 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Defending Against Image Corruptions Through Adversarial Augmentations
Apr 02, 2021

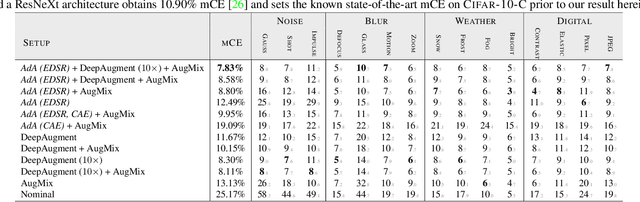
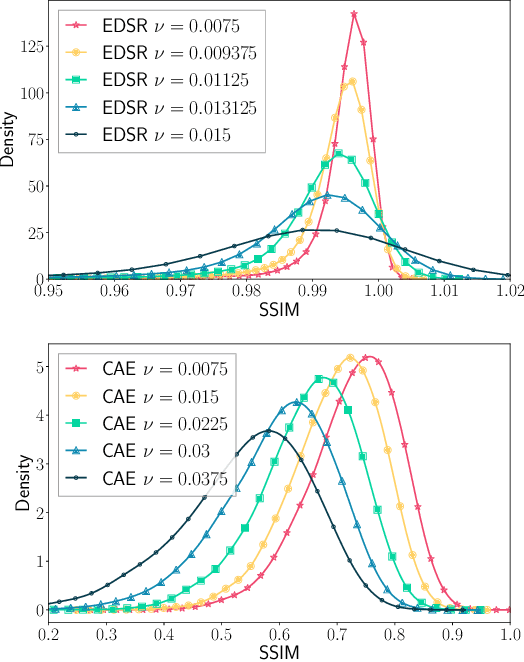
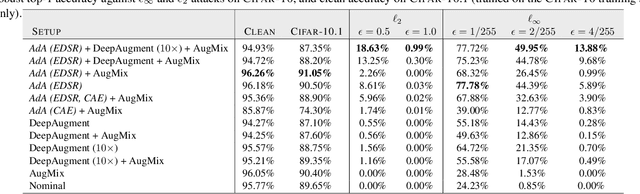
Modern neural networks excel at image classification, yet they remain vulnerable to common image corruptions such as blur, speckle noise or fog. Recent methods that focus on this problem, such as AugMix and DeepAugment, introduce defenses that operate in expectation over a distribution of image corruptions. In contrast, the literature on $\ell_p$-norm bounded perturbations focuses on defenses against worst-case corruptions. In this work, we reconcile both approaches by proposing AdversarialAugment, a technique which optimizes the parameters of image-to-image models to generate adversarially corrupted augmented images. We theoretically motivate our method and give sufficient conditions for the consistency of its idealized version as well as that of DeepAugment. Our classifiers improve upon the state-of-the-art on common image corruption benchmarks conducted in expectation on CIFAR-10-C and improve worst-case performance against $\ell_p$-norm bounded perturbations on both CIFAR-10 and ImageNet.
A Trainable Spectral-Spatial Sparse Coding Model for Hyperspectral Image Restoration
Nov 18, 2021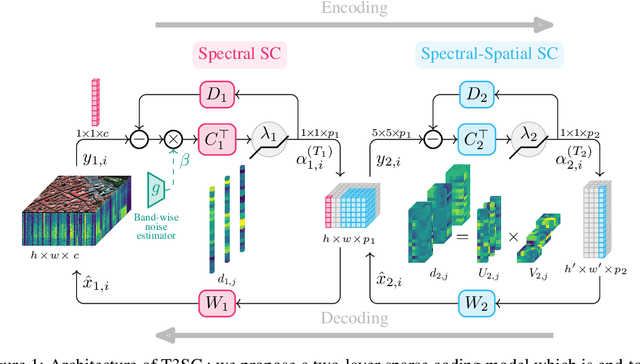

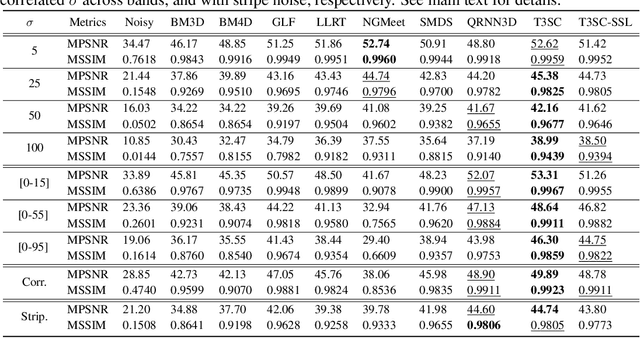

Hyperspectral imaging offers new perspectives for diverse applications, ranging from the monitoring of the environment using airborne or satellite remote sensing, precision farming, food safety, planetary exploration, or astrophysics. Unfortunately, the spectral diversity of information comes at the expense of various sources of degradation, and the lack of accurate ground-truth "clean" hyperspectral signals acquired on the spot makes restoration tasks challenging. In particular, training deep neural networks for restoration is difficult, in contrast to traditional RGB imaging problems where deep models tend to shine. In this paper, we advocate instead for a hybrid approach based on sparse coding principles that retains the interpretability of classical techniques encoding domain knowledge with handcrafted image priors, while allowing to train model parameters end-to-end without massive amounts of data. We show on various denoising benchmarks that our method is computationally efficient and significantly outperforms the state of the art.
Expanding the Latent Space of StyleGAN for Real Face Editing
Apr 26, 2022
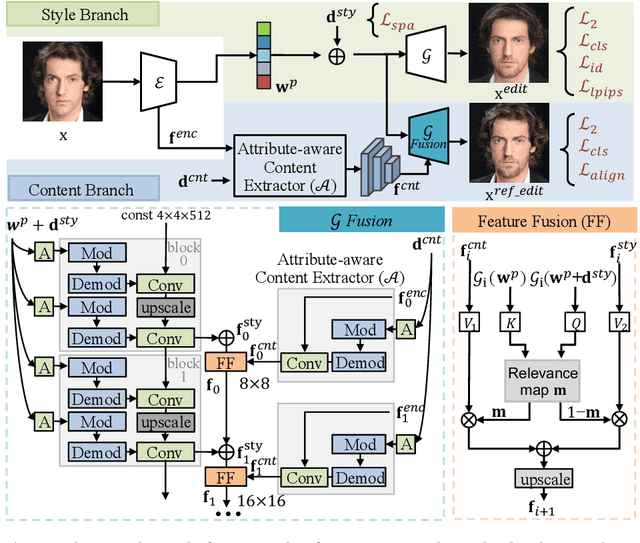

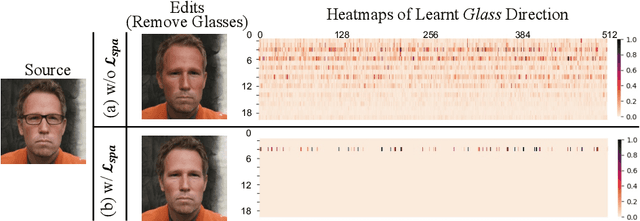
Recently, a surge of face editing techniques have been proposed to employ the pretrained StyleGAN for semantic manipulation. To successfully edit a real image, one must first convert the input image into StyleGAN's latent variables. However, it is still challenging to find latent variables, which have the capacity for preserving the appearance of the input subject (e.g., identity, lighting, hairstyles) as well as enabling meaningful manipulations. In this paper, we present a method to expand the latent space of StyleGAN with additional content features to break down the trade-off between low-distortion and high-editability. Specifically, we proposed a two-branch model, where the style branch first tackles the entanglement issue by the sparse manipulation of latent codes, and the content branch then mitigates the distortion issue by leveraging the content and appearance details from the input image. We confirm the effectiveness of our method using extensive qualitative and quantitative experiments on real face editing and reconstruction tasks.
Unpaired Image-to-Image Translation via Latent Energy Transport
Dec 01, 2020
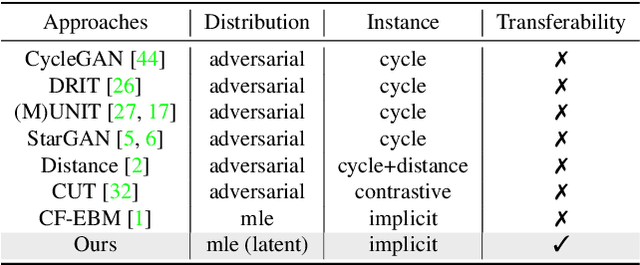
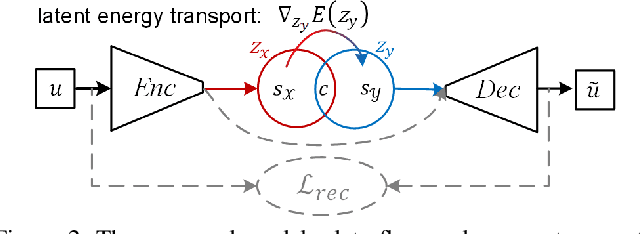

Image-to-image translation aims to preserve source contents while translating to discriminative target styles between two visual domains. Most works apply adversarial learning in the ambient image space, which could be computationally expensive and challenging to train. In this paper, we propose to deploy an energy-based model (EBM) in the latent space of a pretrained autoencoder for this task. The pretrained autoencoder serves as both a latent code extractor and an image reconstruction worker. Our model is based on the assumption that two domains share the same latent space, where latent representation is implicitly decomposed as a content code and a domain-specific style code. Instead of explicitly extracting the two codes and applying adaptive instance normalization to combine them, our latent EBM can implicitly learn to transport the source style code to the target style code while preserving the content code, which is an advantage over existing image translation methods. This simplified solution also brings us far more efficiency in the one-sided unpaired image translation setting. Qualitative and quantitative comparisons demonstrate superior translation quality and faithfulness for content preservation. To the best of our knowledge, our model is the first to be applicable to 1024$\times$1024-resolution unpaired image translation.
ItemSage: Learning Product Embeddings for Shopping Recommendations at Pinterest
May 24, 2022

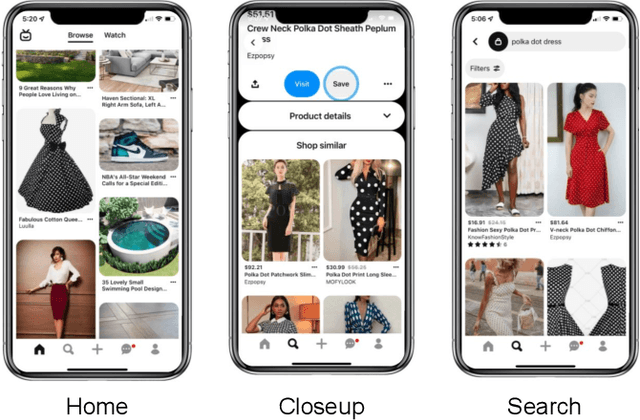
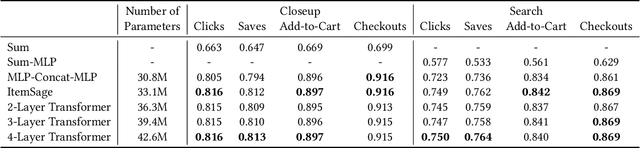
Learned embeddings for products are an important building block for web-scale e-commerce recommendation systems. At Pinterest, we build a single set of product embeddings called ItemSage to provide relevant recommendations in all shopping use cases including user, image and search based recommendations. This approach has led to significant improvements in engagement and conversion metrics, while reducing both infrastructure and maintenance cost. While most prior work focuses on building product embeddings from features coming from a single modality, we introduce a transformer-based architecture capable of aggregating information from both text and image modalities and show that it significantly outperforms single modality baselines. We also utilize multi-task learning to make ItemSage optimized for several engagement types, leading to a candidate generation system that is efficient for all of the engagement objectives of the end-to-end recommendation system. Extensive offline experiments are conducted to illustrate the effectiveness of our approach and results from online A/B experiments show substantial gains in key business metrics (up to +7% gross merchandise value/user and +11% click volume).
* 9 pages, 5 figures
Learning Sparse Masks for Diffusion-based Image Inpainting
Oct 06, 2021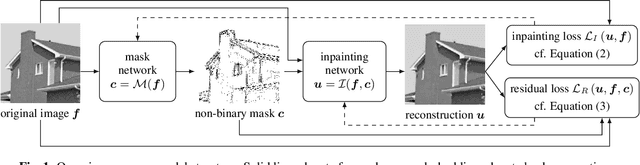


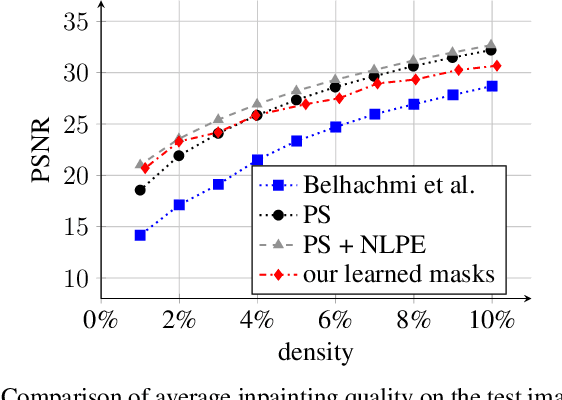
Diffusion-based inpainting is a powerful tool for the reconstruction of images from sparse data. Its quality strongly depends on the choice of known data. Optimising their spatial location -- the inpainting mask -- is challenging. A commonly used tool for this task are stochastic optimisation strategies. However, they are slow as they compute multiple inpainting results. We provide a remedy in terms of a learned mask generation model. By emulating the complete inpainting pipeline with two networks for mask generation and neural surrogate inpainting, we obtain a model for highly efficient adaptive mask generation. Experiments indicate that our model can achieve competitive quality with an acceleration by as much as four orders of magnitude. Our findings serve as a basis for making diffusion-based inpainting more attractive for various applications such as image compression, where fast encoding is highly desirable.
High Resolution Solar Image Generation using Generative Adversarial Networks
Jun 07, 2021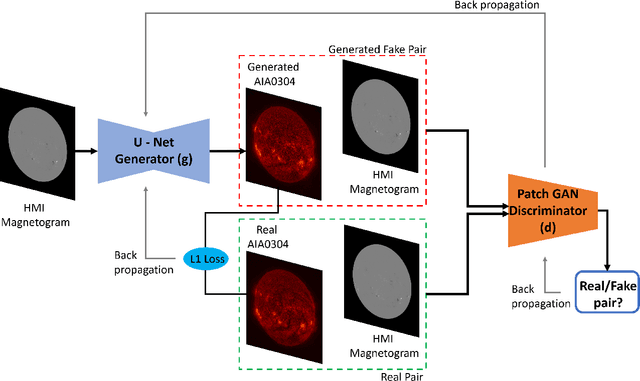
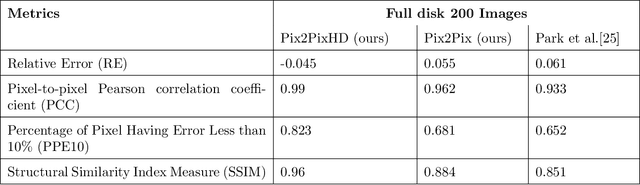
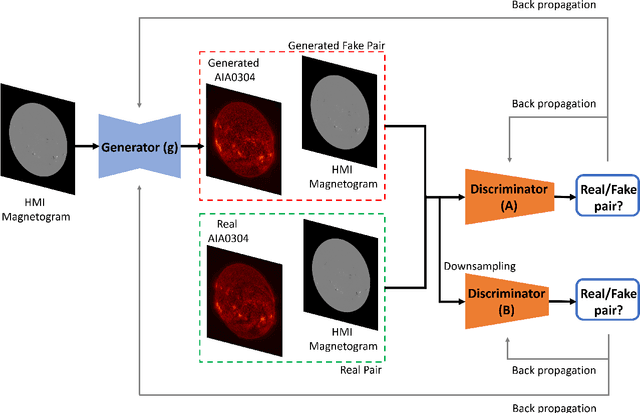

We applied Deep Learning algorithm known as Generative Adversarial Networks (GANs) to perform solar image-to-image translation. That is, from Solar Dynamics Observatory (SDO)/Helioseismic and Magnetic Imager(HMI) line of sight magnetogram images to SDO/Atmospheric Imaging Assembly(AIA) 0304-{\AA} images. The Ultraviolet(UV)/Extreme Ultraviolet(EUV) observations like the SDO/AIA0304-{\AA} images were only made available to scientists in the late 1990s even though the magenetic field observations like the SDO/HMI have been available since the 1970s. Therefore by leveraging Deep Learning algorithms like GANs we can give scientists access to complete datasets for analysis. For generating high resolution solar images we use the Pix2PixHD and Pix2Pix algorithms. The Pix2PixHD algorithm was specifically designed for high resolution image generation tasks, and the Pix2Pix algorithm is by far the most widely used image to image translation algorithm. For training and testing we used the data for the year 2012, 2013 and 2014. The results show that our deep learning models are capable of generating high resolution(1024 x 1024 pixels) AIA0304 images from HMI magnetograms. Specifically, the pixel-to-pixel Pearson Correlation Coefficient of the images generated by Pix2PixHD and original images is as high as 0.99. The number is 0.962 if Pix2Pix is used to generate images. The results we get for our Pix2PixHD model is better than the results obtained by previous works done by others to generate AIA0304 images. Thus, we can use these models to generate AIA0304 images when the AIA0304 data is not available which can be used for understanding space weather and giving researchers the capability to predict solar events such as Solar Flares and Coronal Mass Ejections. As far as we know, our work is the first attempt to leverage Pix2PixHD algorithm for SDO/HMI to SDO/AIA0304 image-to-image translation.
Underwater Image Restoration via Contrastive Learning and a Real-world Dataset
Jun 20, 2021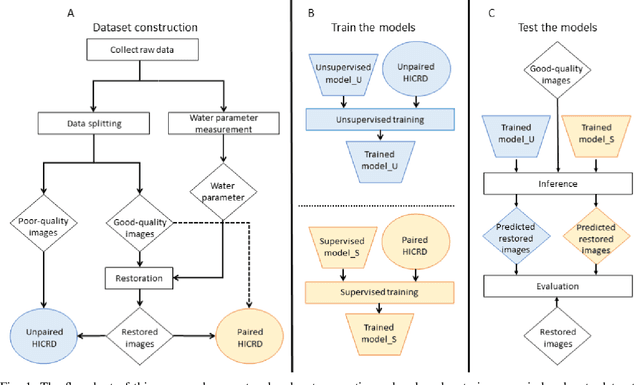
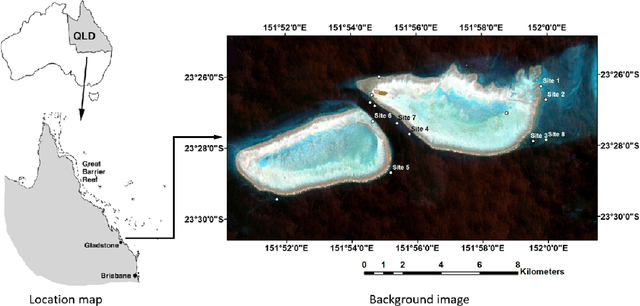
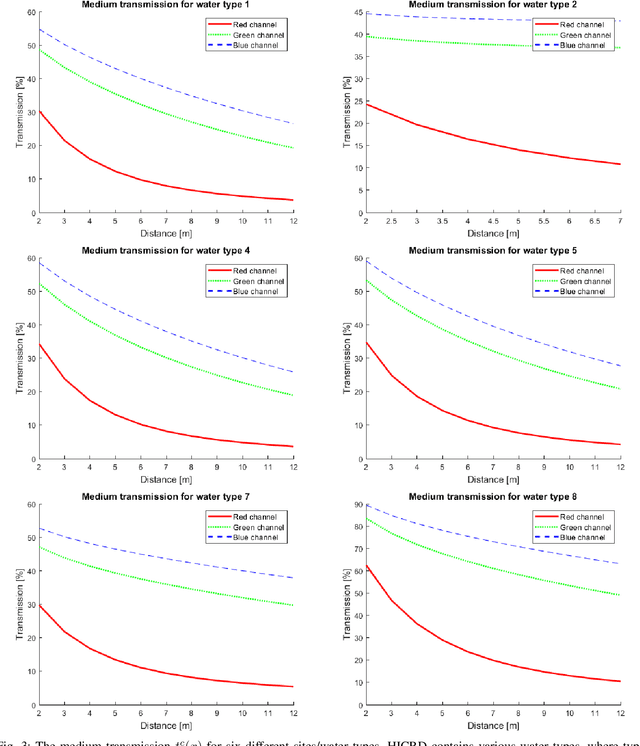
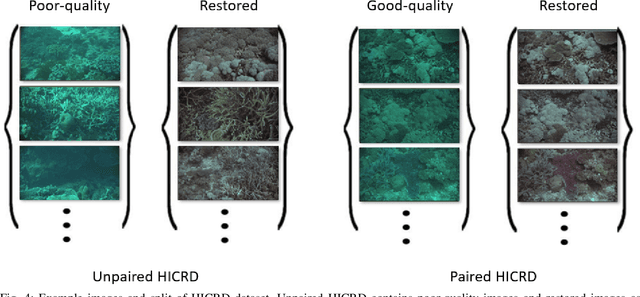
Underwater image restoration is of significant importance in unveiling the underwater world. Numerous techniques and algorithms have been developed in the past decades. However, due to fundamental difficulties associated with imaging/sensing, lighting, and refractive geometric distortions, in capturing clear underwater images, no comprehensive evaluations have been conducted of underwater image restoration. To address this gap, we have constructed a large-scale real underwater image dataset, dubbed `HICRD' (Heron Island Coral Reef Dataset), for the purpose of benchmarking existing methods and supporting the development of new deep-learning based methods. We employ accurate water parameter (diffuse attenuation coefficient) in generating reference images. There are 2000 reference restored images and 6003 original underwater images in the unpaired training set. Further, we present a novel method for underwater image restoration based on unsupervised image-to-image translation framework. Our proposed method leveraged contrastive learning and generative adversarial networks to maximize the mutual information between raw and restored images. Extensive experiments with comparisons to recent approaches further demonstrate the superiority of our proposed method. Our code and dataset are publicly available at GitHub.
A machine learning based approach to gravitational lens identification with the International LOFAR Telescope
Jul 21, 2022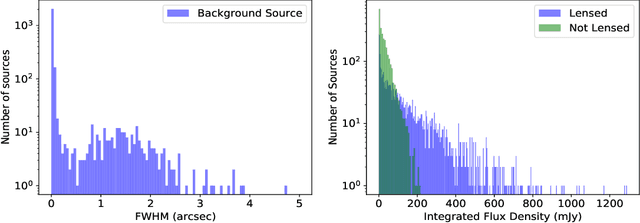

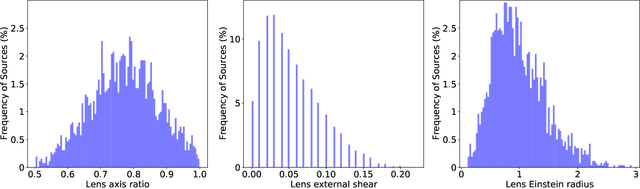
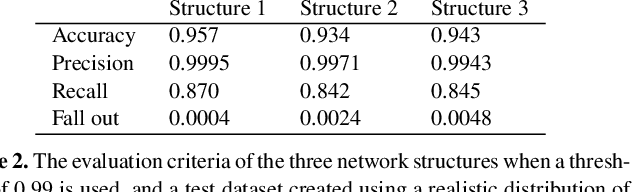
We present a novel machine learning based approach for detecting galaxy-scale gravitational lenses from interferometric data, specifically those taken with the International LOFAR Telescope (ILT), which is observing the northern radio sky at a frequency of 150 MHz, an angular resolution of 350 mas and a sensitivity of 90 uJy beam-1 (1 sigma). We develop and test several Convolutional Neural Networks to determine the probability and uncertainty of a given sample being classified as a lensed or non-lensed event. By training and testing on a simulated interferometric imaging data set that includes realistic lensed and non-lensed radio sources, we find that it is possible to recover 95.3 per cent of the lensed samples (true positive rate), with a contamination of just 0.008 per cent from non-lensed samples (false positive rate). Taking the expected lensing probability into account results in a predicted sample purity for lensed events of 92.2 per cent. We find that the network structure is most robust when the maximum image separation between the lensed images is greater than 3 times the synthesized beam size, and the lensed images have a total flux density that is equivalent to at least a 20 sigma (point-source) detection. For the ILT, this corresponds to a lens sample with Einstein radii greater than 0.5 arcsec and a radio source population with 150 MHz flux densities more than 2 mJy. By applying these criteria and our lens detection algorithm we expect to discover the vast majority of galaxy-scale gravitational lens systems contained within the LOFAR Two Metre Sky Survey.
Interactive Style Transfer: All is Your Palette
Mar 25, 2022

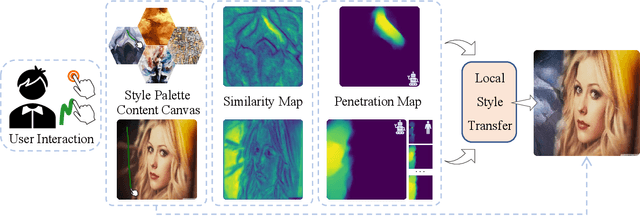

Neural style transfer (NST) can create impressive artworks by transferring reference style to content image. Current image-to-image NST methods are short of fine-grained controls, which are often demanded by artistic editing. To mitigate this limitation, we propose a drawing-like interactive style transfer (IST) method, by which users can interactively create a harmonious-style image. Our IST method can serve as a brush, dip style from anywhere, and then paint to any region of the target content image. To determine the action scope, we formulate a fluid simulation algorithm, which takes styles as pigments around the position of brush interaction, and diffusion in style or content images according to the similarity maps. Our IST method expands the creative dimension of NST. By dipping and painting, even employing one style image can produce thousands of eye-catching works. The demo video is available in supplementary files or in http://mmcheng.net/ist.