 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PIZZA: A Powerful Image-only Zero-Shot Zero-CAD Approach to 6 DoF Tracking
Sep 15, 2022
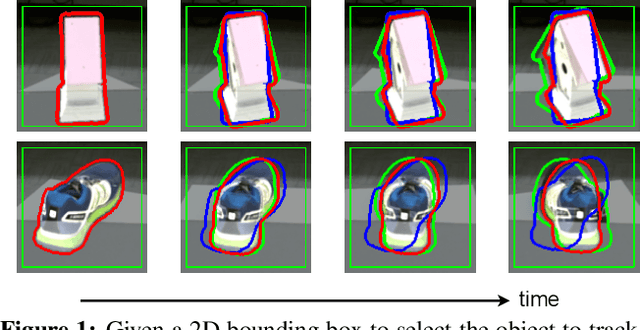
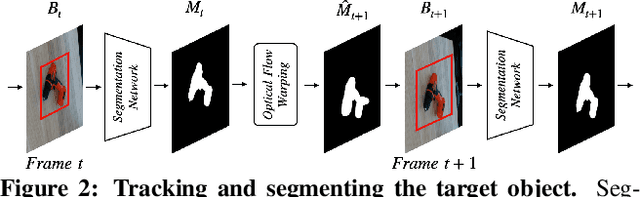
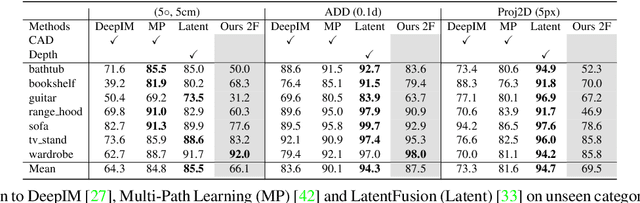
Estimating the relative pose of a new object without prior knowledge is a hard problem, while it is an ability very much needed in robotics and Augmented Reality. We present a method for tracking the 6D motion of objects in RGB video sequences when neither the training images nor the 3D geometry of the objects are available. In contrast to previous works, our method can therefore consider unknown objects in open world instantly, without requiring any prior information or a specific training phase. We consider two architectures, one based on two frames, and the other relying on a Transformer Encoder, which can exploit an arbitrary number of past frames. We train our architectures using only synthetic renderings with domain randomization. Our results on challenging datasets are on par with previous works that require much more information (training images of the target objects, 3D models, and/or depth data). Our source code is available at https://github.com/nv-nguyen/pizza
Enhancing Diffusion-Based Image Synthesis with Robust Classifier Guidance
Aug 18, 2022
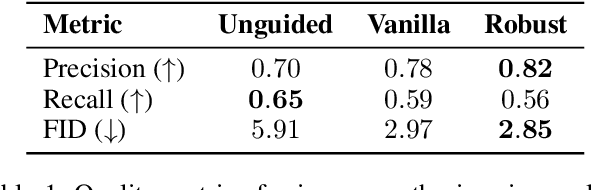

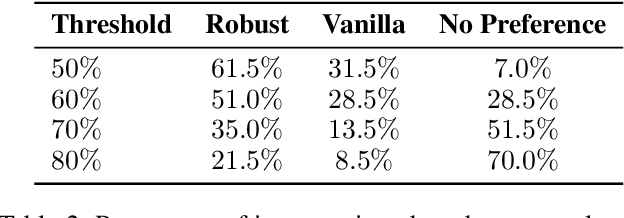
Denoising diffusion probabilistic models (DDPMs) are a recent family of generative models that achieve state-of-the-art results. In order to obtain class-conditional generation, it was suggested to guide the diffusion process by gradients from a time-dependent classifier. While the idea is theoretically sound, deep learning-based classifiers are infamously susceptible to gradient-based adversarial attacks. Therefore, while traditional classifiers may achieve good accuracy scores, their gradients are possibly unreliable and might hinder the improvement of the generation results. Recent work discovered that adversarially robust classifiers exhibit gradients that are aligned with human perception, and these could better guide a generative process towards semantically meaningful images. We utilize this observation by defining and training a time-dependent adversarially robust classifier and use it as guidance for a generative diffusion model. In experiments on the highly challenging and diverse ImageNet dataset, our scheme introduces significantly more intelligible intermediate gradients, better alignment with theoretical findings, as well as improved generation results under several evaluation metrics. Furthermore, we conduct an opinion survey whose findings indicate that human raters prefer our method's results.
Unified Multivariate Gaussian Mixture for Efficient Neural Image Compression
Mar 21, 2022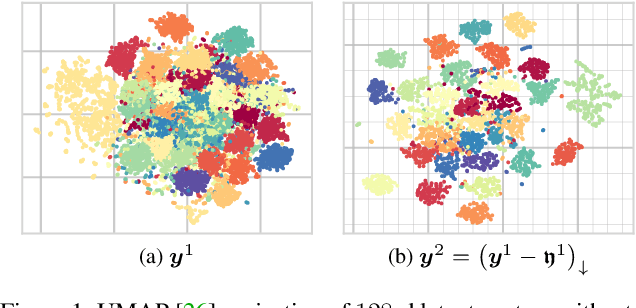
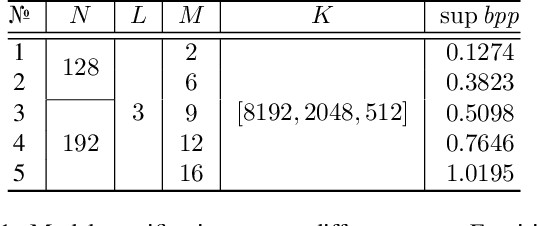
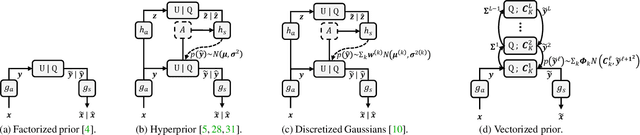
Modeling latent variables with priors and hyperpriors is an essential problem in variational image compression. Formally, trade-off between rate and distortion is handled well if priors and hyperpriors precisely describe latent variables. Current practices only adopt univariate priors and process each variable individually. However, we find inter-correlations and intra-correlations exist when observing latent variables in a vectorized perspective. These findings reveal visual redundancies to improve rate-distortion performance and parallel processing ability to speed up compression. This encourages us to propose a novel vectorized prior. Specifically, a multivariate Gaussian mixture is proposed with means and covariances to be estimated. Then, a novel probabilistic vector quantization is utilized to effectively approximate means, and remaining covariances are further induced to a unified mixture and solved by cascaded estimation without context models involved. Furthermore, codebooks involved in quantization are extended to multi-codebooks for complexity reduction, which formulates an efficient compression procedure. Extensive experiments on benchmark datasets against state-of-the-art indicate our model has better rate-distortion performance and an impressive $3.18\times$ compression speed up, giving us the ability to perform real-time, high-quality variational image compression in practice. Our source code is publicly available at \url{https://github.com/xiaosu-zhu/McQuic}.
* Accepted to CVPR 2022
CycleGAN with three different unpaired datasets
Aug 12, 2022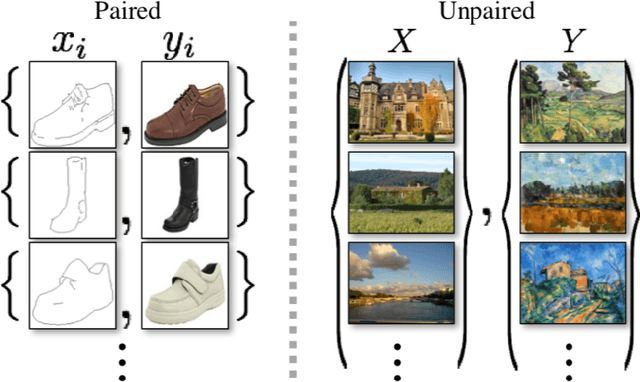
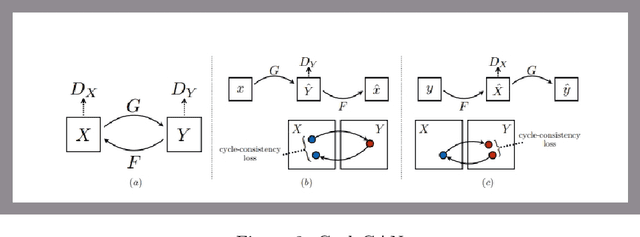


The original publication Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks served as the inspiration for this implementation project. Researchers developed a novel method for doing image-to-image translations using an unpaired dataset in the original study. Despite the fact that the pix2pix models findings are good, the matched dataset is frequently not available. In the absence of paired data, cycleGAN can therefore get over this issue by converting images to images. In order to lessen the difference between the images, they implemented cycle consistency loss.I evaluated CycleGAN with three different datasets, and this paper briefly discusses the findings and conclusions.
LATITUDE: Robotic Global Localization with Truncated Dynamic Low-pass Filter in City-scale NeRF
Sep 18, 2022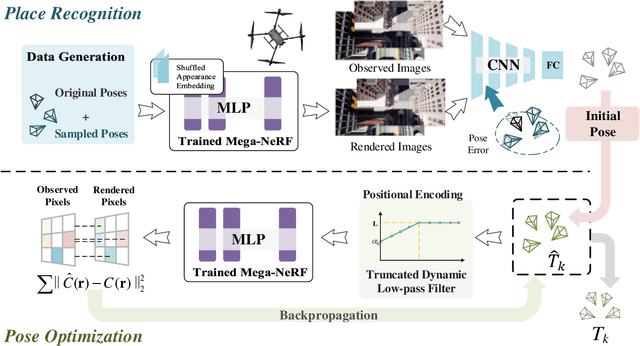
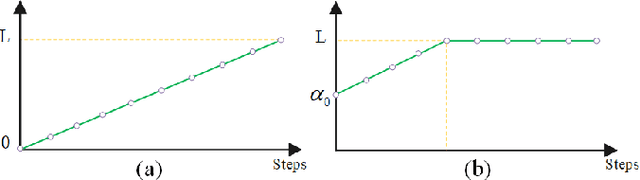

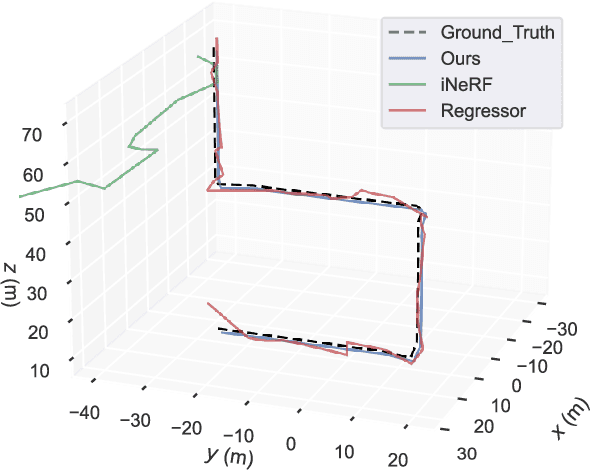
Neural Radiance Fields (NeRFs) have made great success in representing complex 3D scenes with high-resolution details and efficient memory. Nevertheless, current NeRF-based pose estimators have no initial pose prediction and are prone to local optima during optimization. In this paper, we present LATITUDE: Global Localization with Truncated Dynamic Low-pass Filter, which introduces a two-stage localization mechanism in city-scale NeRF. In place recognition stage, we train a regressor through images generated from trained NeRFs, which provides an initial value for global localization. In pose optimization stage, we minimize the residual between the observed image and rendered image by directly optimizing the pose on tangent plane. To avoid convergence to local optimum, we introduce a Truncated Dynamic Low-pass Filter (TDLF) for coarse-to-fine pose registration. We evaluate our method on both synthetic and real-world data and show its potential applications for high-precision navigation in large-scale city scenes. Codes and data will be publicly available at https://github.com/jike5/LATITUDE.
Hybrid Parallel Imaging and Compressed Sensing MRI Reconstruction with GRAPPA Integrated Multi-loss Supervised GAN
Sep 19, 2022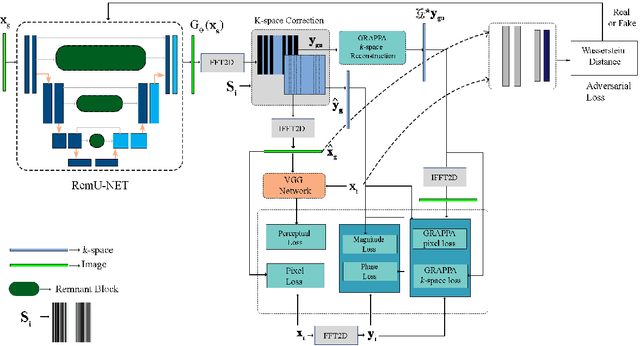



Objective: Parallel imaging accelerates the acquisition of magnetic resonance imaging (MRI) data by acquiring additional sensitivity information with an array of receiver coils resulting in reduced phase encoding steps. Compressed sensing magnetic resonance imaging (CS-MRI) has achieved popularity in the field of medical imaging because of its less data requirement than parallel imaging. Parallel imaging and compressed sensing (CS) both speed up traditional MRI acquisition by minimizing the amount of data captured in the k-space. As acquisition time is inversely proportional to the number of samples, the inverse formation of an image from reduced k-space samples leads to faster acquisition but with aliasing artifacts. This paper proposes a novel Generative Adversarial Network (GAN) namely RECGAN-GR supervised with multi-modal losses for de-aliasing the reconstructed image. Methods: In contrast to existing GAN networks, our proposed method introduces a novel generator network namely RemU-Net integrated with dual-domain loss functions including weighted magnitude and phase loss functions along with parallel imaging-based loss i.e., GRAPPA consistency loss. A k-space correction block is proposed as refinement learning to make the GAN network self-resistant to generating unnecessary data which drives the convergence of the reconstruction process faster. Results: Comprehensive results show that the proposed RECGAN-GR achieves a 4 dB improvement in the PSNR among the GAN-based methods and a 2 dB improvement among conventional state-of-the-art CNN methods available in the literature. Conclusion and significance: The proposed work contributes to significant improvement in the image quality for low retained data leading to 5x or 10x faster acquisition.
A Smoothing and Thresholding Image Segmentation Framework with Weighted Anisotropic-Isotropic Total Variation
Mar 20, 2022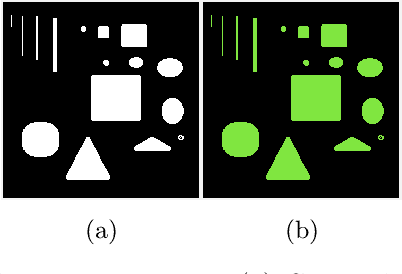
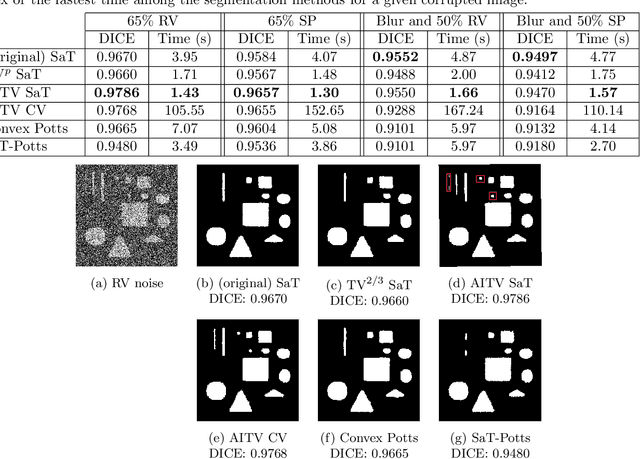

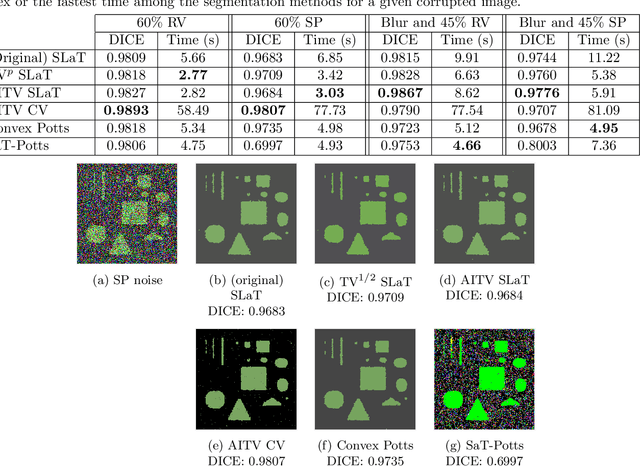
In this paper, we propose a multi-stage image segmentation framework that incorporates a weighted difference of anisotropic and isotropic total variation (AITV). The segmentation framework generally consists of two stages: smoothing and thresholding, thus referred to as SaT. In the first stage, a smoothed image is obtained by an AITV-regularized Mumford-Shah (MS) model, which can be solved efficiently by the alternating direction method of multipliers (ADMM) with a closed-form solution of a proximal operator of the $\ell_1 -\alpha \ell_2$ regularizer. Convergence of the ADMM algorithm is analyzed. In the second stage, we threshold the smoothed image by $k$-means clustering to obtain the final segmentation result. Numerical experiments demonstrate that the proposed segmentation framework is versatile for both grayscale and color images, efficient in producing high-quality segmentation results within a few seconds, and robust to input images that are corrupted with noise, blur, or both. We compare the AITV method with its original convex and nonconvex TV$^p (0<p<1)$ counterparts, showcasing the qualitative and quantitative advantages of our proposed method.
Learning Deep Sensorimotor Policies for Vision-based Autonomous Drone Racing
Oct 26, 2022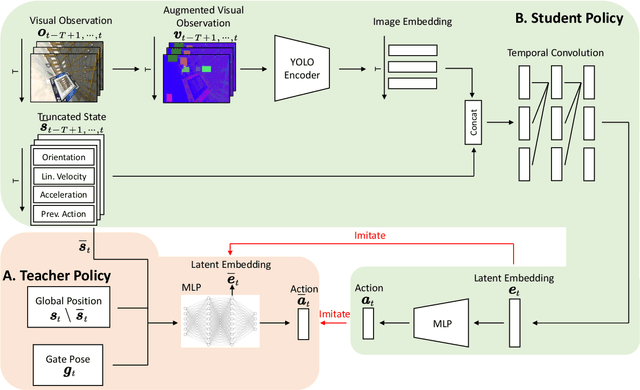

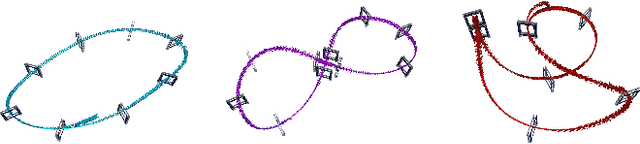
Autonomous drones can operate in remote and unstructured environments, enabling various real-world applications. However, the lack of effective vision-based algorithms has been a stumbling block to achieving this goal. Existing systems often require hand-engineered components for state estimation, planning, and control. Such a sequential design involves laborious tuning, human heuristics, and compounding delays and errors. This paper tackles the vision-based autonomous-drone-racing problem by learning deep sensorimotor policies. We use contrastive learning to extract robust feature representations from the input images and leverage a two-stage learning-by-cheating framework for training a neural network policy. The resulting policy directly infers control commands with feature representations learned from raw images, forgoing the need for globally-consistent state estimation, trajectory planning, and handcrafted control design. Our experimental results indicate that our vision-based policy can achieve the same level of racing performance as the state-based policy while being robust against different visual disturbances and distractors. We believe this work serves as a stepping-stone toward developing intelligent vision-based autonomous systems that control the drone purely from image inputs, like human pilots.
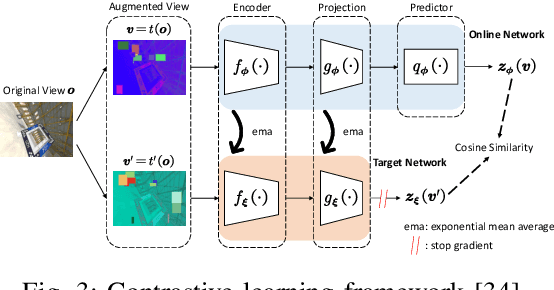
Adversarial Pretraining of Self-Supervised Deep Networks: Past, Present and Future
Oct 23, 2022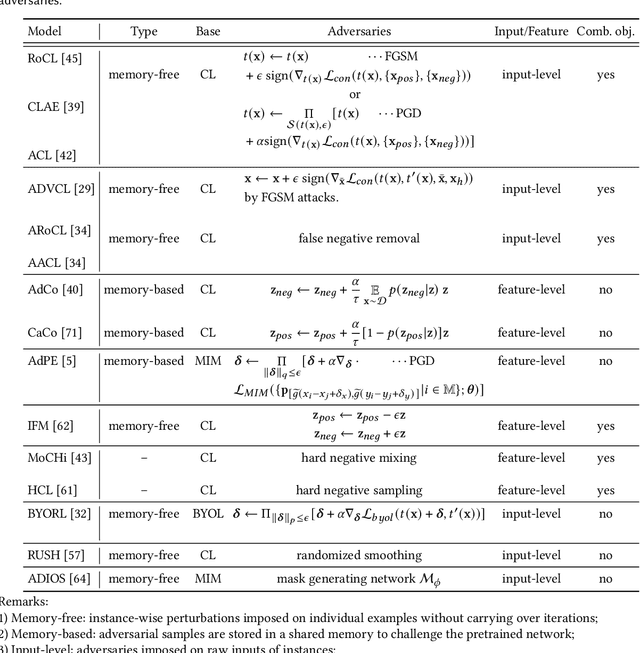
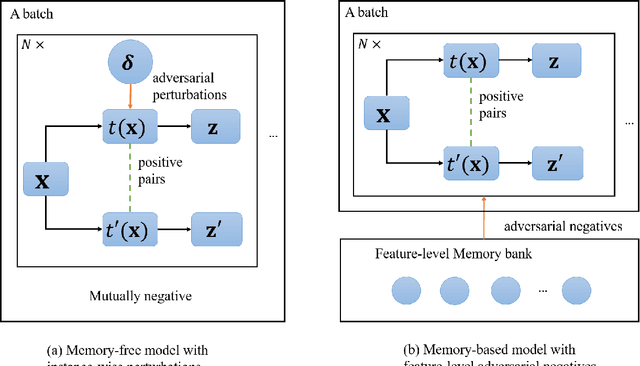

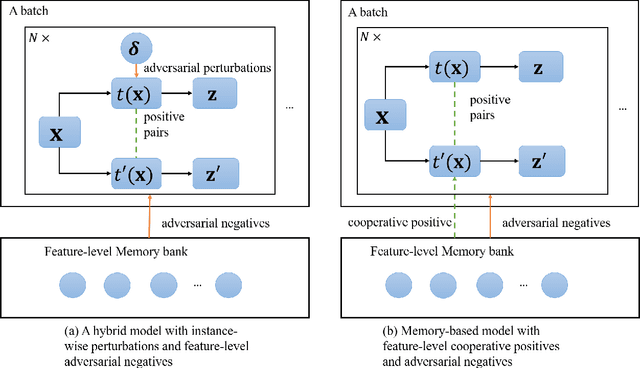
In this paper, we review adversarial pretraining of self-supervised deep networks including both convolutional neural networks and vision transformers. Unlike the adversarial training with access to labeled examples, adversarial pretraining is complicated as it only has access to unlabeled examples. To incorporate adversaries into pretraining models on either input or feature level, we find that existing approaches are largely categorized into two groups: memory-free instance-wise attacks imposing worst-case perturbations on individual examples, and memory-based adversaries shared across examples over iterations. In particular, we review several representative adversarial pretraining models based on Contrastive Learning (CL) and Masked Image Modeling (MIM), respectively, two popular self-supervised pretraining methods in literature. We also review miscellaneous issues about computing overheads, input-/feature-level adversaries, as well as other adversarial pretraining approaches beyond the above two groups. Finally, we discuss emerging trends and future directions about the relations between adversarial and cooperative pretraining, unifying adversarial CL and MIM pretraining, and the trade-off between accuracy and robustness in adversarial pretraining.
GAN-based Facial Attribute Manipulation
Oct 23, 2022
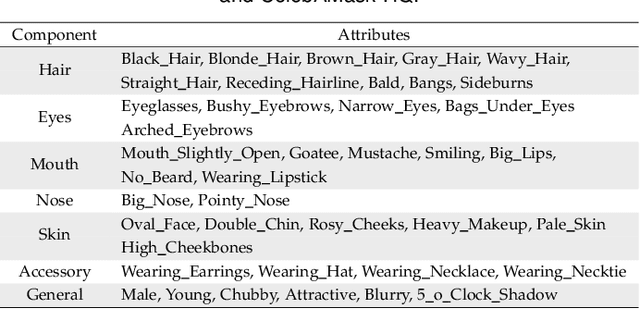
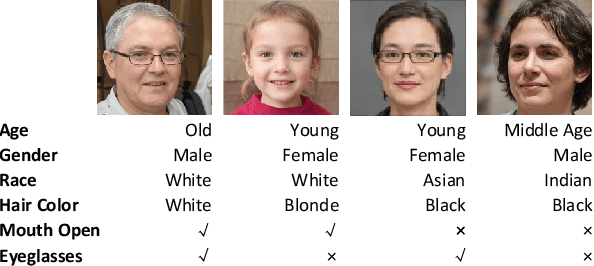
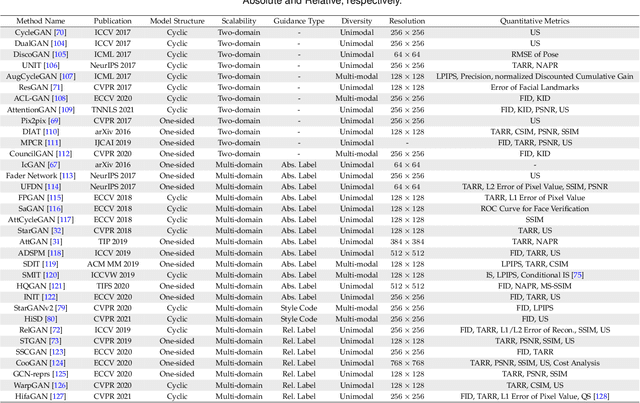
Facial Attribute Manipulation (FAM) aims to aesthetically modify a given face image to render desired attributes, which has received significant attention due to its broad practical applications ranging from digital entertainment to biometric forensics. In the last decade, with the remarkable success of Generative Adversarial Networks (GANs) in synthesizing realistic images, numerous GAN-based models have been proposed to solve FAM with various problem formulation approaches and guiding information representations. This paper presents a comprehensive survey of GAN-based FAM methods with a focus on summarizing their principal motivations and technical details. The main contents of this survey include: (i) an introduction to the research background and basic concepts related to FAM, (ii) a systematic review of GAN-based FAM methods in three main categories, and (iii) an in-depth discussion of important properties of FAM methods, open issues, and future research directions. This survey not only builds a good starting point for researchers new to this field but also serves as a reference for the vision community.