 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning 3D Semantic Segmentation with only 2D Image Supervision
Oct 21, 2021

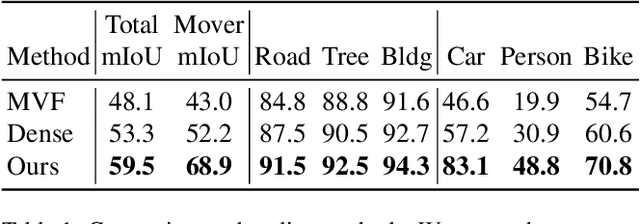
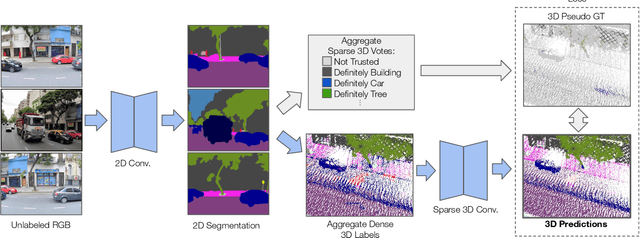
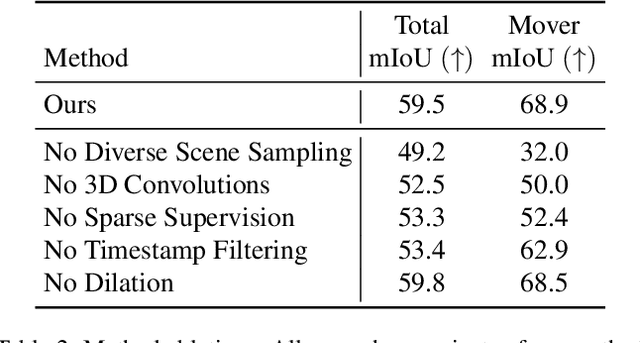
With the recent growth of urban mapping and autonomous driving efforts, there has been an explosion of raw 3D data collected from terrestrial platforms with lidar scanners and color cameras. However, due to high labeling costs, ground-truth 3D semantic segmentation annotations are limited in both quantity and geographic diversity, while also being difficult to transfer across sensors. In contrast, large image collections with ground-truth semantic segmentations are readily available for diverse sets of scenes. In this paper, we investigate how to use only those labeled 2D image collections to supervise training 3D semantic segmentation models. Our approach is to train a 3D model from pseudo-labels derived from 2D semantic image segmentations using multiview fusion. We address several novel issues with this approach, including how to select trusted pseudo-labels, how to sample 3D scenes with rare object categories, and how to decouple input features from 2D images from pseudo-labels during training. The proposed network architecture, 2D3DNet, achieves significantly better performance (+6.2-11.4 mIoU) than baselines during experiments on a new urban dataset with lidar and images captured in 20 cities across 5 continents.
Thunder: Thumbnail based Fast Lightweight Image Denoising Network
May 24, 2022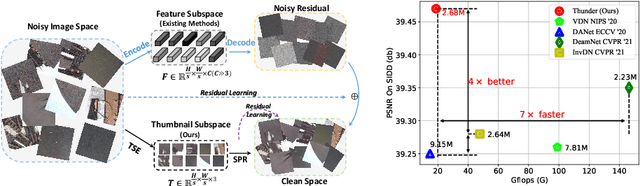
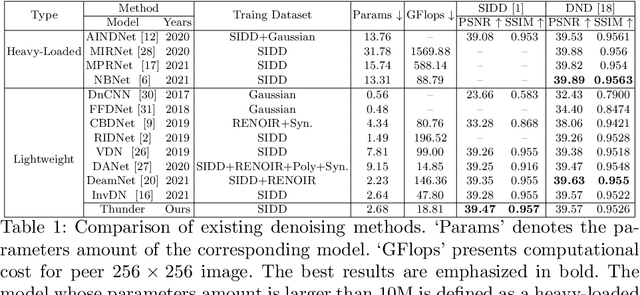
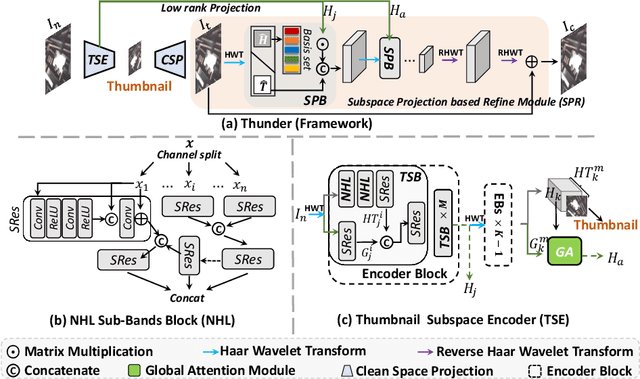
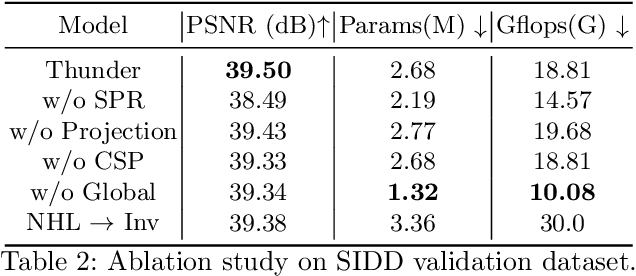
To achieve promising results on removing noise from real-world images, most of existing denoising networks are formulated with complex network structure, making them impractical for deployment. Some attempts focused on reducing the number of filters and feature channels but suffered from large performance loss, and a more practical and lightweight denoising network with fast inference speed is of high demand. To this end, a \textbf{Thu}mb\textbf{n}ail based \textbf{D}\textbf{e}noising Netwo\textbf{r}k dubbed Thunder, is proposed and implemented as a lightweight structure for fast restoration without comprising the denoising capabilities. Specifically, the Thunder model contains two newly-established modules: (1) a wavelet-based Thumbnail Subspace Encoder (TSE) which can leverage sub-bands correlation to provide an approximate thumbnail based on the low-frequent feature; (2) a Subspace Projection based Refine Module (SPR) which can restore the details for thumbnail progressively based on the subspace projection approach. Extensive experiments have been carried out on two real-world denoising benchmarks, demonstrating that the proposed Thunder outperforms the existing lightweight models and achieves competitive performance on PSNR and SSIM when compared with the complex designs.
Instance As Identity: A Generic Online Paradigm for Video Instance Segmentation
Aug 16, 2022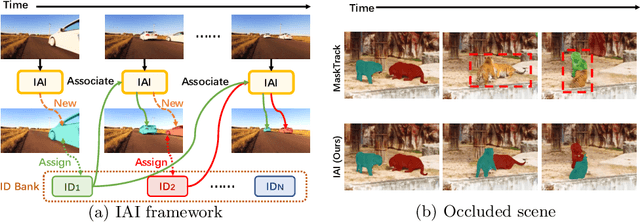
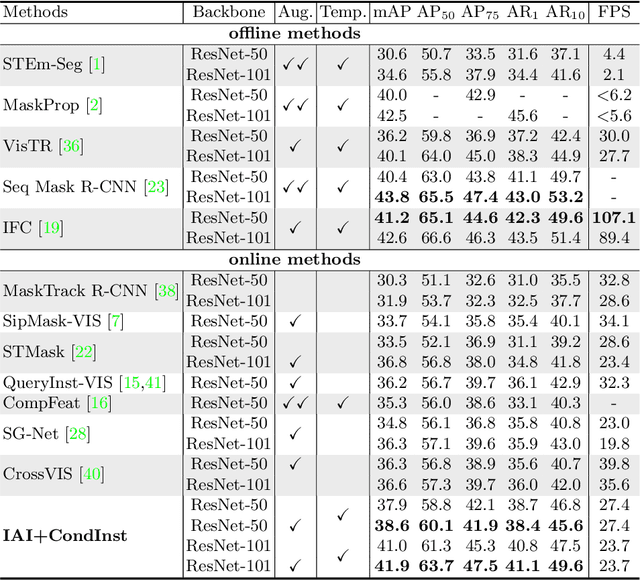
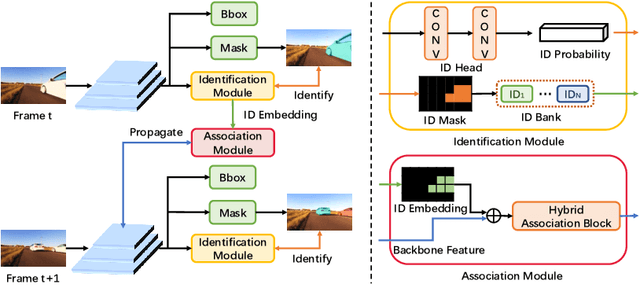
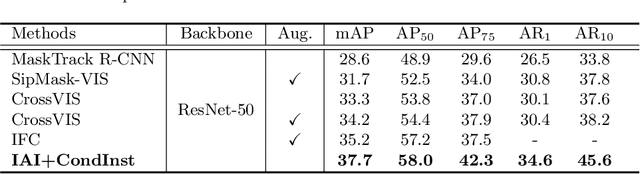
Modeling temporal information for both detection and tracking in a unified framework has been proved a promising solution to video instance segmentation (VIS). However, how to effectively incorporate the temporal information into an online model remains an open problem. In this work, we propose a new online VIS paradigm named Instance As Identity (IAI), which models temporal information for both detection and tracking in an efficient way. In detail, IAI employs a novel identification module to predict identification number for tracking instances explicitly. For passing temporal information cross frame, IAI utilizes an association module which combines current features and past embeddings. Notably, IAI can be integrated with different image models. We conduct extensive experiments on three VIS benchmarks. IAI outperforms all the online competitors on YouTube-VIS-2019 (ResNet-101 43.7 mAP) and YouTube-VIS-2021 (ResNet-50 38.0 mAP). Surprisingly, on the more challenging OVIS, IAI achieves SOTA performance (20.6 mAP). Code is available at https://github.com/zfonemore/IAI
Face Deblurring using Dual Camera Fusion on Mobile Phones
Jul 23, 2022
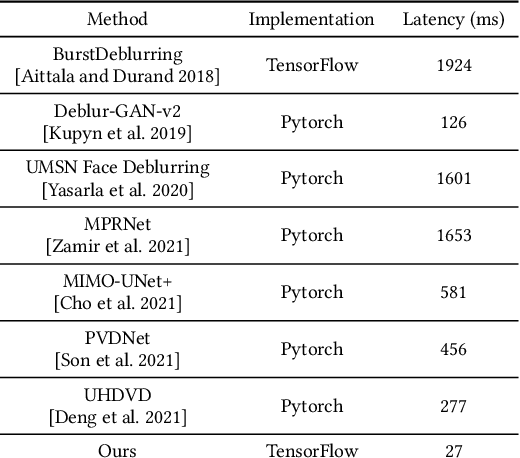

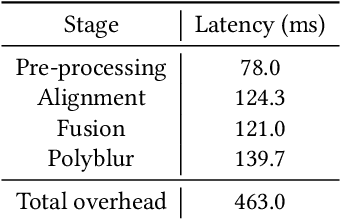
Motion blur of fast-moving subjects is a longstanding problem in photography and very common on mobile phones due to limited light collection efficiency, particularly in low-light conditions. While we have witnessed great progress in image deblurring in recent years, most methods require significant computational power and have limitations in processing high-resolution photos with severe local motions. To this end, we develop a novel face deblurring system based on the dual camera fusion technique for mobile phones. The system detects subject motion to dynamically enable a reference camera, e.g., ultrawide angle camera commonly available on recent premium phones, and captures an auxiliary photo with faster shutter settings. While the main shot is low noise but blurry, the reference shot is sharp but noisy. We learn ML models to align and fuse these two shots and output a clear photo without motion blur. Our algorithm runs efficiently on Google Pixel 6, which takes 463 ms overhead per shot. Our experiments demonstrate the advantage and robustness of our system against alternative single-image, multi-frame, face-specific, and video deblurring algorithms as well as commercial products. To the best of our knowledge, our work is the first mobile solution for face motion deblurring that works reliably and robustly over thousands of images in diverse motion and lighting conditions.
Semantic Relation Preserving Knowledge Distillation for Image-to-Image Translation
Apr 30, 2021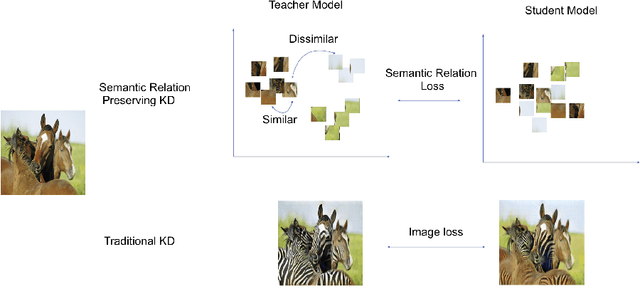
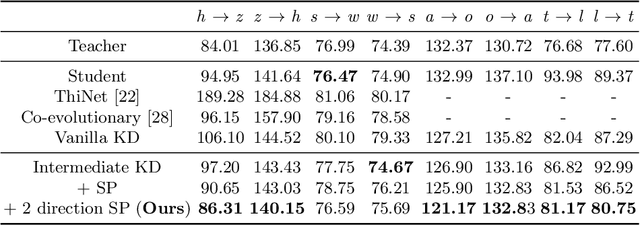
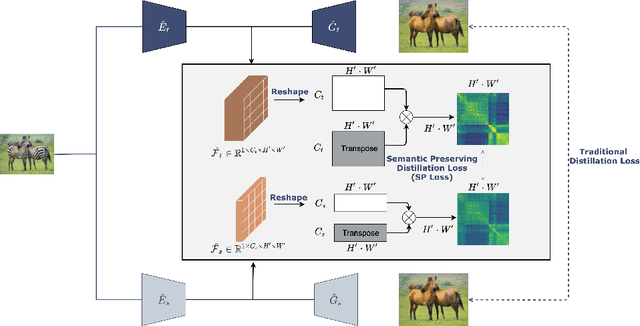
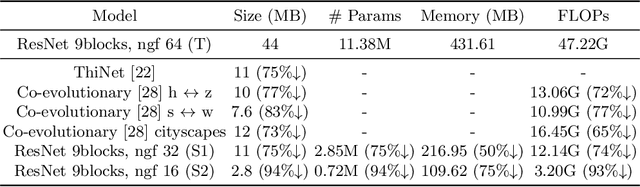
Generative adversarial networks (GANs) have shown significant potential in modeling high dimensional distributions of image data, especially on image-to-image translation tasks. However, due to the complexity of these tasks, state-of-the-art models often contain a tremendous amount of parameters, which results in large model size and long inference time. In this work, we propose a novel method to address this problem by applying knowledge distillation together with distillation of a semantic relation preserving matrix. This matrix, derived from the teacher's feature encoding, helps the student model learn better semantic relations. In contrast to existing compression methods designed for classification tasks, our proposed method adapts well to the image-to-image translation task on GANs. Experiments conducted on 5 different datasets and 3 different pairs of teacher and student models provide strong evidence that our methods achieve impressive results both qualitatively and quantitatively.
Comparative Analysis of Non-Blind Deblurring Methods for Noisy Blurred Images
May 06, 2022

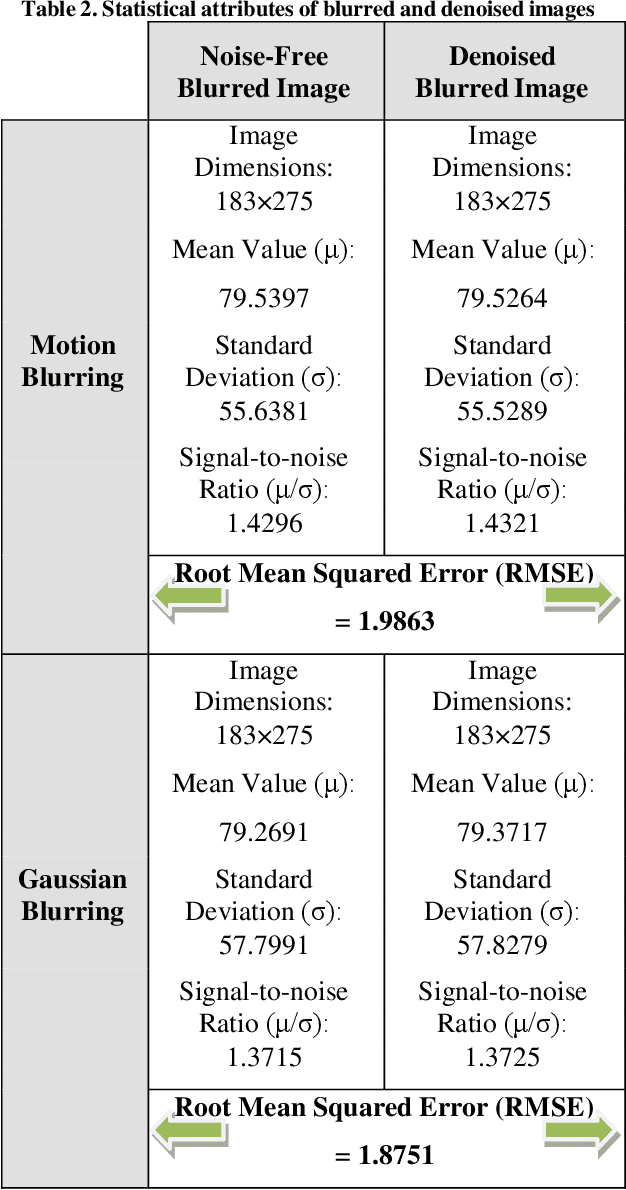
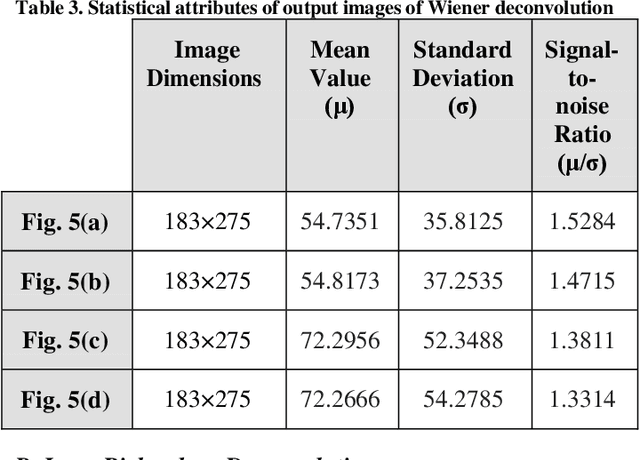
Image blurring refers to the degradation of an image wherein the image's overall sharpness decreases. Image blurring is caused by several factors. Additionally, during the image acquisition process, noise may get added to the image. Such a noisy and blurred image can be represented as the image resulting from the convolution of the original image with the associated point spread function, along with additive noise. However, the blurred image often contains inadequate information to uniquely determine the plausible original image. Based on the availability of blurring information, image deblurring methods can be classified as blind and non-blind. In non-blind image deblurring, some prior information is known regarding the corresponding point spread function and the added noise. The objective of this study is to determine the effectiveness of non-blind image deblurring methods with respect to the identification and elimination of noise present in blurred images. In this study, three non-blind image deblurring methods, namely Wiener deconvolution, Lucy-Richardson deconvolution, and regularized deconvolution were comparatively analyzed for noisy images featuring salt-and-pepper noise. Two types of blurring effects were simulated, namely motion blurring and Gaussian blurring. The said three non-blind deblurring methods were applied under two scenarios: direct deblurring of noisy blurred images and deblurring of images after denoising through the application of the adaptive median filter. The obtained results were then compared for each scenario to determine the best approach for deblurring noisy images.
Repairing Systematic Outliers by Learning Clean Subspaces in VAEs
Jul 17, 2022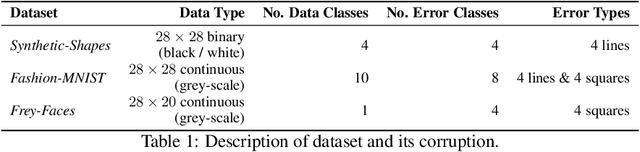
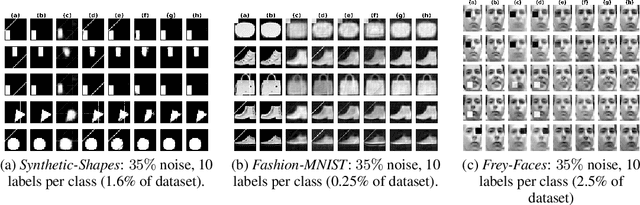
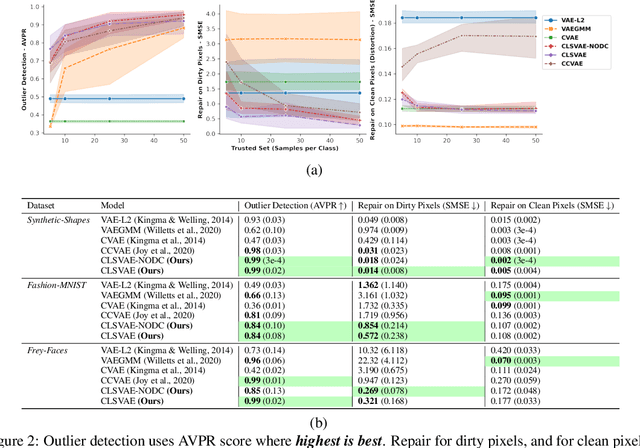

Data cleaning often comprises outlier detection and data repair. Systematic errors result from nearly deterministic transformations that occur repeatedly in the data, e.g. specific image pixels being set to default values or watermarks. Consequently, models with enough capacity easily overfit to these errors, making detection and repair difficult. Seeing as a systematic outlier is a combination of patterns of a clean instance and systematic error patterns, our main insight is that inliers can be modelled by a smaller representation (subspace) in a model than outliers. By exploiting this, we propose Clean Subspace Variational Autoencoder (CLSVAE), a novel semi-supervised model for detection and automated repair of systematic errors. The main idea is to partition the latent space and model inlier and outlier patterns separately. CLSVAE is effective with much less labelled data compared to previous related models, often with less than 2% of the data. We provide experiments using three image datasets in scenarios with different levels of corruption and labelled set sizes, comparing to relevant baselines. CLSVAE provides superior repairs without human intervention, e.g. with just 0.25% of labelled data we see a relative error decrease of 58% compared to the closest baseline.
Progressive Multi-scale Light Field Networks
Aug 13, 2022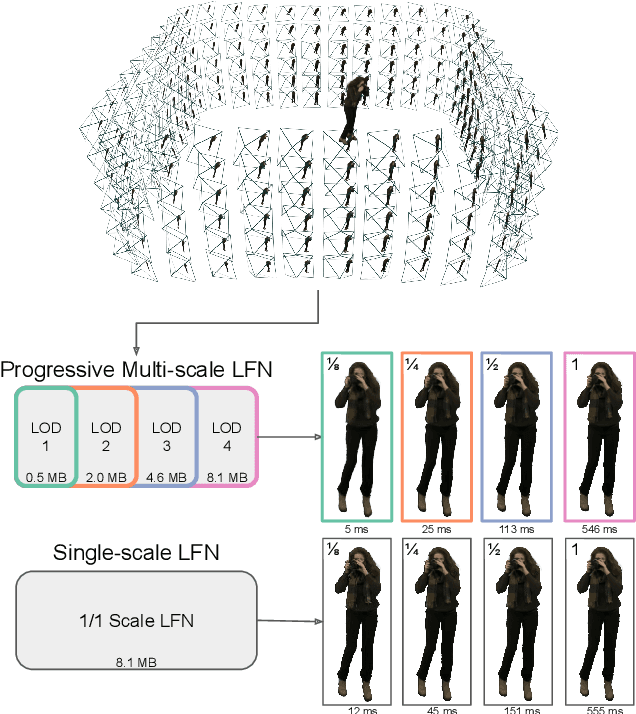


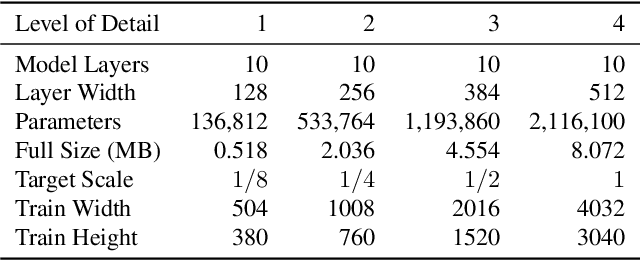
Neural representations have shown great promise in their ability to represent radiance and light fields while being very compact compared to the image set representation. However, current representations are not well suited for streaming as decoding can only be done at a single level of detail and requires downloading the entire neural network model. Furthermore, high-resolution light field networks can exhibit flickering and aliasing as neural networks are sampled without appropriate filtering. To resolve these issues, we present a progressive multi-scale light field network that encodes a light field with multiple levels of detail. Lower levels of detail are encoded using fewer neural network weights enabling progressive streaming and reducing rendering time. Our progressive multi-scale light field network addresses aliasing by encoding smaller anti-aliased representations at its lower levels of detail. Additionally, per-pixel level of detail enables our representation to support dithered transitions and foveated rendering.
Rethinking Generalization in Few-Shot Classification
Jun 15, 2022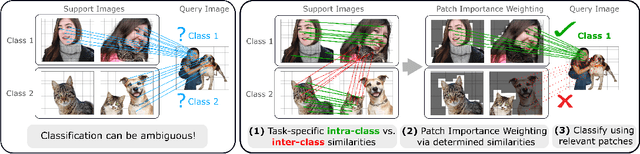
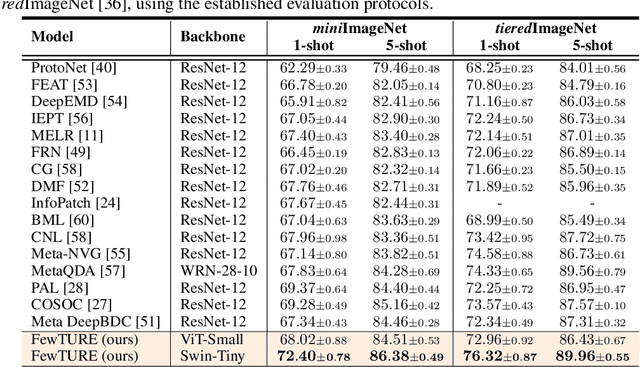
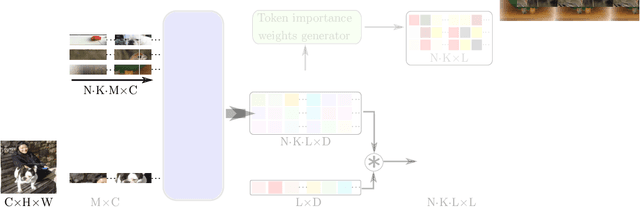
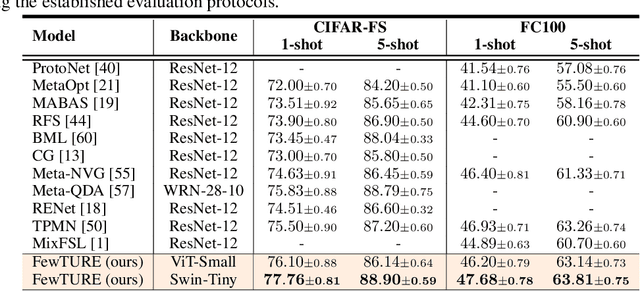
Single image-level annotations only correctly describe an often small subset of an image's content, particularly when complex real-world scenes are depicted. While this might be acceptable in many classification scenarios, it poses a significant challenge for applications where the set of classes differs significantly between training and test time. In this paper, we take a closer look at the implications in the context of $\textit{few-shot learning}$. Splitting the input samples into patches and encoding these via the help of Vision Transformers allows us to establish semantic correspondences between local regions across images and independent of their respective class. The most informative patch embeddings for the task at hand are then determined as a function of the support set via online optimization at inference time, additionally providing visual interpretability of `$\textit{what matters most}$' in the image. We build on recent advances in unsupervised training of networks via masked image modelling to overcome the lack of fine-grained labels and learn the more general statistical structure of the data while avoiding negative image-level annotation influence, $\textit{aka}$ supervision collapse. Experimental results show the competitiveness of our approach, achieving new state-of-the-art results on four popular few-shot classification benchmarks for $5$-shot and $1$-shot scenarios.
Infrared Image Super-Resolution via Heterogeneous Convolutional WGAN
Sep 02, 2021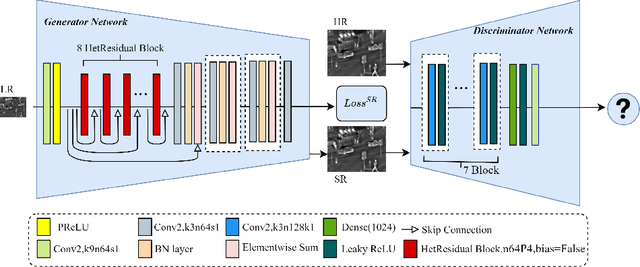
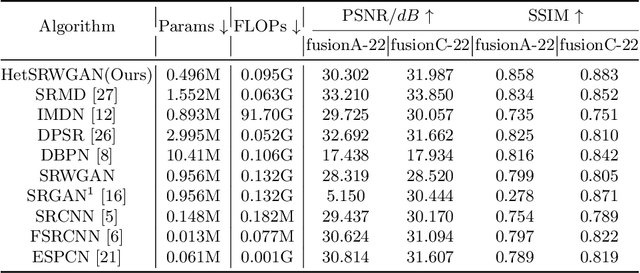
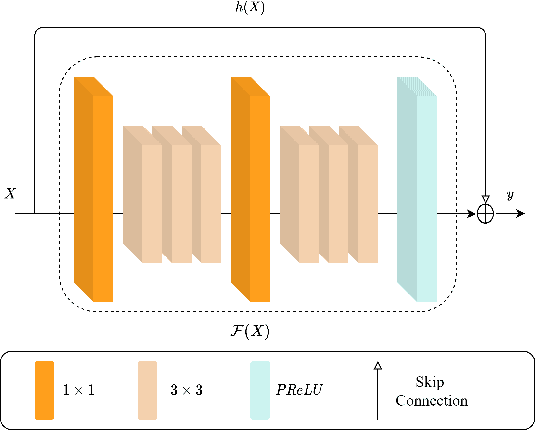
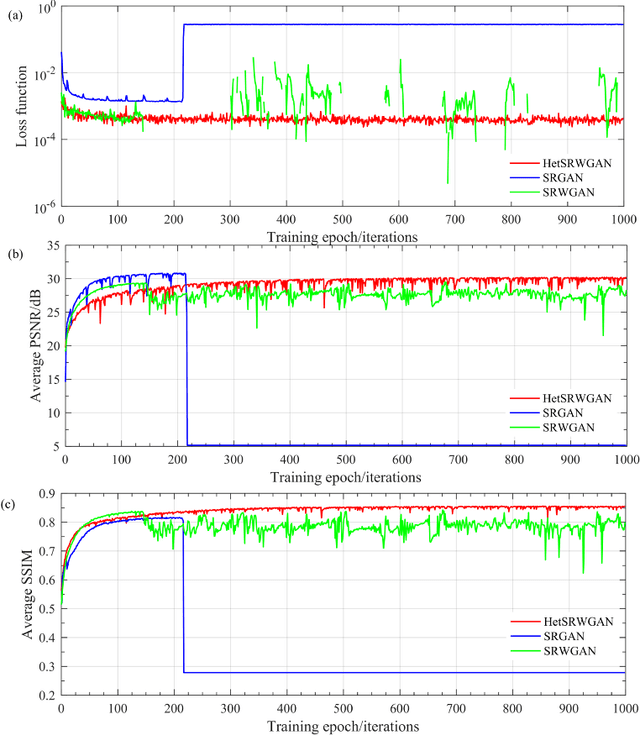
Image super-resolution is important in many fields, such as surveillance and remote sensing. However, infrared (IR) images normally have low resolution since the optical equipment is relatively expensive. Recently, deep learning methods have dominated image super-resolution and achieved remarkable performance on visible images; however, IR images have received less attention. IR images have fewer patterns, and hence, it is difficult for deep neural networks (DNNs) to learn diverse features from IR images. In this paper, we present a framework that employs heterogeneous convolution and adversarial training, namely, heterogeneous kernel-based super-resolution Wasserstein GAN (HetSRWGAN), for IR image super-resolution. The HetSRWGAN algorithm is a lightweight GAN architecture that applies a plug-and-play heterogeneous kernel-based residual block. Moreover, a novel loss function that employs image gradients is adopted, which can be applied to an arbitrary model. The proposed HetSRWGAN achieves consistently better performance in both qualitative and quantitative evaluations. According to the experimental results, the whole training process is more stable.