 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Diversity in Image Generation via Attribute-Conditional Human Evaluation
Nov 13, 2025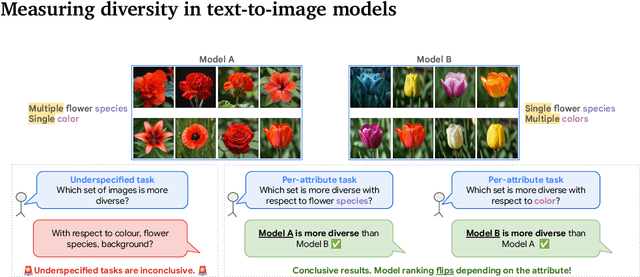
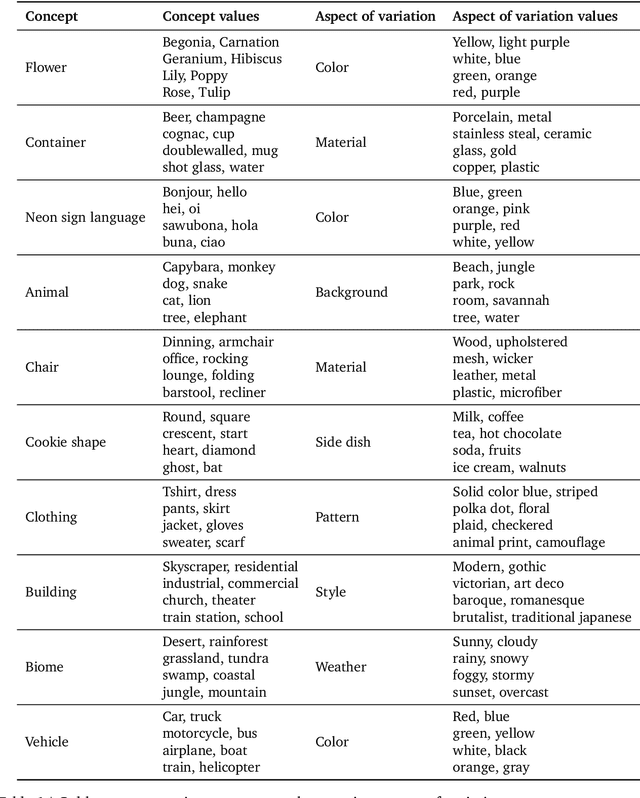
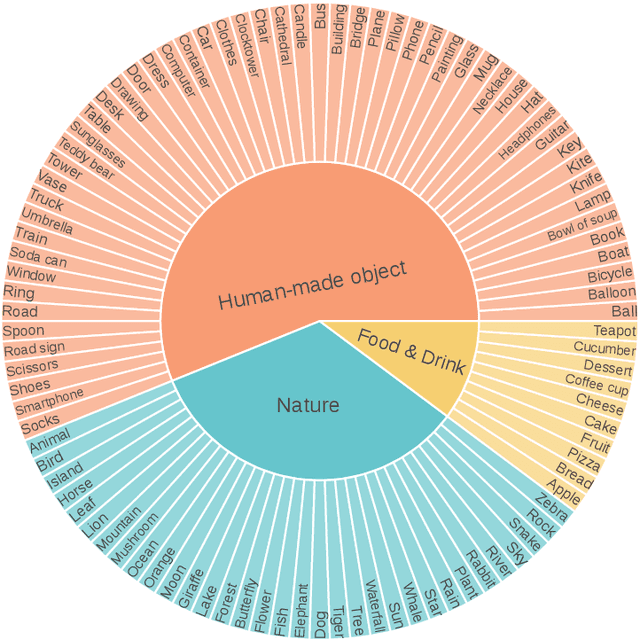
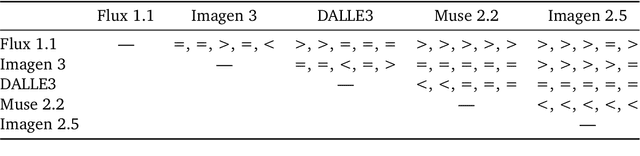
Despite advances in generation quality, current text-to-image (T2I) models often lack diversity, generating homogeneous outputs. This work introduces a framework to address the need for robust diversity evaluation in T2I models. Our framework systematically assesses diversity by evaluating individual concepts and their relevant factors of variation. Key contributions include: (1) a novel human evaluation template for nuanced diversity assessment; (2) a curated prompt set covering diverse concepts with their identified factors of variation (e.g. prompt: An image of an apple, factor of variation: color); and (3) a methodology for comparing models in terms of human annotations via binomial tests. Furthermore, we rigorously compare various image embeddings for diversity measurement. Notably, our principled approach enables ranking of T2I models by diversity, identifying categories where they particularly struggle. This research offers a robust methodology and insights, paving the way for improvements in T2I model diversity and metric development.
Dynamic Classifier-Free Diffusion Guidance via Online Feedback
Sep 19, 2025



Classifier-free guidance (CFG) is a cornerstone of text-to-image diffusion models, yet its effectiveness is limited by the use of static guidance scales. This "one-size-fits-all" approach fails to adapt to the diverse requirements of different prompts; moreover, prior solutions like gradient-based correction or fixed heuristic schedules introduce additional complexities and fail to generalize. In this work, we challeng this static paradigm by introducing a framework for dynamic CFG scheduling. Our method leverages online feedback from a suite of general-purpose and specialized small-scale latent-space evaluations, such as CLIP for alignment, a discriminator for fidelity and a human preference reward model, to assess generation quality at each step of the reverse diffusion process. Based on this feedback, we perform a greedy search to select the optimal CFG scale for each timestep, creating a unique guidance schedule tailored to every prompt and sample. We demonstrate the effectiveness of our approach on both small-scale models and the state-of-the-art Imagen 3, showing significant improvements in text alignment, visual quality, text rendering and numerical reasoning. Notably, when compared against the default Imagen 3 baseline, our method achieves up to 53.8% human preference win-rate for overall preference, a figure that increases up to to 55.5% on prompts targeting specific capabilities like text rendering. Our work establishes that the optimal guidance schedule is inherently dynamic and prompt-dependent, and provides an efficient and generalizable framework to achieve it.
AlphaEarth Foundations: An embedding field model for accurate and efficient global mapping from sparse label data
Jul 29, 2025Unprecedented volumes of Earth observation data are continually collected around the world, but high-quality labels remain scarce given the effort required to make physical measurements and observations. This has led to considerable investment in bespoke modeling efforts translating sparse labels into maps. Here we introduce AlphaEarth Foundations, an embedding field model yielding a highly general, geospatial representation that assimilates spatial, temporal, and measurement contexts across multiple sources, enabling accurate and efficient production of maps and monitoring systems from local to global scales. The embeddings generated by AlphaEarth Foundations are the only to consistently outperform all previous featurization approaches tested on a diverse set of mapping evaluations without re-training. We will release a dataset of global, annual, analysis-ready embedding field layers from 2017 through 2024.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Evaluating Model Bias Requires Characterizing its Mistakes
Jul 15, 2024



The ability to properly benchmark model performance in the face of spurious correlations is important to both build better predictors and increase confidence that models are operating as intended. We demonstrate that characterizing (as opposed to simply quantifying) model mistakes across subgroups is pivotal to properly reflect model biases, which are ignored by standard metrics such as worst-group accuracy or accuracy gap. Inspired by the hypothesis testing framework, we introduce SkewSize, a principled and flexible metric that captures bias from mistakes in a model's predictions. It can be used in multi-class settings or generalised to the open vocabulary setting of generative models. SkewSize is an aggregation of the effect size of the interaction between two categorical variables: the spurious variable representing the bias attribute and the model's prediction. We demonstrate the utility of SkewSize in multiple settings including: standard vision models trained on synthetic data, vision models trained on ImageNet, and large scale vision-and-language models from the BLIP-2 family. In each case, the proposed SkewSize is able to highlight biases not captured by other metrics, while also providing insights on the impact of recently proposed techniques, such as instruction tuning.
Evaluating Numerical Reasoning in Text-to-Image Models
Jun 20, 2024



Text-to-image generative models are capable of producing high-quality images that often faithfully depict concepts described using natural language. In this work, we comprehensively evaluate a range of text-to-image models on numerical reasoning tasks of varying difficulty, and show that even the most advanced models have only rudimentary numerical skills. Specifically, their ability to correctly generate an exact number of objects in an image is limited to small numbers, it is highly dependent on the context the number term appears in, and it deteriorates quickly with each successive number. We also demonstrate that models have poor understanding of linguistic quantifiers (such as "a few" or "as many as"), the concept of zero, and struggle with more advanced concepts such as partial quantities and fractional representations. We bundle prompts, generated images and human annotations into GeckoNum, a novel benchmark for evaluation of numerical reasoning.
Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings
Apr 25, 2024While text-to-image (T2I) generative models have become ubiquitous, they do not necessarily generate images that align with a given prompt. While previous work has evaluated T2I alignment by proposing metrics, benchmarks, and templates for collecting human judgements, the quality of these components is not systematically measured. Human-rated prompt sets are generally small and the reliability of the ratings -- and thereby the prompt set used to compare models -- is not evaluated. We address this gap by performing an extensive study evaluating auto-eval metrics and human templates. We provide three main contributions: (1) We introduce a comprehensive skills-based benchmark that can discriminate models across different human templates. This skills-based benchmark categorises prompts into sub-skills, allowing a practitioner to pinpoint not only which skills are challenging, but at what level of complexity a skill becomes challenging. (2) We gather human ratings across four templates and four T2I models for a total of >100K annotations. This allows us to understand where differences arise due to inherent ambiguity in the prompt and where they arise due to differences in metric and model quality. (3) Finally, we introduce a new QA-based auto-eval metric that is better correlated with human ratings than existing metrics for our new dataset, across different human templates, and on TIFA160.
Generative models improve fairness of medical classifiers under distribution shifts
Apr 18, 2023A ubiquitous challenge in machine learning is the problem of domain generalisation. This can exacerbate bias against groups or labels that are underrepresented in the datasets used for model development. Model bias can lead to unintended harms, especially in safety-critical applications like healthcare. Furthermore, the challenge is compounded by the difficulty of obtaining labelled data due to high cost or lack of readily available domain expertise. In our work, we show that learning realistic augmentations automatically from data is possible in a label-efficient manner using generative models. In particular, we leverage the higher abundance of unlabelled data to capture the underlying data distribution of different conditions and subgroups for an imaging modality. By conditioning generative models on appropriate labels, we can steer the distribution of synthetic examples according to specific requirements. We demonstrate that these learned augmentations can surpass heuristic ones by making models more robust and statistically fair in- and out-of-distribution. To evaluate the generality of our approach, we study 3 distinct medical imaging contexts of varying difficulty: (i) histopathology images from a publicly available generalisation benchmark, (ii) chest X-rays from publicly available clinical datasets, and (iii) dermatology images characterised by complex shifts and imaging conditions. Complementing real training samples with synthetic ones improves the robustness of models in all three medical tasks and increases fairness by improving the accuracy of diagnosis within underrepresented groups. This approach leads to stark improvements OOD across modalities: 7.7% prediction accuracy improvement in histopathology, 5.2% in chest radiology with 44.6% lower fairness gap and a striking 63.5% improvement in high-risk sensitivity for dermatology with a 7.5x reduction in fairness gap.
Differentially Private Diffusion Models Generate Useful Synthetic Images
Feb 27, 2023



The ability to generate privacy-preserving synthetic versions of sensitive image datasets could unlock numerous ML applications currently constrained by data availability. Due to their astonishing image generation quality, diffusion models are a prime candidate for generating high-quality synthetic data. However, recent studies have found that, by default, the outputs of some diffusion models do not preserve training data privacy. By privately fine-tuning ImageNet pre-trained diffusion models with more than 80M parameters, we obtain SOTA results on CIFAR-10 and Camelyon17 in terms of both FID and the accuracy of downstream classifiers trained on synthetic data. We decrease the SOTA FID on CIFAR-10 from 26.2 to 9.8, and increase the accuracy from 51.0% to 88.0%. On synthetic data from Camelyon17, we achieve a downstream accuracy of 91.1% which is close to the SOTA of 96.5% when training on the real data. We leverage the ability of generative models to create infinite amounts of data to maximise the downstream prediction performance, and further show how to use synthetic data for hyperparameter tuning. Our results demonstrate that diffusion models fine-tuned with differential privacy can produce useful and provably private synthetic data, even in applications with significant distribution shift between the pre-training and fine-tuning distributions.
Compressed Vision for Efficient Video Understanding
Oct 06, 2022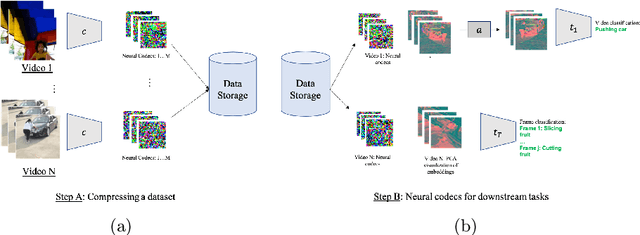
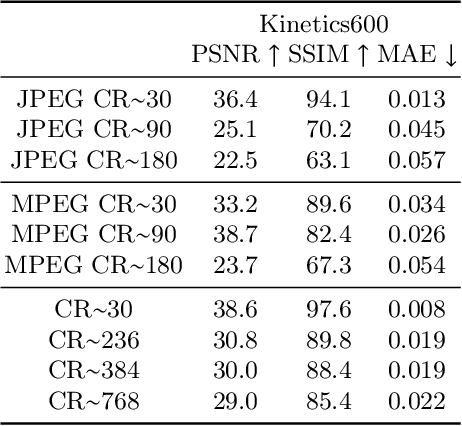
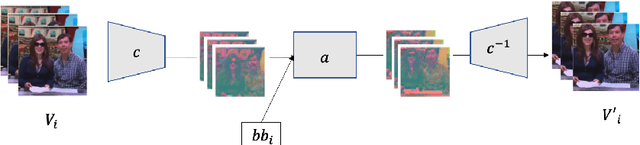

Experience and reasoning occur across multiple temporal scales: milliseconds, seconds, hours or days. The vast majority of computer vision research, however, still focuses on individual images or short videos lasting only a few seconds. This is because handling longer videos require more scalable approaches even to process them. In this work, we propose a framework enabling research on hour-long videos with the same hardware that can now process second-long videos. We replace standard video compression, e.g. JPEG, with neural compression and show that we can directly feed compressed videos as inputs to regular video networks. Operating on compressed videos improves efficiency at all pipeline levels -- data transfer, speed and memory -- making it possible to train models faster and on much longer videos. Processing compressed signals has, however, the downside of precluding standard augmentation techniques if done naively. We address that by introducing a small network that can apply transformations to latent codes corresponding to commonly used augmentations in the original video space. We demonstrate that with our compressed vision pipeline, we can train video models more efficiently on popular benchmarks such as Kinetics600 and COIN. We also perform proof-of-concept experiments with new tasks defined over hour-long videos at standard frame rates. Processing such long videos is impossible without using compressed representation.