 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Content-aware Scalable Deep Compressed Sensing
Jul 19, 2022
To more efficiently address image compressed sensing (CS) problems, we present a novel content-aware scalable network dubbed CASNet which collectively achieves adaptive sampling rate allocation, fine granular scalability and high-quality reconstruction. We first adopt a data-driven saliency detector to evaluate the importances of different image regions and propose a saliency-based block ratio aggregation (BRA) strategy for sampling rate allocation. A unified learnable generating matrix is then developed to produce sampling matrix of any CS ratio with an ordered structure. Being equipped with the optimization-inspired recovery subnet guided by saliency information and a multi-block training scheme preventing blocking artifacts, CASNet jointly reconstructs the image blocks sampled at various sampling rates with one single model. To accelerate training convergence and improve network robustness, we propose an SVD-based initialization scheme and a random transformation enhancement (RTE) strategy, which are extensible without introducing extra parameters. All the CASNet components can be combined and learned end-to-end. We further provide a four-stage implementation for evaluation and practical deployments. Experiments demonstrate that CASNet outperforms other CS networks by a large margin, validating the collaboration and mutual supports among its components and strategies. Codes are available at https://github.com/Guaishou74851/CASNet.
Scene Graph Generation for Better Image Captioning?
Sep 23, 2021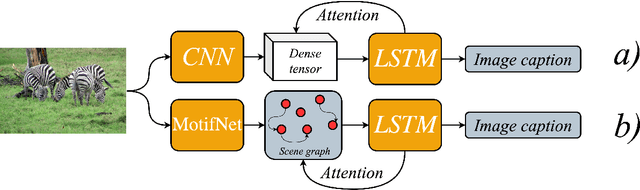
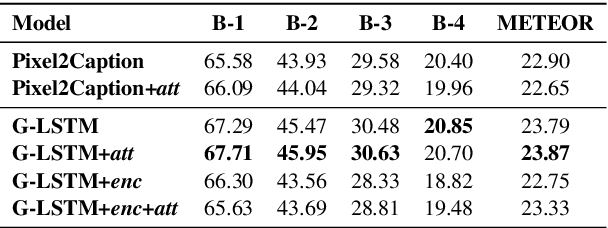
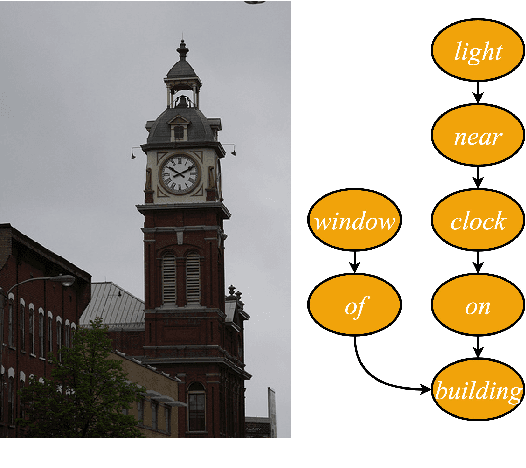
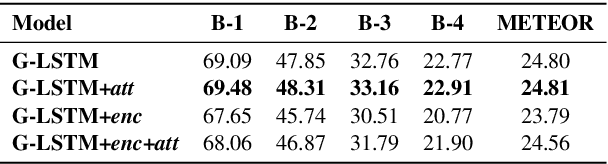
We investigate the incorporation of visual relationships into the task of supervised image caption generation by proposing a model that leverages detected objects and auto-generated visual relationships to describe images in natural language. To do so, we first generate a scene graph from raw image pixels by identifying individual objects and visual relationships between them. This scene graph then serves as input to our graph-to-text model, which generates the final caption. In contrast to previous approaches, our model thus explicitly models the detection of objects and visual relationships in the image. For our experiments we construct a new dataset from the intersection of Visual Genome and MS COCO, consisting of images with both a corresponding gold scene graph and human-authored caption. Our results show that our methods outperform existing state-of-the-art end-to-end models that generate image descriptions directly from raw input pixels when compared in terms of the BLEU and METEOR evaluation metrics.
High-Resolution Image Harmonization via Collaborative Dual Transformations
Sep 14, 2021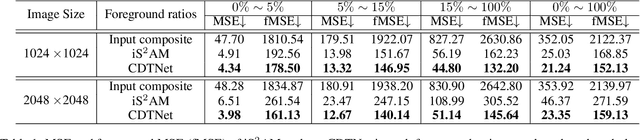

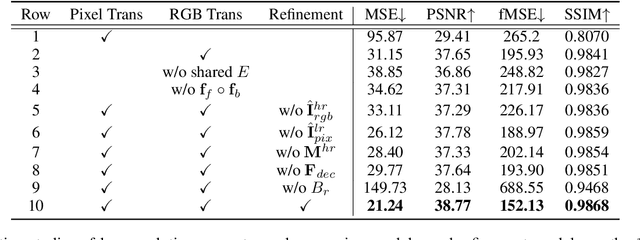
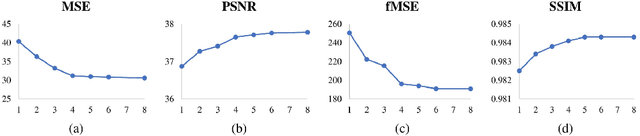
Given a composite image, image harmonization aims to adjust the foreground to make it compatible with the background. High-resolution image harmonization is in high demand, but still remains unexplored. Conventional image harmonization methods learn global RGB-to-RGB transformation which could effortlessly scale to high resolution, but ignore diverse local context. Recent deep learning methods learn the dense pixel-to-pixel transformation which could generate harmonious outputs, but are highly constrained in low resolution. In this work, we propose a high-resolution image harmonization network with Collaborative Dual Transformation (CDTNet) to combine pixel-to-pixel transformation and RGB-to-RGB transformation coherently in an end-to-end framework. Our CDTNet consists of a low-resolution generator for pixel-to-pixel transformation, a color mapping module for RGB-to-RGB transformation, and a refinement module to take advantage of both. Extensive experiments on high-resolution image harmonization dataset demonstrate that our CDTNet strikes a good balance between efficiency and effectiveness.
POP: Mining POtential Performance of new fashion products via webly cross-modal query expansion
Jul 22, 2022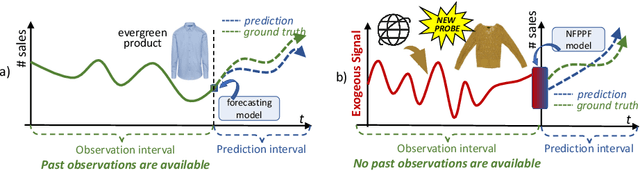
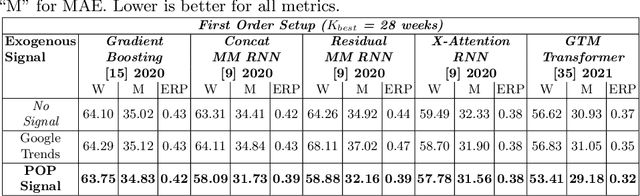

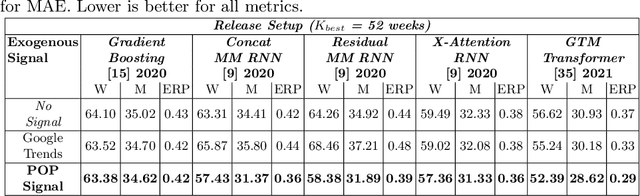
We propose a data-centric pipeline able to generate exogenous observation data for the New Fashion Product Performance Forecasting (NFPPF) problem, i.e., predicting the performance of a brand-new clothing probe with no available past observations. Our pipeline manufactures the missing past starting from a single, available image of the clothing probe. It starts by expanding textual tags associated with the image, querying related fashionable or unfashionable images uploaded on the web at a specific time in the past. A binary classifier is robustly trained on these web images by confident learning, to learn what was fashionable in the past and how much the probe image conforms to this notion of fashionability. This compliance produces the POtential Performance (POP) time series, indicating how performing the probe could have been if it were available earlier. POP proves to be highly predictive for the probe's future performance, ameliorating the sales forecasts of all state-of-the-art models on the recent VISUELLE fast-fashion dataset. We also show that POP reflects the ground-truth popularity of new styles (ensembles of clothing items) on the Fashion Forward benchmark, demonstrating that our webly-learned signal is a truthful expression of popularity, accessible by everyone and generalizable to any time of analysis. Forecasting code, data and the POP time series are available at: https://github.com/HumaticsLAB/POP-Mining-POtential-Performance
The Curious Layperson: Fine-Grained Image Recognition without Expert Labels
Nov 05, 2021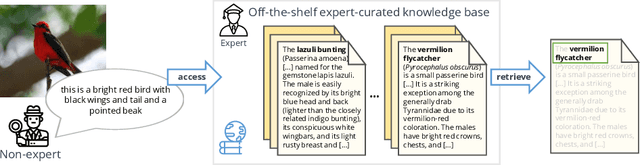
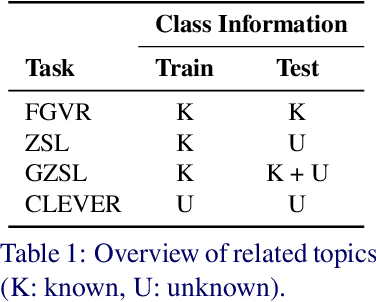
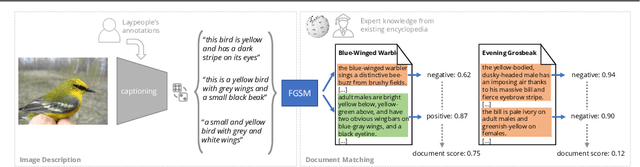
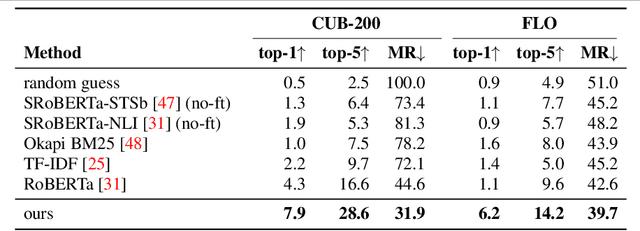
Most of us are not experts in specific fields, such as ornithology. Nonetheless, we do have general image and language understanding capabilities that we use to match what we see to expert resources. This allows us to expand our knowledge and perform novel tasks without ad-hoc external supervision. On the contrary, machines have a much harder time consulting expert-curated knowledge bases unless trained specifically with that knowledge in mind. Thus, in this paper we consider a new problem: fine-grained image recognition without expert annotations, which we address by leveraging the vast knowledge available in web encyclopedias. First, we learn a model to describe the visual appearance of objects using non-expert image descriptions. We then train a fine-grained textual similarity model that matches image descriptions with documents on a sentence-level basis. We evaluate the method on two datasets and compare with several strong baselines and the state of the art in cross-modal retrieval. Code is available at: https://github.com/subhc/clever
Distribution Learning Based on Evolutionary Algorithm Assisted Deep Neural Networks for Imbalanced Image Classification
Jul 26, 2022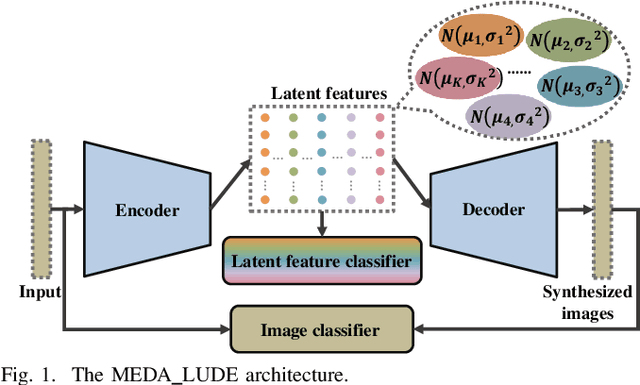
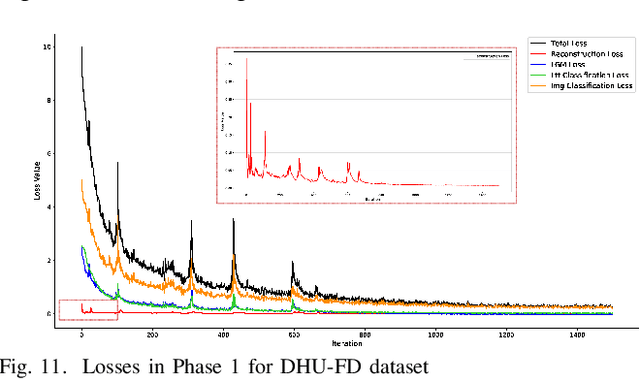
To address the trade-off problem of quality-diversity for the generated images in imbalanced classification tasks, we research on over-sampling based methods at the feature level instead of the data level and focus on searching the latent feature space for optimal distributions. On this basis, we propose an iMproved Estimation Distribution Algorithm based Latent featUre Distribution Evolution (MEDA_LUDE) algorithm, where a joint learning procedure is programmed to make the latent features both optimized and evolved by the deep neural networks and the evolutionary algorithm, respectively. We explore the effect of the Large-margin Gaussian Mixture (L-GM) loss function on distribution learning and design a specialized fitness function based on the similarities among samples to increase diversity. Extensive experiments on benchmark based imbalanced datasets validate the effectiveness of our proposed algorithm, which can generate images with both quality and diversity. Furthermore, the MEDA_LUDE algorithm is also applied to the industrial field and successfully alleviates the imbalanced issue in fabric defect classification.
Discover the Mysteries of the Maya: Selected Contributions from the Machine Learning Challenge & The Discovery Challenge Workshop at ECML PKDD 2021
Aug 05, 2022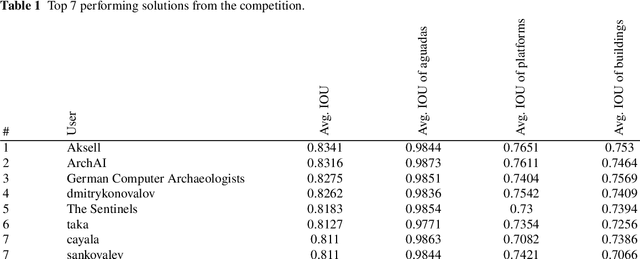
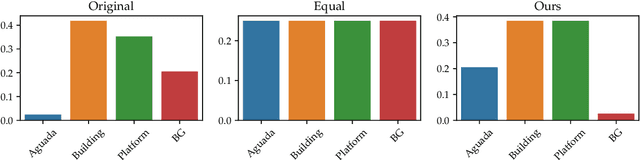


The volume contains selected contributions from the Machine Learning Challenge "Discover the Mysteries of the Maya", presented at the Discovery Challenge Track of The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD 2021). Remote sensing has greatly accelerated traditional archaeological landscape surveys in the forested regions of the ancient Maya. Typical exploration and discovery attempts, beside focusing on whole ancient cities, focus also on individual buildings and structures. Recently, there have been several successful attempts of utilizing machine learning for identifying ancient Maya settlements. These attempts, while relevant, focus on narrow areas and rely on high-quality aerial laser scanning (ALS) data which covers only a fraction of the region where ancient Maya were once settled. Satellite image data, on the other hand, produced by the European Space Agency's (ESA) Sentinel missions, is abundant and, more importantly, publicly available. The "Discover the Mysteries of the Maya" challenge aimed at locating and identifying ancient Maya architectures (buildings, aguadas, and platforms) by performing integrated image segmentation of different types of satellite imagery (from Sentinel-1 and Sentinel-2) data and ALS (lidar) data.
On Real-time Image Reconstruction with Neural Networks for MRI-guided Radiotherapy
Feb 10, 2022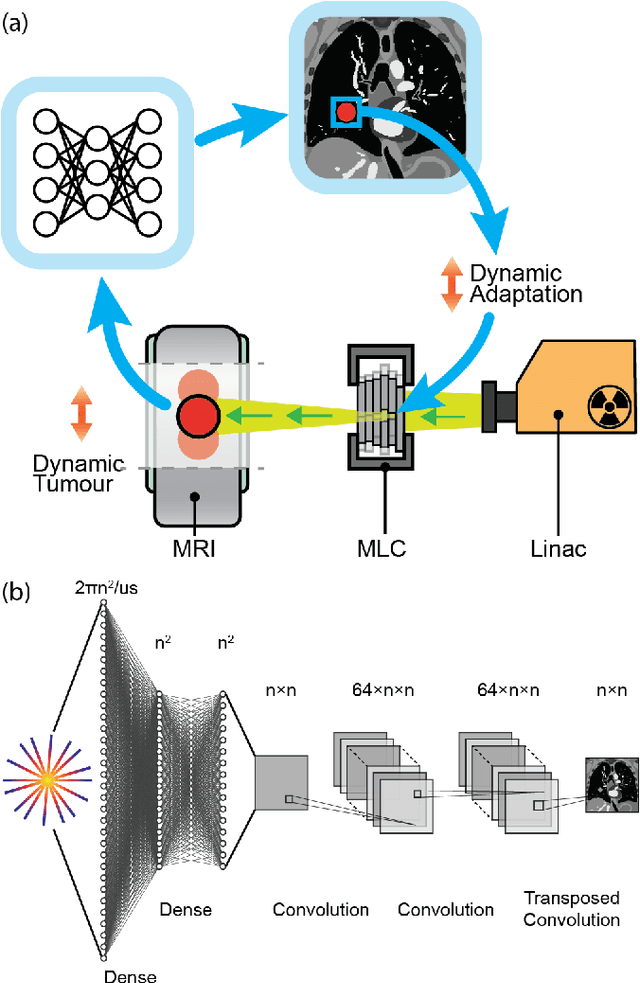
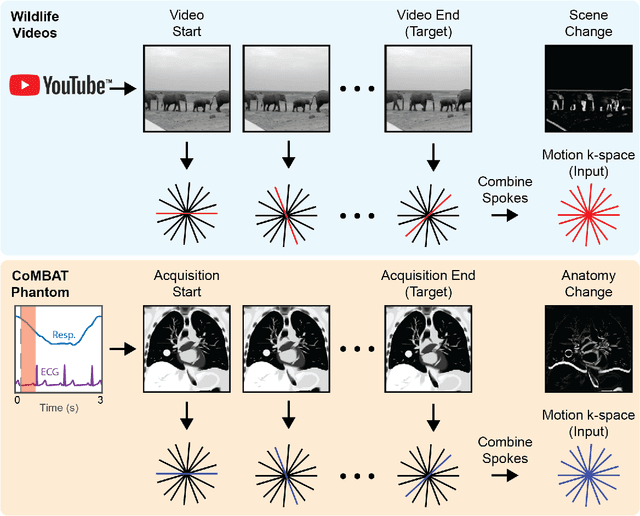
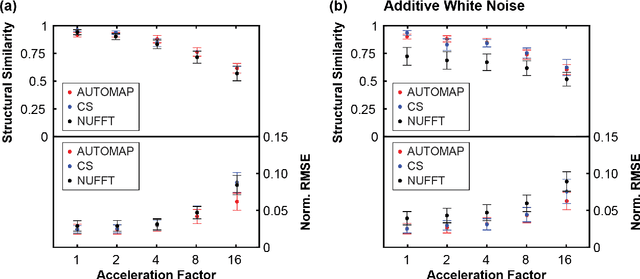
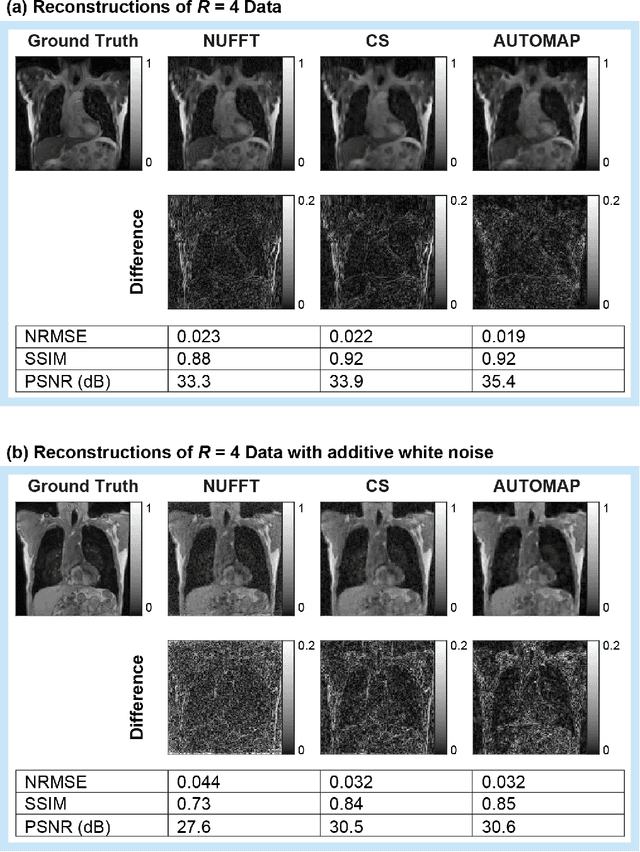
MRI-guidance techniques that dynamically adapt radiation beams to follow tumor motion in real-time will lead to more accurate cancer treatments and reduced collateral healthy tissue damage. The gold-standard for reconstruction of undersampled MR data is compressed sensing (CS) which is computationally slow and limits the rate that images can be available for real-time adaptation. Here, we demonstrate the use of automated transform by manifold approximation (AUTOMAP), a generalized framework that maps raw MR signal to the target image domain, to rapidly reconstruct images from undersampled radial k-space data. The AUTOMAP neural network was trained to reconstruct images from a golden-angle radial acquisition, a benchmark for motion-sensitive imaging, on lung cancer patient data and generic images from ImageNet. Model training was subsequently augmented with motion-encoded k-space data derived from videos in the YouTube-8M dataset to encourage motion robust reconstruction. We find that AUTOMAP-reconstructed radial k-space has equivalent accuracy to CS but with much shorter processing times after initial fine-tuning on retrospectively acquired lung cancer patient data. Validation of motion-trained models with a virtual dynamic lung tumor phantom showed that the generalized motion properties learned from YouTube lead to improved target tracking accuracy. Our work shows that AUTOMAP can achieve real-time, accurate reconstruction of radial data. These findings imply that neural-network-based reconstruction is potentially superior to existing approaches for real-time image guidance applications.
Injecting 3D Perception of Controllable NeRF-GAN into StyleGAN for Editable Portrait Image Synthesis
Jul 26, 2022

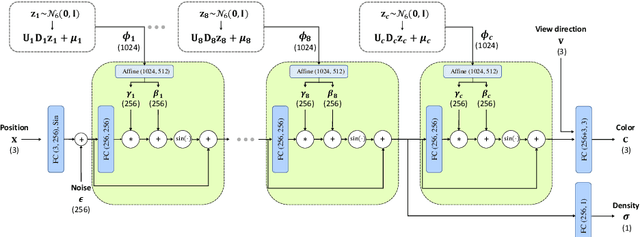
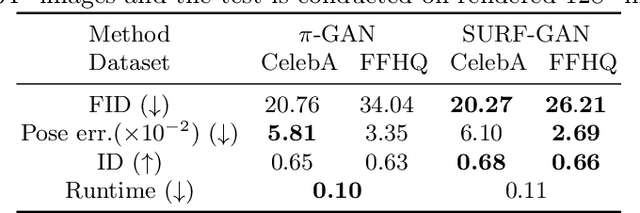
Over the years, 2D GANs have achieved great successes in photorealistic portrait generation. However, they lack 3D understanding in the generation process, thus they suffer from multi-view inconsistency problem. To alleviate the issue, many 3D-aware GANs have been proposed and shown notable results, but 3D GANs struggle with editing semantic attributes. The controllability and interpretability of 3D GANs have not been much explored. In this work, we propose two solutions to overcome these weaknesses of 2D GANs and 3D-aware GANs. We first introduce a novel 3D-aware GAN, SURF-GAN, which is capable of discovering semantic attributes during training and controlling them in an unsupervised manner. After that, we inject the prior of SURF-GAN into StyleGAN to obtain a high-fidelity 3D-controllable generator. Unlike existing latent-based methods allowing implicit pose control, the proposed 3D-controllable StyleGAN enables explicit pose control over portrait generation. This distillation allows direct compatibility between 3D control and many StyleGAN-based techniques (e.g., inversion and stylization), and also brings an advantage in terms of computational resources. Our codes are available at https://github.com/jgkwak95/SURF-GAN.
Monocular Human Shape and Pose with Dense Mesh-borne Local Image Features
Nov 10, 2021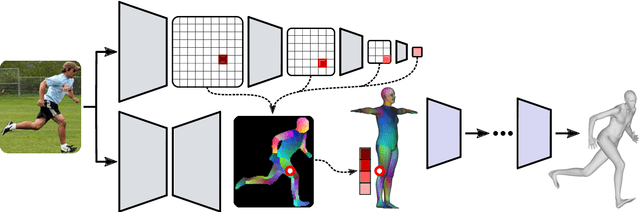

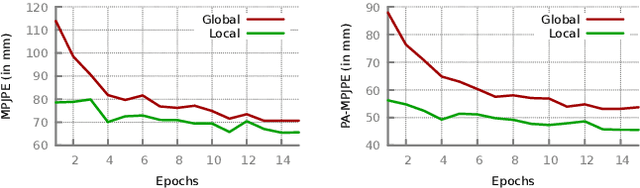
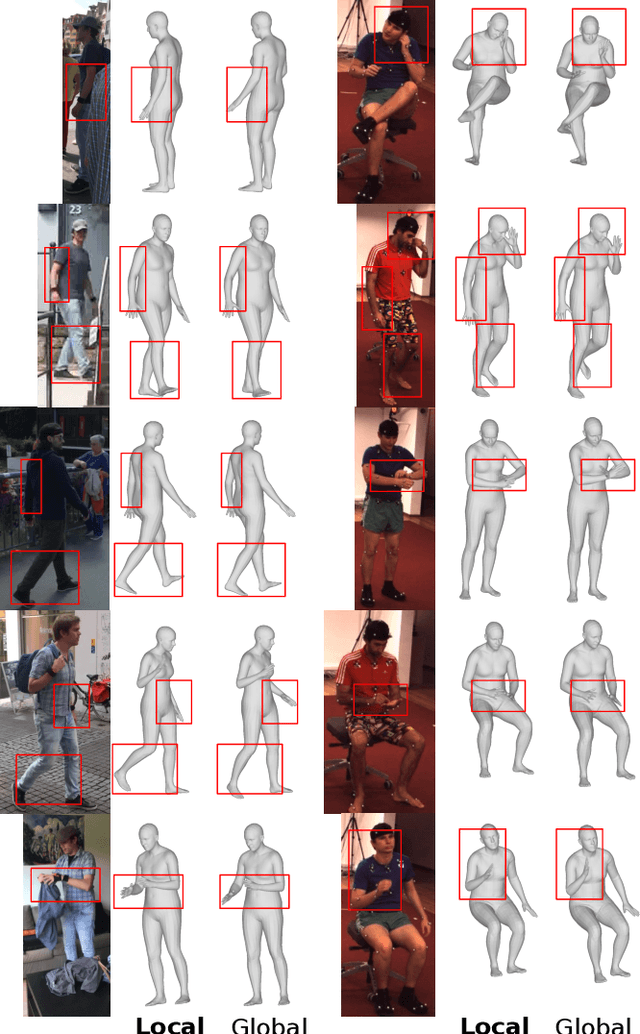
We propose to improve on graph convolution based approaches for human shape and pose estimation from monocular input, using pixel-aligned local image features. Given a single input color image, existing graph convolutional network (GCN) based techniques for human shape and pose estimation use a single convolutional neural network (CNN) generated global image feature appended to all mesh vertices equally to initialize the GCN stage, which transforms a template T-posed mesh into the target pose. In contrast, we propose for the first time the idea of using local image features per vertex. These features are sampled from the CNN image feature maps by utilizing pixel-to-mesh correspondences generated with DensePose. Our quantitative and qualitative results on standard benchmarks show that using local features improves on global ones and leads to competitive performances with respect to the state-of-the-art.