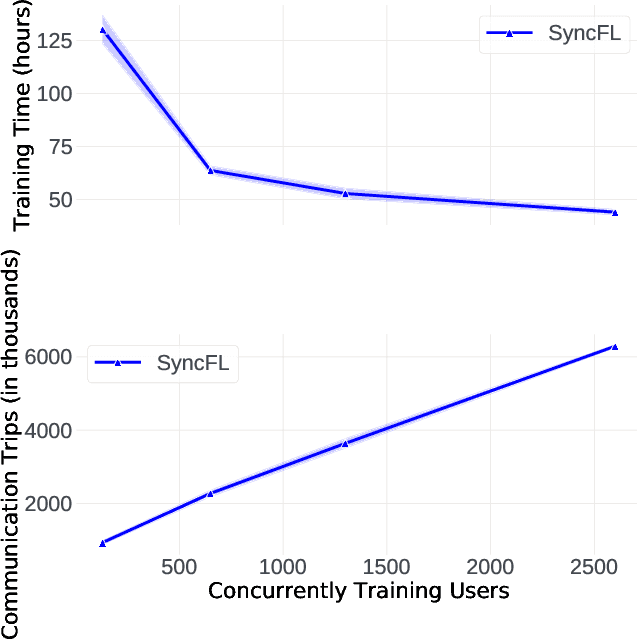
Cross-device Federated Learning (FL) is a distributed learning paradigm with several challenges that differentiate it from traditional distributed learning, variability in the system characteristics on each device, and millions of clients coordinating with a central server being primary ones. Most FL systems described in the literature are synchronous - they perform a synchronized aggregation of model updates from individual clients. Scaling synchronous FL is challenging since increasing the number of clients training in parallel leads to diminishing returns in training speed, analogous to large-batch training. Moreover, stragglers hinder synchronous FL training. In this work, we outline a production asynchronous FL system design. Our work tackles the aforementioned issues, sketches of some of the system design challenges and their solutions, and touches upon principles that emerged from building a production FL system for millions of clients. Empirically, we demonstrate that asynchronous FL converges faster than synchronous FL when training across nearly one hundred million devices. In particular, in high concurrency settings, asynchronous FL is 5x faster and has nearly 8x less communication overhead than synchronous FL.
Federated Learning with Buffered Asynchronous Aggregation
Jun 11, 2021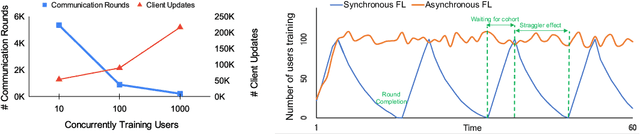

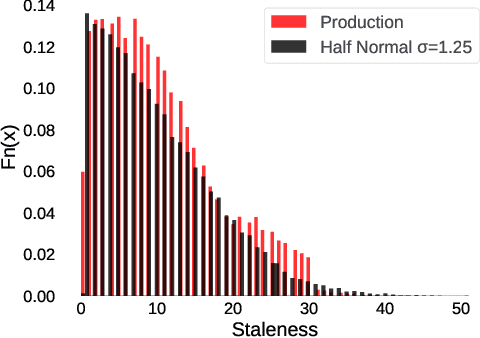
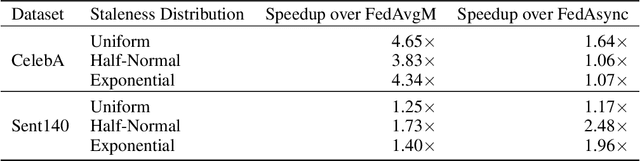
Federated Learning (FL) trains a shared model across distributed devices while keeping the training data on the devices. Most FL schemes are synchronous: they perform a synchronized aggregation of model updates from individual devices. Synchronous training can be slow because of late-arriving devices (stragglers). On the other hand, completely asynchronous training makes FL less private because of incompatibility with secure aggregation. In this work, we propose a model aggregation scheme, FedBuff, that combines the best properties of synchronous and asynchronous FL. Similar to synchronous FL, FedBuff is compatible with secure aggregation. Similar to asynchronous FL, FedBuff is robust to stragglers. In FedBuff, clients trains asynchronously and send updates to the server. The server aggregates client updates in a private buffer until updates have been received, at which point a server model update is immediately performed. We provide theoretical convergence guarantees for FedBuff in a non-convex setting. Empirically, FedBuff converges up to 3.8x faster than previous proposals for synchronous FL (e.g., FedAvgM), and up to 2.5x faster than previous proposals for asynchronous FL (e.g., FedAsync). We show that FedBuff is robust to different staleness distributions and is more scalable than synchronous FL techniques.