 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparfels: Fast Reconstruction from Sparse Unposed Imagery
May 04, 2025We present a method for Sparse view reconstruction with surface element splatting that runs within 3 minutes on a consumer grade GPU. While few methods address sparse radiance field learning from noisy or unposed sparse cameras, shape recovery remains relatively underexplored in this setting. Several radiance and shape learning test-time optimization methods address the sparse posed setting by learning data priors or using combinations of external monocular geometry priors. Differently, we propose an efficient and simple pipeline harnessing a single recent 3D foundation model. We leverage its various task heads, notably point maps and camera initializations to instantiate a bundle adjusting 2D Gaussian Splatting (2DGS) model, and image correspondences to guide camera optimization midst 2DGS training. Key to our contribution is a novel formulation of splatted color variance along rays, which can be computed efficiently. Reducing this moment in training leads to more accurate shape reconstructions. We demonstrate state-of-the-art performances in the sparse uncalibrated setting in reconstruction and novel view benchmarks based on established multi-view datasets.
SparSplat: Fast Multi-View Reconstruction with Generalizable 2D Gaussian Splatting
May 04, 2025Recovering 3D information from scenes via multi-view stereo reconstruction (MVS) and novel view synthesis (NVS) is inherently challenging, particularly in scenarios involving sparse-view setups. The advent of 3D Gaussian Splatting (3DGS) enabled real-time, photorealistic NVS. Following this, 2D Gaussian Splatting (2DGS) leveraged perspective accurate 2D Gaussian primitive rasterization to achieve accurate geometry representation during rendering, improving 3D scene reconstruction while maintaining real-time performance. Recent approaches have tackled the problem of sparse real-time NVS using 3DGS within a generalizable, MVS-based learning framework to regress 3D Gaussian parameters. Our work extends this line of research by addressing the challenge of generalizable sparse 3D reconstruction and NVS jointly, and manages to perform successfully at both tasks. We propose an MVS-based learning pipeline that regresses 2DGS surface element parameters in a feed-forward fashion to perform 3D shape reconstruction and NVS from sparse-view images. We further show that our generalizable pipeline can benefit from preexisting foundational multi-view deep visual features. The resulting model attains the state-of-the-art results on the DTU sparse 3D reconstruction benchmark in terms of Chamfer distance to ground-truth, as-well as state-of-the-art NVS. It also demonstrates strong generalization on the BlendedMVS and Tanks and Temples datasets. We note that our model outperforms the prior state-of-the-art in feed-forward sparse view reconstruction based on volume rendering of implicit representations, while offering an almost 2 orders of magnitude higher inference speed.
Toward Robust Neural Reconstruction from Sparse Point Sets
Dec 20, 2024



We consider the challenging problem of learning Signed Distance Functions (SDF) from sparse and noisy 3D point clouds. In contrast to recent methods that depend on smoothness priors, our method, rooted in a distributionally robust optimization (DRO) framework, incorporates a regularization term that leverages samples from the uncertainty regions of the model to improve the learned SDFs. Thanks to tractable dual formulations, we show that this framework enables a stable and efficient optimization of SDFs in the absence of ground truth supervision. Using a variety of synthetic and real data evaluations from different modalities, we show that our DRO based learning framework can improve SDF learning with respect to baselines and the state-of-the-art methods.
GeoTransfer : Generalizable Few-Shot Multi-View Reconstruction via Transfer Learning
Aug 27, 2024This paper presents a novel approach for sparse 3D reconstruction by leveraging the expressive power of Neural Radiance Fields (NeRFs) and fast transfer of their features to learn accurate occupancy fields. Existing 3D reconstruction methods from sparse inputs still struggle with capturing intricate geometric details and can suffer from limitations in handling occluded regions. On the other hand, NeRFs excel in modeling complex scenes but do not offer means to extract meaningful geometry. Our proposed method offers the best of both worlds by transferring the information encoded in NeRF features to derive an accurate occupancy field representation. We utilize a pre-trained, generalizable state-of-the-art NeRF network to capture detailed scene radiance information, and rapidly transfer this knowledge to train a generalizable implicit occupancy network. This process helps in leveraging the knowledge of the scene geometry encoded in the generalizable NeRF prior and refining it to learn occupancy fields, facilitating a more precise generalizable representation of 3D space. The transfer learning approach leads to a dramatic reduction in training time, by orders of magnitude (i.e. from several days to 3.5 hrs), obviating the need to train generalizable sparse surface reconstruction methods from scratch. Additionally, we introduce a novel loss on volumetric rendering weights that helps in the learning of accurate occupancy fields, along with a normal loss that helps in global smoothing of the occupancy fields. We evaluate our approach on the DTU dataset and demonstrate state-of-the-art performance in terms of reconstruction accuracy, especially in challenging scenarios with sparse input data and occluded regions. We furthermore demonstrate the generalization capabilities of our method by showing qualitative results on the Blended MVS dataset without any retraining.
Neural Mesh-Based Graphics
Aug 23, 2022
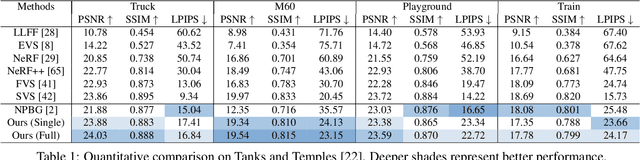


We revisit NPBG, the popular approach to novel view synthesis that introduced the ubiquitous point feature neural rendering paradigm. We are interested in particular in data-efficient learning with fast view synthesis. We achieve this through a view-dependent mesh-based denser point descriptor rasterization, in addition to a foreground/background scene rendering split, and an improved loss. By training solely on a single scene, we outperform NPBG, which has been trained on ScanNet and then scene finetuned. We also perform competitively with respect to the state-of-the-art method SVS, which has been trained on the full dataset (DTU and Tanks and Temples) and then scene finetuned, in spite of their deeper neural renderer.
Monocular Human Shape and Pose with Dense Mesh-borne Local Image Features
Nov 11, 2021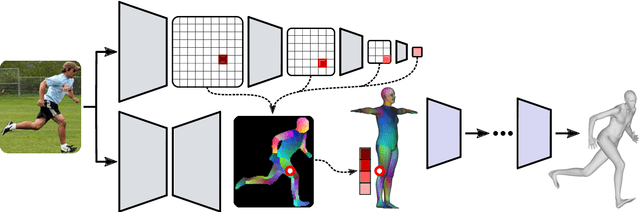

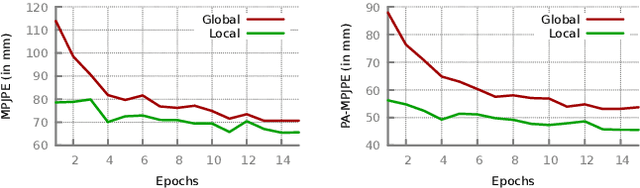
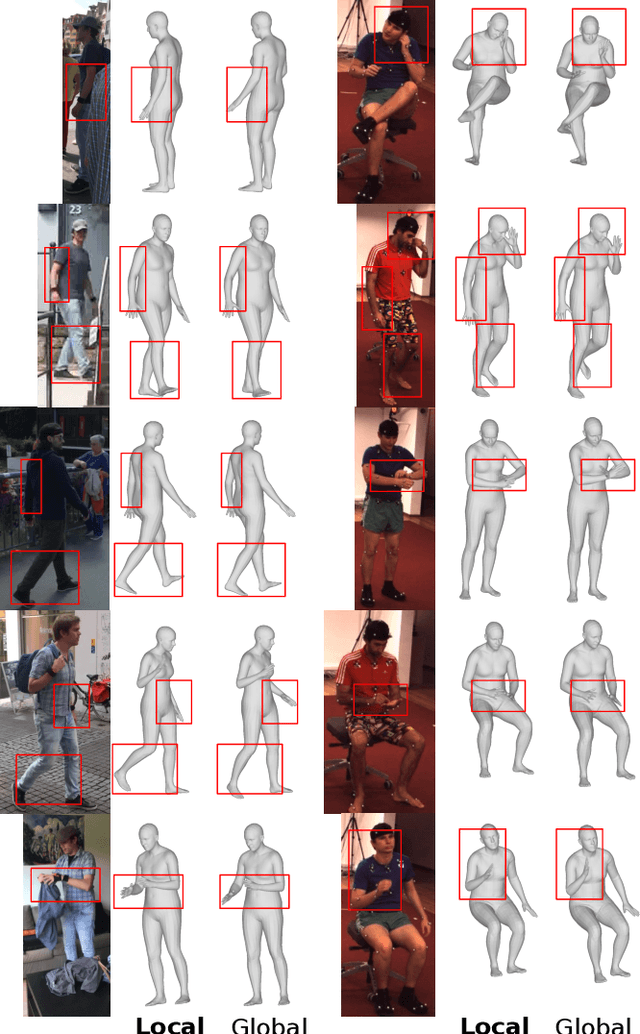
We propose to improve on graph convolution based approaches for human shape and pose estimation from monocular input, using pixel-aligned local image features. Given a single input color image, existing graph convolutional network (GCN) based techniques for human shape and pose estimation use a single convolutional neural network (CNN) generated global image feature appended to all mesh vertices equally to initialize the GCN stage, which transforms a template T-posed mesh into the target pose. In contrast, we propose for the first time the idea of using local image features per vertex. These features are sampled from the CNN image feature maps by utilizing pixel-to-mesh correspondences generated with DensePose. Our quantitative and qualitative results on standard benchmarks show that using local features improves on global ones and leads to competitive performances with respect to the state-of-the-art.