 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single Slice Thigh CT Muscle Group Segmentation with Domain Adaptation and Self-Training
Nov 30, 2022
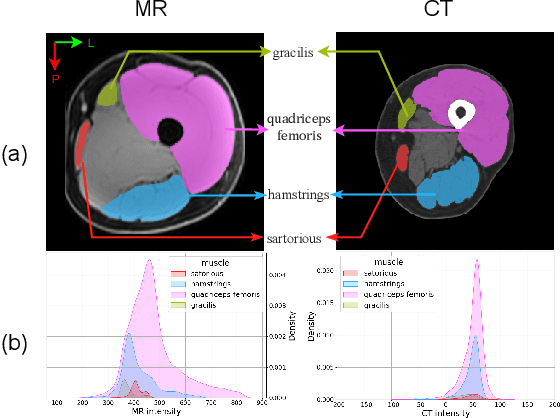
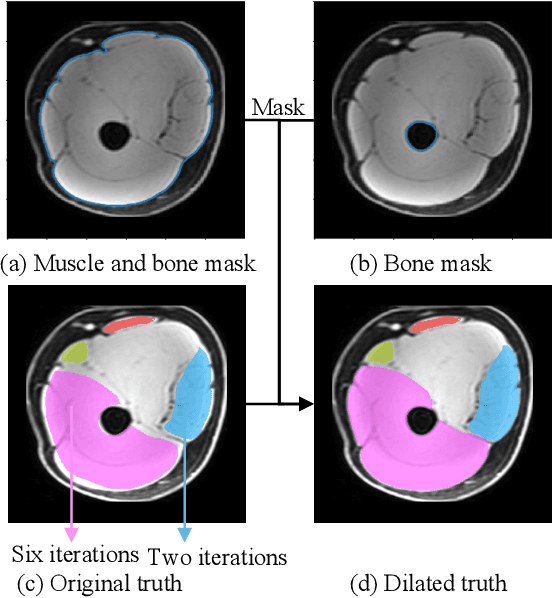
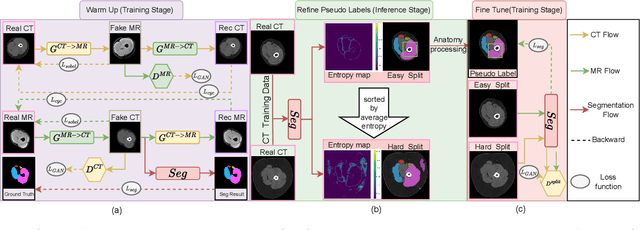
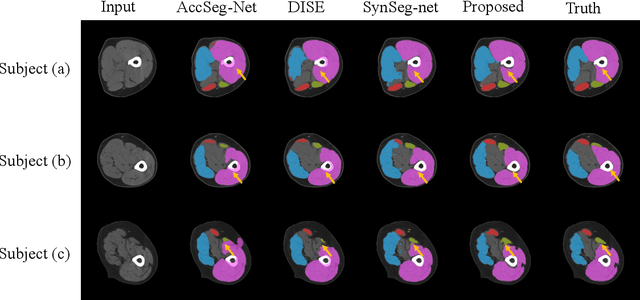
Objective: Thigh muscle group segmentation is important for assessment of muscle anatomy, metabolic disease and aging. Many efforts have been put into quantifying muscle tissues with magnetic resonance (MR) imaging including manual annotation of individual muscles. However, leveraging publicly available annotations in MR images to achieve muscle group segmentation on single slice computed tomography (CT) thigh images is challenging. Method: We propose an unsupervised domain adaptation pipeline with self-training to transfer labels from 3D MR to single CT slice. First, we transform the image appearance from MR to CT with CycleGAN and feed the synthesized CT images to a segmenter simultaneously. Single CT slices are divided into hard and easy cohorts based on the entropy of pseudo labels inferenced by the segmenter. After refining easy cohort pseudo labels based on anatomical assumption, self-training with easy and hard splits is applied to fine tune the segmenter. Results: On 152 withheld single CT thigh images, the proposed pipeline achieved a mean Dice of 0.888(0.041) across all muscle groups including sartorius, hamstrings, quadriceps femoris and gracilis. muscles Conclusion: To our best knowledge, this is the first pipeline to achieve thigh imaging domain adaptation from MR to CT. The proposed pipeline is effective and robust in extracting muscle groups on 2D single slice CT thigh images.The container is available for public use at https://github.com/MASILab/DA_CT_muscle_seg
FSOINet: Feature-Space Optimization-Inspired Network for Image Compressive Sensing
Apr 12, 2022
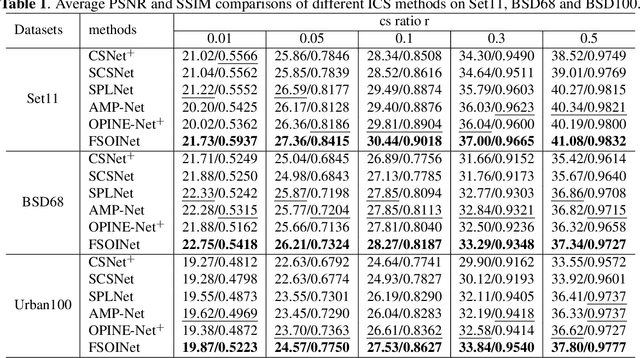
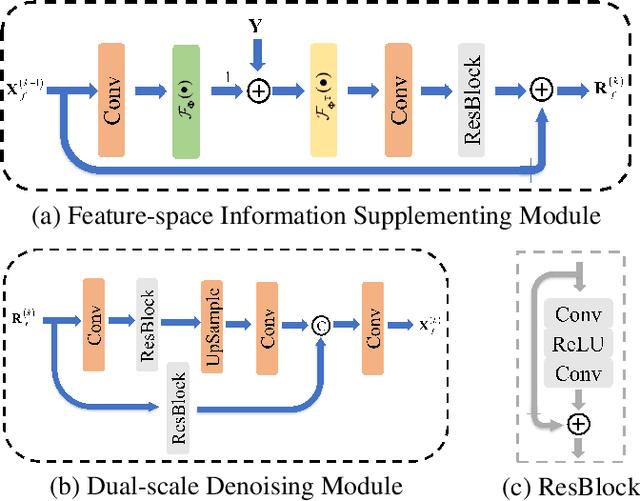

In recent years, deep learning-based image compressive sensing (ICS) methods have achieved brilliant success. Many optimization-inspired networks have been proposed to bring the insights of optimization algorithms into the network structure design and have achieved excellent reconstruction quality with low computational complexity. But they keep the information flow in pixel space as traditional algorithms by updating and transferring the image in pixel space, which does not fully use the information in the image features. In this paper, we propose the idea of achieving information flow phase by phase in feature space and design a Feature-Space Optimization-Inspired Network (dubbed FSOINet) to implement it by mapping both steps of proximal gradient descent algorithm from pixel space to feature space. Moreover, the sampling matrix is learned end-to-end with other network parameters. Experiments show that the proposed FSOINet outperforms the existing state-of-the-art methods by a large margin both quantitatively and qualitatively. The source code is available on https://github.com/cwjjun/FSOINet.
Giga-SSL: Self-Supervised Learning for Gigapixel Images
Dec 06, 2022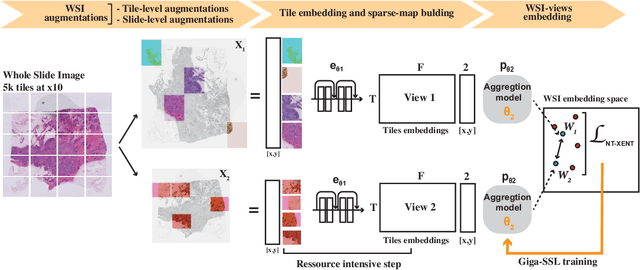
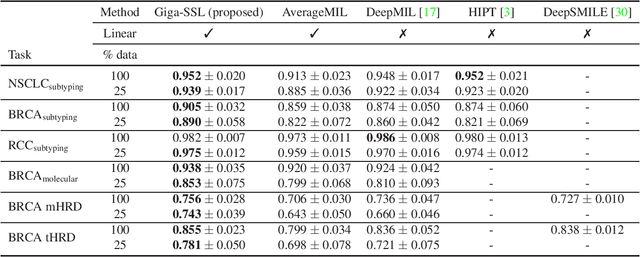
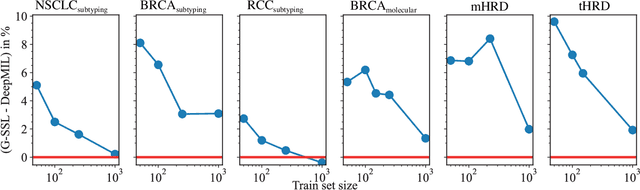
Whole slide images (WSI) are microscopy images of stained tissue slides routinely prepared for diagnosis and treatment selection in medical practice. WSI are very large (gigapixel size) and complex (made of up to millions of cells). The current state-of-the-art (SoTA) approach to classify WSI subdivides them into tiles, encodes them by pre-trained networks and applies Multiple Instance Learning (MIL) to train for specific downstream tasks. However, annotated datasets are often small, typically a few hundred to a few thousand WSI, which may cause overfitting and underperforming models. Conversely, the number of unannotated WSI is ever increasing, with datasets of tens of thousands (soon to be millions) of images available. While it has been previously proposed to use these unannotated data to identify suitable tile representations by self-supervised learning (SSL), downstream classification tasks still require full supervision because parts of the MIL architecture is not trained during tile level SSL pre-training. Here, we propose a strategy of slide level SSL to leverage the large number of WSI without annotations to infer powerful slide representations. Applying our method to The Cancer-Genome Atlas, one of the most widely used data resources in cancer research (16 TB image data), we are able to downsize the dataset to 23 MB without any loss in predictive power: we show that a linear classifier trained on top of these embeddings maintains or improves previous SoTA performances on various benchmark WSI classification tasks. Finally, we observe that training a classifier on these representations with tiny datasets (e.g. 50 slides) improved performances over SoTA by an average of +6.3 AUC points over all downstream tasks.
Learning Visual Planning Models from Partially Observed Images
Nov 25, 2022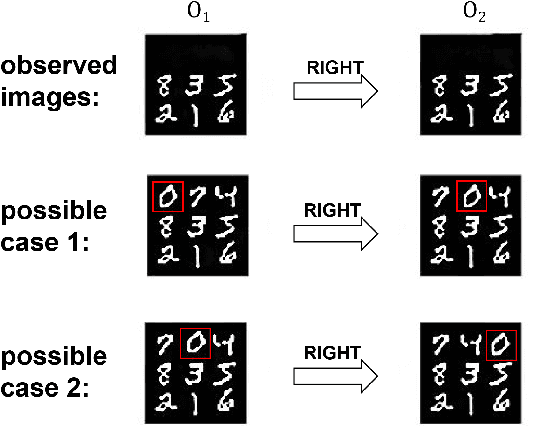
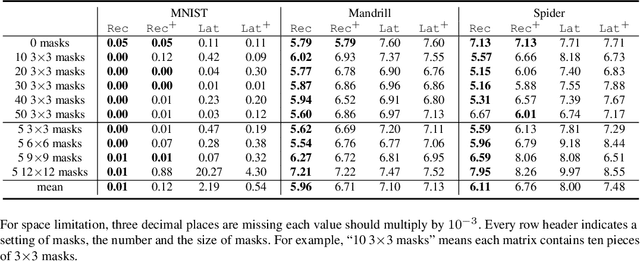
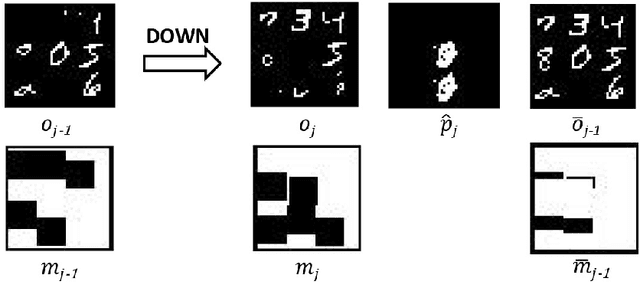
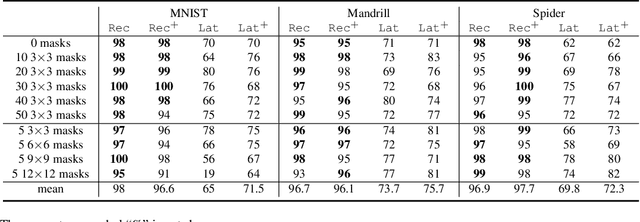
There has been increasing attention on planning model learning in classical planning. Most existing approaches, however, focus on learning planning models from structured data in symbolic representations. It is often difficult to obtain such structured data in real-world scenarios. Although a number of approaches have been developed for learning planning models from fully observed unstructured data (e.g., images), in many scenarios raw observations are often incomplete. In this paper, we provide a novel framework, \aType{Recplan}, for learning a transition model from partially observed raw image traces. More specifically, by considering the preceding and subsequent images in a trace, we learn the latent state representations of raw observations and then build a transition model based on such representations. Additionally, we propose a neural-network-based approach to learn a heuristic model that estimates the distance toward a given goal observation. Based on the learned transition model and heuristic model, we implement a classical planner for images. We exhibit empirically that our approach is more effective than a state-of-the-art approach of learning visual planning models in the environment with incomplete observations.
UNeXt: MLP-based Rapid Medical Image Segmentation Network
Mar 09, 2022
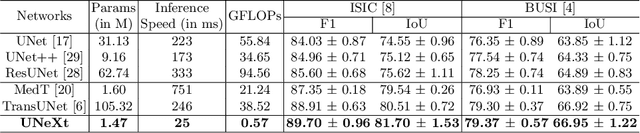
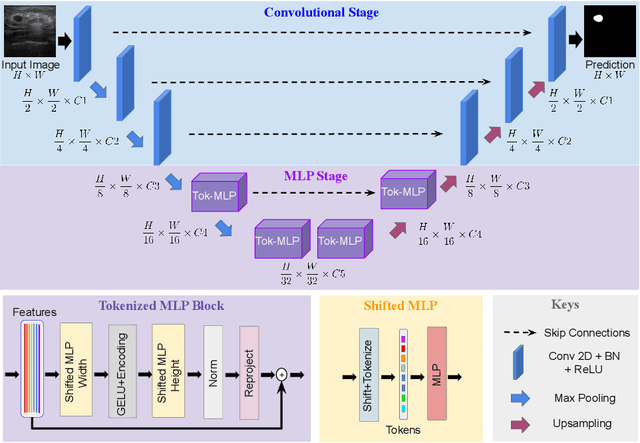
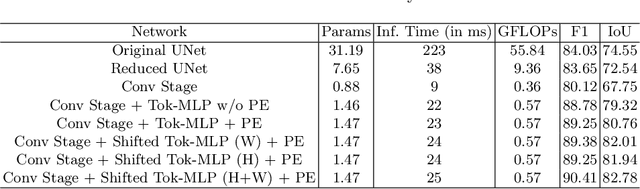
UNet and its latest extensions like TransUNet have been the leading medical image segmentation methods in recent years. However, these networks cannot be effectively adopted for rapid image segmentation in point-of-care applications as they are parameter-heavy, computationally complex and slow to use. To this end, we propose UNeXt which is a Convolutional multilayer perceptron (MLP) based network for image segmentation. We design UNeXt in an effective way with an early convolutional stage and a MLP stage in the latent stage. We propose a tokenized MLP block where we efficiently tokenize and project the convolutional features and use MLPs to model the representation. To further boost the performance, we propose shifting the channels of the inputs while feeding in to MLPs so as to focus on learning local dependencies. Using tokenized MLPs in latent space reduces the number of parameters and computational complexity while being able to result in a better representation to help segmentation. The network also consists of skip connections between various levels of encoder and decoder. We test UNeXt on multiple medical image segmentation datasets and show that we reduce the number of parameters by 72x, decrease the computational complexity by 68x, and improve the inference speed by 10x while also obtaining better segmentation performance over the state-of-the-art medical image segmentation architectures. Code is available at https://github.com/jeya-maria-jose/UNeXt-pytorch
Time-of-Day Neural Style Transfer for Architectural Photographs
Sep 13, 2022

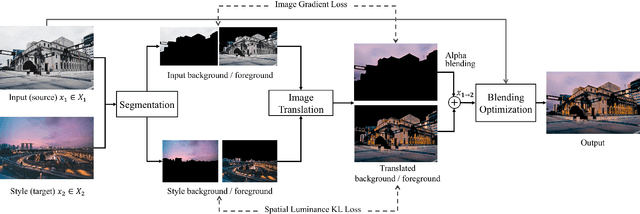

Architectural photography is a genre of photography that focuses on capturing a building or structure in the foreground with dramatic lighting in the background. Inspired by recent successes in image-to-image translation methods, we aim to perform style transfer for architectural photographs. However, the special composition in architectural photography poses great challenges for style transfer in this type of photographs. Existing neural style transfer methods treat the architectural images as a single entity, which would generate mismatched chrominance and destroy geometric features of the original architecture, yielding unrealistic lighting, wrong color rendition, and visual artifacts such as ghosting, appearance distortion, or color mismatching. In this paper, we specialize a neural style transfer method for architectural photography. Our method addresses the composition of the foreground and background in an architectural photograph in a two-branch neural network that separately considers the style transfer of the foreground and the background, respectively. Our method comprises a segmentation module, a learning-based image-to-image translation module, and an image blending optimization module. We trained our image-to-image translation neural network with a new dataset of unconstrained outdoor architectural photographs captured at different magic times of a day, utilizing additional semantic information for better chrominance matching and geometry preservation. Our experiments show that our method can produce photorealistic lighting and color rendition on both the foreground and background, and outperforms general image-to-image translation and arbitrary style transfer baselines quantitatively and qualitatively. Our code and data are available at https://github.com/hkust-vgd/architectural_style_transfer.
Improving Training and Inference of Face Recognition Models via Random Temperature Scaling
Dec 02, 2022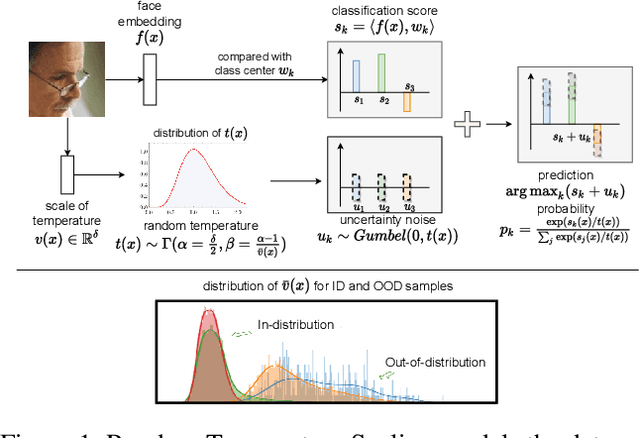
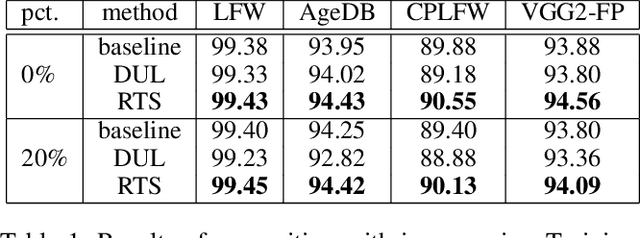
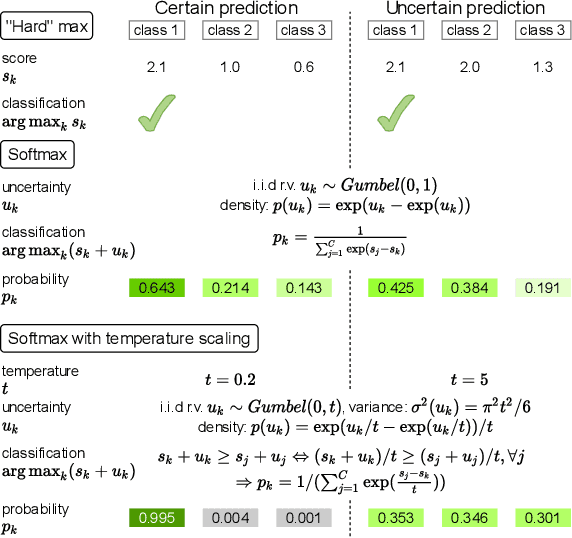
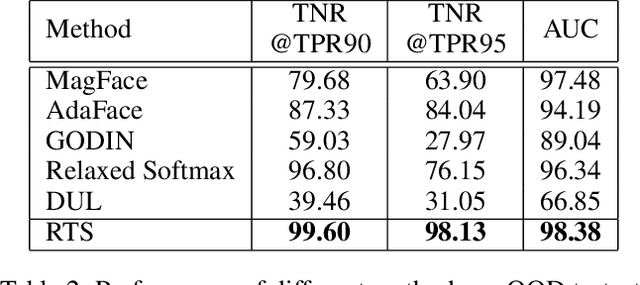
Data uncertainty is commonly observed in the images for face recognition (FR). However, deep learning algorithms often make predictions with high confidence even for uncertain or irrelevant inputs. Intuitively, FR algorithms can benefit from both the estimation of uncertainty and the detection of out-of-distribution (OOD) samples. Taking a probabilistic view of the current classification model, the temperature scalar is exactly the scale of uncertainty noise implicitly added in the softmax function. Meanwhile, the uncertainty of images in a dataset should follow a prior distribution. Based on the observation, a unified framework for uncertainty modeling and FR, Random Temperature Scaling (RTS), is proposed to learn a reliable FR algorithm. The benefits of RTS are two-fold. (1) In the training phase, it can adjust the learning strength of clean and noisy samples for stability and accuracy. (2) In the test phase, it can provide a score of confidence to detect uncertain, low-quality and even OOD samples, without training on extra labels. Extensive experiments on FR benchmarks demonstrate that the magnitude of variance in RTS, which serves as an OOD detection metric, is closely related to the uncertainty of the input image. RTS can achieve top performance on both the FR and OOD detection tasks. Moreover, the model trained with RTS can perform robustly on datasets with noise. The proposed module is light-weight and only adds negligible computation cost to the model.
Progressive with Purpose: Guiding Progressive Inpainting DNNs through Context and Structure
Sep 21, 2022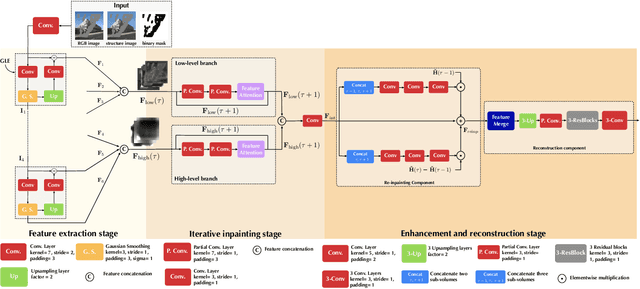



The advent of deep learning in the past decade has significantly helped advance image inpainting. Although achieving promising performance, deep learning-based inpainting algorithms still struggle from the distortion caused by the fusion of structural and contextual features, which are commonly obtained from, respectively, deep and shallow layers of a convolutional encoder. Motivated by this observation, we propose a novel progressive inpainting network that maintains the structural and contextual integrity of a processed image. More specifically, inspired by the Gaussian and Laplacian pyramids, the core of the proposed network is a feature extraction module named GLE. Stacking GLE modules enables the network to extract image features from different image frequency components. This ability is important to maintain structural and contextual integrity, for high frequency components correspond to structural information while low frequency components correspond to contextual information. The proposed network utilizes the GLE features to progressively fill in missing regions in a corrupted image in an iterative manner. Our benchmarking experiments demonstrate that the proposed method achieves clear improvement in performance over many state-of-the-art inpainting algorithms.
MouseGAN++: Unsupervised Disentanglement and Contrastive Representation for Multiple MRI Modalities Synthesis and Structural Segmentation of Mouse Brain
Dec 04, 2022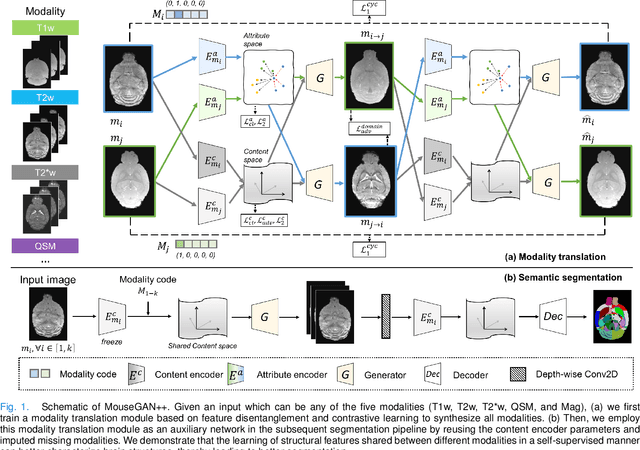
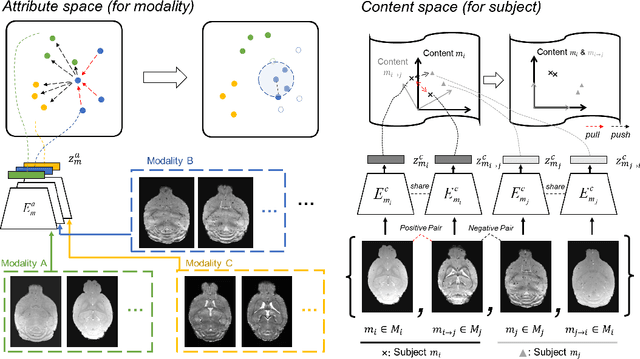
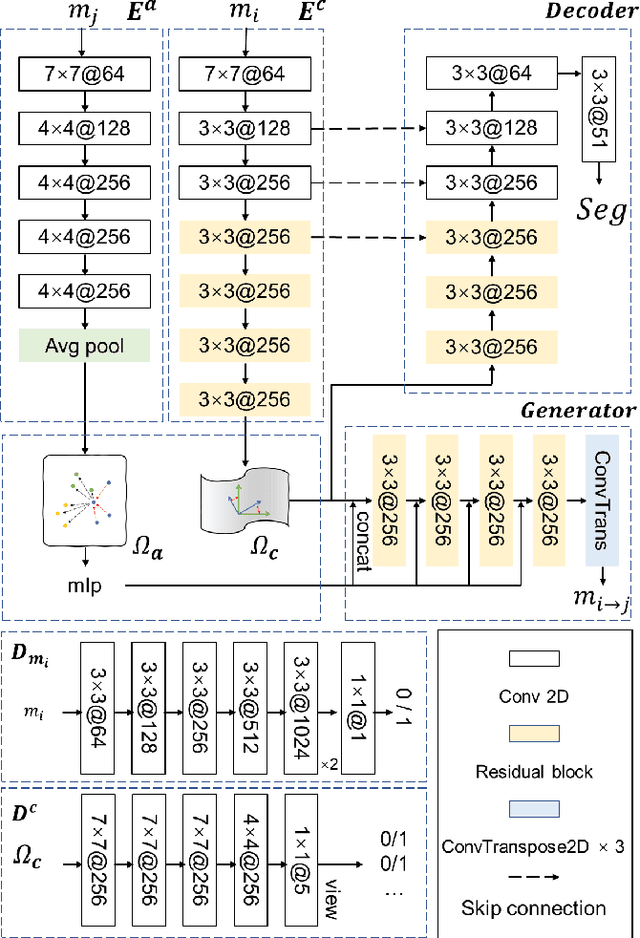
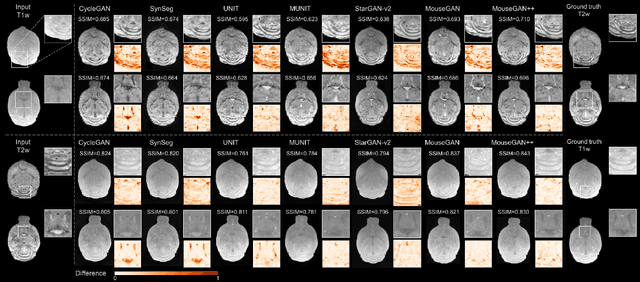
Segmenting the fine structure of the mouse brain on magnetic resonance (MR) images is critical for delineating morphological regions, analyzing brain function, and understanding their relationships. Compared to a single MRI modality, multimodal MRI data provide complementary tissue features that can be exploited by deep learning models, resulting in better segmentation results. However, multimodal mouse brain MRI data is often lacking, making automatic segmentation of mouse brain fine structure a very challenging task. To address this issue, it is necessary to fuse multimodal MRI data to produce distinguished contrasts in different brain structures. Hence, we propose a novel disentangled and contrastive GAN-based framework, named MouseGAN++, to synthesize multiple MR modalities from single ones in a structure-preserving manner, thus improving the segmentation performance by imputing missing modalities and multi-modality fusion. Our results demonstrate that the translation performance of our method outperforms the state-of-the-art methods. Using the subsequently learned modality-invariant information as well as the modality-translated images, MouseGAN++ can segment fine brain structures with averaged dice coefficients of 90.0% (T2w) and 87.9% (T1w), respectively, achieving around +10% performance improvement compared to the state-of-the-art algorithms. Our results demonstrate that MouseGAN++, as a simultaneous image synthesis and segmentation method, can be used to fuse cross-modality information in an unpaired manner and yield more robust performance in the absence of multimodal data. We release our method as a mouse brain structural segmentation tool for free academic usage at https://github.com/yu02019.
AdaTriplet: Adaptive Gradient Triplet Loss with Automatic Margin Learning for Forensic Medical Image Matching
May 10, 2022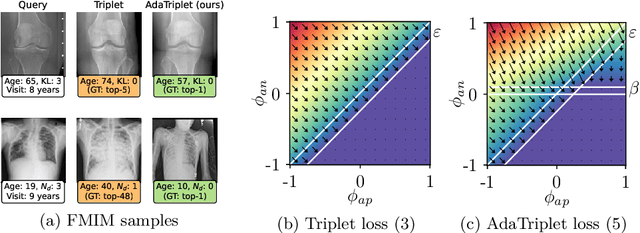
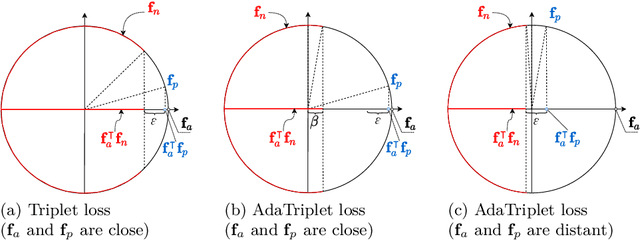
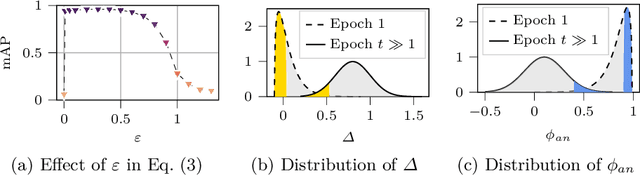
This paper tackles the challenge of forensic medical image matching (FMIM) using deep neural networks (DNNs). FMIM is a particular case of content-based image retrieval (CBIR). The main challenge in FMIM compared to the general case of CBIR, is that the subject to whom a query image belongs may be affected by aging and progressive degenerative disorders, making it difficult to match data on a subject level. CBIR with DNNs is generally solved by minimizing a ranking loss, such as Triplet loss (TL), computed on image representations extracted by a DNN from the original data. TL, in particular, operates on triplets: anchor, positive (similar to anchor) and negative (dissimilar to anchor). Although TL has been shown to perform well in many CBIR tasks, it still has limitations, which we identify and analyze in this work. In this paper, we introduce (i) the AdaTriplet loss -- an extension of TL whose gradients adapt to different difficulty levels of negative samples, and (ii) the AutoMargin method -- a technique to adjust hyperparameters of margin-based losses such as TL and our proposed loss dynamically. Our results are evaluated on two large-scale benchmarks for FMIM based on the Osteoarthritis Initiative and Chest X-ray-14 datasets. The codes allowing replication of this study have been made publicly available at \url{https://github.com/Oulu-IMEDS/AdaTriplet}.