 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hyperspectral Demosaicing of Snapshot Camera Images Using Deep Learning
Nov 21, 2022
Spectral imaging technologies have rapidly evolved during the past decades. The recent development of single-camera-one-shot techniques for hyperspectral imaging allows multiple spectral bands to be captured simultaneously (3x3, 4x4 or 5x5 mosaic), opening up a wide range of applications. Examples include intraoperative imaging, agricultural field inspection and food quality assessment. To capture images across a wide spectrum range, i.e. to achieve high spectral resolution, the sensor design sacrifices spatial resolution. With increasing mosaic size, this effect becomes increasingly detrimental. Furthermore, demosaicing is challenging. Without incorporating edge, shape, and object information during interpolation, chromatic artifacts are likely to appear in the obtained images. Recent approaches use neural networks for demosaicing, enabling direct information extraction from image data. However, obtaining training data for these approaches poses a challenge as well. This work proposes a parallel neural network based demosaicing procedure trained on a new ground truth dataset captured in a controlled environment by a hyperspectral snapshot camera with a 4x4 mosaic pattern. The dataset is a combination of real captured scenes with images from publicly available data adapted to the 4x4 mosaic pattern. To obtain real world ground-truth data, we performed multiple camera captures with 1-pixel shifts in order to compose the entire data cube. Experiments show that the proposed network outperforms state-of-art networks.
* German Conference on Pattern Recognition (GCPR) 2022
Twin-S: A Digital Twin for Skull-base Surgery
Nov 21, 2022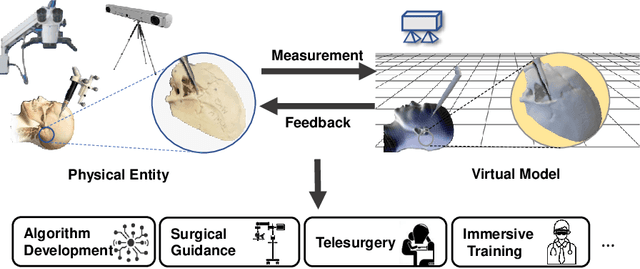
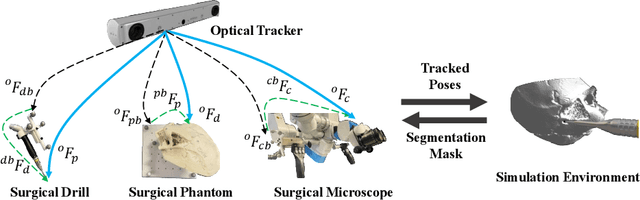
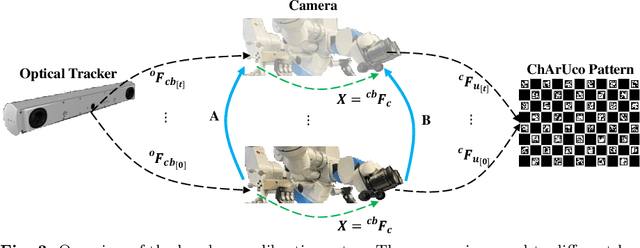
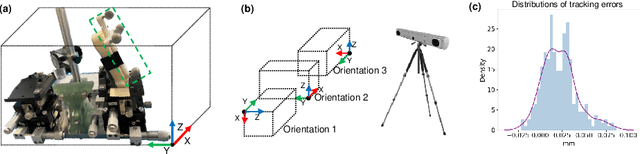
Purpose: Digital twins are virtual interactive models of the real world, exhibiting identical behavior and properties. In surgical applications, computational analysis from digital twins can be used, for example, to enhance situational awareness. Methods: We present a digital twin framework for skull-base surgeries, named Twin-S, which can be integrated within various image-guided interventions seamlessly. Twin-S combines high-precision optical tracking and real-time simulation. We rely on rigorous calibration routines to ensure that the digital twin representation precisely mimics all real-world processes. Twin-S models and tracks the critical components of skull-base surgery, including the surgical tool, patient anatomy, and surgical camera. Significantly, Twin-S updates and reflects real-world drilling of the anatomical model in frame rate. Results: We extensively evaluate the accuracy of Twin-S, which achieves an average 1.39 mm error during the drilling process. We further illustrate how segmentation masks derived from the continuously updated digital twin can augment the surgical microscope view in a mixed reality setting, where bone requiring ablation is highlighted to provide surgeons additional situational awareness. Conclusion: We present Twin-S, a digital twin environment for skull-base surgery. Twin-S tracks and updates the virtual model in real-time given measurements from modern tracking technologies. Future research on complementing optical tracking with higher-precision vision-based approaches may further increase the accuracy of Twin-S.
Expansion of Visual Hints for Improved Generalization in Stereo Matching
Nov 01, 2022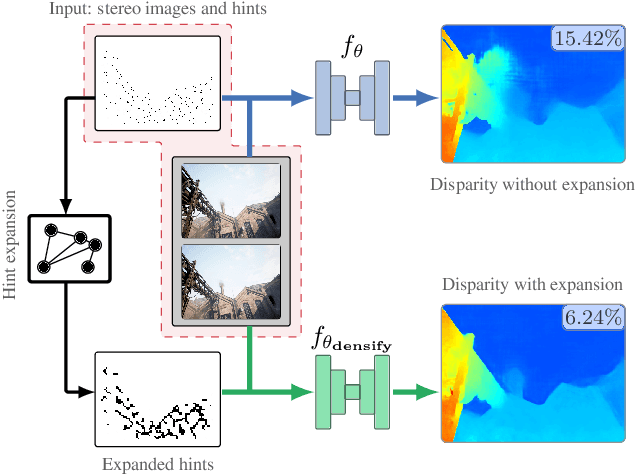


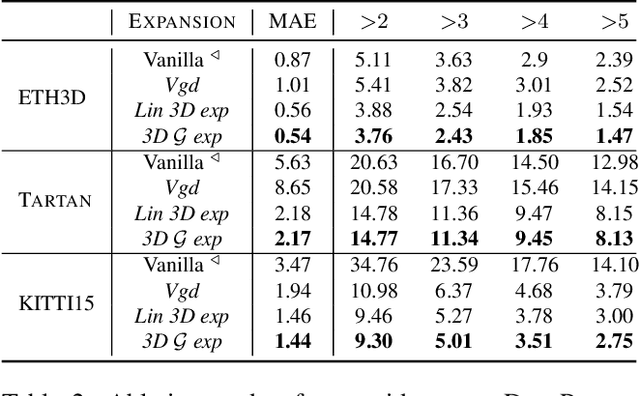
We introduce visual hints expansion for guiding stereo matching to improve generalization. Our work is motivated by the robustness of Visual Inertial Odometry (VIO) in computer vision and robotics, where a sparse and unevenly distributed set of feature points characterizes a scene. To improve stereo matching, we propose to elevate 2D hints to 3D points. These sparse and unevenly distributed 3D visual hints are expanded using a 3D random geometric graph, which enhances the learning and inference process. We evaluate our proposal on multiple widely adopted benchmarks and show improved performance without access to additional sensors other than the image sequence. To highlight practical applicability and symbiosis with visual odometry, we demonstrate how our methods run on embedded hardware.
Dynamic Bank Learning for Semi-supervised Federated Image Diagnosis with Class Imbalance
Jun 27, 2022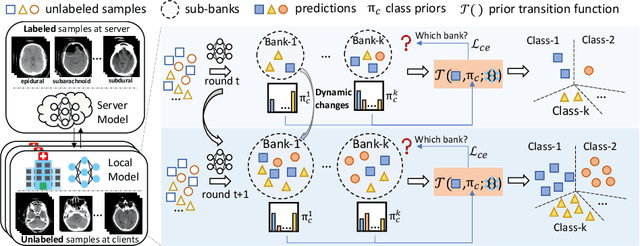
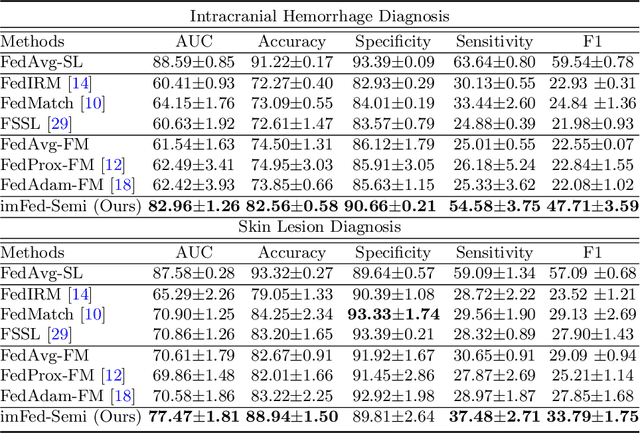
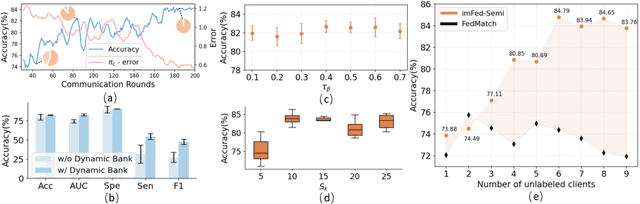
Despite recent progress on semi-supervised federated learning (FL) for medical image diagnosis, the problem of imbalanced class distributions among unlabeled clients is still unsolved for real-world use. In this paper, we study a practical yet challenging problem of class imbalanced semi-supervised FL (imFed-Semi), which allows all clients to have only unlabeled data while the server just has a small amount of labeled data. This imFed-Semi problem is addressed by a novel dynamic bank learning scheme, which improves client training by exploiting class proportion information. This scheme consists of two parts, i.e., the dynamic bank construction to distill various class proportions for each local client, and the sub-bank classification to impose the local model to learn different class proportions. We evaluate our approach on two public real-world medical datasets, including the intracranial hemorrhage diagnosis with 25,000 CT slices and skin lesion diagnosis with 10,015 dermoscopy images. The effectiveness of our method has been validated with significant performance improvements (7.61% and 4.69%) compared with the second-best on the accuracy, as well as comprehensive analytical studies. Code is available at https://github.com/med-air/imFedSemi.
Understanding ME? Multimodal Evaluation for Fine-grained Visual Commonsense
Nov 10, 2022
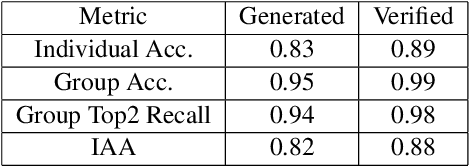
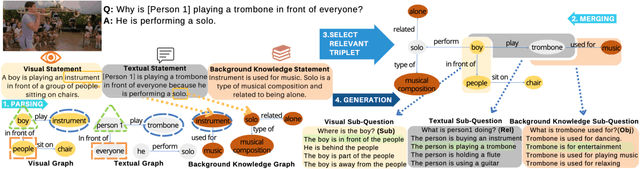
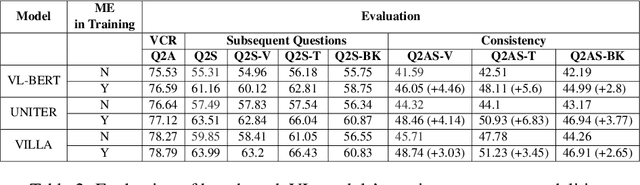
Visual commonsense understanding requires Vision Language (VL) models to not only understand image and text but also cross-reference in-between to fully integrate and achieve comprehension of the visual scene described. Recently, various approaches have been developed and have achieved high performance on visual commonsense benchmarks. However, it is unclear whether the models really understand the visual scene and underlying commonsense knowledge due to limited evaluation data resources. To provide an in-depth analysis, we present a Multimodal Evaluation (ME) pipeline to automatically generate question-answer pairs to test models' understanding of the visual scene, text, and related knowledge. We then take a step further to show that training with the ME data boosts the model's performance in standard VCR evaluation. Lastly, our in-depth analysis and comparison reveal interesting findings: (1) semantically low-level information can assist the learning of high-level information but not the opposite; (2) visual information is generally under utilization compared with text.
Harmonizing Output Imbalance for semantic segmentation on extremely-imbalanced input data
Nov 10, 2022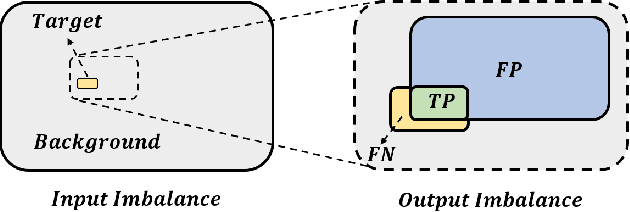
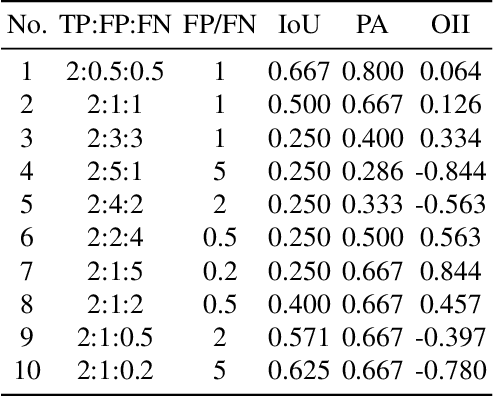
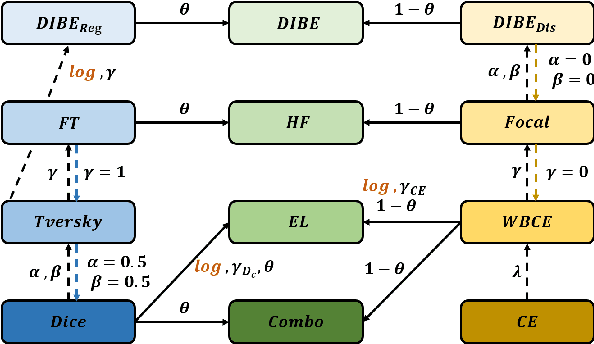
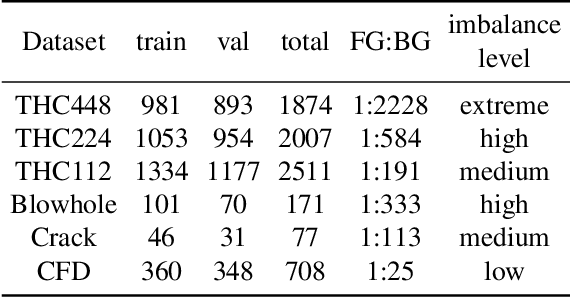
Semantic segmentation is a high level computer vision task that assigns a label for each pixel of an image. It is challengeful to deal with extremely-imbalanced data in which the ratio of target ixels to background pixels is lower than 1:1000. Such severe input imbalance leads to output imbalance for poor model training. This paper considers three issues for extremely-imbalanced data: inspired by the region based loss, an implicit measure for the output imbalance is proposed, and an adaptive algorithm is designed for guiding the output imbalance hyperparameter selection; then it is generalized to distribution based loss for dealing with output imbalance; and finally a compound loss with our adaptive hyperparameter selection alogorithm can keep the consistency of training and inference for harmonizing the output imbalance. With four popular deep architectures on our private dataset with three input imbalance scales and three public datasets, extensive experiments demonstrate the ompetitive/promising performance of the proposed method.
Contrastive Learning for Climate Model Bias Correction and Super-Resolution
Nov 10, 2022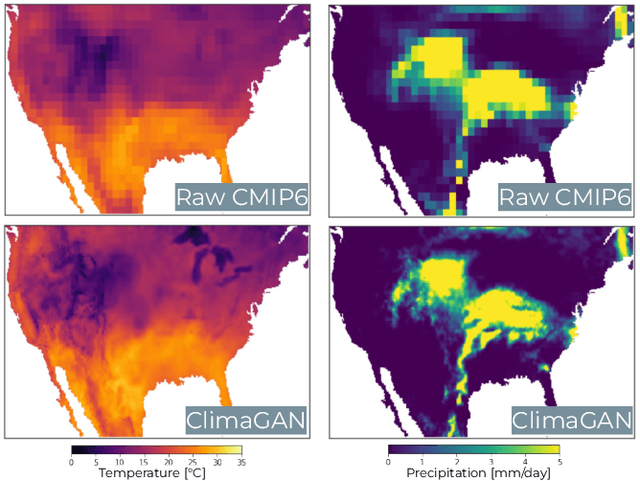
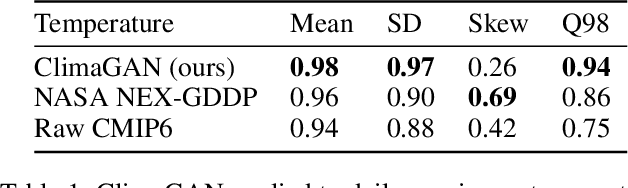
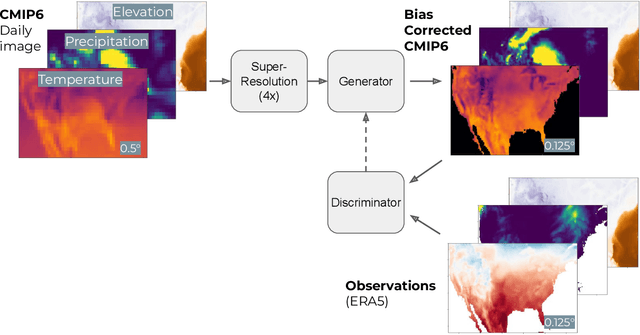
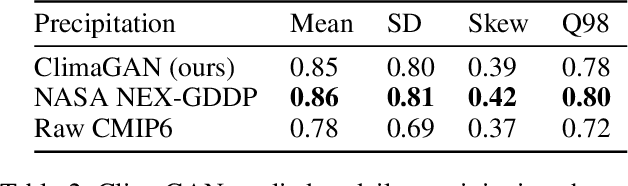
Climate models often require post-processing in order to make accurate estimates of local climate risk. The most common post-processing applied is bias-correction and spatial resolution enhancement. However, the statistical methods typically used for this not only are incapable of capturing multivariate spatial correlation information but are also reliant on rich observational data often not available outside of developed countries, limiting their potential. Here we propose an alternative approach to this challenge based on a combination of image super resolution (SR) and contrastive learning generative adversarial networks (GANs). We benchmark performance against NASA's flagship post-processed CMIP6 climate model product, NEX-GDDP. We find that our model successfully reaches a spatial resolution double that of NASA's product while also achieving comparable or improved levels of bias correction in both daily precipitation and temperature. The resulting higher fidelity simulations of present and forward-looking climate can enable more local, accurate models of hazards like flooding, drought, and heatwaves.
MixMask: Revisiting Masked Siamese Self-supervised Learning in Asymmetric Distance
Oct 20, 2022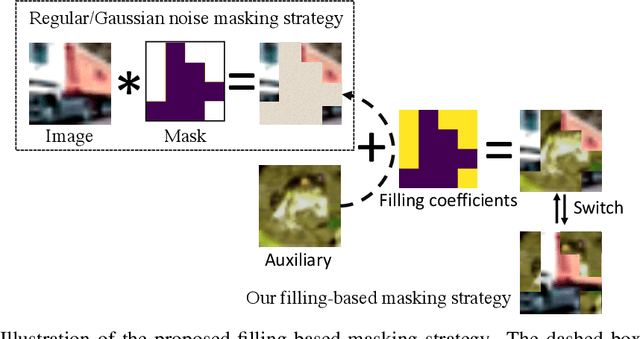
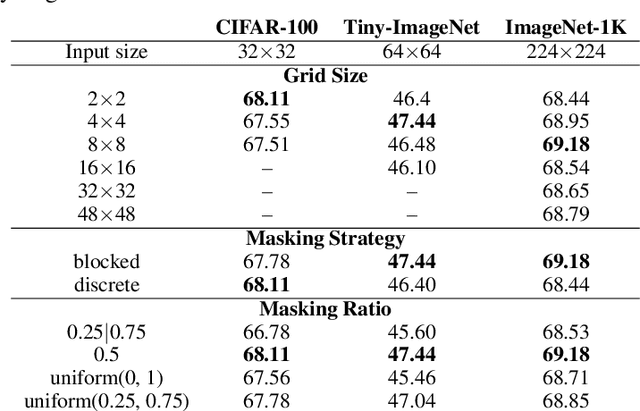
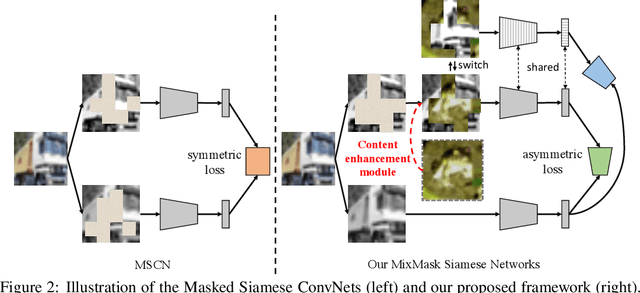

Recent advances in self-supervised learning integrate Masked Modeling and Siamese Networks into a single framework to fully reap the advantages of both the two techniques. However, previous erasing-based masking scheme in masked image modeling is not originally designed for siamese networks. Existing approaches simply inherit the default loss design from previous siamese networks, and ignore the information loss and distance change after employing masking operation in the frameworks. In this paper, we propose a filling-based masking strategy called MixMask to prevent information loss due to the randomly erased areas of an image in vanilla masking method. We further introduce a dynamic loss function design with soft distance to adapt the integrated architecture and avoid mismatches between transformed input and objective in Masked Siamese ConvNets (MSCN). The dynamic loss distance is calculated according to the proposed mix-masking scheme. Extensive experiments are conducted on various datasets of CIFAR-100, Tiny-ImageNet and ImageNet-1K. The results demonstrate that the proposed framework can achieve better accuracy on linear probing, semi-supervised and {supervised finetuning}, which outperforms the state-of-the-art MSCN by a significant margin. We also show the superiority on downstream tasks of object detection and segmentation. Our source code is available at https://github.com/LightnessOfBeing/MixMask.
Residual Degradation Learning Unfolding Framework with Mixing Priors across Spectral and Spatial for Compressive Spectral Imaging
Nov 13, 2022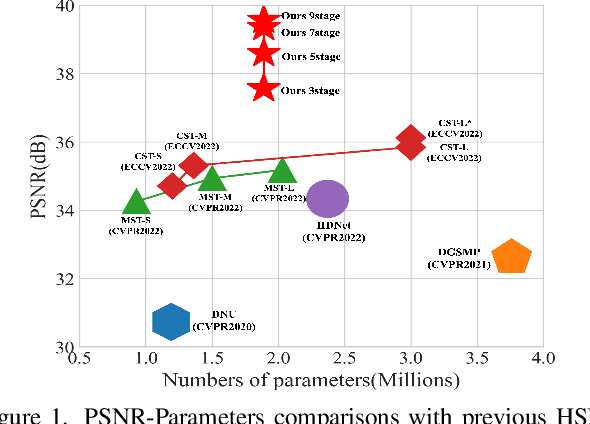
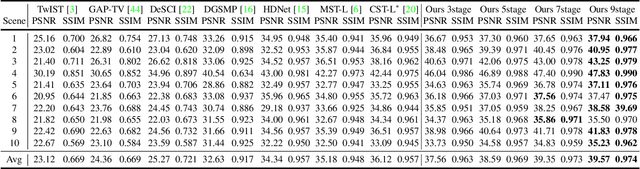
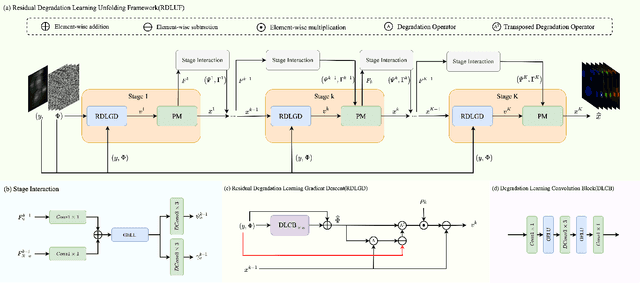

To acquire a snapshot spectral image, coded aperture snapshot spectral imaging (CASSI) is proposed. A core problem of the CASSI system is to recover the reliable and fine underlying 3D spectral cube from the 2D measurement. By alternately solving a data subproblem and a prior subproblem, deep unfolding methods achieve good performance. However, in the data subproblem, the used sensing matrix is ill-suited for the real degradation process due to the device errors caused by phase aberration, distortion; in the prior subproblem, it is important to design a suitable model to jointly exploit both spatial and spectral priors. In this paper, we propose a Residual Degradation Learning Unfolding Framework (RDLUF), which bridges the gap between the sensing matrix and the degradation process. Moreover, a Mix$S^2$ Transformer is designed via mixing priors across spectral and spatial to strengthen the spectral-spatial representation capability. Finally, plugging the Mix$S^2$ Transformer into the RDLUF leads to an end-to-end trainable and interpretable neural network RDLUF-Mix$S^2$. Experimental results establish the superior performance of the proposed method over existing ones.
Semantic-assisted image compression
Jan 29, 2022Conventional image compression methods typically aim at pixel-level consistency while ignoring the performance of downstream AI tasks.To solve this problem, this paper proposes a Semantic-Assisted Image Compression method (SAIC), which can maintain semantic-level consistency to enable high performance of downstream AI tasks.To this end, we train the compression network using semantic-level loss function. In particular, semantic-level loss is measured using gradient-based semantic weights mechanism (GSW). GSW directly consider downstream AI tasks' perceptual results. Then, this paper proposes a semantic-level distortion evaluation metric to quantify the amount of semantic information retained during the compression process. Experimental results show that the proposed SAIC method can retain more semantic-level information and achieve better performance of downstream AI tasks compared to the traditional deep learning-based method and the advanced perceptual method at the same compression ratio.