 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
L2G: A Simple Local-to-Global Knowledge Transfer Framework for Weakly Supervised Semantic Segmentation
Apr 07, 2022
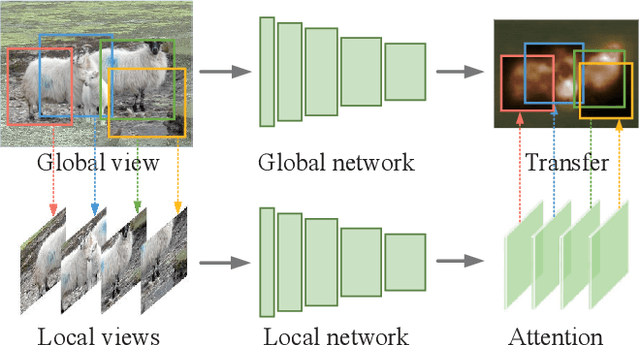


Mining precise class-aware attention maps, a.k.a, class activation maps, is essential for weakly supervised semantic segmentation. In this paper, we present L2G, a simple online local-to-global knowledge transfer framework for high-quality object attention mining. We observe that classification models can discover object regions with more details when replacing the input image with its local patches. Taking this into account, we first leverage a local classification network to extract attentions from multiple local patches randomly cropped from the input image. Then, we utilize a global network to learn complementary attention knowledge across multiple local attention maps online. Our framework conducts the global network to learn the captured rich object detail knowledge from a global view and thereby produces high-quality attention maps that can be directly used as pseudo annotations for semantic segmentation networks. Experiments show that our method attains 72.1% and 44.2% mIoU scores on the validation set of PASCAL VOC 2012 and MS COCO 2014, respectively, setting new state-of-the-art records. Code is available at https://github.com/PengtaoJiang/L2G.
A Good Image Generator Is What You Need for High-Resolution Video Synthesis
Apr 30, 2021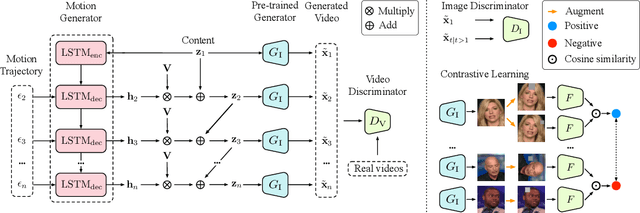



Image and video synthesis are closely related areas aiming at generating content from noise. While rapid progress has been demonstrated in improving image-based models to handle large resolutions, high-quality renderings, and wide variations in image content, achieving comparable video generation results remains problematic. We present a framework that leverages contemporary image generators to render high-resolution videos. We frame the video synthesis problem as discovering a trajectory in the latent space of a pre-trained and fixed image generator. Not only does such a framework render high-resolution videos, but it also is an order of magnitude more computationally efficient. We introduce a motion generator that discovers the desired trajectory, in which content and motion are disentangled. With such a representation, our framework allows for a broad range of applications, including content and motion manipulation. Furthermore, we introduce a new task, which we call cross-domain video synthesis, in which the image and motion generators are trained on disjoint datasets belonging to different domains. This allows for generating moving objects for which the desired video data is not available. Extensive experiments on various datasets demonstrate the advantages of our methods over existing video generation techniques. Code will be released at https://github.com/snap-research/MoCoGAN-HD.
MSR: Making Self-supervised learning Robust to Aggressive Augmentations
Jun 04, 2022

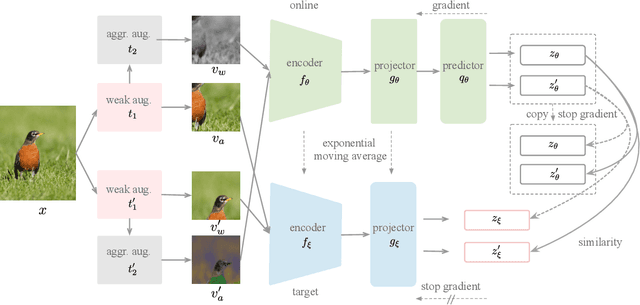

Most recent self-supervised learning methods learn visual representation by contrasting different augmented views of images. Compared with supervised learning, more aggressive augmentations have been introduced to further improve the diversity of training pairs. However, aggressive augmentations may distort images' structures leading to a severe semantic shift problem that augmented views of the same image may not share the same semantics, thus degrading the transfer performance. To address this problem, we propose a new SSL paradigm, which counteracts the impact of semantic shift by balancing the role of weak and aggressively augmented pairs. Specifically, semantically inconsistent pairs are of minority and we treat them as noisy pairs. Note that deep neural networks (DNNs) have a crucial memorization effect that DNNs tend to first memorize clean (majority) examples before overfitting to noisy (minority) examples. Therefore, we set a relatively large weight for aggressively augmented data pairs at the early learning stage. With the training going on, the model begins to overfit noisy pairs. Accordingly, we gradually reduce the weights of aggressively augmented pairs. In doing so, our method can better embrace the aggressive augmentations and neutralize the semantic shift problem. Experiments show that our model achieves 73.1% top-1 accuracy on ImageNet-1K with ResNet-50 for 200 epochs, which is a 2.5% improvement over BYOL. Moreover, experiments also demonstrate that the learned representations can transfer well for various downstream tasks.
Semi-supervised Semantics-guided Adversarial Training for Trajectory Prediction
May 27, 2022

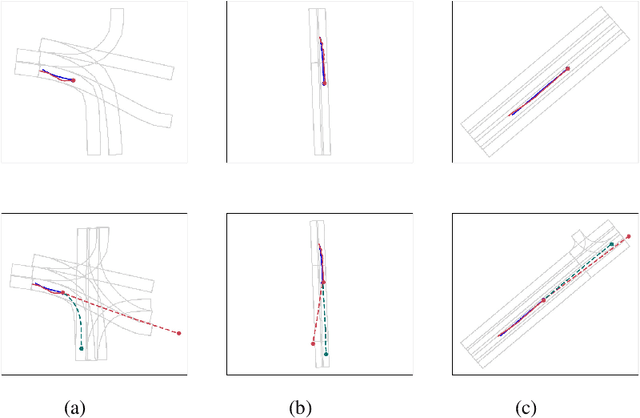
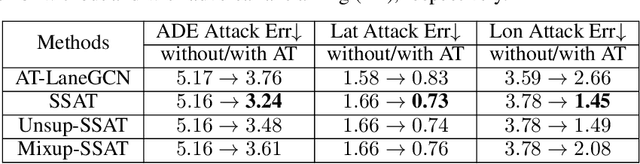
Predicting the trajectories of surrounding objects is a critical task in self-driving and many other autonomous systems. Recent works demonstrate that adversarial attacks on trajectory prediction, where small crafted perturbations are introduced to history trajectories, may significantly mislead the prediction of future trajectories and ultimately induce unsafe planning. However, few works have addressed enhancing the robustness of this important safety-critical task. In this paper, we present the first adversarial training method for trajectory prediction. Compared with typical adversarial training on image tasks, our work is challenged by more random inputs with rich context, and a lack of class labels. To address these challenges, we propose a method based on a semi-supervised adversarial autoencoder that models disentangled semantic features with domain knowledge and provides additional latent labels for the adversarial training. Extensive experiments with different types of attacks demonstrate that our semi-supervised semantics-guided adversarial training method can effectively mitigate the impact of adversarial attacks and generally improve the system's adversarial robustness to a variety of attacks, including unseen ones. We believe that such semantics-guided architecture and advancement in robust generalization is an important step for developing robust prediction models and enabling safe decision making.
Image-based monitoring of bolt loosening through deep-learning-based integrated detection and tracking
Nov 16, 2021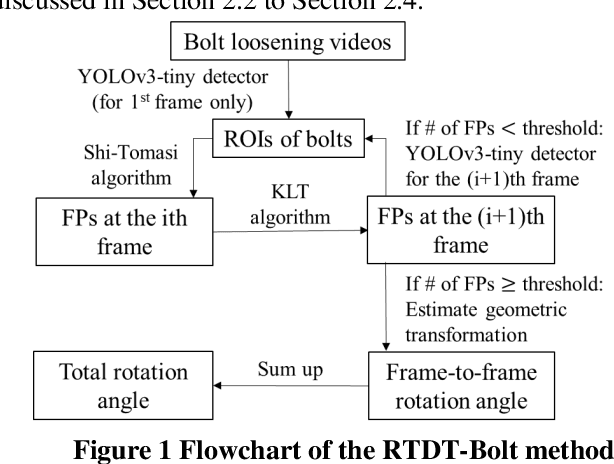
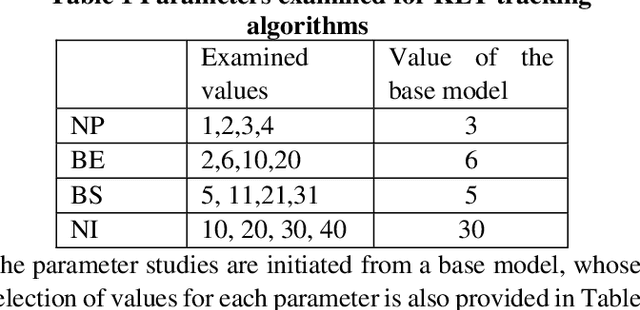

Structural bolts are critical components used in different structural elements, such as beam-column connections and friction damping devices. The clamping force in structural bolts is highly influenced by the bolt rotation. Much of the existing vision-based research about bolt rotation estimation relies on traditional computer vision algorithms such as Hough Transform to assess static images of bolts. This requires careful image preprocessing, and it may not perform well in the situation of complicated bolt assemblies, or in the presence of surrounding objects and background noise, thus hindering their real-world applications. In this study, an integrated real-time detect-track method, namely RTDT-Bolt, is proposed to monitor the bolt rotation angle. First, a real-time convolutional-neural-networks-based object detector, named YOLOv3-tiny, is established and trained to localize structural bolts. Then, the target-free object tracking algorithm based on optical flow is implemented, to continuously monitor and quantify the rotation of structural bolts. In order to enhance the tracking performance against background noise and potential illumination changes during tracking, the YOLOv3-tiny is integrated with the optical flow tracking algorithm to re-detect the bolts when the tracking gets lost. Extensive parameter studies were conducted to identify optimal tracking performance and examine the potential limitations. The results indicate the RTDT-Bolt method can greatly enhance the tracking performance of bolt rotation, which can achieve over 90% accuracy using the recommended range for the parameters.
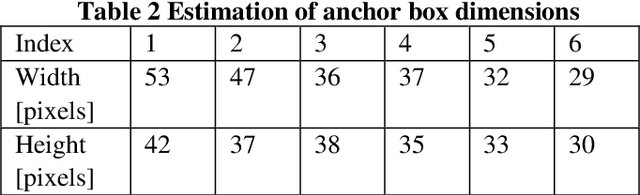
TransClaw U-Net: Claw U-Net with Transformers for Medical Image Segmentation
Jul 12, 2021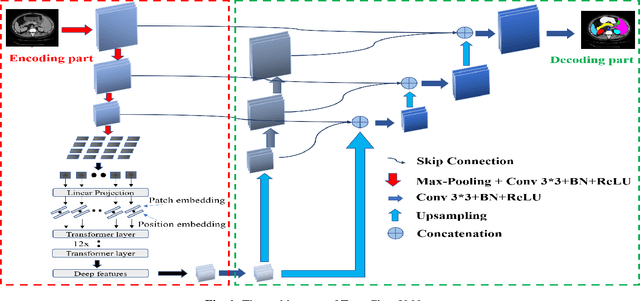
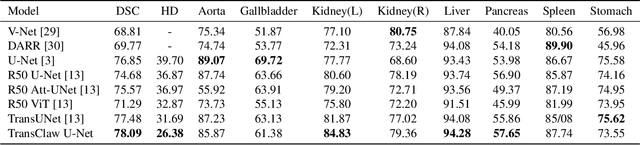
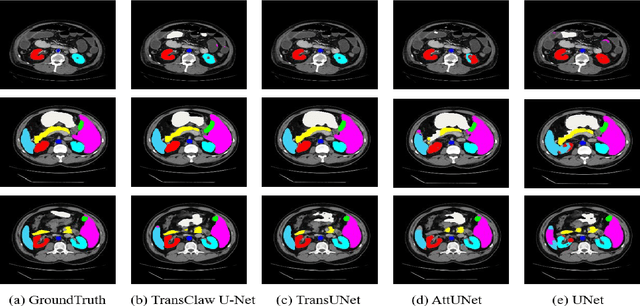

In recent years, computer-aided diagnosis has become an increasingly popular topic. Methods based on convolutional neural networks have achieved good performance in medical image segmentation and classification. Due to the limitations of the convolution operation, the long-term spatial features are often not accurately obtained. Hence, we propose a TransClaw U-Net network structure, which combines the convolution operation with the transformer operation in the encoding part. The convolution part is applied for extracting the shallow spatial features to facilitate the recovery of the image resolution after upsampling. The transformer part is used to encode the patches, and the self-attention mechanism is used to obtain global information between sequences. The decoding part retains the bottom upsampling structure for better detail segmentation performance. The experimental results on Synapse Multi-organ Segmentation Datasets show that the performance of TransClaw U-Net is better than other network structures. The ablation experiments also prove the generalization performance of TransClaw U-Net.
Simple Unsupervised Object-Centric Learning for Complex and Naturalistic Videos
May 27, 2022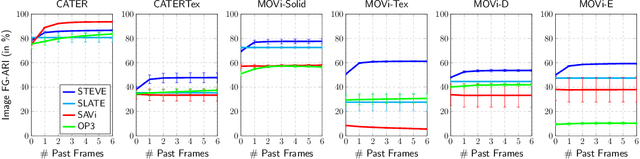
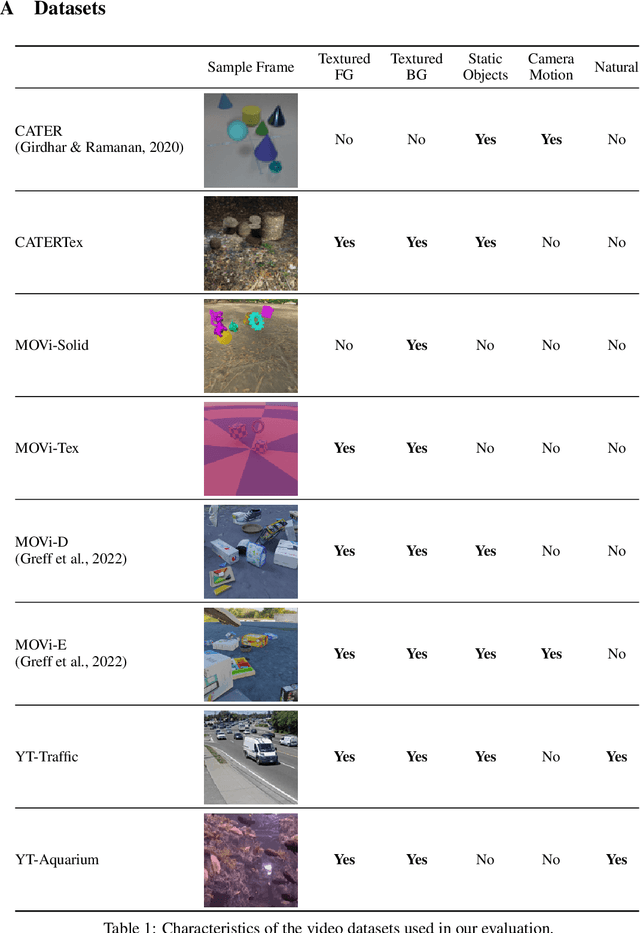
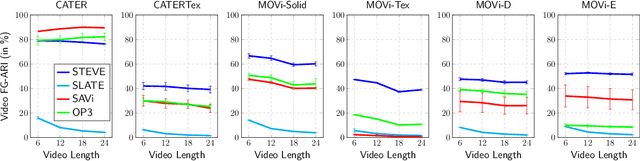
Unsupervised object-centric learning aims to represent the modular, compositional, and causal structure of a scene as a set of object representations and thereby promises to resolve many critical limitations of traditional single-vector representations such as poor systematic generalization. Although there have been many remarkable advances in recent years, one of the most critical problems in this direction has been that previous methods work only with simple and synthetic scenes but not with complex and naturalistic images or videos. In this paper, we propose STEVE, an unsupervised model for object-centric learning in videos. Our proposed model makes a significant advancement by demonstrating its effectiveness on various complex and naturalistic videos unprecedented in this line of research. Interestingly, this is achieved by neither adding complexity to the model architecture nor introducing a new objective or weak supervision. Rather, it is achieved by a surprisingly simple architecture that uses a transformer-based image decoder conditioned on slots and the learning objective is simply to reconstruct the observation. Our experiment results on various complex and naturalistic videos show significant improvements compared to the previous state-of-the-art.
A Benchmark for Compositional Visual Reasoning
Jun 11, 2022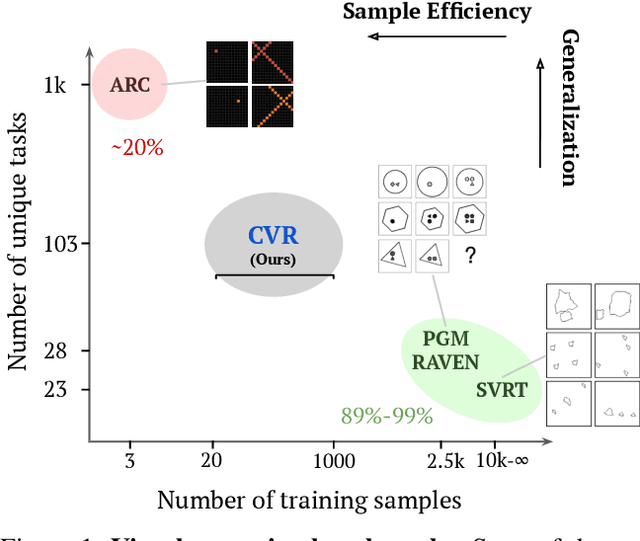
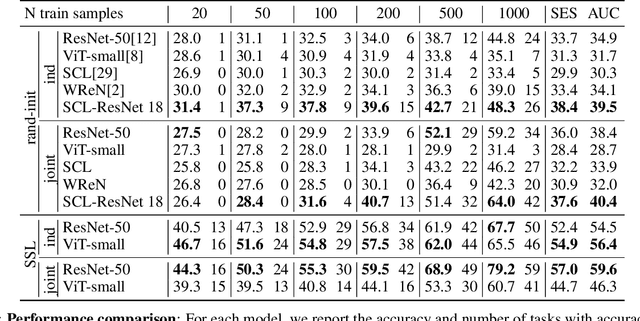
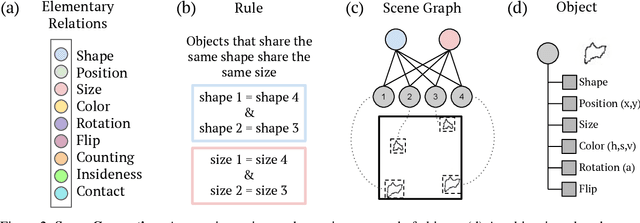
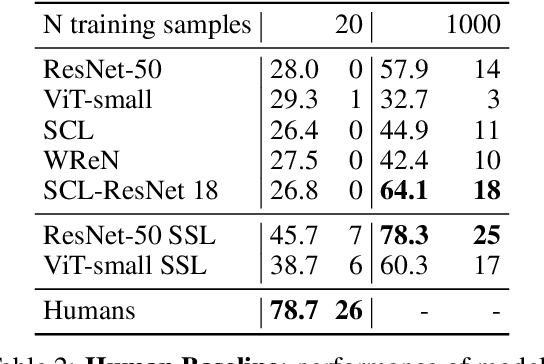
A fundamental component of human vision is our ability to parse complex visual scenes and judge the relations between their constituent objects. AI benchmarks for visual reasoning have driven rapid progress in recent years with state-of-the-art systems now reaching human accuracy on some of these benchmarks. Yet, a major gap remains in terms of the sample efficiency with which humans and AI systems learn new visual reasoning tasks. Humans' remarkable efficiency at learning has been at least partially attributed to their ability to harness compositionality -- such that they can efficiently take advantage of previously gained knowledge when learning new tasks. Here, we introduce a novel visual reasoning benchmark, Compositional Visual Relations (CVR), to drive progress towards the development of more data-efficient learning algorithms. We take inspiration from fluidic intelligence and non-verbal reasoning tests and describe a novel method for creating compositions of abstract rules and associated image datasets at scale. Our proposed benchmark includes measures of sample efficiency, generalization and transfer across task rules, as well as the ability to leverage compositionality. We systematically evaluate modern neural architectures and find that, surprisingly, convolutional architectures surpass transformer-based architectures across all performance measures in most data regimes. However, all computational models are a lot less data efficient compared to humans even after learning informative visual representations using self-supervision. Overall, we hope that our challenge will spur interest in the development of neural architectures that can learn to harness compositionality toward more efficient learning.
Validation of image systems simulation technology using a Cornell Box
May 10, 2021
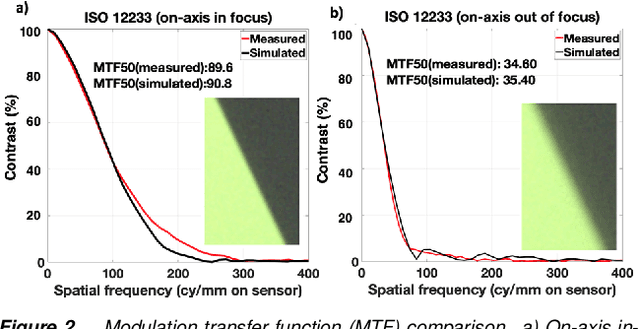
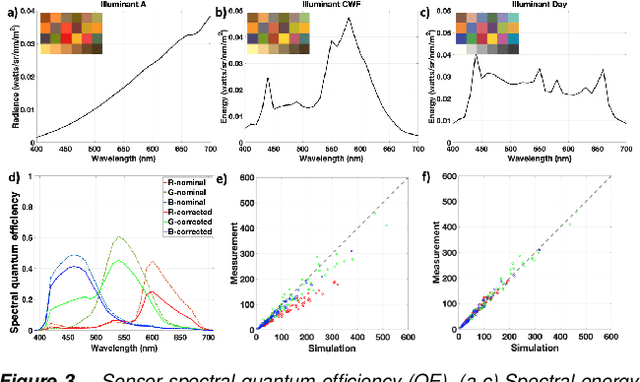

We describe and experimentally validate an end-to-end simulation of a digital camera. The simulation models the spectral radiance of 3D-scenes, formation of the spectral irradiance by multi-element optics, and conversion of the irradiance to digital values by the image sensor. We quantify the accuracy of the simulation by comparing real and simulated images of a precisely constructed, three-dimensional high dynamic range test scene. Validated end-to-end software simulation of a digital camera can accelerate innovation by reducing many of the time-consuming and expensive steps in designing, building and evaluating image systems.
Global Filter Networks for Image Classification
Jul 01, 2021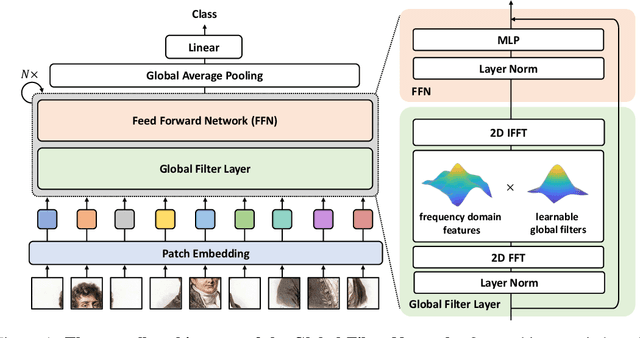

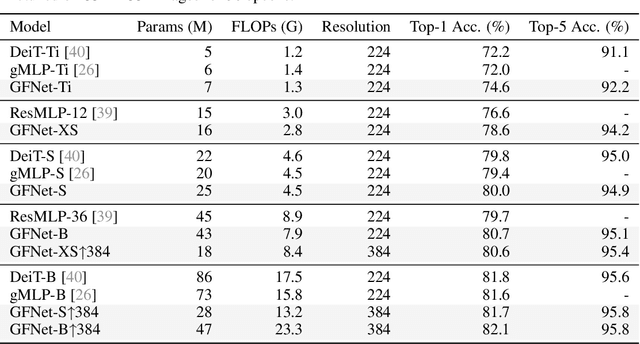
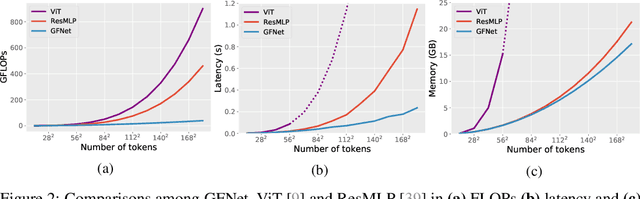
Recent advances in self-attention and pure multi-layer perceptrons (MLP) models for vision have shown great potential in achieving promising performance with fewer inductive biases. These models are generally based on learning interaction among spatial locations from raw data. The complexity of self-attention and MLP grows quadratically as the image size increases, which makes these models hard to scale up when high-resolution features are required. In this paper, we present the Global Filter Network (GFNet), a conceptually simple yet computationally efficient architecture, that learns long-term spatial dependencies in the frequency domain with log-linear complexity. Our architecture replaces the self-attention layer in vision transformers with three key operations: a 2D discrete Fourier transform, an element-wise multiplication between frequency-domain features and learnable global filters, and a 2D inverse Fourier transform. We exhibit favorable accuracy/complexity trade-offs of our models on both ImageNet and downstream tasks. Our results demonstrate that GFNet can be a very competitive alternative to transformer-style models and CNNs in efficiency, generalization ability and robustness. Code is available at https://github.com/raoyongming/GFNet