 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Based Early Warning of Vineyard Disease Risk from Environmental Time Series
May 06, 2026Accurate early warning of vineyard disease risk from environmental observations is essential for timely intervention and more sustainable crop protection. However, many existing studies formulate disease prediction as daily presence classification, which can favor persistence-driven predictions and provide only limited support for actionable short-horizon warning. In this paper, we present an event-based approach for early warning of vineyard disease risk from environmental time series and evaluate it through a vineyard case study. Rather than predicting daily disease status, the task is reformulated to predict transitions into annotated disease-risk periods within a future window of 3-7 days. To reduce fragmentation caused by short interruptions in the binary labels, new events are defined only after a minimum disease-free gap. This formulation encourages models to capture environmental precursors associated with upcoming risk periods instead of merely reproducing temporal persistence. Using multi-year agro-meteorological data, we construct input representations that capture humidity dynamics, rainfall accumulation, temperature variability, and seasonal structure through cyclic temporal encoding. We evaluate representative methods from classical machine learning and deep learning, including XGBoost, Long Short-Term Memory (LSTM) networks, and Temporal Convolutional Networks (TCNs), using both standard classification metrics and an event-oriented early warning protocol. The results show that the event-based formulation supports practical short-horizon warning, while the compared models exhibit distinct trade-offs between event recall, lead time, and false-alert behavior. Overall, the study underscores the importance of problem formulation in environmental time-series learning and demonstrates the value of event-based prediction for vineyard disease warning systems.
Deep Multimodal Fusion for Semantic Segmentation of Remote Sensing Earth Observation Data
Oct 01, 2024



Accurate semantic segmentation of remote sensing imagery is critical for various Earth observation applications, such as land cover mapping, urban planning, and environmental monitoring. However, individual data sources often present limitations for this task. Very High Resolution (VHR) aerial imagery provides rich spatial details but cannot capture temporal information about land cover changes. Conversely, Satellite Image Time Series (SITS) capture temporal dynamics, such as seasonal variations in vegetation, but with limited spatial resolution, making it difficult to distinguish fine-scale objects. This paper proposes a late fusion deep learning model (LF-DLM) for semantic segmentation that leverages the complementary strengths of both VHR aerial imagery and SITS. The proposed model consists of two independent deep learning branches. One branch integrates detailed textures from aerial imagery captured by UNetFormer with a Multi-Axis Vision Transformer (MaxViT) backbone. The other branch captures complex spatio-temporal dynamics from the Sentinel-2 satellite image time series using a U-Net with Temporal Attention Encoder (U-TAE). This approach leads to state-of-the-art results on the FLAIR dataset, a large-scale benchmark for land cover segmentation using multi-source optical imagery. The findings highlight the importance of multi-modality fusion in improving the accuracy and robustness of semantic segmentation in remote sensing applications.
Semantic Segmentation of Unmanned Aerial Vehicle Remote Sensing Images using SegFormer
Oct 01, 2024The escalating use of Unmanned Aerial Vehicles (UAVs) as remote sensing platforms has garnered considerable attention, proving invaluable for ground object recognition. While satellite remote sensing images face limitations in resolution and weather susceptibility, UAV remote sensing, employing low-speed unmanned aircraft, offers enhanced object resolution and agility. The advent of advanced machine learning techniques has propelled significant strides in image analysis, particularly in semantic segmentation for UAV remote sensing images. This paper evaluates the effectiveness and efficiency of SegFormer, a semantic segmentation framework, for the semantic segmentation of UAV images. SegFormer variants, ranging from real-time (B0) to high-performance (B5) models, are assessed using the UAVid dataset tailored for semantic segmentation tasks. The research details the architecture and training procedures specific to SegFormer in the context of UAV semantic segmentation. Experimental results showcase the model's performance on benchmark dataset, highlighting its ability to accurately delineate objects and land cover features in diverse UAV scenarios, leading to both high efficiency and performance.
In-Domain Self-Supervised Learning Can Lead to Improvements in Remote Sensing Image Classification
Jul 04, 2023


Self-supervised learning (SSL) has emerged as a promising approach for remote sensing image classification due to its ability to leverage large amounts of unlabeled data. In contrast to traditional supervised learning, SSL aims to learn representations of data without the need for explicit labels. This is achieved by formulating auxiliary tasks that can be used to create pseudo-labels for the unlabeled data and learn pre-trained models. The pre-trained models can then be fine-tuned on downstream tasks such as remote sensing image scene classification. The paper analyzes the effectiveness of SSL pre-training using Million AID - a large unlabeled remote sensing dataset on various remote sensing image scene classification datasets as downstream tasks. More specifically, we evaluate the effectiveness of SSL pre-training using the iBOT framework coupled with Vision transformers (ViT) in contrast to supervised pre-training of ViT using the ImageNet dataset. The comprehensive experimental work across 14 datasets with diverse properties reveals that in-domain SSL leads to improved predictive performance of models compared to the supervised counterparts.
Discover the Mysteries of the Maya: Selected Contributions from the Machine Learning Challenge & The Discovery Challenge Workshop at ECML PKDD 2021
Aug 09, 2022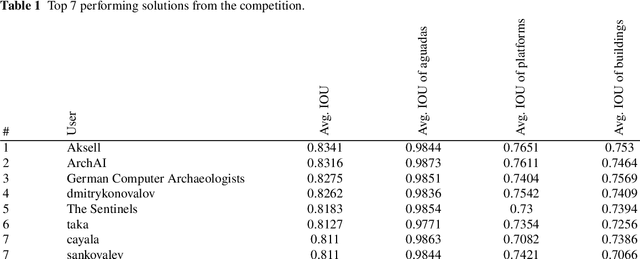
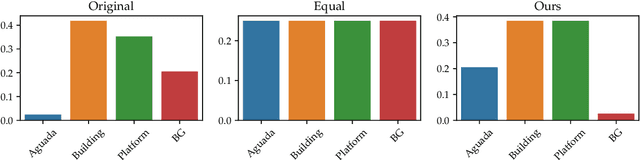


The volume contains selected contributions from the Machine Learning Challenge "Discover the Mysteries of the Maya", presented at the Discovery Challenge Track of The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD 2021). Remote sensing has greatly accelerated traditional archaeological landscape surveys in the forested regions of the ancient Maya. Typical exploration and discovery attempts, beside focusing on whole ancient cities, focus also on individual buildings and structures. Recently, there have been several successful attempts of utilizing machine learning for identifying ancient Maya settlements. These attempts, while relevant, focus on narrow areas and rely on high-quality aerial laser scanning (ALS) data which covers only a fraction of the region where ancient Maya were once settled. Satellite image data, on the other hand, produced by the European Space Agency's (ESA) Sentinel missions, is abundant and, more importantly, publicly available. The "Discover the Mysteries of the Maya" challenge aimed at locating and identifying ancient Maya architectures (buildings, aguadas, and platforms) by performing integrated image segmentation of different types of satellite imagery (from Sentinel-1 and Sentinel-2) data and ALS (lidar) data.
Current Trends in Deep Learning for Earth Observation: An Open-source Benchmark Arena for Image Classification
Jul 14, 2022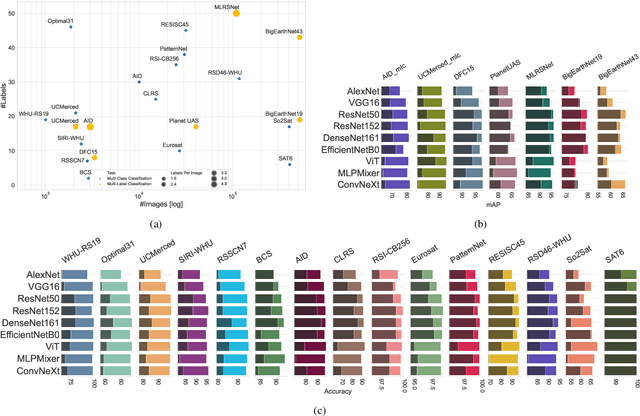
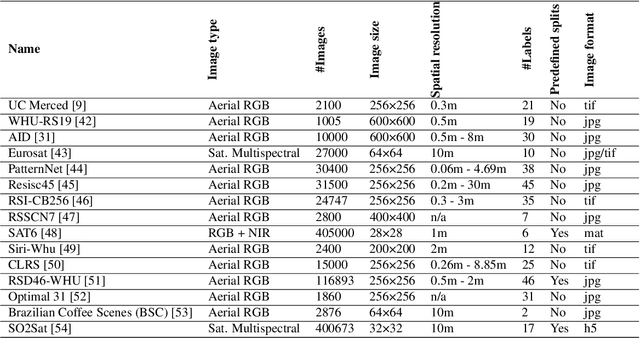
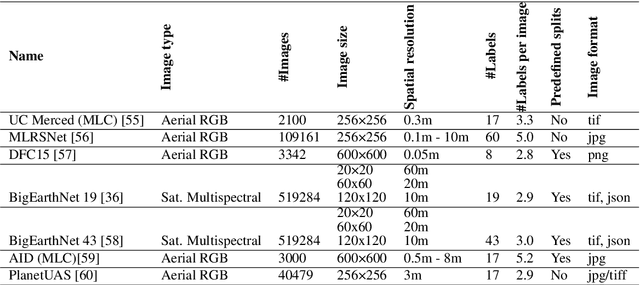
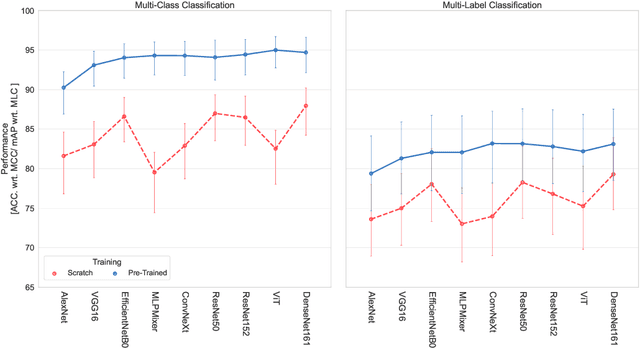
We present 'AiTLAS: Benchmark Arena' -- an open-source benchmark framework for evaluating state-of-the-art deep learning approaches for image classification in Earth Observation (EO). To this end, we present a comprehensive comparative analysis of more than 400 models derived from nine different state-of-the-art architectures, and compare them to a variety of multi-class and multi-label classification tasks from 22 datasets with different sizes and properties. In addition to models trained entirely on these datasets, we also benchmark models trained in the context of transfer learning, leveraging pre-trained model variants, as it is typically performed in practice. All presented approaches are general and can be easily extended to many other remote sensing image classification tasks not considered in this study. To ensure reproducibility and facilitate better usability and further developments, all of the experimental resources including the trained models, model configurations and processing details of the datasets (with their corresponding splits used for training and evaluating the models) are publicly available on the repository: https://github.com/biasvariancelabs/aitlas-arena.
AiTLAS: Artificial Intelligence Toolbox for Earth Observation
Jan 21, 2022
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which further allows benchmarking of various existing and novel AI methods tailored for EO data.
Addressing Item-Cold Start Problem in Recommendation Systems using Model Based Approach and Deep Learning
Jun 18, 2017
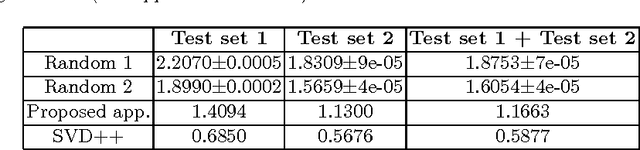
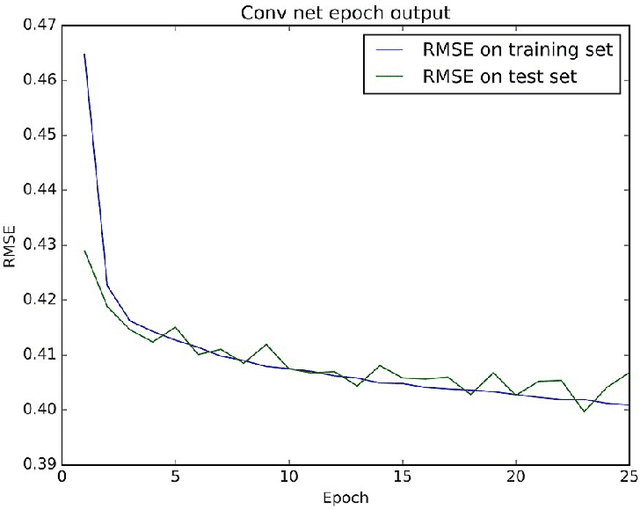
Traditional recommendation systems rely on past usage data in order to generate new recommendations. Those approaches fail to generate sensible recommendations for new users and items into the system due to missing information about their past interactions. In this paper, we propose a solution for successfully addressing item-cold start problem which uses model-based approach and recent advances in deep learning. In particular, we use latent factor model for recommendation, and predict the latent factors from item's descriptions using convolutional neural network when they cannot be obtained from usage data. Latent factors obtained by applying matrix factorization to the available usage data are used as ground truth to train the convolutional neural network. To create latent factor representations for the new items, the convolutional neural network uses their textual description. The results from the experiments reveal that the proposed approach significantly outperforms several baseline estimators.