 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Zero-shot cross-modal transfer of Reinforcement Learning policies through a Global Workspace
Mar 07, 2024
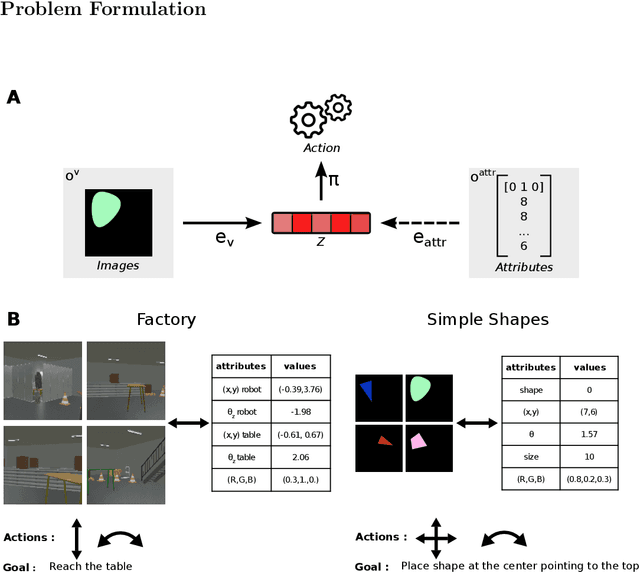

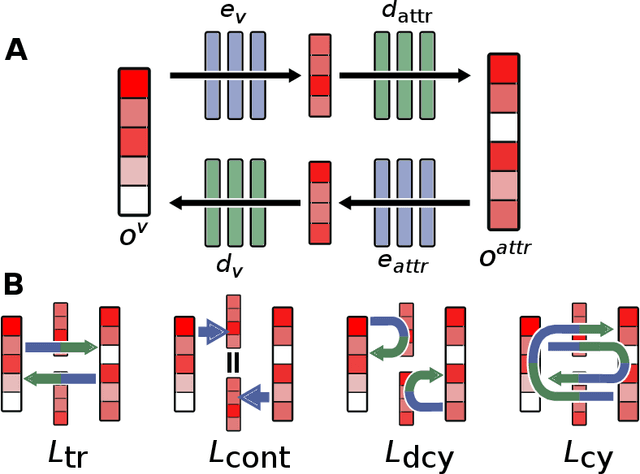

Humans perceive the world through multiple senses, enabling them to create a comprehensive representation of their surroundings and to generalize information across domains. For instance, when a textual description of a scene is given, humans can mentally visualize it. In fields like robotics and Reinforcement Learning (RL), agents can also access information about the environment through multiple sensors; yet redundancy and complementarity between sensors is difficult to exploit as a source of robustness (e.g. against sensor failure) or generalization (e.g. transfer across domains). Prior research demonstrated that a robust and flexible multimodal representation can be efficiently constructed based on the cognitive science notion of a 'Global Workspace': a unique representation trained to combine information across modalities, and to broadcast its signal back to each modality. Here, we explore whether such a brain-inspired multimodal representation could be advantageous for RL agents. First, we train a 'Global Workspace' to exploit information collected about the environment via two input modalities (a visual input, or an attribute vector representing the state of the agent and/or its environment). Then, we train a RL agent policy using this frozen Global Workspace. In two distinct environments and tasks, our results reveal the model's ability to perform zero-shot cross-modal transfer between input modalities, i.e. to apply to image inputs a policy previously trained on attribute vectors (and vice-versa), without additional training or fine-tuning. Variants and ablations of the full Global Workspace (including a CLIP-like multimodal representation trained via contrastive learning) did not display the same generalization abilities.
A challenge in A(G)I, cybernetics revived in the Ouroboros Model as one algorithm for all thinking
Mar 07, 2024
A topical challenge for algorithms in general and for automatic image categorization and generation in particular is presented in the form of a drawing for AI to understand. In a second vein, AI is challenged to produce something similar from verbal description. The aim of the paper is to highlight strengths and deficiencies of current Artificial Intelligence approaches while coarsely sketching a way forward. A general lack of encompassing symbol-embedding and (not only) -grounding in some bodily basis is made responsible for current deficiencies. A concomitant dearth of hierarchical organization of concepts follows suite. As a remedy for these shortcomings, it is proposed to take a wide step back and to newly incorporate aspects of cybernetics and analog control processes. It is claimed that a promising overarching perspective is provided by the Ouroboros Model with a valid and versatile algorithmic backbone for general cognition at all accessible levels of abstraction and capabilities. Reality, rules, truth, and Free Will are all useful abstractions according to the Ouroboros Model. Logic deduction as well as intuitive guesses are claimed as produced on the basis of one compartmentalized memory for schemata and a pattern-matching, i.e., monitoring process termed consumption analysis. The latter directs attention on short (attention proper) and also on long times scales (emotional biases). In this cybernetic approach, discrepancies between expectations and actual activations (e.g., sensory precepts) drive the general process of cognition and at the same time steer the storage of new and adapted memory entries. Dedicated structures in the human brain work in concert according to this scheme.
* 26 pages, 11 figures
Bespoke Non-Stationary Solvers for Fast Sampling of Diffusion and Flow Models
Mar 02, 2024
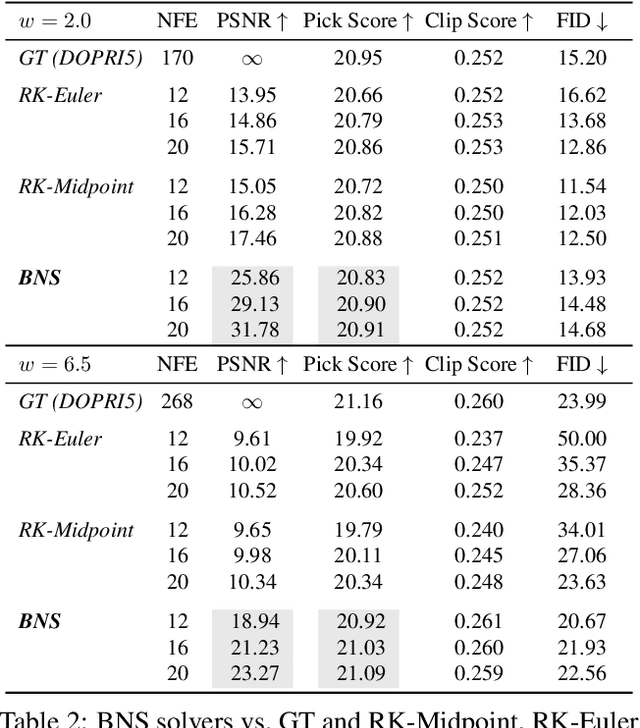
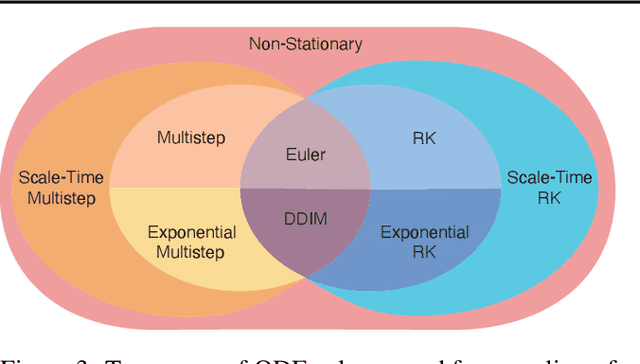
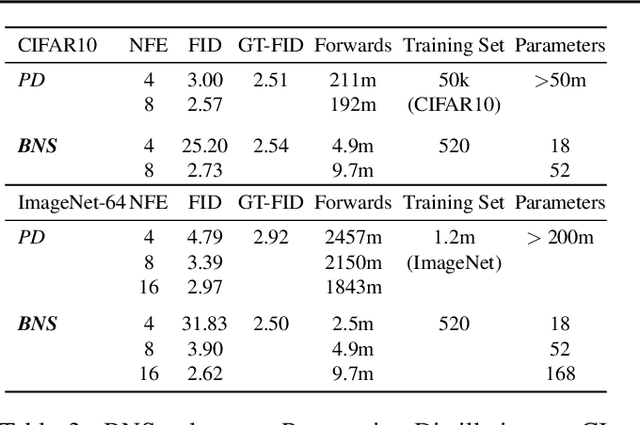
This paper introduces Bespoke Non-Stationary (BNS) Solvers, a solver distillation approach to improve sample efficiency of Diffusion and Flow models. BNS solvers are based on a family of non-stationary solvers that provably subsumes existing numerical ODE solvers and consequently demonstrate considerable improvement in sample approximation (PSNR) over these baselines. Compared to model distillation, BNS solvers benefit from a tiny parameter space ($<$200 parameters), fast optimization (two orders of magnitude faster), maintain diversity of samples, and in contrast to previous solver distillation approaches nearly close the gap from standard distillation methods such as Progressive Distillation in the low-medium NFE regime. For example, BNS solver achieves 45 PSNR / 1.76 FID using 16 NFE in class-conditional ImageNet-64. We experimented with BNS solvers for conditional image generation, text-to-image generation, and text-2-audio generation showing significant improvement in sample approximation (PSNR) in all.
Auxiliary Tasks Enhanced Dual-affinity Learning for Weakly Supervised Semantic Segmentation
Mar 02, 2024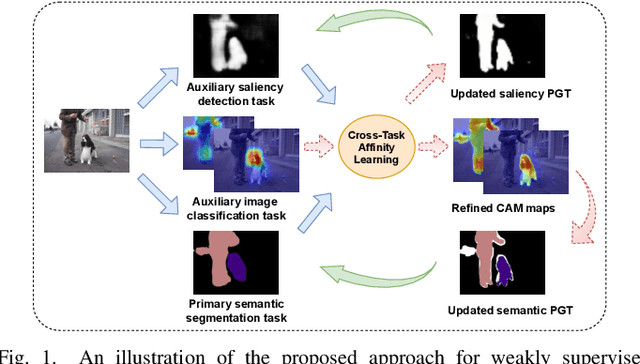
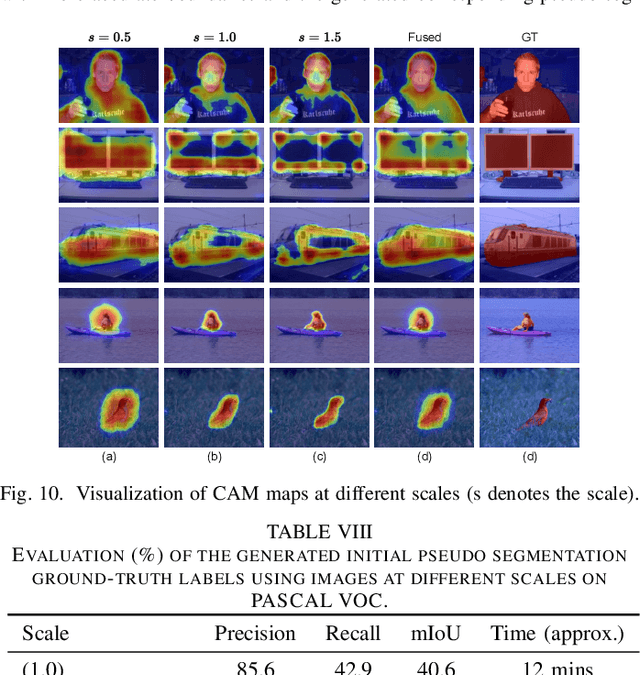

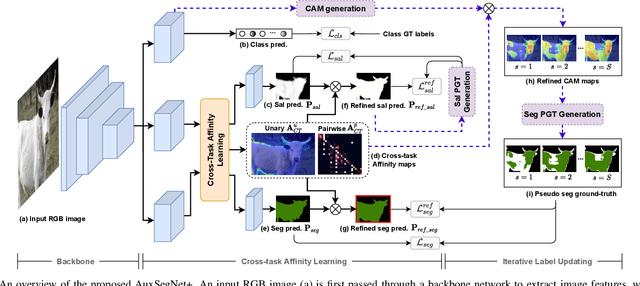
Most existing weakly supervised semantic segmentation (WSSS) methods rely on Class Activation Mapping (CAM) to extract coarse class-specific localization maps using image-level labels. Prior works have commonly used an off-line heuristic thresholding process that combines the CAM maps with off-the-shelf saliency maps produced by a general pre-trained saliency model to produce more accurate pseudo-segmentation labels. We propose AuxSegNet+, a weakly supervised auxiliary learning framework to explore the rich information from these saliency maps and the significant inter-task correlation between saliency detection and semantic segmentation. In the proposed AuxSegNet+, saliency detection and multi-label image classification are used as auxiliary tasks to improve the primary task of semantic segmentation with only image-level ground-truth labels. We also propose a cross-task affinity learning mechanism to learn pixel-level affinities from the saliency and segmentation feature maps. In particular, we propose a cross-task dual-affinity learning module to learn both pairwise and unary affinities, which are used to enhance the task-specific features and predictions by aggregating both query-dependent and query-independent global context for both saliency detection and semantic segmentation. The learned cross-task pairwise affinity can also be used to refine and propagate CAM maps to provide better pseudo labels for both tasks. Iterative improvement of segmentation performance is enabled by cross-task affinity learning and pseudo-label updating. Extensive experiments demonstrate the effectiveness of the proposed approach with new state-of-the-art WSSS results on the challenging PASCAL VOC and MS COCO benchmarks.
Few-Shot Relation Extraction with Hybrid Visual Evidence
Mar 01, 2024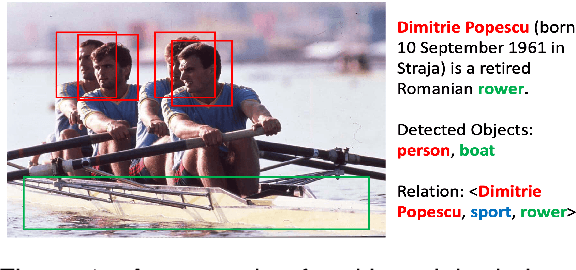

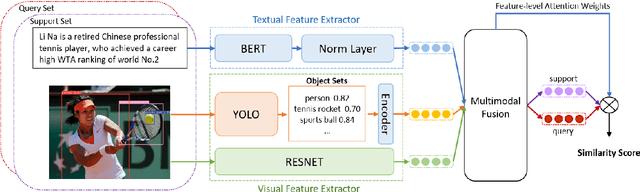

The goal of few-shot relation extraction is to predict relations between name entities in a sentence when only a few labeled instances are available for training. Existing few-shot relation extraction methods focus on uni-modal information such as text only. This reduces performance when there are no clear contexts between the name entities described in text. We propose a multi-modal few-shot relation extraction model (MFS-HVE) that leverages both textual and visual semantic information to learn a multi-modal representation jointly. The MFS-HVE includes semantic feature extractors and multi-modal fusion components. The MFS-HVE semantic feature extractors are developed to extract both textual and visual features. The visual features include global image features and local object features within the image. The MFS-HVE multi-modal fusion unit integrates information from various modalities using image-guided attention, object-guided attention, and hybrid feature attention to fully capture the semantic interaction between visual regions of images and relevant texts. Extensive experiments conducted on two public datasets demonstrate that semantic visual information significantly improves the performance of few-shot relation prediction.
* 16 pages, 5 figures
AIO2: Online Correction of Object Labels for Deep Learning with Incomplete Annotation in Remote Sensing Image Segmentation
Mar 03, 2024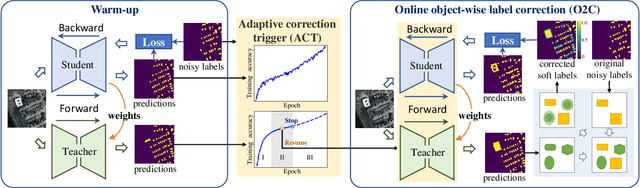
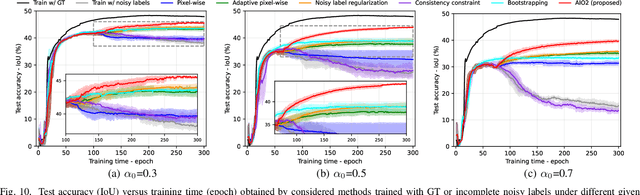

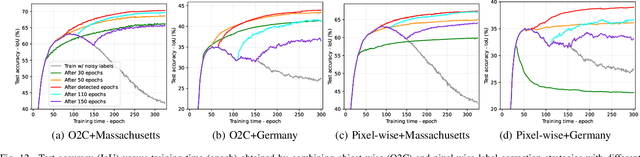
While the volume of remote sensing data is increasing daily, deep learning in Earth Observation faces lack of accurate annotations for supervised optimization. Crowdsourcing projects such as OpenStreetMap distribute the annotation load to their community. However, such annotation inevitably generates noise due to insufficient control of the label quality, lack of annotators, frequent changes of the Earth's surface as a result of natural disasters and urban development, among many other factors. We present Adaptively trIggered Online Object-wise correction (AIO2) to address annotation noise induced by incomplete label sets. AIO2 features an Adaptive Correction Trigger (ACT) module that avoids label correction when the model training under- or overfits, and an Online Object-wise Correction (O2C) methodology that employs spatial information for automated label modification. AIO2 utilizes a mean teacher model to enhance training robustness with noisy labels to both stabilize the training accuracy curve for fitting in ACT and provide pseudo labels for correction in O2C. Moreover, O2C is implemented online without the need to store updated labels every training epoch. We validate our approach on two building footprint segmentation datasets with different spatial resolutions. Experimental results with varying degrees of building label noise demonstrate the robustness of AIO2. Source code will be available at https://github.com/zhu-xlab/AIO2.git.
Transformer for Times Series: an Application to the S&P500
Mar 04, 2024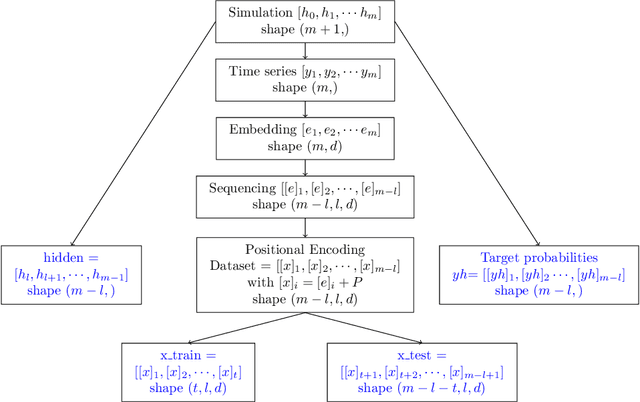

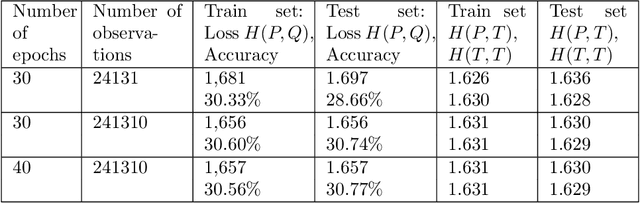
The transformer models have been extensively used with good results in a wide area of machine learning applications including Large Language Models and image generation. Here, we inquire on the applicability of this approach to financial time series. We first describe the dataset construction for two prototypical situations: a mean reverting synthetic Ornstein-Uhlenbeck process on one hand and real S&P500 data on the other hand. Then, we present in detail the proposed Transformer architecture and finally we discuss some encouraging results. For the synthetic data we predict rather accurately the next move, and for the S&P500 we get some interesting results related to quadratic variation and volatility prediction.
Face Swap via Diffusion Model
Mar 02, 2024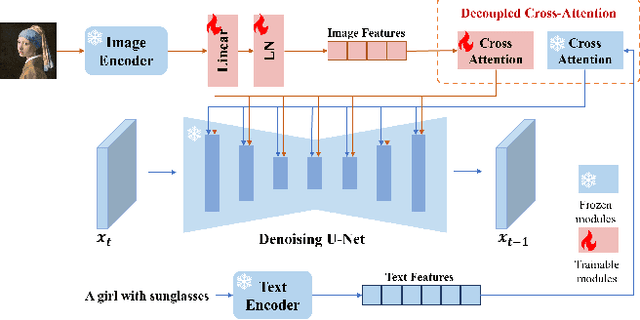
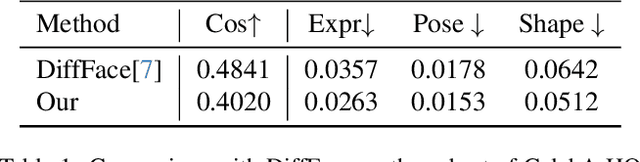


This technical report presents a diffusion model based framework for face swapping between two portrait images. The basic framework consists of three components, i.e., IP-Adapter, ControlNet, and Stable Diffusion's inpainting pipeline, for face feature encoding, multi-conditional generation, and face inpainting respectively. Besides, I introduce facial guidance optimization and CodeFormer based blending to further improve the generation quality. Specifically, we engage a recent light-weighted customization method (i.e., DreamBooth-LoRA), to guarantee the identity consistency by 1) using a rare identifier "sks" to represent the source identity, and 2) injecting the image features of source portrait into each cross-attention layer like the text features. Then I resort to the strong inpainting ability of Stable Diffusion, and utilize canny image and face detection annotation of the target portrait as the conditions, to guide ContorlNet's generation and align source portrait with the target portrait. To further correct face alignment, we add the facial guidance loss to optimize the text embedding during the sample generation.
HDRFlow: Real-Time HDR Video Reconstruction with Large Motions
Mar 06, 2024
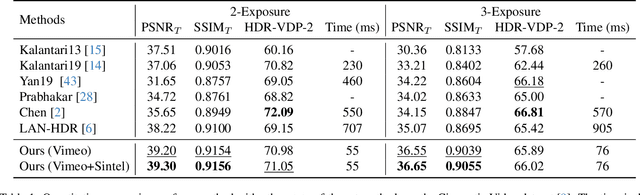

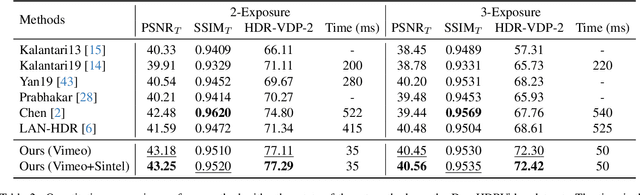
Reconstructing High Dynamic Range (HDR) video from image sequences captured with alternating exposures is challenging, especially in the presence of large camera or object motion. Existing methods typically align low dynamic range sequences using optical flow or attention mechanism for deghosting. However, they often struggle to handle large complex motions and are computationally expensive. To address these challenges, we propose a robust and efficient flow estimator tailored for real-time HDR video reconstruction, named HDRFlow. HDRFlow has three novel designs: an HDR-domain alignment loss (HALoss), an efficient flow network with a multi-size large kernel (MLK), and a new HDR flow training scheme. The HALoss supervises our flow network to learn an HDR-oriented flow for accurate alignment in saturated and dark regions. The MLK can effectively model large motions at a negligible cost. In addition, we incorporate synthetic data, Sintel, into our training dataset, utilizing both its provided forward flow and backward flow generated by us to supervise our flow network, enhancing our performance in large motion regions. Extensive experiments demonstrate that our HDRFlow outperforms previous methods on standard benchmarks. To the best of our knowledge, HDRFlow is the first real-time HDR video reconstruction method for video sequences captured with alternating exposures, capable of processing 720p resolution inputs at 25ms.
Towards Controllable Time Series Generation
Mar 06, 2024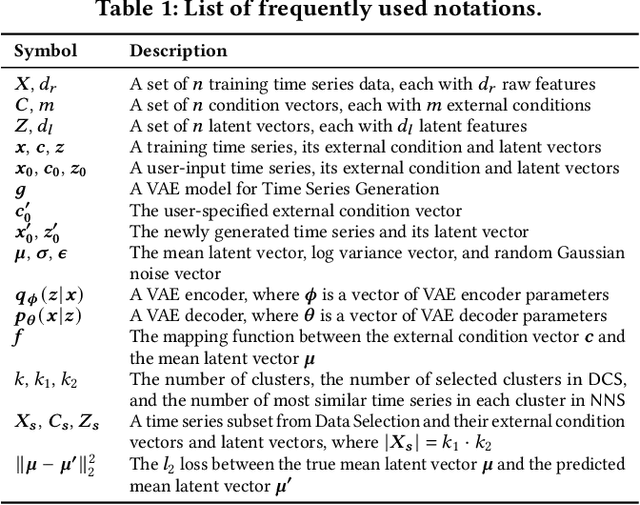
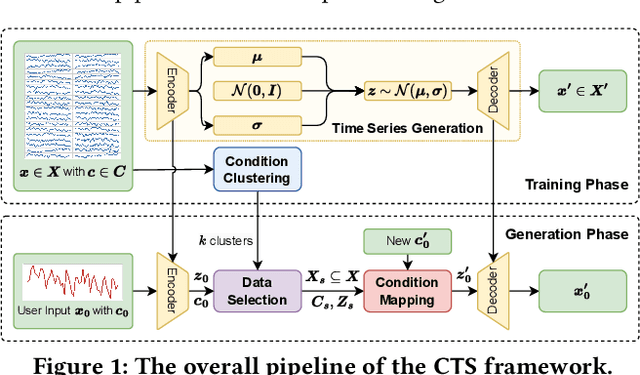
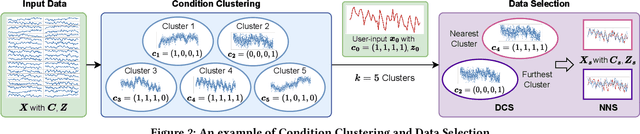
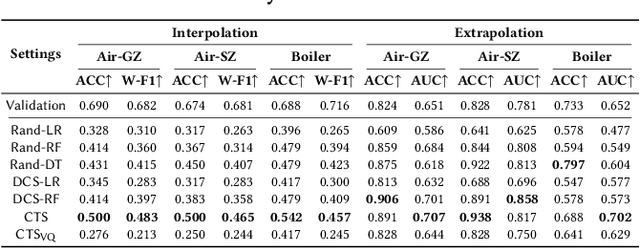
Time Series Generation (TSG) has emerged as a pivotal technique in synthesizing data that accurately mirrors real-world time series, becoming indispensable in numerous applications. Despite significant advancements in TSG, its efficacy frequently hinges on having large training datasets. This dependency presents a substantial challenge in data-scarce scenarios, especially when dealing with rare or unique conditions. To confront these challenges, we explore a new problem of Controllable Time Series Generation (CTSG), aiming to produce synthetic time series that can adapt to various external conditions, thereby tackling the data scarcity issue. In this paper, we propose \textbf{C}ontrollable \textbf{T}ime \textbf{S}eries (\textsf{CTS}), an innovative VAE-agnostic framework tailored for CTSG. A key feature of \textsf{CTS} is that it decouples the mapping process from standard VAE training, enabling precise learning of a complex interplay between latent features and external conditions. Moreover, we develop a comprehensive evaluation scheme for CTSG. Extensive experiments across three real-world time series datasets showcase \textsf{CTS}'s exceptional capabilities in generating high-quality, controllable outputs. This underscores its adeptness in seamlessly integrating latent features with external conditions. Extending \textsf{CTS} to the image domain highlights its remarkable potential for explainability and further reinforces its versatility across different modalities.