 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Instance Field for Dynamic Scene Understanding
Dec 16, 2025



We introduce Consistent Instance Field, a continuous and probabilistic spatio-temporal representation for dynamic scene understanding. Unlike prior methods that rely on discrete tracking or view-dependent features, our approach disentangles visibility from persistent object identity by modeling each space-time point with an occupancy probability and a conditional instance distribution. To realize this, we introduce a novel instance-embedded representation based on deformable 3D Gaussians, which jointly encode radiance and semantic information and are learned directly from input RGB images and instance masks through differentiable rasterization. Furthermore, we introduce new mechanisms to calibrate per-Gaussian identities and resample Gaussians toward semantically active regions, ensuring consistent instance representations across space and time. Experiments on HyperNeRF and Neu3D datasets demonstrate that our method significantly outperforms state-of-the-art methods on novel-view panoptic segmentation and open-vocabulary 4D querying tasks.
From Particles to Fields: Reframing Photon Mapping with Continuous Gaussian Photon Fields
Dec 13, 2025Accurately modeling light transport is essential for realistic image synthesis. Photon mapping provides physically grounded estimates of complex global illumination effects such as caustics and specular-diffuse interactions, yet its per-view radiance estimation remains computationally inefficient when rendering multiple views of the same scene. The inefficiency arises from independent photon tracing and stochastic kernel estimation at each viewpoint, leading to inevitable redundant computation. To accelerate multi-view rendering, we reformulate photon mapping as a continuous and reusable radiance function. Specifically, we introduce the Gaussian Photon Field (GPF), a learnable representation that encodes photon distributions as anisotropic 3D Gaussian primitives parameterized by position, rotation, scale, and spectrum. GPF is initialized from physically traced photons in the first SPPM iteration and optimized using multi-view supervision of final radiance, distilling photon-based light transport into a continuous field. Once trained, the field enables differentiable radiance evaluation along camera rays without repeated photon tracing or iterative refinement. Extensive experiments on scenes with complex light transport, such as caustics and specular-diffuse interactions, demonstrate that GPF attains photon-level accuracy while reducing computation by orders of magnitude, unifying the physical rigor of photon-based rendering with the efficiency of neural scene representations.
GoTrack: Generic 6DoF Object Pose Refinement and Tracking
Jun 08, 2025We introduce GoTrack, an efficient and accurate CAD-based method for 6DoF object pose refinement and tracking, which can handle diverse objects without any object-specific training. Unlike existing tracking methods that rely solely on an analysis-by-synthesis approach for model-to-frame registration, GoTrack additionally integrates frame-to-frame registration, which saves compute and stabilizes tracking. Both types of registration are realized by optical flow estimation. The model-to-frame registration is noticeably simpler than in existing methods, relying only on standard neural network blocks (a transformer is trained on top of DINOv2) and producing reliable pose confidence scores without a scoring network. For the frame-to-frame registration, which is an easier problem as consecutive video frames are typically nearly identical, we employ a light off-the-shelf optical flow model. We demonstrate that GoTrack can be seamlessly combined with existing coarse pose estimation methods to create a minimal pipeline that reaches state-of-the-art RGB-only results on standard benchmarks for 6DoF object pose estimation and tracking. Our source code and trained models are publicly available at https://github.com/facebookresearch/gotrack
BOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
OpenStreetView-5M: The Many Roads to Global Visual Geolocation
Apr 29, 2024



Determining the location of an image anywhere on Earth is a complex visual task, which makes it particularly relevant for evaluating computer vision algorithms. Yet, the absence of standard, large-scale, open-access datasets with reliably localizable images has limited its potential. To address this issue, we introduce OpenStreetView-5M, a large-scale, open-access dataset comprising over 5.1 million geo-referenced street view images, covering 225 countries and territories. In contrast to existing benchmarks, we enforce a strict train/test separation, allowing us to evaluate the relevance of learned geographical features beyond mere memorization. To demonstrate the utility of our dataset, we conduct an extensive benchmark of various state-of-the-art image encoders, spatial representations, and training strategies. All associated codes and models can be found at https://github.com/gastruc/osv5m.
BOP Challenge 2023 on Detection, Segmentation and Pose Estimation of Seen and Unseen Rigid Objects
Mar 14, 2024



We present the evaluation methodology, datasets and results of the BOP Challenge 2023, the fifth in a series of public competitions organized to capture the state of the art in model-based 6D object pose estimation from an RGB/RGB-D image and related tasks. Besides the three tasks from 2022 (model-based 2D detection, 2D segmentation, and 6D localization of objects seen during training), the 2023 challenge introduced new variants of these tasks focused on objects unseen during training. In the new tasks, methods were required to learn new objects during a short onboarding stage (max 5 minutes, 1 GPU) from provided 3D object models. The best 2023 method for 6D localization of unseen objects (GenFlow) notably reached the accuracy of the best 2020 method for seen objects (CosyPose), although being noticeably slower. The best 2023 method for seen objects (GPose) achieved a moderate accuracy improvement but a significant 43% run-time improvement compared to the best 2022 counterpart (GDRNPP). Since 2017, the accuracy of 6D localization of seen objects has improved by more than 50% (from 56.9 to 85.6 AR_C). The online evaluation system stays open and is available at: http://bop.felk.cvut.cz/.
GigaPose: Fast and Robust Novel Object Pose Estimation via One Correspondence
Nov 23, 2023We present GigaPose, a fast, robust, and accurate method for CAD-based novel object pose estimation in RGB images. GigaPose first leverages discriminative templates, rendered images of the CAD models, to recover the out-of-plane rotation and then uses patch correspondences to estimate the four remaining parameters. Our approach samples templates in only a two-degrees-of-freedom space instead of the usual three and matches the input image to the templates using fast nearest neighbor search in feature space, results in a speedup factor of 38x compared to the state of the art. Moreover, GigaPose is significantly more robust to segmentation errors. Our extensive evaluation on the seven core datasets of the BOP challenge demonstrates that it achieves state-of-the-art accuracy and can be seamlessly integrated with a refinement method. Additionally, we show the potential of GigaPose with 3D models predicted by recent work on 3D reconstruction from a single image, relaxing the need for CAD models and making 6D pose object estimation much more convenient. Our source code and trained models are publicly available at https://github.com/nv-nguyen/gigaPose
CNOS: A Strong Baseline for CAD-based Novel Object Segmentation
Aug 03, 2023



We propose a simple three-stage approach to segment unseen objects in RGB images using their CAD models. Leveraging recent powerful foundation models, DINOv2 and Segment Anything, we create descriptors and generate proposals, including binary masks for a given input RGB image. By matching proposals with reference descriptors created from CAD models, we achieve precise object ID assignment along with modal masks. We experimentally demonstrate that our method achieves state-of-the-art results in CAD-based novel object segmentation, surpassing existing approaches on the seven core datasets of the BOP challenge by 19.8% AP using the same BOP evaluation protocol. Our source code is available at https://github.com/nv-nguyen/cnos.
NOPE: Novel Object Pose Estimation from a Single Image
Mar 23, 2023The practicality of 3D object pose estimation remains limited for many applications due to the need for prior knowledge of a 3D model and a training period for new objects. To address this limitation, we propose an approach that takes a single image of a new object as input and predicts the relative pose of this object in new images without prior knowledge of the object's 3D model and without requiring training time for new objects and categories. We achieve this by training a model to directly predict discriminative embeddings for viewpoints surrounding the object. This prediction is done using a simple U-Net architecture with attention and conditioned on the desired pose, which yields extremely fast inference. We compare our approach to state-of-the-art methods and show it outperforms them both in terms of accuracy and robustness. Our source code is publicly available at https://github.com/nv-nguyen/nope
PIZZA: A Powerful Image-only Zero-Shot Zero-CAD Approach to 6 DoF Tracking
Sep 15, 2022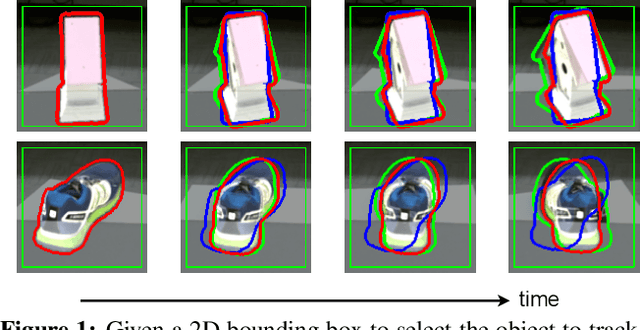
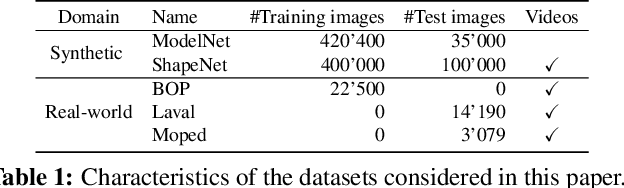
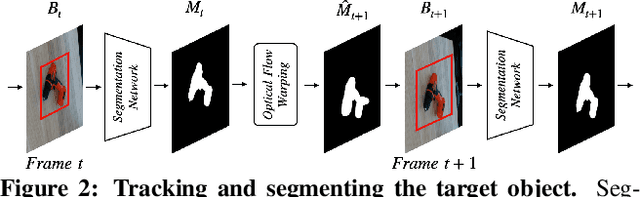
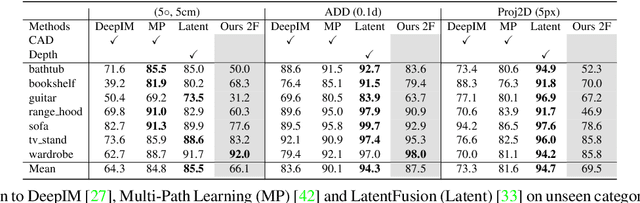
Estimating the relative pose of a new object without prior knowledge is a hard problem, while it is an ability very much needed in robotics and Augmented Reality. We present a method for tracking the 6D motion of objects in RGB video sequences when neither the training images nor the 3D geometry of the objects are available. In contrast to previous works, our method can therefore consider unknown objects in open world instantly, without requiring any prior information or a specific training phase. We consider two architectures, one based on two frames, and the other relying on a Transformer Encoder, which can exploit an arbitrary number of past frames. We train our architectures using only synthetic renderings with domain randomization. Our results on challenging datasets are on par with previous works that require much more information (training images of the target objects, 3D models, and/or depth data). Our source code is available at https://github.com/nv-nguyen/pizza