 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Memory-based Adapters for Online 3D Scene Perception
Mar 11, 2024
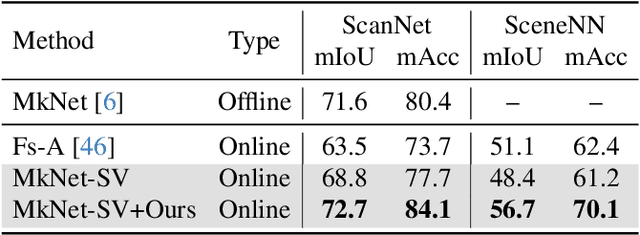
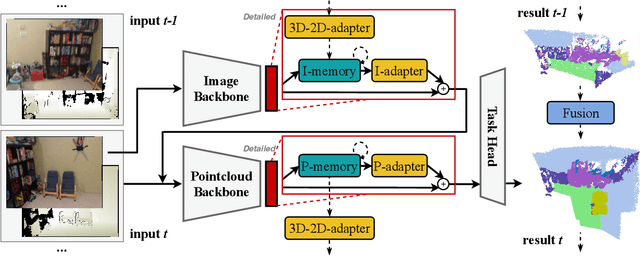
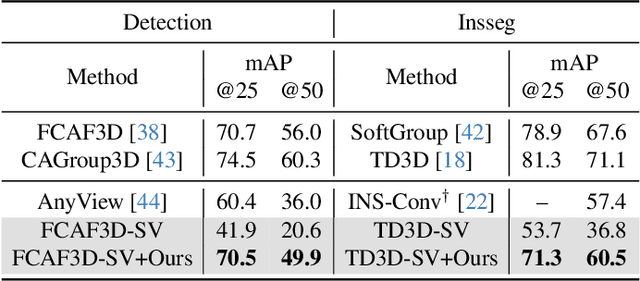
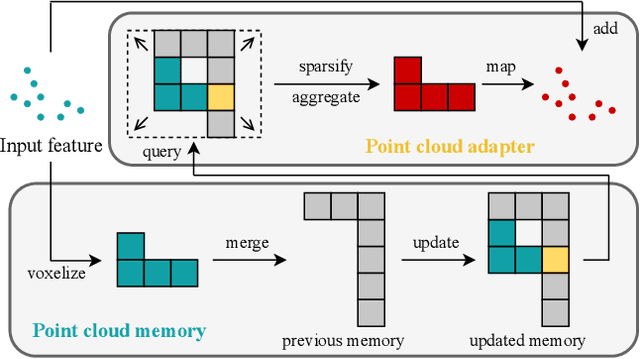
In this paper, we propose a new framework for online 3D scene perception. Conventional 3D scene perception methods are offline, i.e., take an already reconstructed 3D scene geometry as input, which is not applicable in robotic applications where the input data is streaming RGB-D videos rather than a complete 3D scene reconstructed from pre-collected RGB-D videos. To deal with online 3D scene perception tasks where data collection and perception should be performed simultaneously, the model should be able to process 3D scenes frame by frame and make use of the temporal information. To this end, we propose an adapter-based plug-and-play module for the backbone of 3D scene perception model, which constructs memory to cache and aggregate the extracted RGB-D features to empower offline models with temporal learning ability. Specifically, we propose a queued memory mechanism to cache the supporting point cloud and image features. Then we devise aggregation modules which directly perform on the memory and pass temporal information to current frame. We further propose 3D-to-2D adapter to enhance image features with strong global context. Our adapters can be easily inserted into mainstream offline architectures of different tasks and significantly boost their performance on online tasks. Extensive experiments on ScanNet and SceneNN datasets demonstrate our approach achieves leading performance on three 3D scene perception tasks compared with state-of-the-art online methods by simply finetuning existing offline models, without any model and task-specific designs. \href{https://xuxw98.github.io/Online3D/}{Project page}.
A Probabilistic Hadamard U-Net for MRI Bias Field Correction
Mar 08, 2024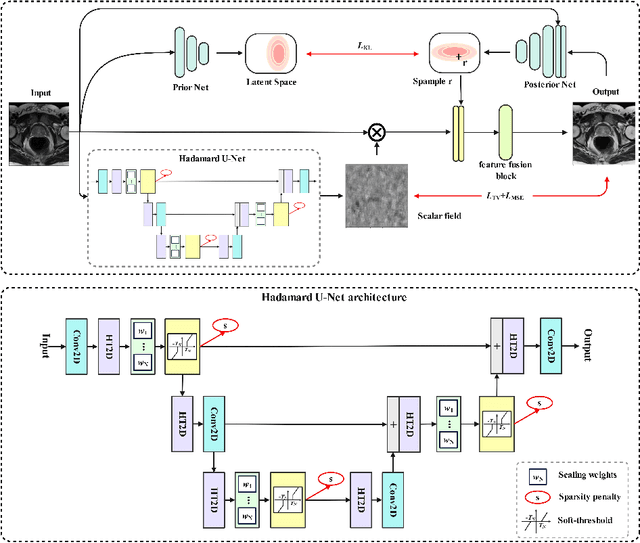
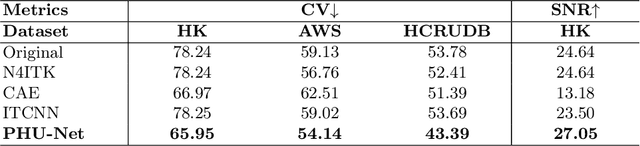
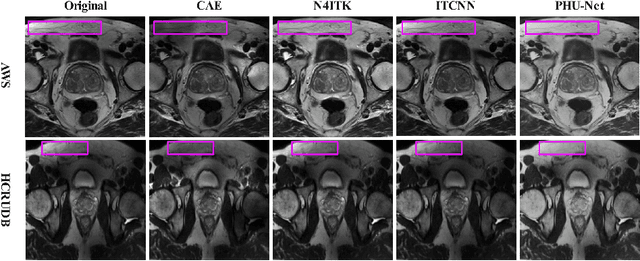
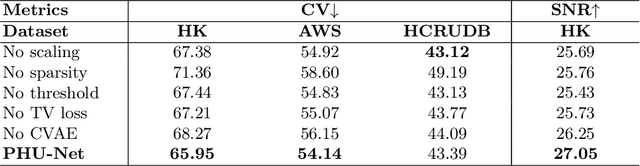
Magnetic field inhomogeneity correction remains a challenging task in MRI analysis. Most established techniques are designed for brain MRI by supposing that image intensities in the identical tissue follow a uniform distribution. Such an assumption cannot be easily applied to other organs, especially those that are small in size and heterogeneous in texture (large variations in intensity), such as the prostate. To address this problem, this paper proposes a probabilistic Hadamard U-Net (PHU-Net) for prostate MRI bias field correction. First, a novel Hadamard U-Net (HU-Net) is introduced to extract the low-frequency scalar field, multiplied by the original input to obtain the prototypical corrected image. HU-Net converts the input image from the time domain into the frequency domain via Hadamard transform. In the frequency domain, high-frequency components are eliminated using the trainable filter (scaling layer), hard-thresholding layer, and sparsity penalty. Next, a conditional variational autoencoder is used to encode possible bias field-corrected variants into a low-dimensional latent space. Random samples drawn from latent space are then incorporated with a prototypical corrected image to generate multiple plausible images. Experimental results demonstrate the effectiveness of PHU-Net in correcting bias-field in prostate MRI with a fast inference speed. It has also been shown that prostate MRI segmentation accuracy improves with the high-quality corrected images from PHU-Net. The code will be available in the final version of this manuscript.
ReStainGAN: Leveraging IHC to IF Stain Domain Translation for in-silico Data Generation
Mar 11, 2024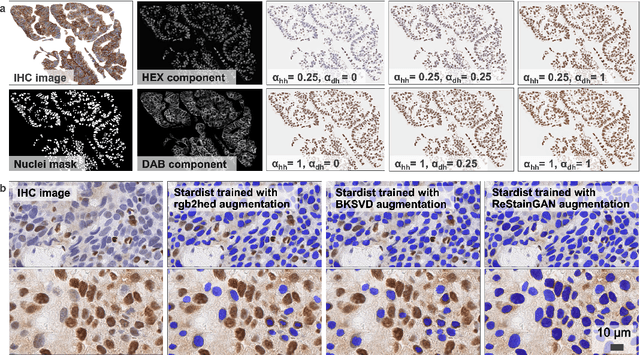
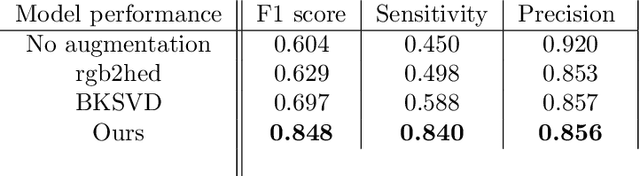
The creation of in-silico datasets can expand the utility of existing annotations to new domains with different staining patterns in computational pathology. As such, it has the potential to significantly lower the cost associated with building large and pixel precise datasets needed to train supervised deep learning models. We propose a novel approach for the generation of in-silico immunohistochemistry (IHC) images by disentangling morphology specific IHC stains into separate image channels in immunofluorescence (IF) images. The proposed approach qualitatively and quantitatively outperforms baseline methods as proven by training nucleus segmentation models on the created in-silico datasets.
Consolidating Attention Features for Multi-view Image Editing
Feb 22, 2024Large-scale text-to-image models enable a wide range of image editing techniques, using text prompts or even spatial controls. However, applying these editing methods to multi-view images depicting a single scene leads to 3D-inconsistent results. In this work, we focus on spatial control-based geometric manipulations and introduce a method to consolidate the editing process across various views. We build on two insights: (1) maintaining consistent features throughout the generative process helps attain consistency in multi-view editing, and (2) the queries in self-attention layers significantly influence the image structure. Hence, we propose to improve the geometric consistency of the edited images by enforcing the consistency of the queries. To do so, we introduce QNeRF, a neural radiance field trained on the internal query features of the edited images. Once trained, QNeRF can render 3D-consistent queries, which are then softly injected back into the self-attention layers during generation, greatly improving multi-view consistency. We refine the process through a progressive, iterative method that better consolidates queries across the diffusion timesteps. We compare our method to a range of existing techniques and demonstrate that it can achieve better multi-view consistency and higher fidelity to the input scene. These advantages allow us to train NeRFs with fewer visual artifacts, that are better aligned with the target geometry.
Solving the bongard-logo problem by modeling a probabilistic model
Mar 09, 2024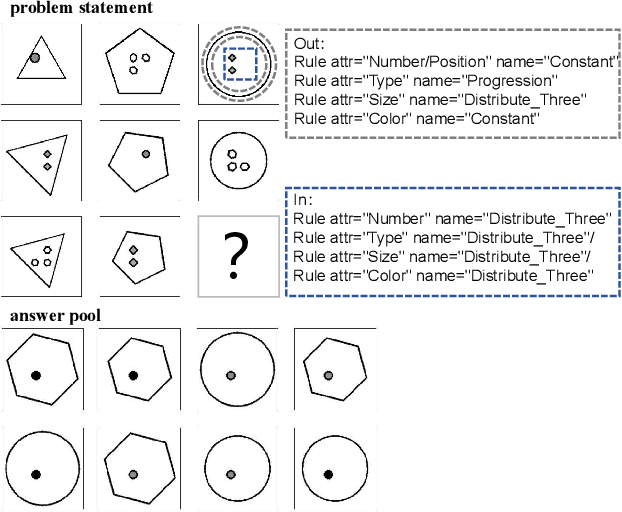
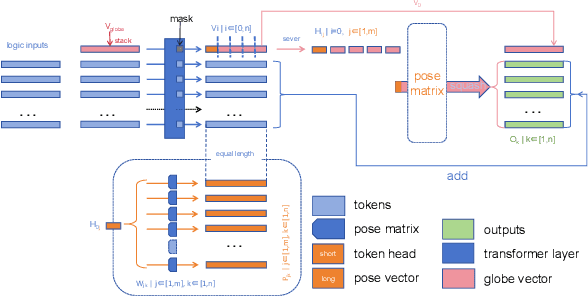
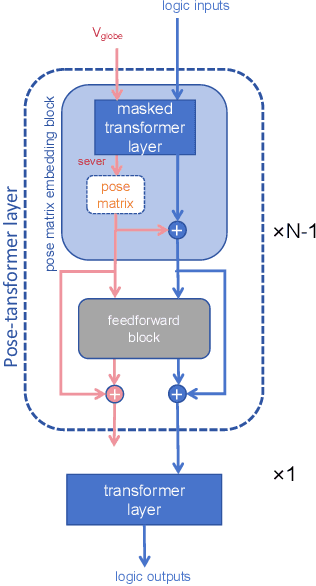
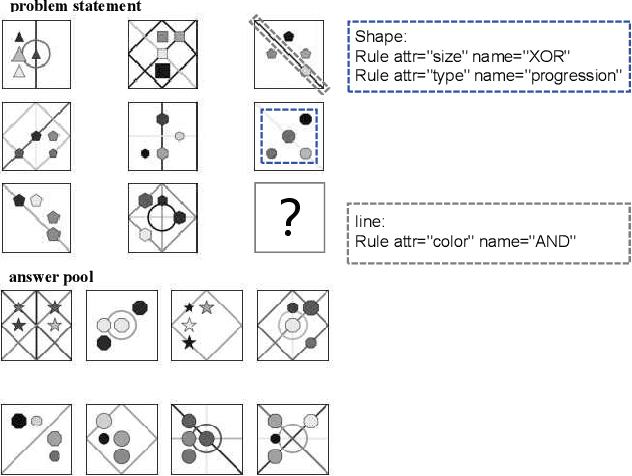
Abstract reasoning problems challenge the perceptual and cognitive abilities of AI algorithms, demanding deeper pattern discernment and inductive reasoning beyond explicit image features. This study introduces PMoC, a tailored probability model for the Bongard-Logo problem, achieving high reasoning accuracy by constructing independent probability models. Additionally, we present Pose-Transformer, an enhanced Transformer-Encoder designed for complex abstract reasoning tasks, including Bongard-Logo, RAVEN, I-RAVEN, and PGM. Pose-Transformer incorporates positional information learning, inspired by capsule networks' pose matrices, enhancing its focus on local positional relationships in image data processing. When integrated with PMoC, it further improves reasoning accuracy. Our approach effectively addresses reasoning difficulties associated with abstract entities' positional changes, outperforming previous models on the OIG, D3$\times$3 subsets of RAVEN, and PGM databases. This research contributes to advancing AI's capabilities in abstract reasoning and cognitive pattern recognition.
MMSR: Symbolic Regression is a Multimodal Task
Mar 14, 2024Mathematical formulas are the crystallization of human wisdom in exploring the laws of nature for thousands of years. Describing the complex laws of nature with a concise mathematical formula is a constant pursuit of scientists and a great challenge for artificial intelligence. This field is called symbolic regression. Symbolic regression was originally formulated as a combinatorial optimization problem, and GP and reinforcement learning algorithms were used to solve it. However, GP is sensitive to hyperparameters, and these two types of algorithms are inefficient. To solve this problem, researchers treat the mapping from data to expressions as a translation problem. And the corresponding large-scale pre-trained model is introduced. However, the data and expression skeletons do not have very clear word correspondences as the two languages do. Instead, they are more like two modalities (e.g., image and text). Therefore, in this paper, we proposed MMSR. The SR problem is solved as a pure multimodal problem, and contrastive learning is also introduced in the training process for modal alignment to facilitate later modal feature fusion. It is worth noting that in order to better promote the modal feature fusion, we adopt the strategy of training contrastive learning loss and other losses at the same time, which only needs one-step training, instead of training contrastive learning loss first and then training other losses. Because our experiments prove training together can make the feature extraction module and feature fusion module running-in better. Experimental results show that compared with multiple large-scale pre-training baselines, MMSR achieves the most advanced results on multiple mainstream datasets including SRBench.
Generalizable Whole Slide Image Classification with Fine-Grained Visual-Semantic Interaction
Feb 29, 2024Whole Slide Image (WSI) classification is often formulated as a Multiple Instance Learning (MIL) problem. Recently, Vision-Language Models (VLMs) have demonstrated remarkable performance in WSI classification. However, existing methods leverage coarse-grained pathogenetic descriptions for visual representation supervision, which are insufficient to capture the complex visual appearance of pathogenetic images, hindering the generalizability of models on diverse downstream tasks. Additionally, processing high-resolution WSIs can be computationally expensive. In this paper, we propose a novel "Fine-grained Visual-Semantic Interaction" (FiVE) framework for WSI classification. It is designed to enhance the model's generalizability by leveraging the interplay between localized visual patterns and fine-grained pathological semantics. Specifically, with meticulously designed queries, we start by utilizing a large language model to extract fine-grained pathological descriptions from various non-standardized raw reports. The output descriptions are then reconstructed into fine-grained labels used for training. By introducing a Task-specific Fine-grained Semantics (TFS) module, we enable prompts to capture crucial visual information in WSIs, which enhances representation learning and augments generalization capabilities significantly. Furthermore, given that pathological visual patterns are redundantly distributed across tissue slices, we sample a subset of visual instances during training. Our method demonstrates robust generalizability and strong transferability, dominantly outperforming the counterparts on the TCGA Lung Cancer dataset with at least 9.19% higher accuracy in few-shot experiments.
CN-RMA: Combined Network with Ray Marching Aggregation for 3D Indoors Object Detection from Multi-view Images
Mar 07, 2024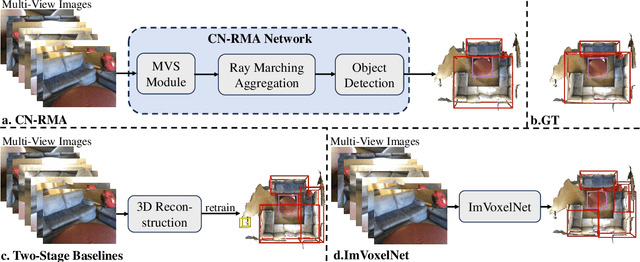
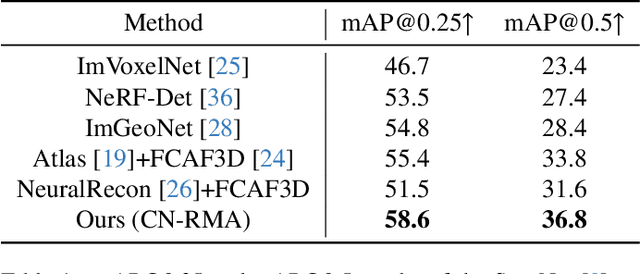
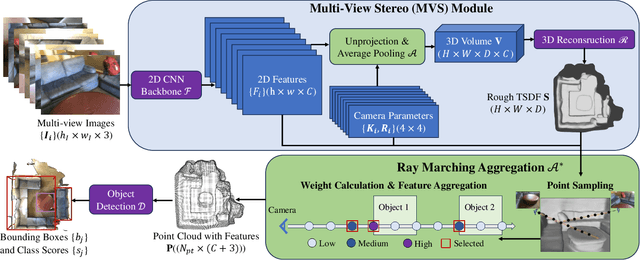
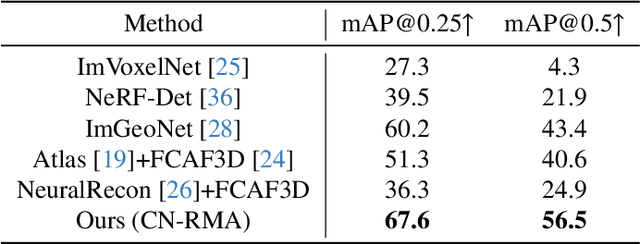
This paper introduces CN-RMA, a novel approach for 3D indoor object detection from multi-view images. We observe the key challenge as the ambiguity of image and 3D correspondence without explicit geometry to provide occlusion information. To address this issue, CN-RMA leverages the synergy of 3D reconstruction networks and 3D object detection networks, where the reconstruction network provides a rough Truncated Signed Distance Function (TSDF) and guides image features to vote to 3D space correctly in an end-to-end manner. Specifically, we associate weights to sampled points of each ray through ray marching, representing the contribution of a pixel in an image to corresponding 3D locations. Such weights are determined by the predicted signed distances so that image features vote only to regions near the reconstructed surface. Our method achieves state-of-the-art performance in 3D object detection from multi-view images, as measured by mAP@0.25 and mAP@0.5 on the ScanNet and ARKitScenes datasets. The code and models are released at https://github.com/SerCharles/CN-RMA.
MedFLIP: Medical Vision-and-Language Self-supervised Fast Pre-Training with Masked Autoencoder
Mar 07, 2024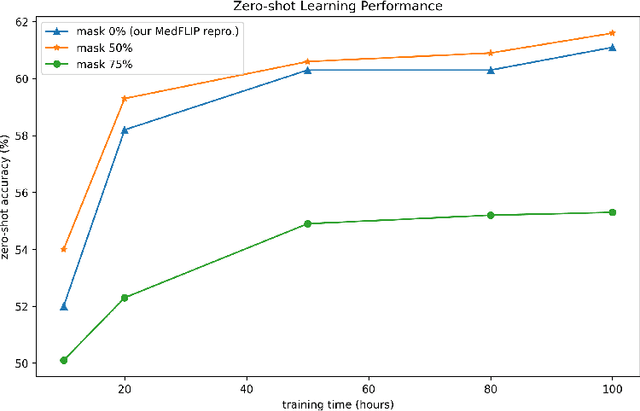
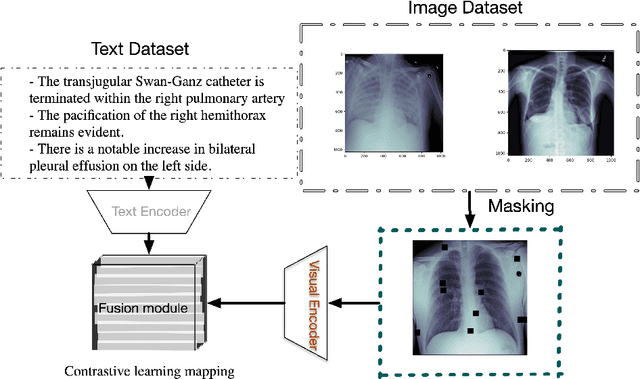

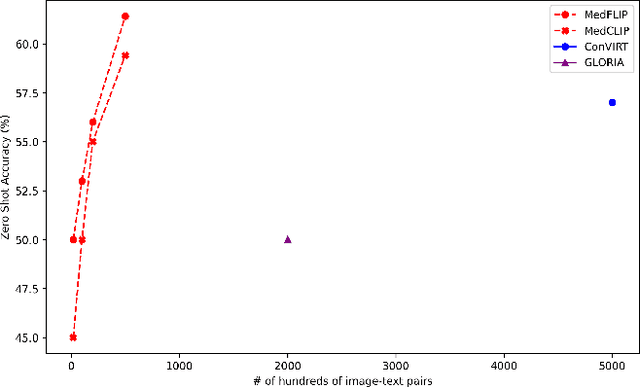
Within the domain of medical analysis, extensive research has explored the potential of mutual learning between Masked Autoencoders(MAEs) and multimodal data. However, the impact of MAEs on intermodality remains a key challenge. We introduce MedFLIP, a Fast Language-Image Pre-training method for Medical analysis. We explore MAEs for zero-shot learning with crossed domains, which enhances the model ability to learn from limited data, a common scenario in medical diagnostics. We verify that masking an image does not affect intermodal learning. Furthermore, we propose the SVD loss to enhance the representation learning for characteristics of medical images, aiming to improve classification accuracy by leveraging the structural intricacies of such data. Lastly, we validate using language will improve the zero-shot performance for the medical image analysis. MedFLIP scaling of the masking process marks an advancement in the field, offering a pathway to rapid and precise medical image analysis without the traditional computational bottlenecks. Through experiments and validation, MedFLIP demonstrates efficient performance improvements, setting an explored standard for future research and application in medical diagnostics.
Applicability of oculomics for individual risk prediction: Repeatability and robustness of retinal Fractal Dimension using DART and AutoMorph
Mar 11, 2024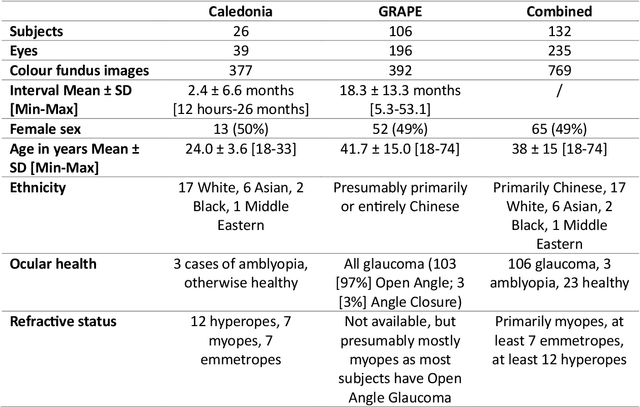
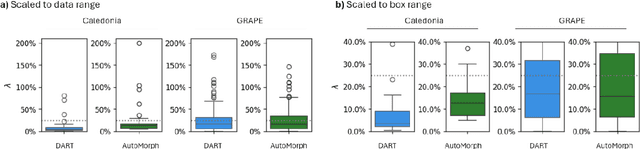
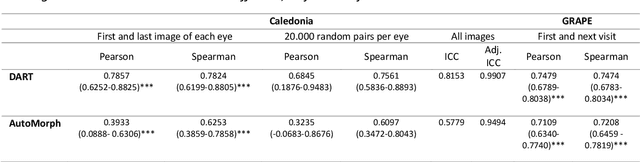
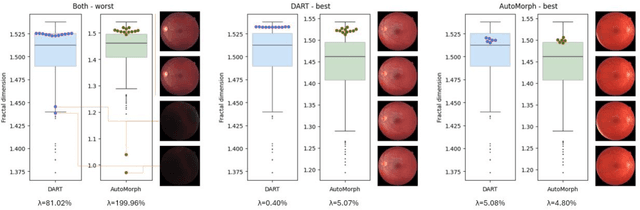
Purpose: To investigate whether Fractal Dimension (FD)-based oculomics could be used for individual risk prediction by evaluating repeatability and robustness. Methods: We used two datasets: Caledonia, healthy adults imaged multiple times in quick succession for research (26 subjects, 39 eyes, 377 colour fundus images), and GRAPE, glaucoma patients with baseline and follow-up visits (106 subjects, 196 eyes, 392 images). Mean follow-up time was 18.3 months in GRAPE, thus it provides a pessimistic lower-bound as vasculature could change. FD was computed with DART and AutoMorph. Image quality was assessed with QuickQual, but no images were initially excluded. Pearson, Spearman, and Intraclass Correlation (ICC) were used for population-level repeatability. For individual-level repeatability, we introduce measurement noise parameter {\lambda} which is within-eye Standard Deviation (SD) of FD measurements in units of between-eyes SD. Results: In Caledonia, ICC was 0.8153 for DART and 0.5779 for AutoMorph, Pearson/Spearman correlation (first and last image) 0.7857/0.7824 for DART, and 0.3933/0.6253 for AutoMorph. In GRAPE, Pearson/Spearman correlation (first and next visit) was 0.7479/0.7474 for DART, and 0.7109/0.7208 for AutoMorph (all p<0.0001). Median {\lambda} in Caledonia without exclusions was 3.55\% for DART and 12.65\% for AutoMorph, and improved to up to 1.67\% and 6.64\% with quality-based exclusions, respectively. Quality exclusions primarily mitigated large outliers. Worst quality in an eye correlated strongly with {\lambda} (Pearson 0.5350-0.7550, depending on dataset and method, all p<0.0001). Conclusions: Repeatability was sufficient for individual-level predictions in heterogeneous populations. DART performed better on all metrics and might be able to detect small, longitudinal changes, highlighting the potential of robust methods.