 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BoostMIS: Boosting Medical Image Semi-supervised Learning with Adaptive Pseudo Labeling and Informative Active Annotation
Mar 04, 2022
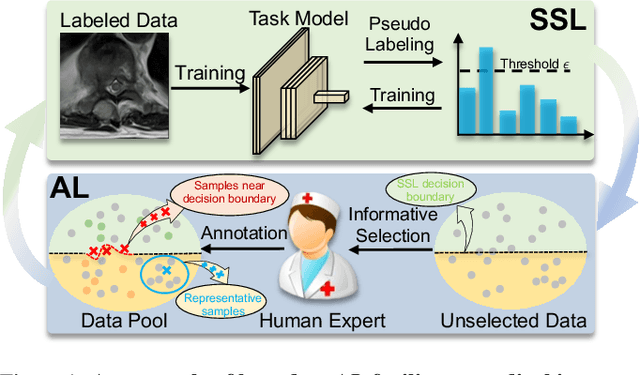
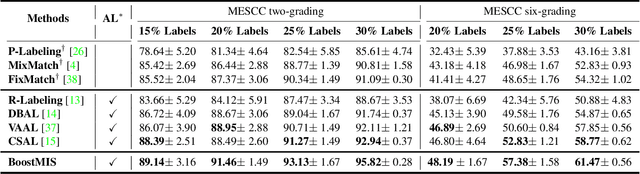
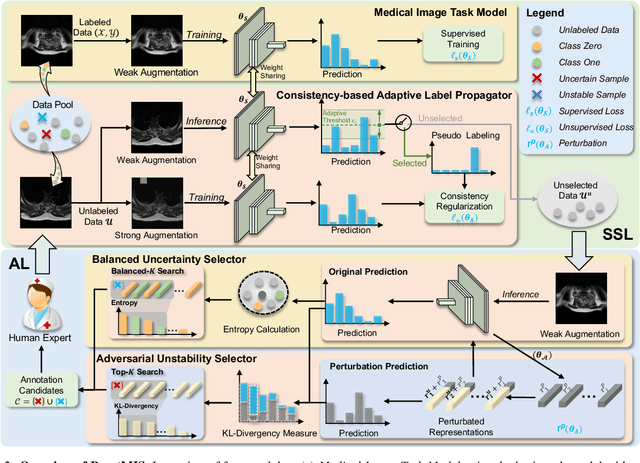
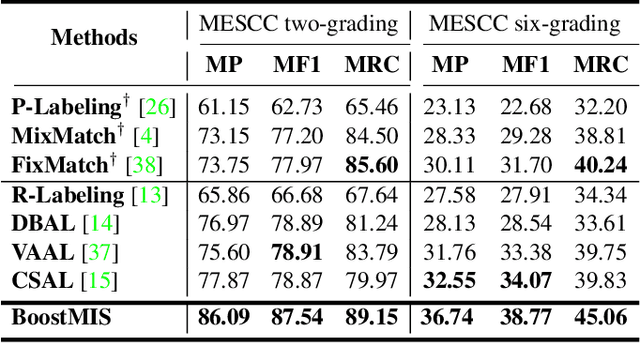
In this paper, we propose a novel semi-supervised learning (SSL) framework named BoostMIS that combines adaptive pseudo labeling and informative active annotation to unleash the potential of medical image SSL models: (1) BoostMIS can adaptively leverage the cluster assumption and consistency regularization of the unlabeled data according to the current learning status. This strategy can adaptively generate one-hot ``hard'' labels converted from task model predictions for better task model training. (2) For the unselected unlabeled images with low confidence, we introduce an Active learning (AL) algorithm to find the informative samples as the annotation candidates by exploiting virtual adversarial perturbation and model's density-aware entropy. These informative candidates are subsequently fed into the next training cycle for better SSL label propagation. Notably, the adaptive pseudo-labeling and informative active annotation form a learning closed-loop that are mutually collaborative to boost medical image SSL. To verify the effectiveness of the proposed method, we collected a metastatic epidural spinal cord compression (MESCC) dataset that aims to optimize MESCC diagnosis and classification for improved specialist referral and treatment. We conducted an extensive experimental study of BoostMIS on MESCC and another public dataset COVIDx. The experimental results verify our framework's effectiveness and generalisability for different medical image datasets with a significant improvement over various state-of-the-art methods.
* 10 pages
Enhanced total variation minimization for stable image reconstruction
Jan 09, 2022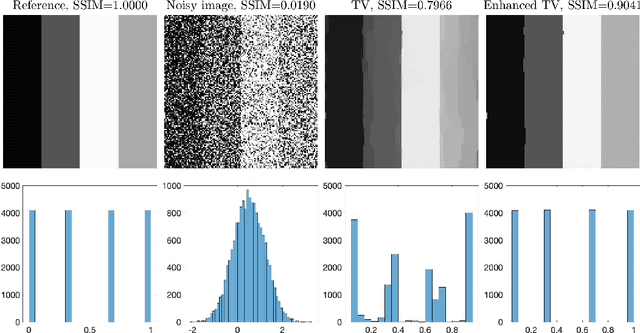
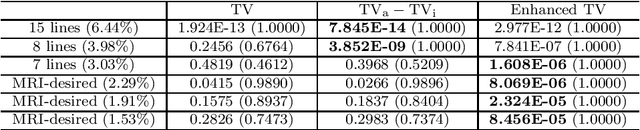
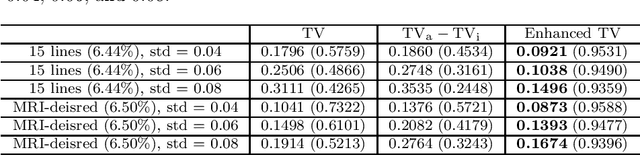
The total variation (TV) regularization has phenomenally boosted various variational models for image processing tasks. We propose combining the backward diffusion process in the earlier literature of image enhancement with the TV regularization and show that the resulting enhanced TV minimization model is particularly effective for reducing the loss of contrast, which is often encountered by models using the TV regularization. We establish stable reconstruction guarantees for the enhanced TV model from noisy subsampled measurements; non-adaptive linear measurements and variable-density sampled Fourier measurements are considered. In particular, under some weaker restricted isometry property conditions, the enhanced TV minimization model is shown to have tighter reconstruction error bounds than various TV-based models for the scenario where the level of noise is significant and the amount of measurements is limited. The advantages of the enhanced TV model are also numerically validated by preliminary experiments on the reconstruction of some synthetic, natural, and medical images.
NeurIPS'22 Cross-Domain MetaDL competition: Design and baseline results
Aug 31, 2022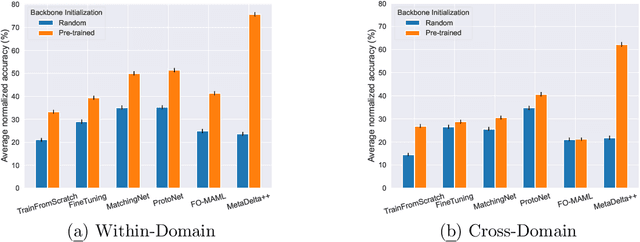

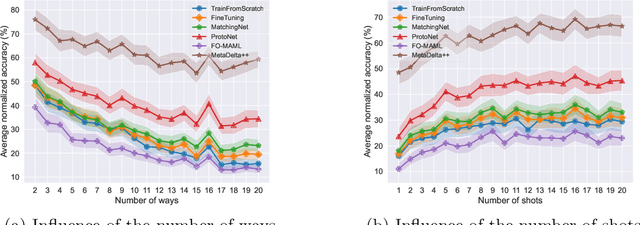

We present the design and baseline results for a new challenge in the ChaLearn meta-learning series, accepted at NeurIPS'22, focusing on "cross-domain" meta-learning. Meta-learning aims to leverage experience gained from previous tasks to solve new tasks efficiently (i.e., with better performance, little training data, and/or modest computational resources). While previous challenges in the series focused on within-domain few-shot learning problems, with the aim of learning efficiently N-way k-shot tasks (i.e., N class classification problems with k training examples), this competition challenges the participants to solve "any-way" and "any-shot" problems drawn from various domains (healthcare, ecology, biology, manufacturing, and others), chosen for their humanitarian and societal impact. To that end, we created Meta-Album, a meta-dataset of 40 image classification datasets from 10 domains, from which we carve out tasks with any number of "ways" (within the range 2-20) and any number of "shots" (within the range 1-20). The competition is with code submission, fully blind-tested on the CodaLab challenge platform. The code of the winners will be open-sourced, enabling the deployment of automated machine learning solutions for few-shot image classification across several domains.
Scale-Net: Learning to Reduce Scale Differences for Large-Scale Invariant Image Matching
Dec 20, 2021
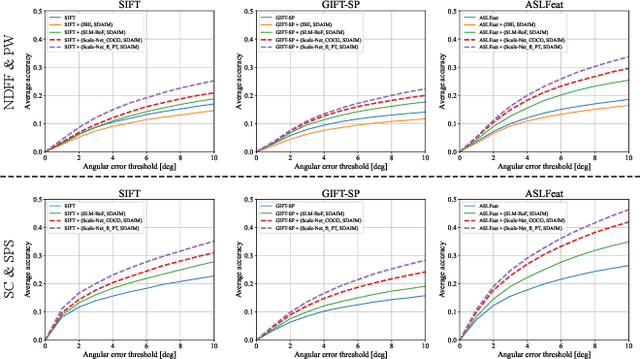
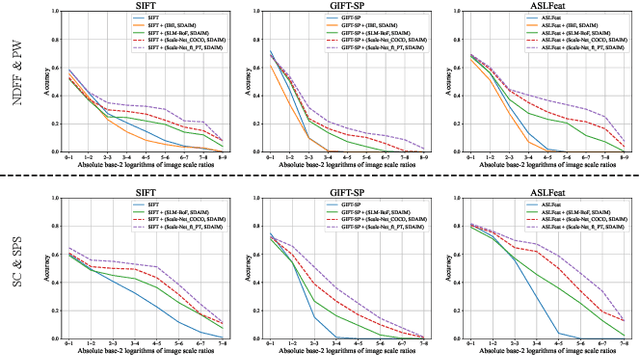

Most image matching methods perform poorly when encountering large scale changes in images. To solve this problem, firstly, we propose a scale-difference-aware image matching method (SDAIM) that reduces image scale differences before local feature extraction, via resizing both images of an image pair according to an estimated scale ratio. Secondly, in order to accurately estimate the scale ratio, we propose a covisibility-attention-reinforced matching module (CVARM) and then design a novel neural network, termed as Scale-Net, based on CVARM. The proposed CVARM can lay more stress on covisible areas within the image pair and suppress the distraction from those areas visible in only one image. Quantitative and qualitative experiments confirm that the proposed Scale-Net has higher scale ratio estimation accuracy and much better generalization ability compared with all the existing scale ratio estimation methods. Further experiments on image matching and relative pose estimation tasks demonstrate that our SDAIM and Scale-Net are able to greatly boost the performance of representative local features and state-of-the-art local feature matching methods.
UAV-based Visual Remote Sensing for Automated Building Inspection
Sep 27, 2022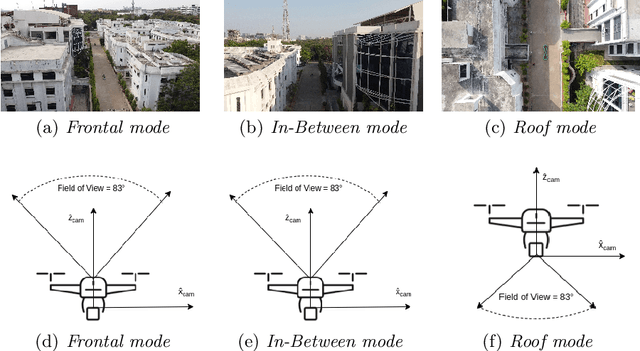
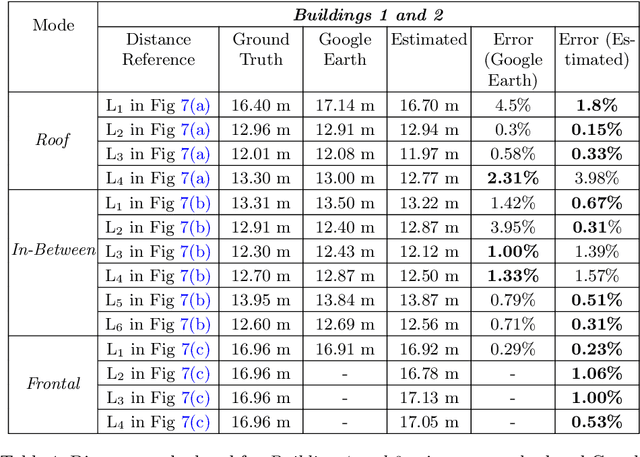
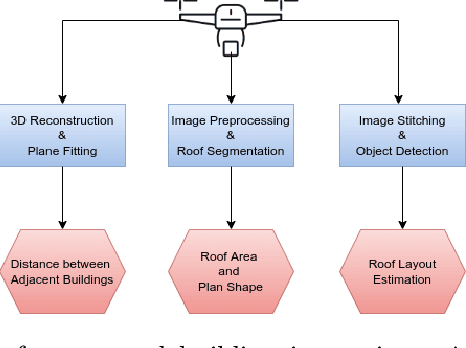
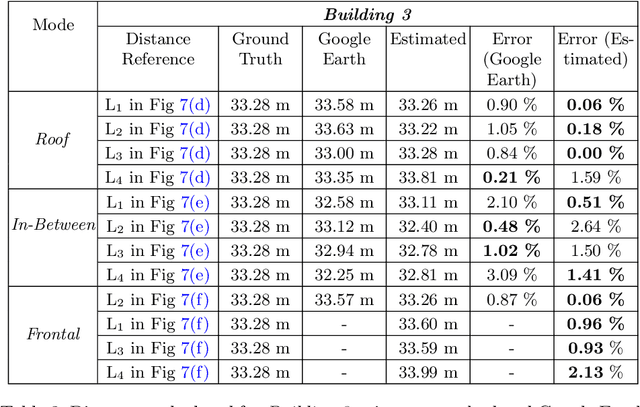
Unmanned Aerial Vehicle (UAV) based remote sensing system incorporated with computer vision has demonstrated potential for assisting building construction and in disaster management like damage assessment during earthquakes. The vulnerability of a building to earthquake can be assessed through inspection that takes into account the expected damage progression of the associated component and the component's contribution to structural system performance. Most of these inspections are done manually, leading to high utilization of manpower, time, and cost. This paper proposes a methodology to automate these inspections through UAV-based image data collection and a software library for post-processing that helps in estimating the seismic structural parameters. The key parameters considered here are the distances between adjacent buildings, building plan-shape, building plan area, objects on the rooftop and rooftop layout. The accuracy of the proposed methodology in estimating the above-mentioned parameters is verified through field measurements taken using a distance measuring sensor and also from the data obtained through Google Earth. Additional details and code can be accessed from https://uvrsabi.github.io/ .
OBBStacking: An Ensemble Method for Remote Sensing Object Detection
Sep 27, 2022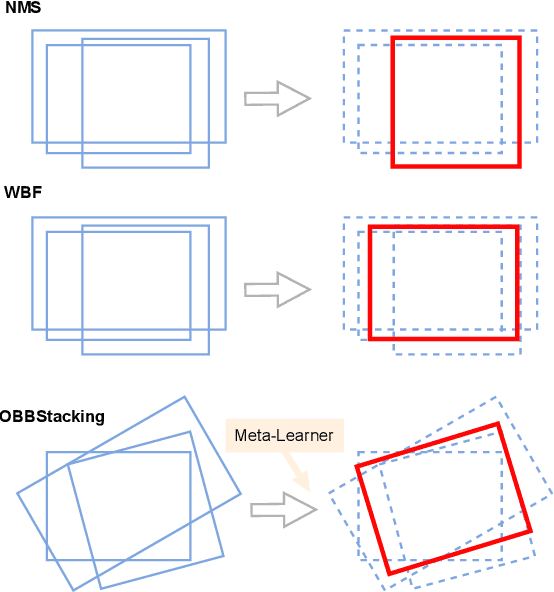


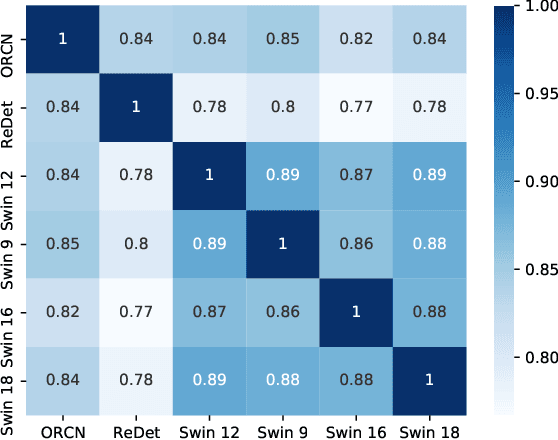
Ensemble methods are a reliable way to combine several models to achieve superior performance. However, research on the application of ensemble methods in the remote sensing object detection scenario is mostly overlooked. Two problems arise. First, one unique characteristic of remote sensing object detection is the Oriented Bounding Boxes (OBB) of the objects and the fusion of multiple OBBs requires further research attention. Second, the widely used deep learning object detectors provide a score for each detected object as an indicator of confidence, but how to use these indicators effectively in an ensemble method remains a problem. Trying to address these problems, this paper proposes OBBStacking, an ensemble method that is compatible with OBBs and combines the detection results in a learned fashion. This ensemble method helps take 1st place in the Challenge Track \textit{Fine-grained Object Recognition in High-Resolution Optical Images}, which was featured in \textit{2021 Gaofen Challenge on Automated High-Resolution Earth Observation Image Interpretation}. The experiments on DOTA dataset and FAIR1M dataset demonstrate the improved performance of OBBStacking and the features of OBBStacking are analyzed.
Fusing Convolutional Neural Network and Geometric Constraint for Image-based Indoor Localization
Jan 05, 2022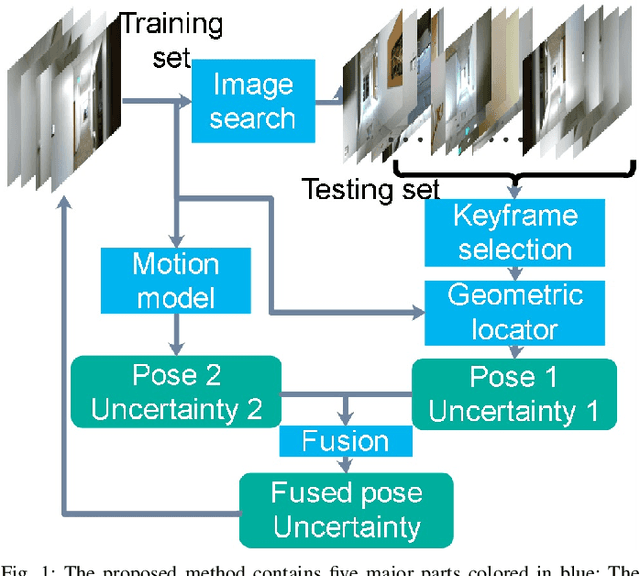
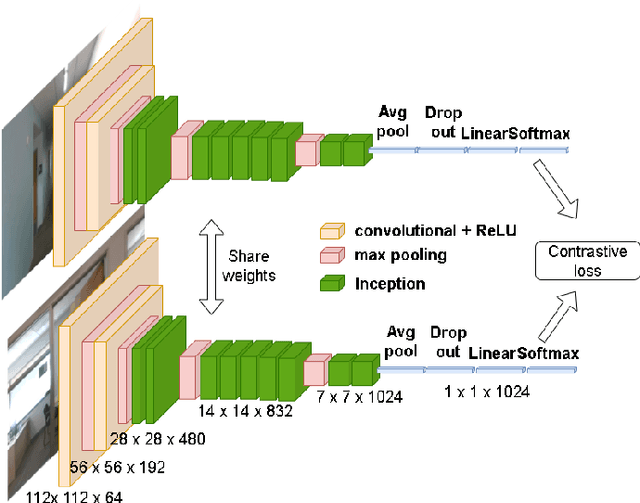
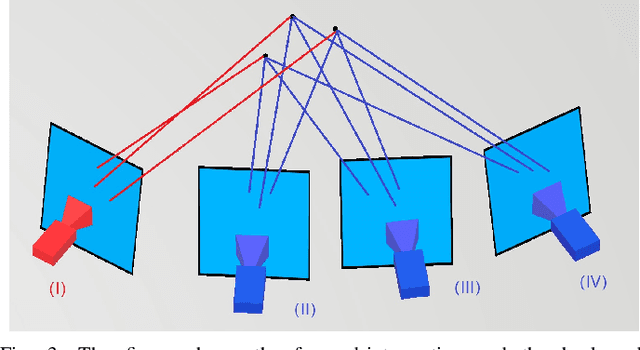

This paper proposes a new image-based localization framework that explicitly localizes the camera/robot by fusing Convolutional Neural Network (CNN) and sequential images' geometric constraints. The camera is localized using a single or few observed images and training images with 6-degree-of-freedom pose labels. A Siamese network structure is adopted to train an image descriptor network, and the visually similar candidate image in the training set is retrieved to localize the testing image geometrically. Meanwhile, a probabilistic motion model predicts the pose based on a constant velocity assumption. The two estimated poses are finally fused using their uncertainties to yield an accurate pose prediction. This method leverages the geometric uncertainty and is applicable in indoor scenarios predominated by diffuse illumination. Experiments on simulation and real data sets demonstrate the efficiency of our proposed method. The results further show that combining the CNN-based framework with geometric constraint achieves better accuracy when compared with CNN-only methods, especially when the training data size is small.
Unsupervised detection of ash dieback disease (Hymenoscyphus fraxineus) using diffusion-based hyperspectral image clustering
Apr 19, 2022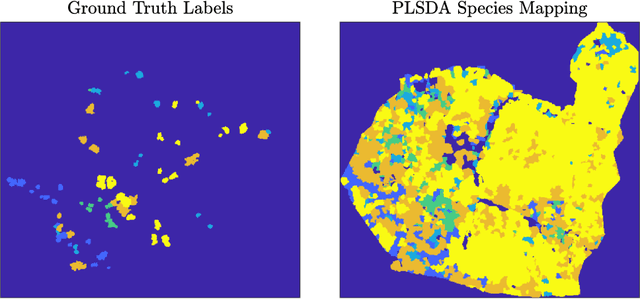

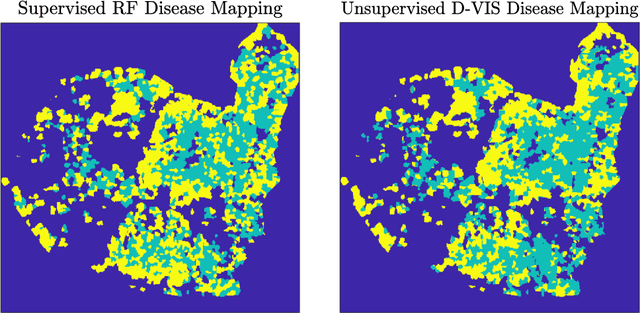
Ash dieback (Hymenoscyphus fraxineus) is an introduced fungal disease that is causing the widespread death of ash trees across Europe. Remote sensing hyperspectral images encode rich structure that has been exploited for the detection of dieback disease in ash trees using supervised machine learning techniques. However, to understand the state of forest health at landscape-scale, accurate unsupervised approaches are needed. This article investigates the use of the unsupervised Diffusion and VCA-Assisted Image Segmentation (D-VIS) clustering algorithm for the detection of ash dieback disease in a forest site near Cambridge, United Kingdom. The unsupervised clustering presented in this work has high overlap with the supervised classification of previous work on this scene (overall accuracy = 71%). Thus, unsupervised learning may be used for the remote detection of ash dieback disease without the need for expert labeling.
Learning True Rate-Distortion-Optimization for End-To-End Image Compression
Jan 05, 2022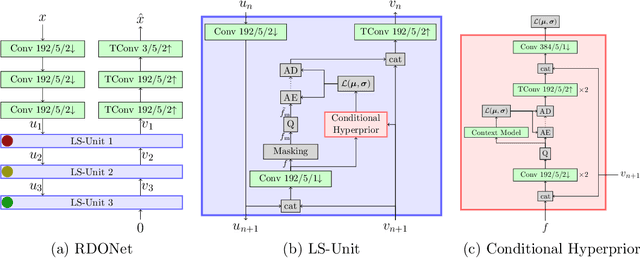
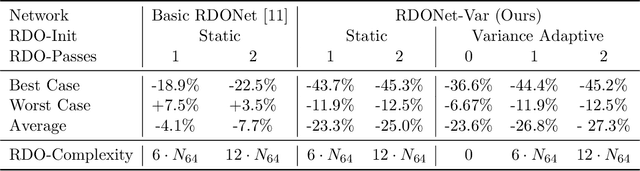


Even though rate-distortion optimization is a crucial part of traditional image and video compression, not many approaches exist which transfer this concept to end-to-end-trained image compression. Most frameworks contain static compression and decompression models which are fixed after training, so efficient rate-distortion optimization is not possible. In a previous work, we proposed RDONet, which enables an RDO approach comparable to adaptive block partitioning in HEVC. In this paper, we enhance the training by introducing low-complexity estimations of the RDO result into the training. Additionally, we propose fast and very fast RDO inference modes. With our novel training method, we achieve average rate savings of 19.6% in MS-SSIM over the previous RDONet model, which equals rate savings of 27.3% over a comparable conventional deep image coder.
T$^2$LR-Net: An Unrolling Reconstruction Network Learning Transformed Tensor Low-Rank prior for Dynamic MR Imaging
Sep 08, 2022
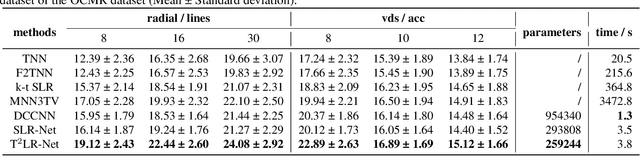
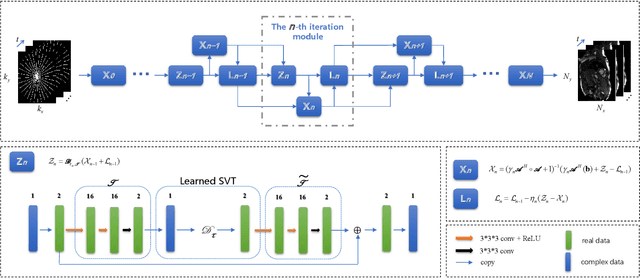
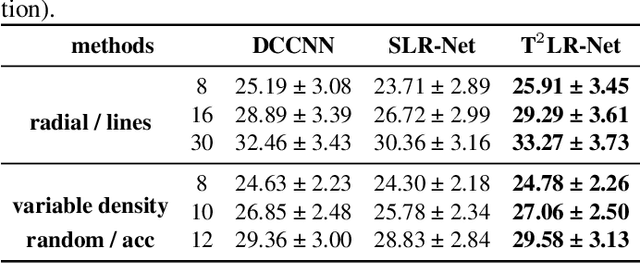
While the methods exploiting the tensor low-rank prior are booming in high-dimensional data processing and have obtained satisfying performance, their applications in dynamic magnetic resonance (MR) image reconstruction are limited. In this paper, we concentrate on the tensor singular value decomposition (t-SVD), which is based on the Fast Fourier Transform (FFT) and only provides the definite and limited tensor low-rank prior in the FFT domain, heavily reliant upon how closely the data and the FFT domain match up. By generalizing the FFT into an arbitrary unitary transformation of the transformed t-SVD and proposing the transformed tensor nuclear norm (TTNN), we introduce a flexible model based on TTNN with the ability to exploit the tensor low-rank prior of a transformed domain in a larger transformation space and elaborately design an iterative optimization algorithm based on the alternating direction method of multipliers (ADMM), which is further unrolled into a model-based deep unrolling reconstruction network to learn the transformed tensor low-rank prior (T$^2$LR-Net). The convolutional neural network (CNN) is incorporated within the T$^2$LR-Net to learn the best-matched transform from the dynamic MR image dataset. The unrolling reconstruction network also provides a new perspective on the low-rank prior utilization by exploiting the low-rank prior in the CNN-extracted feature domain. Experimental results on two cardiac cine MR datasets demonstrate that the proposed framework can provide improved recovery results compared with the state-of-the-art optimization-based and unrolling network-based methods.