 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Collaging Class-specific GANs for Semantic Image Synthesis
Oct 08, 2021

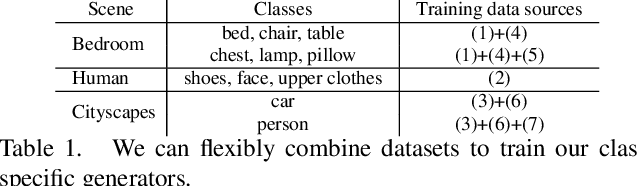
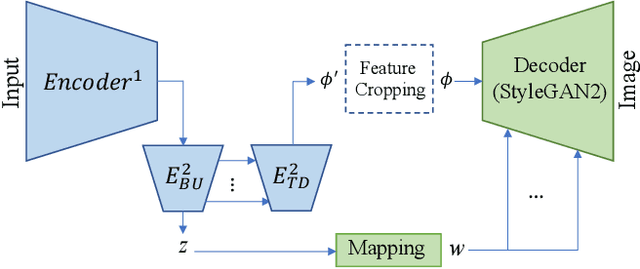
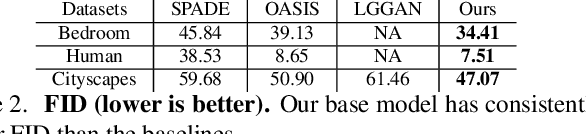
We propose a new approach for high resolution semantic image synthesis. It consists of one base image generator and multiple class-specific generators. The base generator generates high quality images based on a segmentation map. To further improve the quality of different objects, we create a bank of Generative Adversarial Networks (GANs) by separately training class-specific models. This has several benefits including -- dedicated weights for each class; centrally aligned data for each model; additional training data from other sources, potential of higher resolution and quality; and easy manipulation of a specific object in the scene. Experiments show that our approach can generate high quality images in high resolution while having flexibility of object-level control by using class-specific generators.
Structure-aware Image Inpainting with Two Parallel Streams
Nov 05, 2021
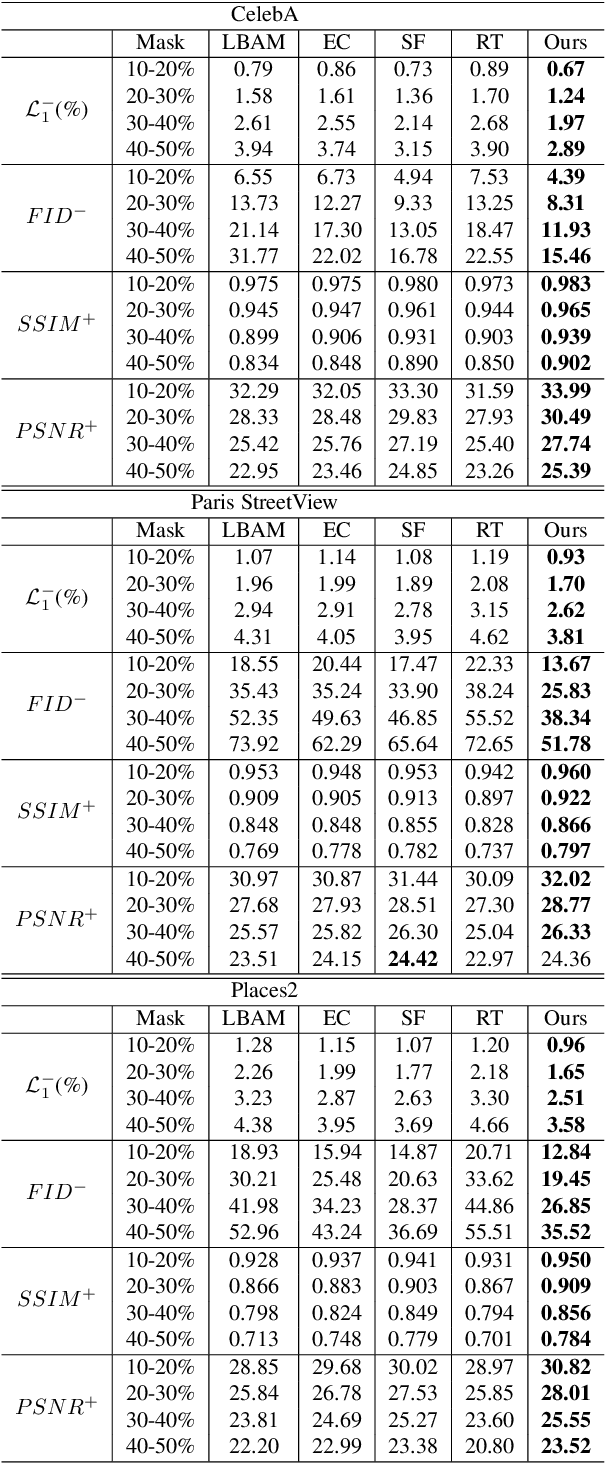
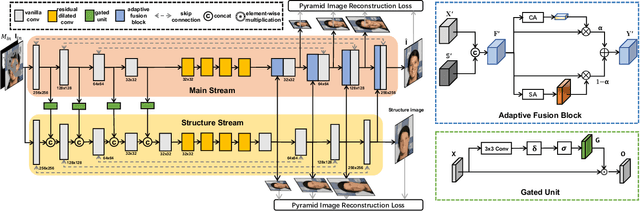
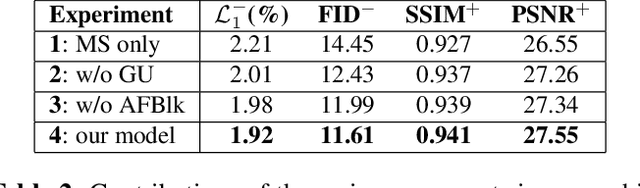
Recent works in image inpainting have shown that structural information plays an important role in recovering visually pleasing results. In this paper, we propose an end-to-end architecture composed of two parallel UNet-based streams: a main stream (MS) and a structure stream (SS). With the assistance of SS, MS can produce plausible results with reasonable structures and realistic details. Specifically, MS reconstructs detailed images by inferring missing structures and textures simultaneously, and SS restores only missing structures by processing the hierarchical information from the encoder of MS. By interacting with SS in the training process, MS can be implicitly encouraged to exploit structural cues. In order to help SS focus on structures and prevent textures in MS from being affected, a gated unit is proposed to depress structure-irrelevant activations in the information flow between MS and SS. Furthermore, the multi-scale structure feature maps in SS are utilized to explicitly guide the structure-reasonable image reconstruction in the decoder of MS through the fusion block. Extensive experiments on CelebA, Paris StreetView and Places2 datasets demonstrate that our proposed method outperforms state-of-the-art methods.
Learned reconstruction with convergence guarantees
Jun 11, 2022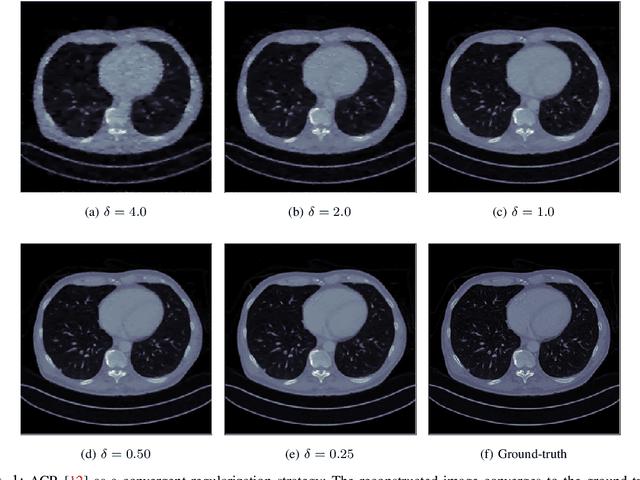
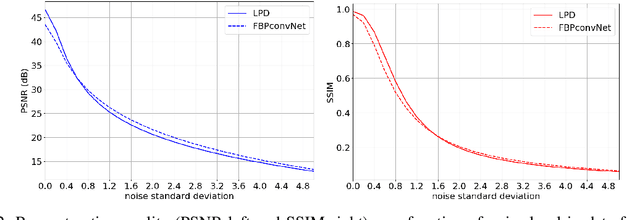
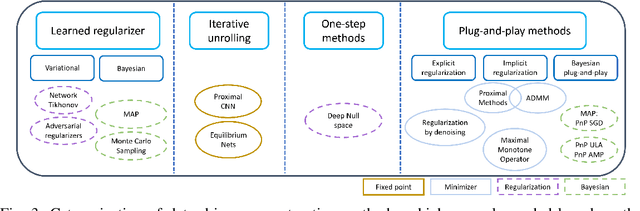
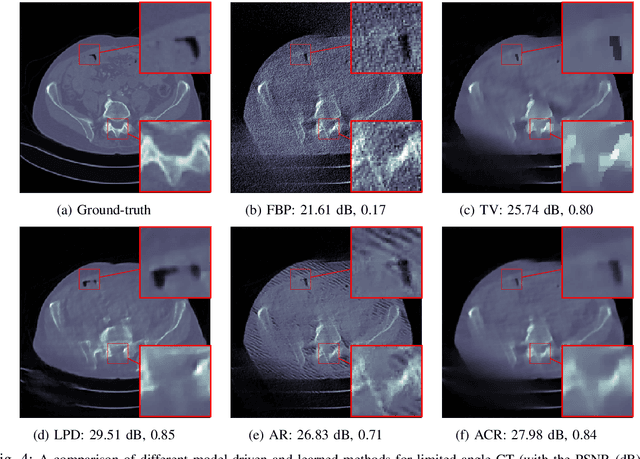
In recent years, deep learning has achieved remarkable empirical success for image reconstruction. This has catalyzed an ongoing quest for precise characterization of correctness and reliability of data-driven methods in critical use-cases, for instance in medical imaging. Notwithstanding the excellent performance and efficacy of deep learning-based methods, concerns have been raised regarding their stability, or lack thereof, with serious practical implications. Significant advances have been made in recent years to unravel the inner workings of data-driven image recovery methods, challenging their widely perceived black-box nature. In this article, we will specify relevant notions of convergence for data-driven image reconstruction, which will form the basis of a survey of learned methods with mathematically rigorous reconstruction guarantees. An example that is highlighted is the role of ICNN, offering the possibility to combine the power of deep learning with classical convex regularization theory for devising methods that are provably convergent. This survey article is aimed at both methodological researchers seeking to advance the frontiers of our understanding of data-driven image reconstruction methods as well as practitioners, by providing an accessible description of convergence concepts and by placing some of the existing empirical practices on a solid mathematical foundation.
Accelerating Score-based Generative Models with Preconditioned Diffusion Sampling
Jul 05, 2022

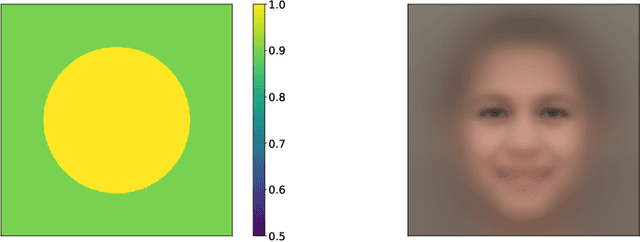

Score-based generative models (SGMs) have recently emerged as a promising class of generative models. However, a fundamental limitation is that their inference is very slow due to a need for many (e.g., 2000) iterations of sequential computations. An intuitive acceleration method is to reduce the sampling iterations which however causes severe performance degradation. We investigate this problem by viewing the diffusion sampling process as a Metropolis adjusted Langevin algorithm, which helps reveal the underlying cause to be ill-conditioned curvature. Under this insight, we propose a model-agnostic preconditioned diffusion sampling (PDS) method that leverages matrix preconditioning to alleviate the aforementioned problem. Crucially, PDS is proven theoretically to converge to the original target distribution of a SGM, no need for retraining. Extensive experiments on three image datasets with a variety of resolutions and diversity validate that PDS consistently accelerates off-the-shelf SGMs whilst maintaining the synthesis quality. In particular, PDS can accelerate by up to 29x on more challenging high resolution (1024x1024) image generation.
Scale Invariant Domain Generalization Image Recapture Detection
Oct 07, 2021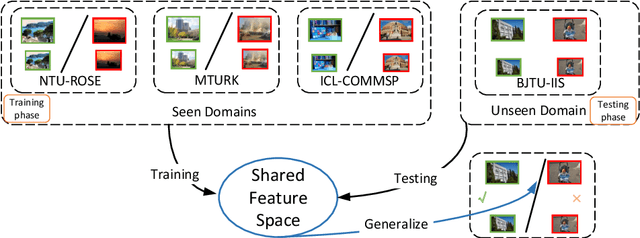

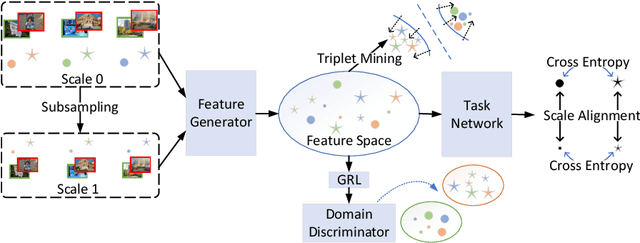
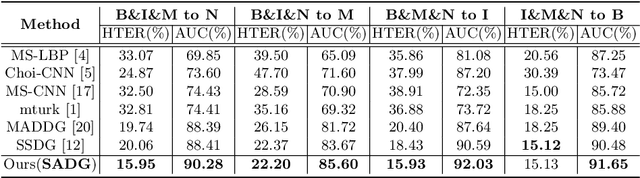
Recapturing and rebroadcasting of images are common attack methods in insurance frauds and face identification spoofing, and an increasing number of detection techniques were introduced to handle this problem. However, most of them ignored the domain generalization scenario and scale variances, with an inferior performance on domain shift situations, and normally were exacerbated by intra-domain and inter-domain scale variances. In this paper, we propose a scale alignment domain generalization framework (SADG) to address these challenges. First, an adversarial domain discriminator is exploited to minimize the discrepancies of image representation distributions among different domains. Meanwhile, we exploit triplet loss as a local constraint to achieve a clearer decision boundary. Moreover, a scale alignment loss is introduced as a global relationship regularization to force the image representations of the same class across different scales to be undistinguishable. Experimental results on four databases and comparison with state-of-the-art approaches show that better performance can be achieved using our framework.
An Image Patch is a Wave: Phase-Aware Vision MLP
Nov 25, 2021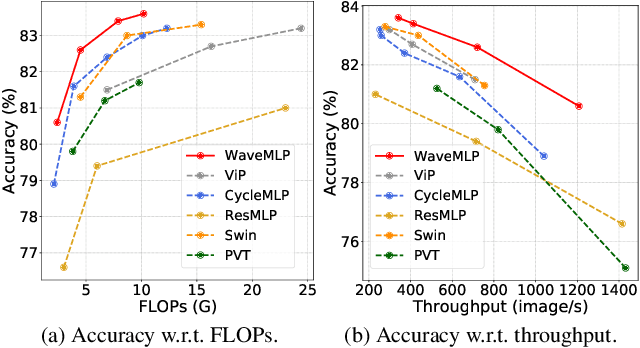
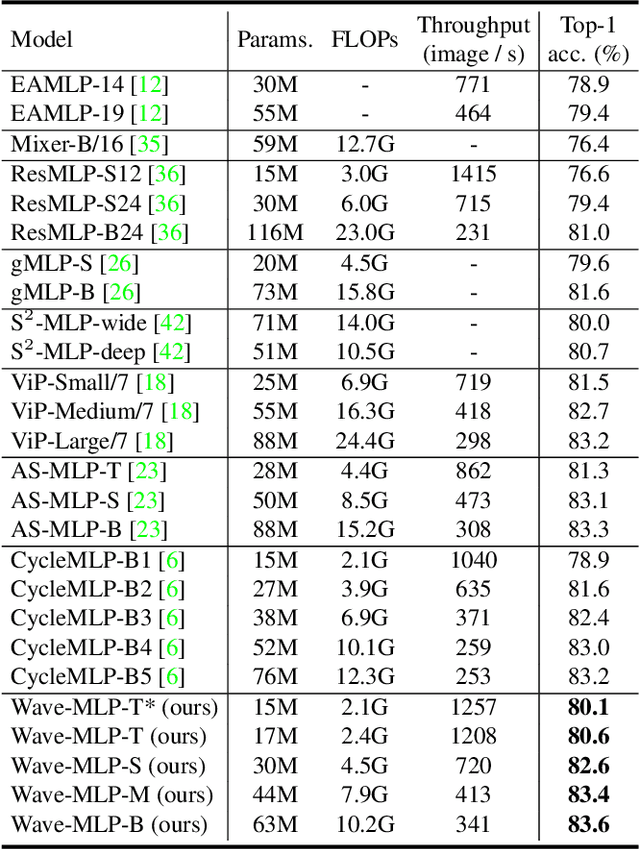
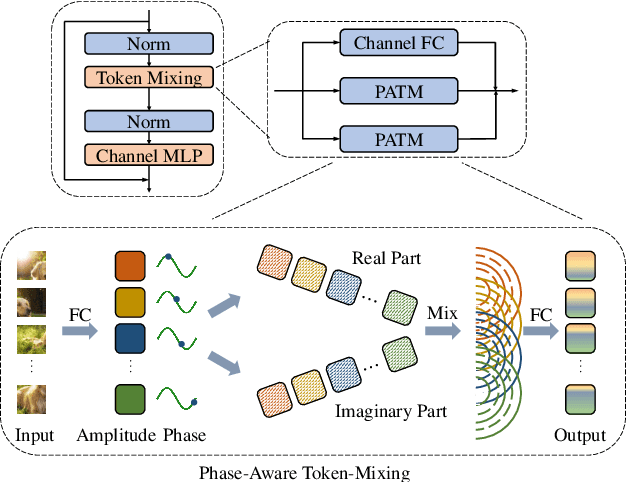
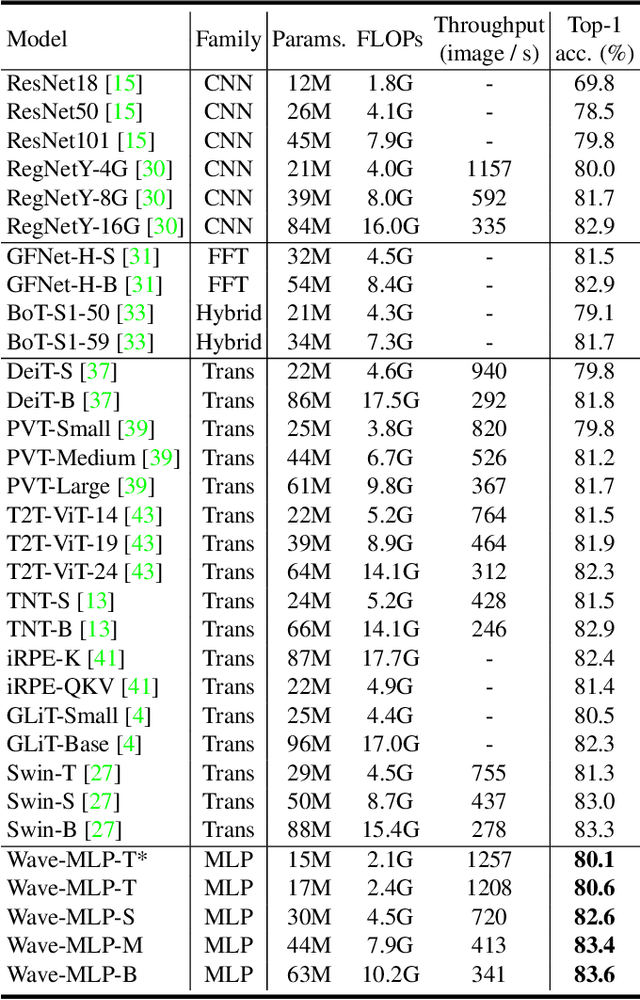
Different from traditional convolutional neural network (CNN) and vision transformer, the multilayer perceptron (MLP) is a new kind of vision model with extremely simple architecture that only stacked by fully-connected layers. An input image of vision MLP is usually split into multiple tokens (patches), while the existing MLP models directly aggregate them with fixed weights, neglecting the varying semantic information of tokens from different images. To dynamically aggregate tokens, we propose to represent each token as a wave function with two parts, amplitude and phase. Amplitude is the original feature and the phase term is a complex value changing according to the semantic contents of input images. Introducing the phase term can dynamically modulate the relationship between tokens and fixed weights in MLP. Based on the wave-like token representation, we establish a novel Wave-MLP architecture for vision tasks. Extensive experiments demonstrate that the proposed Wave-MLP is superior to the state-of-the-art MLP architectures on various vision tasks such as image classification, object detection and semantic segmentation.
ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis
Aug 19, 2021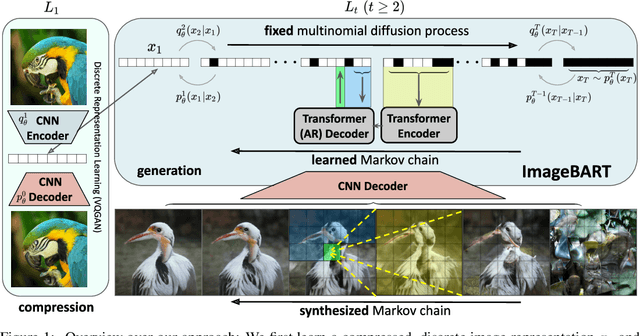



Autoregressive models and their sequential factorization of the data likelihood have recently demonstrated great potential for image representation and synthesis. Nevertheless, they incorporate image context in a linear 1D order by attending only to previously synthesized image patches above or to the left. Not only is this unidirectional, sequential bias of attention unnatural for images as it disregards large parts of a scene until synthesis is almost complete. It also processes the entire image on a single scale, thus ignoring more global contextual information up to the gist of the entire scene. As a remedy we incorporate a coarse-to-fine hierarchy of context by combining the autoregressive formulation with a multinomial diffusion process: Whereas a multistage diffusion process successively removes information to coarsen an image, we train a (short) Markov chain to invert this process. In each stage, the resulting autoregressive ImageBART model progressively incorporates context from previous stages in a coarse-to-fine manner. Experiments show greatly improved image modification capabilities over autoregressive models while also providing high-fidelity image generation, both of which are enabled through efficient training in a compressed latent space. Specifically, our approach can take unrestricted, user-provided masks into account to perform local image editing. Thus, in contrast to pure autoregressive models, it can solve free-form image inpainting and, in the case of conditional models, local, text-guided image modification without requiring mask-specific training.
Hierarchical Perceptual Noise Injection for Social Media Fingerprint Privacy Protection
Aug 23, 2022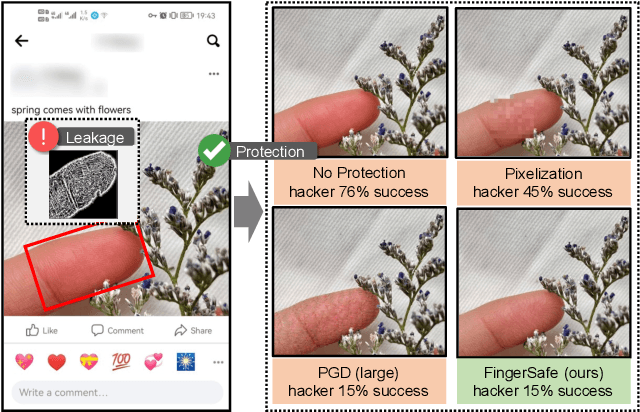
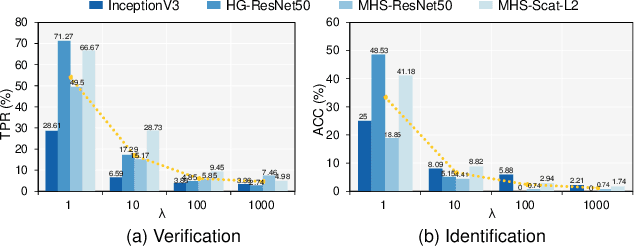
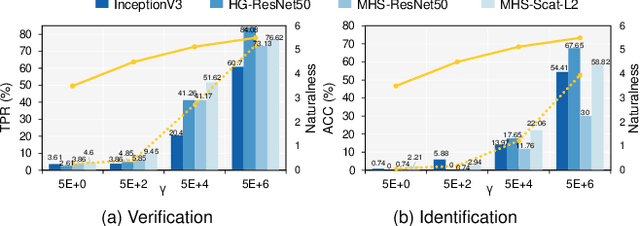
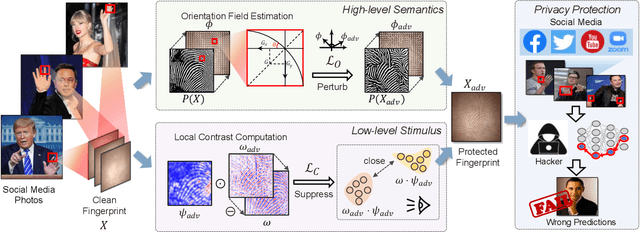
Billions of people are sharing their daily life images on social media every day. However, their biometric information (e.g., fingerprint) could be easily stolen from these images. The threat of fingerprint leakage from social media raises a strong desire for anonymizing shared images while maintaining image qualities, since fingerprints act as a lifelong individual biometric password. To guard the fingerprint leakage, adversarial attack emerges as a solution by adding imperceptible perturbations on images. However, existing works are either weak in black-box transferability or appear unnatural. Motivated by visual perception hierarchy (i.e., high-level perception exploits model-shared semantics that transfer well across models while low-level perception extracts primitive stimulus and will cause high visual sensitivities given suspicious stimulus), we propose FingerSafe, a hierarchical perceptual protective noise injection framework to address the mentioned problems. For black-box transferability, we inject protective noises on fingerprint orientation field to perturb the model-shared high-level semantics (i.e., fingerprint ridges). Considering visual naturalness, we suppress the low-level local contrast stimulus by regularizing the response of Lateral Geniculate Nucleus. Our FingerSafe is the first to provide feasible fingerprint protection in both digital (up to 94.12%) and realistic scenarios (Twitter and Facebook, up to 68.75%). Our code can be found at https://github.com/nlsde-safety-team/FingerSafe.
Global Context with Discrete Diffusion in Vector Quantised Modelling for Image Generation
Dec 03, 2021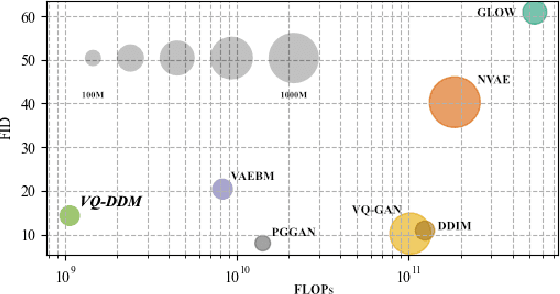
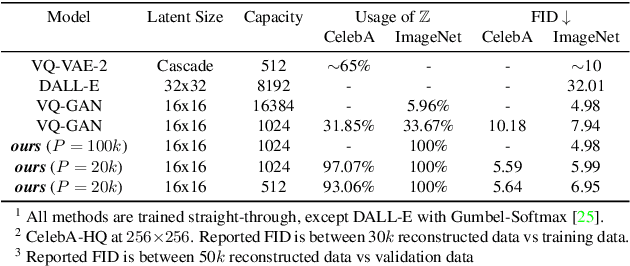
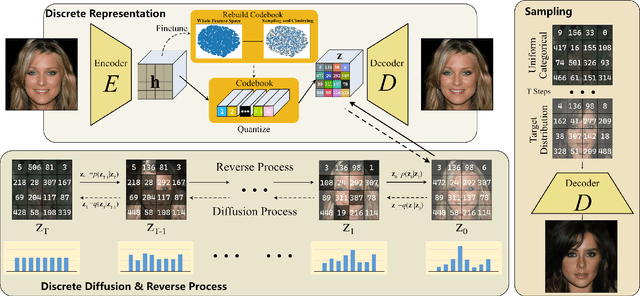
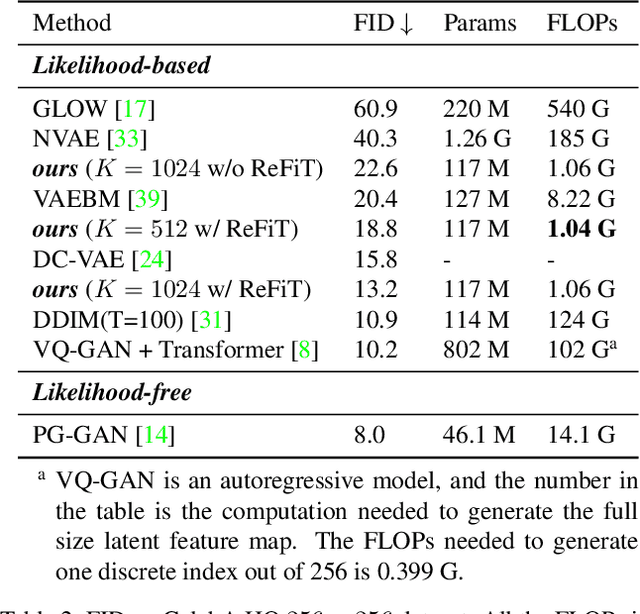
The integration of Vector Quantised Variational AutoEncoder (VQ-VAE) with autoregressive models as generation part has yielded high-quality results on image generation. However, the autoregressive models will strictly follow the progressive scanning order during the sampling phase. This leads the existing VQ series models to hardly escape the trap of lacking global information. Denoising Diffusion Probabilistic Models (DDPM) in the continuous domain have shown a capability to capture the global context, while generating high-quality images. In the discrete state space, some works have demonstrated the potential to perform text generation and low resolution image generation. We show that with the help of a content-rich discrete visual codebook from VQ-VAE, the discrete diffusion model can also generate high fidelity images with global context, which compensates for the deficiency of the classical autoregressive model along pixel space. Meanwhile, the integration of the discrete VAE with the diffusion model resolves the drawback of conventional autoregressive models being oversized, and the diffusion model which demands excessive time in the sampling process when generating images. It is found that the quality of the generated images is heavily dependent on the discrete visual codebook. Extensive experiments demonstrate that the proposed Vector Quantised Discrete Diffusion Model (VQ-DDM) is able to achieve comparable performance to top-tier methods with low complexity. It also demonstrates outstanding advantages over other vectors quantised with autoregressive models in terms of image inpainting tasks without additional training.
A Simple Approach to Image Tilt Correction with Self-Attention MobileNet for Smartphones
Oct 31, 2021

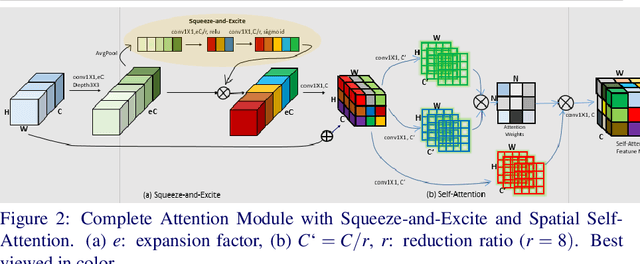
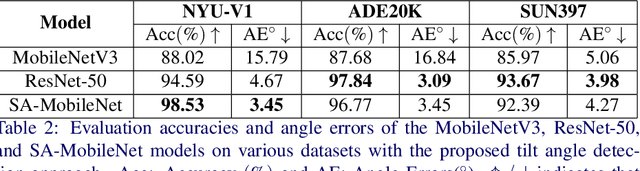
The main contributions of our work are two-fold. First, we present a Self-Attention MobileNet, called SA-MobileNet Network that can model long-range dependencies between the image features instead of processing the local region as done by standard convolutional kernels. SA-MobileNet contains self-attention modules integrated with the inverted bottleneck blocks of the MobileNetV3 model which results in modeling of both channel-wise attention and spatial attention of the image features and at the same time introduce a novel self-attention architecture for low-resource devices. Secondly, we propose a novel training pipeline for the task of image tilt detection. We treat this problem in a multi-label scenario where we predict multiple angles for a tilted input image in a narrow interval of range 1-2 degrees, depending on the dataset used. This process induces an implicit correlation between labels without any computational overhead of the second or higher-order methods in multi-label learning. With the combination of our novel approach and the architecture, we present state-of-the-art results on detecting the image tilt angle on mobile devices as compared to the MobileNetV3 model. Finally, we establish that SA-MobileNet is more accurate than MobileNetV3 on SUN397, NYU-V1, and ADE20K datasets by 6.42%, 10.51%, and 9.09% points respectively, and faster by at least 4 milliseconds on Snapdragon 750 Octa-core.