 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
ItemSage: Learning Product Embeddings for Shopping Recommendations at Pinterest
May 24, 2022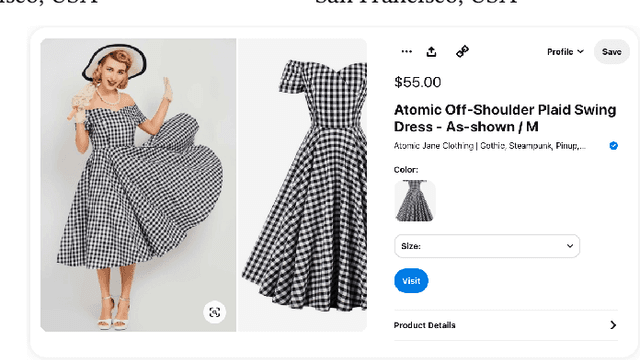

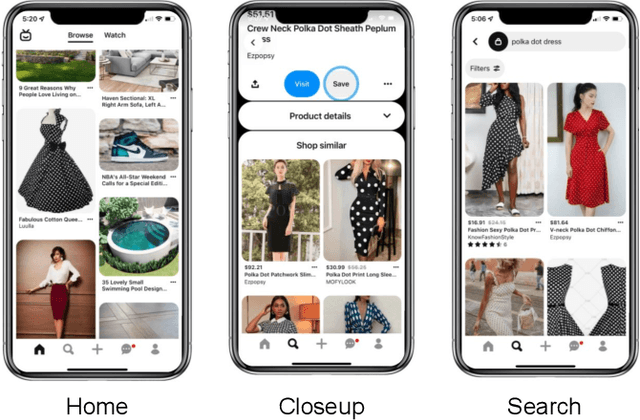
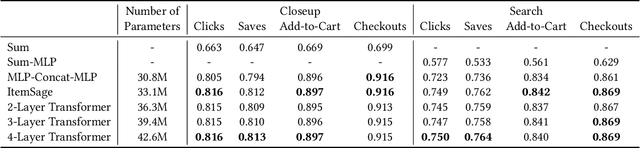
Learned embeddings for products are an important building block for web-scale e-commerce recommendation systems. At Pinterest, we build a single set of product embeddings called ItemSage to provide relevant recommendations in all shopping use cases including user, image and search based recommendations. This approach has led to significant improvements in engagement and conversion metrics, while reducing both infrastructure and maintenance cost. While most prior work focuses on building product embeddings from features coming from a single modality, we introduce a transformer-based architecture capable of aggregating information from both text and image modalities and show that it significantly outperforms single modality baselines. We also utilize multi-task learning to make ItemSage optimized for several engagement types, leading to a candidate generation system that is efficient for all of the engagement objectives of the end-to-end recommendation system. Extensive offline experiments are conducted to illustrate the effectiveness of our approach and results from online A/B experiments show substantial gains in key business metrics (up to +7% gross merchandise value/user and +11% click volume).
* 9 pages, 5 figures
Scalable Machine Translation in Memory Constrained Environments
Oct 06, 2016
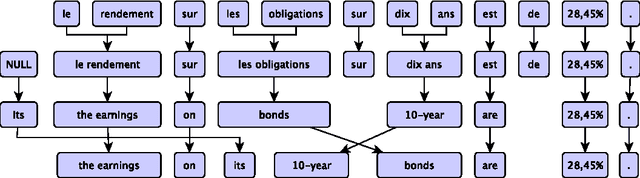
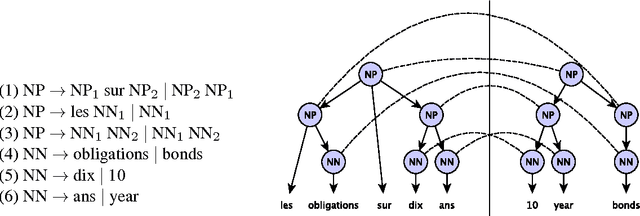
Machine translation is the discipline concerned with developing automated tools for translating from one human language to another. Statistical machine translation (SMT) is the dominant paradigm in this field. In SMT, translations are generated by means of statistical models whose parameters are learned from bilingual data. Scalability is a key concern in SMT, as one would like to make use of as much data as possible to train better translation systems. In recent years, mobile devices with adequate computing power have become widely available. Despite being very successful, mobile applications relying on NLP systems continue to follow a client-server architecture, which is of limited use because access to internet is often limited and expensive. The goal of this dissertation is to show how to construct a scalable machine translation system that can operate with the limited resources available on a mobile device. The main challenge for porting translation systems on mobile devices is memory usage. The amount of memory available on a mobile device is far less than what is typically available on the server side of a client-server application. In this thesis, we investigate alternatives for the two components which prevent standard translation systems from working on mobile devices due to high memory usage. We show that once these standard components are replaced with our proposed alternatives, we obtain a scalable translation system that can work on a device with limited memory.
Pragmatic Neural Language Modelling in Machine Translation
Mar 20, 2015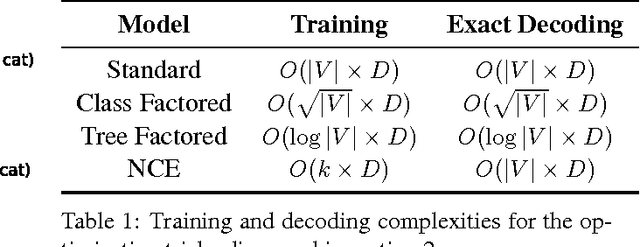
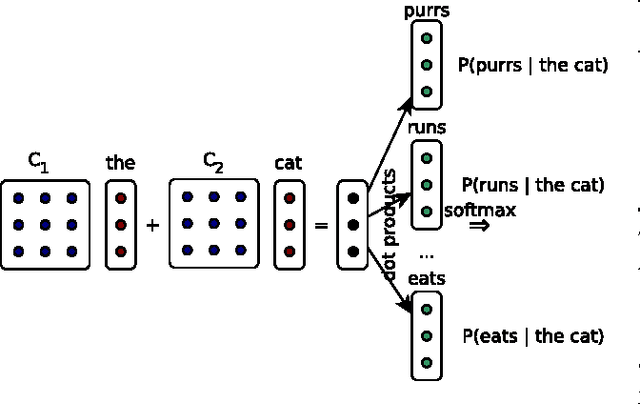

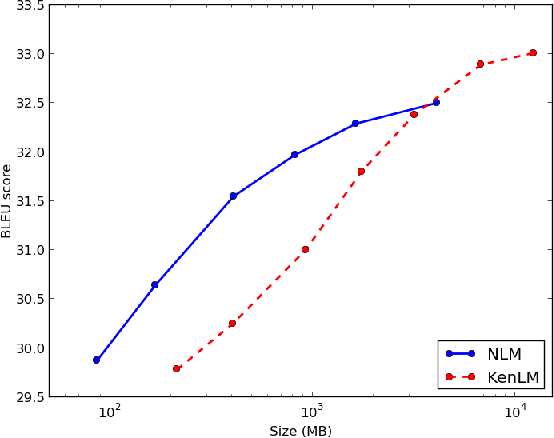
This paper presents an in-depth investigation on integrating neural language models in translation systems. Scaling neural language models is a difficult task, but crucial for real-world applications. This paper evaluates the impact on end-to-end MT quality of both new and existing scaling techniques. We show when explicitly normalising neural models is necessary and what optimisation tricks one should use in such scenarios. We also focus on scalable training algorithms and investigate noise contrastive estimation and diagonal contexts as sources for further speed improvements. We explore the trade-offs between neural models and back-off n-gram models and find that neural models make strong candidates for natural language applications in memory constrained environments, yet still lag behind traditional models in raw translation quality. We conclude with a set of recommendations one should follow to build a scalable neural language model for MT.