 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Matting: A Benchmark Study on Soft Segmentation Method for Pulmonary Nodules Applied in Computed Tomography
Oct 11, 2022

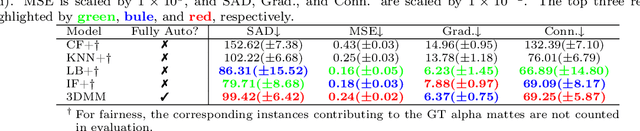
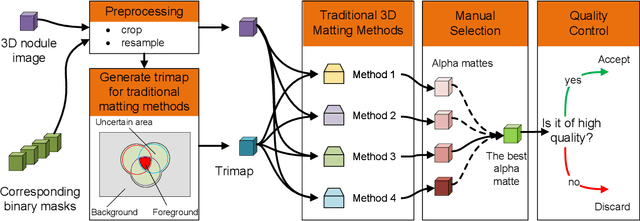
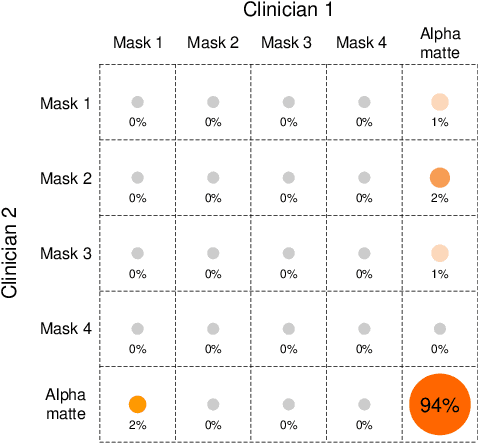
Usually, lesions are not isolated but are associated with the surrounding tissues. For example, the growth of a tumour can depend on or infiltrate into the surrounding tissues. Due to the pathological nature of the lesions, it is challenging to distinguish their boundaries in medical imaging. However, these uncertain regions may contain diagnostic information. Therefore, the simple binarization of lesions by traditional binary segmentation can result in the loss of diagnostic information. In this work, we introduce the image matting into the 3D scenes and use the alpha matte, i.e., a soft mask, to describe lesions in a 3D medical image. The traditional soft mask acted as a training trick to compensate for the easily mislabelled or under-labelled ambiguous regions. In contrast, 3D matting uses soft segmentation to characterize the uncertain regions more finely, which means that it retains more structural information for subsequent diagnosis and treatment. The current study of image matting methods in 3D is limited. To address this issue, we conduct a comprehensive study of 3D matting, including both traditional and deep-learning-based methods. We adapt four state-of-the-art 2D image matting algorithms to 3D scenes and further customize the methods for CT images to calibrate the alpha matte with the radiodensity. Moreover, we propose the first end-to-end deep 3D matting network and implement a solid 3D medical image matting benchmark. Its efficient counterparts are also proposed to achieve a good performance-computation balance. Furthermore, there is no high-quality annotated dataset related to 3D matting, slowing down the development of data-driven deep-learning-based methods. To address this issue, we construct the first 3D medical matting dataset. The validity of the dataset was verified through clinicians' assessments and downstream experiments.
DELAD: Deep Landweber-guided deconvolution with Hessian and sparse prior
Sep 30, 2022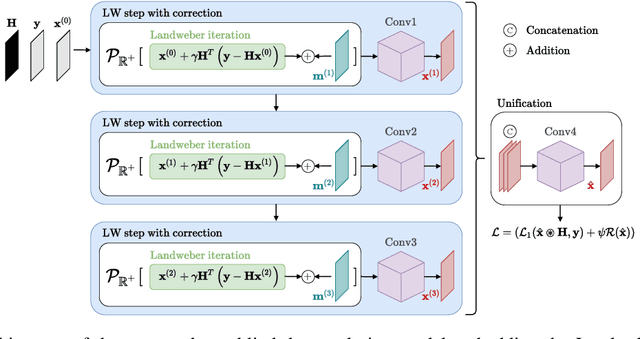
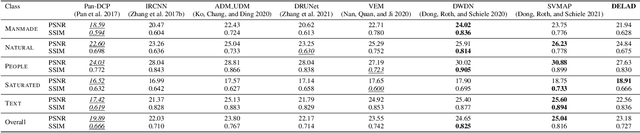

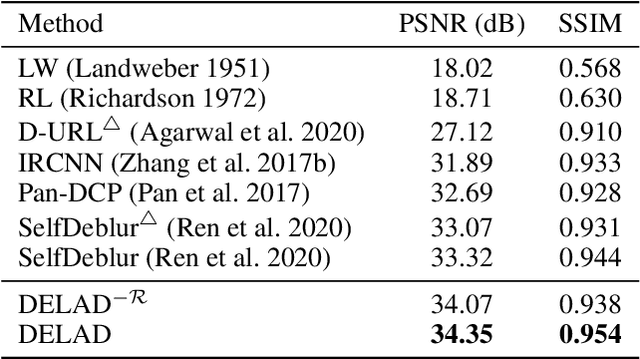
We present a model for non-blind image deconvolution that incorporates the classic iterative method into a deep learning application. Instead of using large over-parameterised generative networks to create sharp picture representations, we build our network based on the iterative Landweber deconvolution algorithm, which is integrated with trainable convolutional layers to enhance the recovered image structures and details. Additional to the data fidelity term, we also add Hessian and sparse constraints as regularization terms to improve the image reconstruction quality. Our proposed model is \textit{self-supervised} and converges to a solution based purely on the input blurred image and respective blur kernel without the requirement of any pre-training. We evaluate our technique using standard computer vision benchmarking datasets as well as real microscope images obtained by our enhanced depth-of-field (EDOF) underwater microscope, demonstrating the capabilities of our model in a real-world application. The quantitative results demonstrate that our approach is competitive with state-of-the-art non-blind image deblurring methods despite having a fraction of the parameters and not being pre-trained, demonstrating the efficiency and efficacy of embedding a classic deconvolution approach inside a deep network.
SizeGAN: Improving Size Representation in Clothing Catalogs
Nov 05, 2022
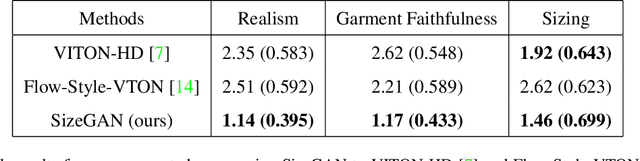
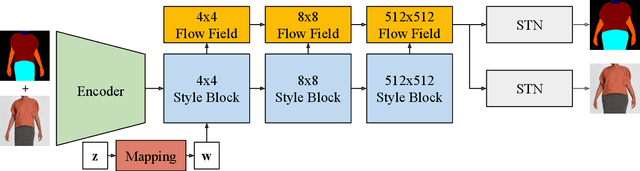
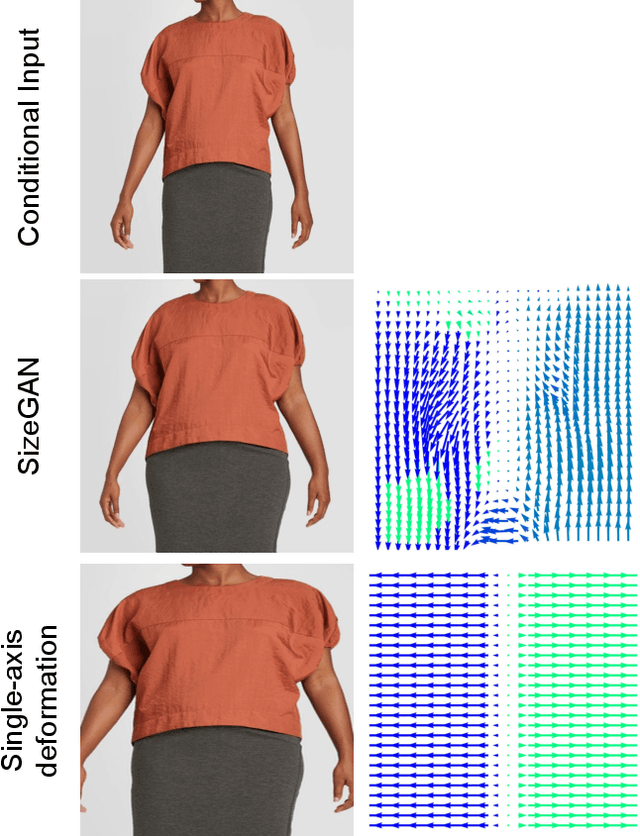
Online clothing catalogs lack diversity in body shape and garment size. Brands commonly display their garments on models of one or two sizes, rarely including plus-size models. In this work, we propose a new method, SizeGAN, for generating images of garments on different-sized models. To change the garment and model size while maintaining a photorealistic image, we incorporate image alignment ideas from the medical imaging literature into the StyleGAN2-ADA architecture. Our method learns deformation fields at multiple resolutions and uses a spatial transformer to modify the garment and model size. We evaluate our approach along three dimensions: realism, garment faithfulness, and size. To our knowledge, SizeGAN is the first method to focus on this size under-representation problem for modeling clothing. We provide an analysis comparing SizeGAN to other plausible approaches and additionally provide the first clothing dataset with size labels. In a user study comparing SizeGAN and two recent virtual try-on methods, we show that our method ranks first in each dimension, and was vastly preferred for realism and garment faithfulness. In comparison to most previous work, which has focused on generating photorealistic images of garments, our work shows that it is possible to generate images that are both photorealistic and cover diverse garment sizes.
A Survey of Deep Face Restoration: Denoise, Super-Resolution, Deblur, Artifact Removal
Nov 05, 2022

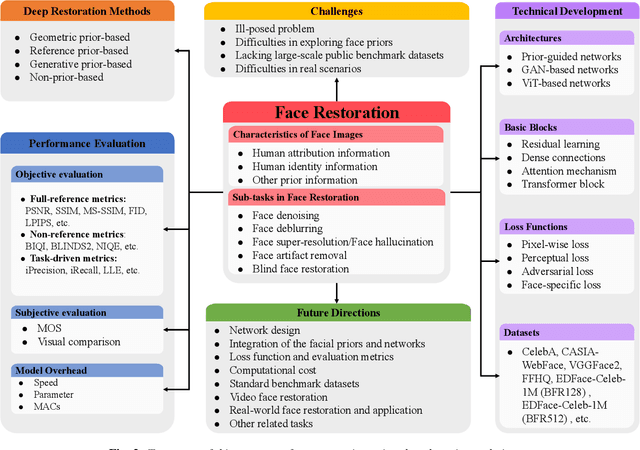
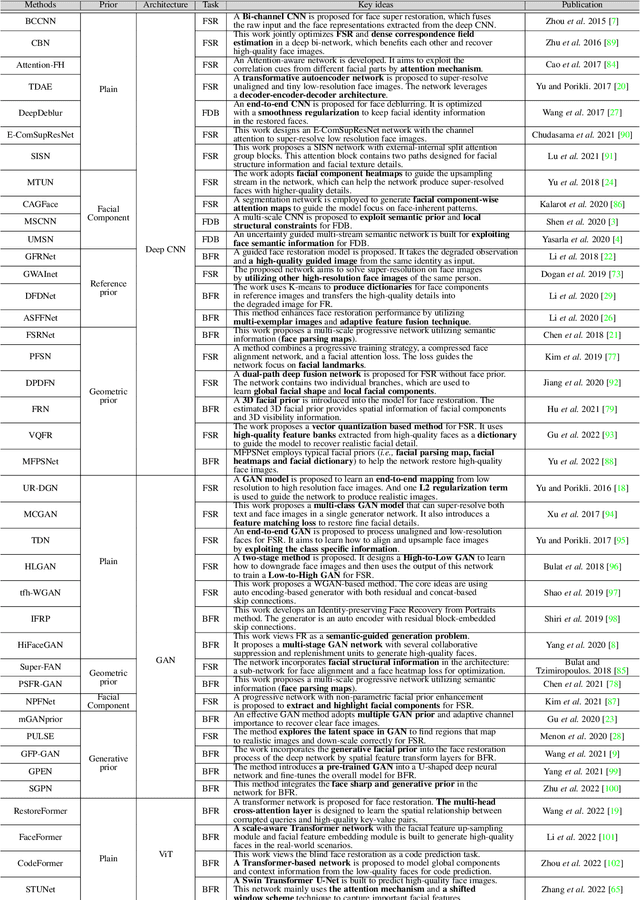
Face Restoration (FR) aims to restore High-Quality (HQ) faces from Low-Quality (LQ) input images, which is a domain-specific image restoration problem in the low-level computer vision area. The early face restoration methods mainly use statistic priors and degradation models, which are difficult to meet the requirements of real-world applications in practice. In recent years, face restoration has witnessed great progress after stepping into the deep learning era. However, there are few works to study deep learning-based face restoration methods systematically. Thus, this paper comprehensively surveys recent advances in deep learning techniques for face restoration. Specifically, we first summarize different problem formulations and analyze the characteristic of the face image. Second, we discuss the challenges of face restoration. Concerning these challenges, we present a comprehensive review of existing FR methods, including prior based methods and deep learning-based methods. Then, we explore developed techniques in the task of FR covering network architectures, loss functions, and benchmark datasets. We also conduct a systematic benchmark evaluation on representative methods. Finally, we discuss future directions, including network designs, metrics, benchmark datasets, applications,etc. We also provide an open-source repository for all the discussed methods, which is available at https://github.com/TaoWangzj/Awesome-Face-Restoration.
FLAIR #1: semantic segmentation and domain adaptation dataset
Nov 28, 2022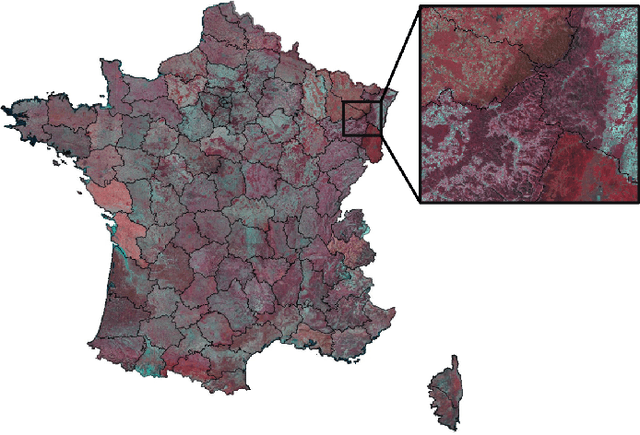
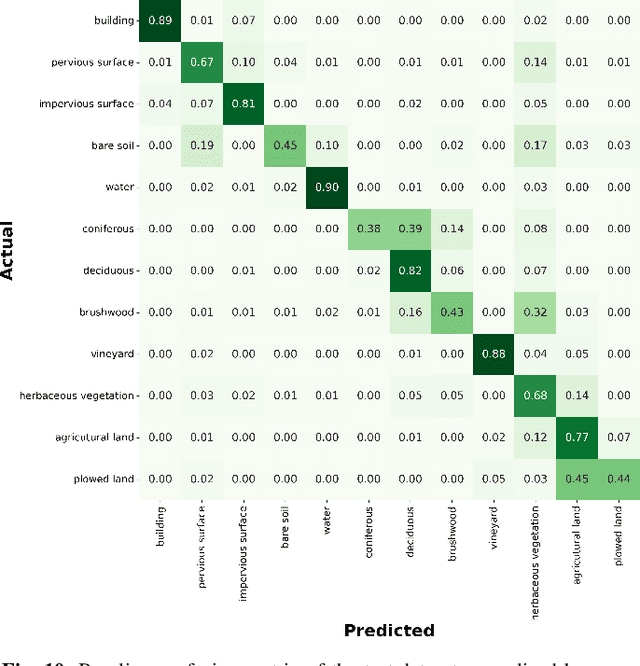
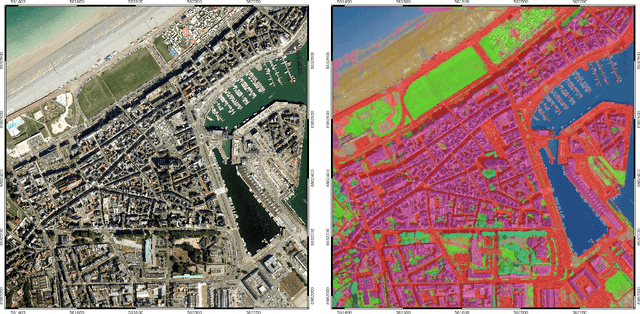
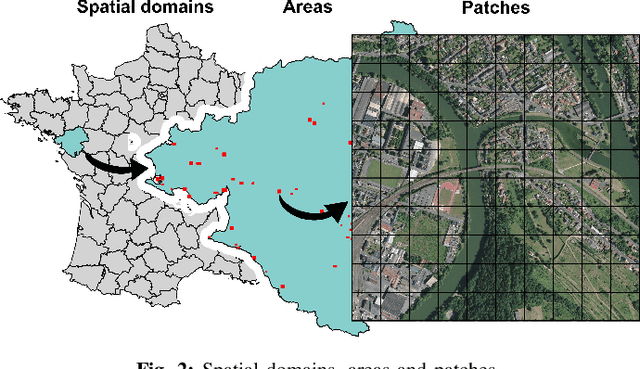
The French National Institute of Geographical and Forest Information (IGN) has the mission to document and measure land-cover on French territory and provides referential geographical datasets, including high-resolution aerial images and topographic maps. The monitoring of land-cover plays a crucial role in land management and planning initiatives, which can have significant socio-economic and environmental impact. Together with remote sensing technologies, artificial intelligence (IA) promises to become a powerful tool in determining land-cover and its evolution. IGN is currently exploring the potential of IA in the production of high-resolution land cover maps. Notably, deep learning methods are employed to obtain a semantic segmentation of aerial images. However, territories as large as France imply heterogeneous contexts: variations in landscapes and image acquisition make it challenging to provide uniform, reliable and accurate results across all of France. The FLAIR-one dataset presented is part of the dataset currently used at IGN to establish the French national reference land cover map "Occupation du sol \`a grande \'echelle" (OCS- GE).
Establishment of Neural Networks Robust to Label Noise
Nov 28, 2022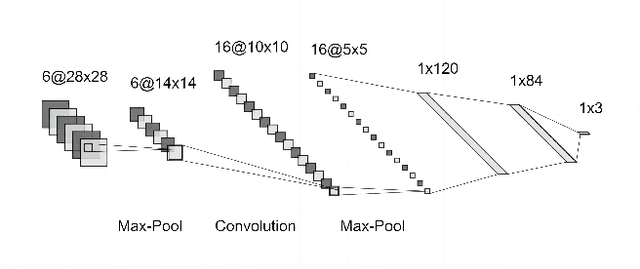


Label noise is a significant obstacle in deep learning model training. It can have a considerable impact on the performance of image classification models, particularly deep neural networks, which are especially susceptible because they have a strong propensity to memorise noisy labels. In this paper, we have examined the fundamental concept underlying related label noise approaches. A transition matrix estimator has been created, and its effectiveness against the actual transition matrix has been demonstrated. In addition, we examined the label noise robustness of two convolutional neural network classifiers with LeNet and AlexNet designs. The two FashionMINIST datasets have revealed the robustness of both models. We are not efficiently able to demonstrate the influence of the transition matrix noise correction on robustness enhancements due to our inability to correctly tune the complex convolutional neural network model due to time and computing resource constraints. There is a need for additional effort to fine-tune the neural network model and explore the precision of the estimated transition model in future research.
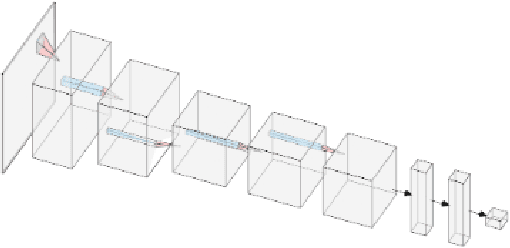
DeepAngle: Fast calculation of contact angles in tomography images using deep learning
Nov 28, 2022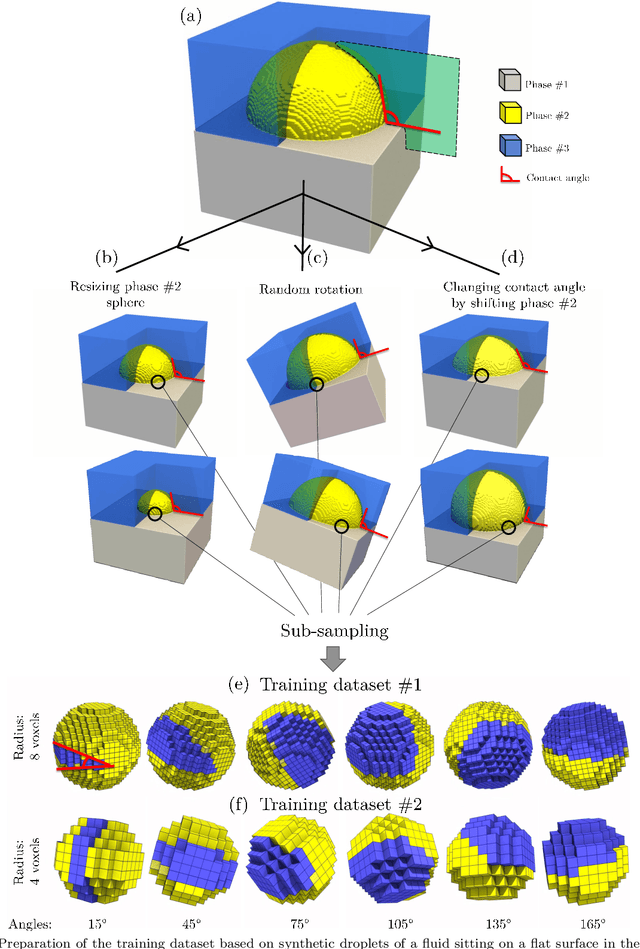
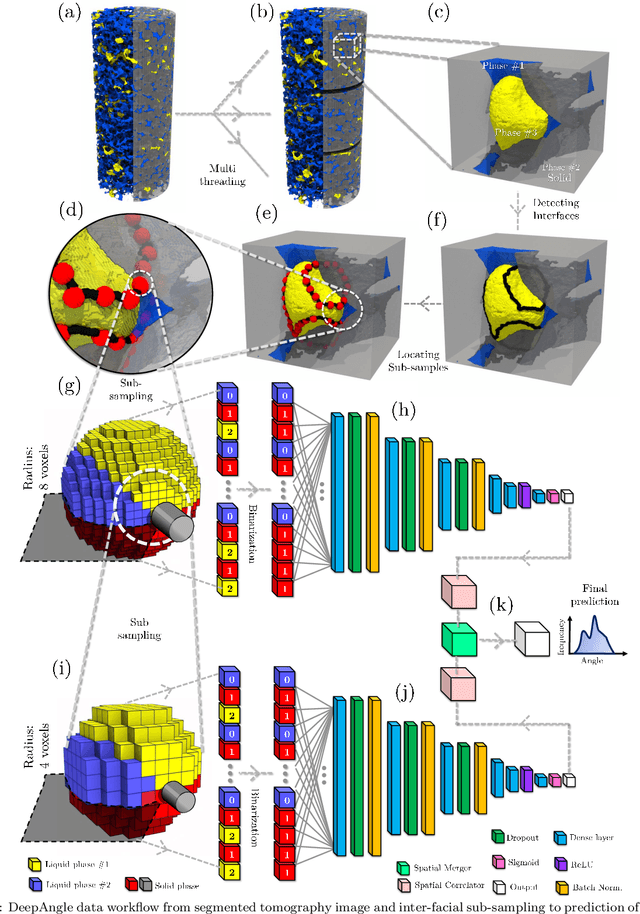
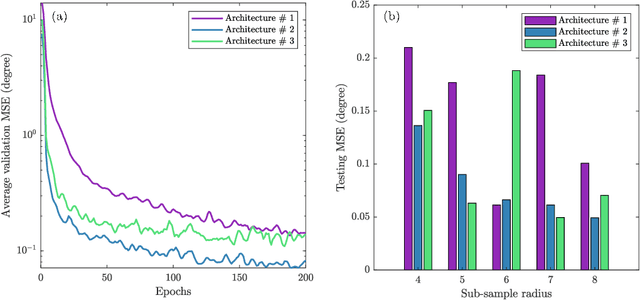
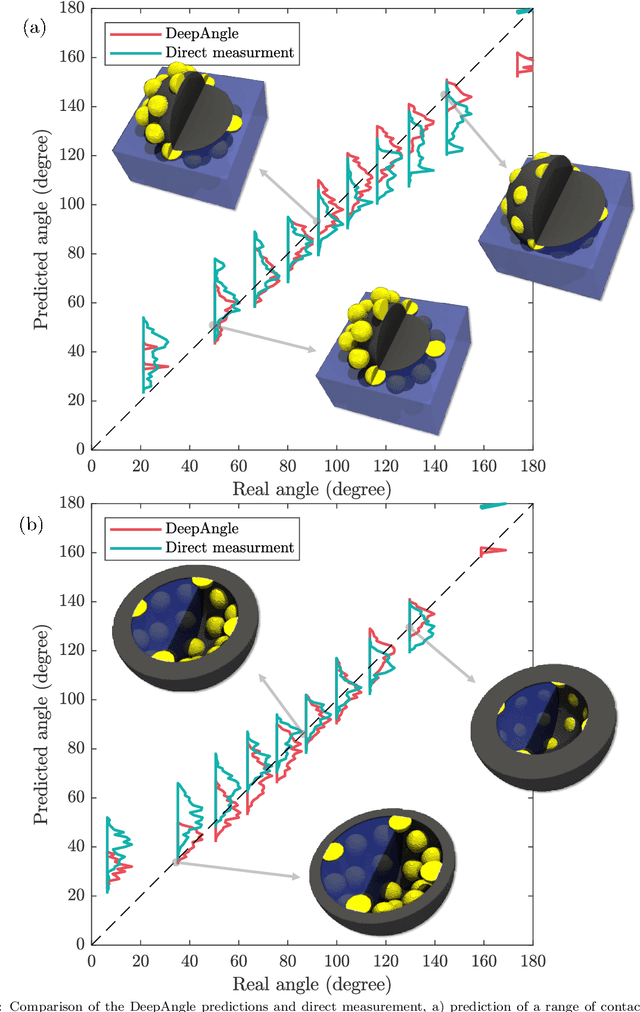
DeepAngle is a machine learning-based method to determine the contact angles of different phases in the tomography images of porous materials. Measurement of angles in 3--D needs to be done within the surface perpendicular to the angle planes, and it could become inaccurate when dealing with the discretized space of the image voxels. A computationally intensive solution is to correlate and vectorize all surfaces using an adaptable grid, and then measure the angles within the desired planes. On the contrary, the present study provides a rapid and low-cost technique powered by deep learning to estimate the interfacial angles directly from images. DeepAngle is tested on both synthetic and realistic images against the direct measurement technique and found to improve the r-squared by 5 to 16% while lowering the computational cost 20 times. This rapid method is especially applicable for processing large tomography data and time-resolved images, which is computationally intensive. The developed code and the dataset are available at an open repository on GitHub (https://www.github.com/ArashRabbani/DeepAngle).
Toward Global Sensing Quality Maximization: A Configuration Optimization Scheme for Camera Networks
Nov 28, 2022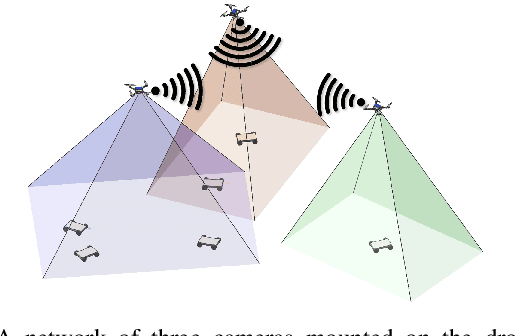
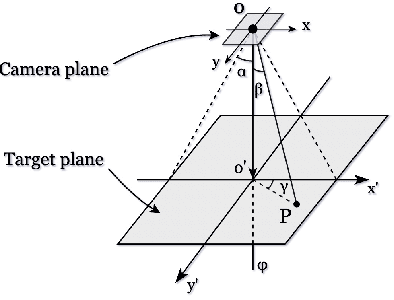
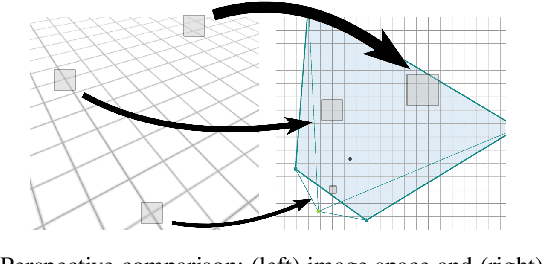
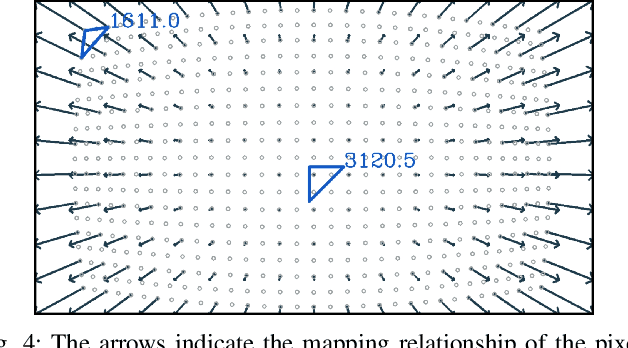
The performance of a camera network monitoring a set of targets depends crucially on the configuration of the cameras. In this paper, we investigate the reconfiguration strategy for the parameterized camera network model, with which the sensing qualities of the multiple targets can be optimized globally and simultaneously. We first propose to use the number of pixels occupied by a unit-length object in image as a metric of the sensing quality of the object, which is determined by the parameters of the camera, such as intrinsic, extrinsic, and distortional coefficients. Then, we form a single quantity that measures the sensing quality of the targets by the camera network. This quantity further serves as the objective function of our optimization problem to obtain the optimal camera configuration. We verify the effectiveness of our approach through extensive simulations and experiments, and the results reveal its improved performance on the AprilTag detection tasks. Codes and related utilities for this work are open-sourced and available at https://github.com/sszxc/MultiCam-Simulation.
Reinforced Swin-Convs Transformer for Underwater Image Enhancement
May 01, 2022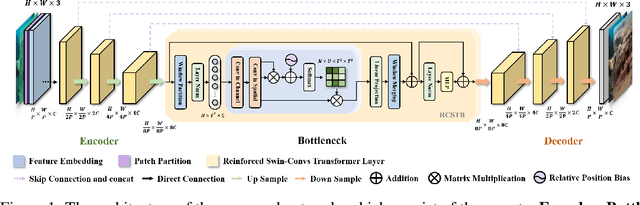
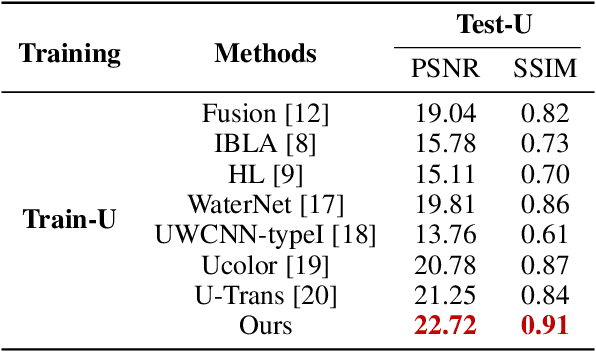
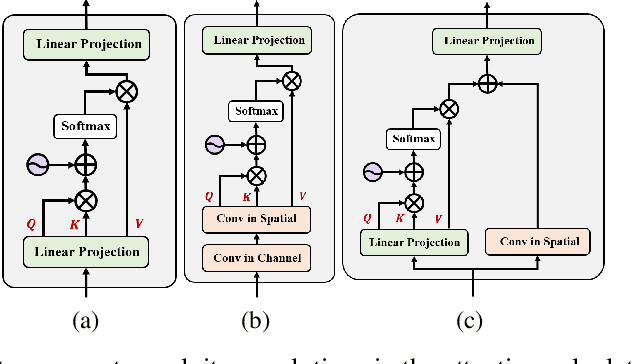
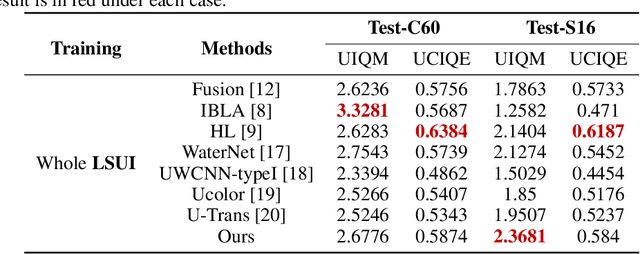
Underwater Image Enhancement (UIE) technology aims to tackle the challenge of restoring the degraded underwater images due to light absorption and scattering. To address problems, a novel U-Net based Reinforced Swin-Convs Transformer for the Underwater Image Enhancement method (URSCT-UIE) is proposed. Specifically, with the deficiency of U-Net based on pure convolutions, we embedded the Swin Transformer into U-Net for improving the ability to capture the global dependency. Then, given the inadequacy of the Swin Transformer capturing the local attention, the reintroduction of convolutions may capture more local attention. Thus, we provide an ingenious manner for the fusion of convolutions and the core attention mechanism to build a Reinforced Swin-Convs Transformer Block (RSCTB) for capturing more local attention, which is reinforced in the channel and the spatial attention of the Swin Transformer. Finally, the experimental results on available datasets demonstrate that the proposed URSCT-UIE achieves state-of-the-art performance compared with other methods in terms of both subjective and objective evaluations. The code will be released on GitHub after acceptance.
Comparison and Analysis of Image-to-Image Generative Adversarial Networks: A Survey
Dec 23, 2021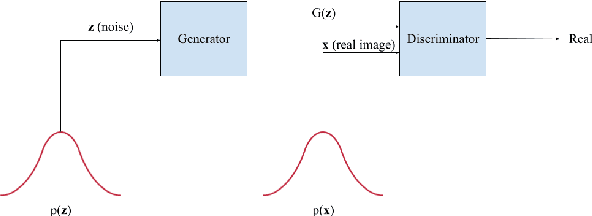
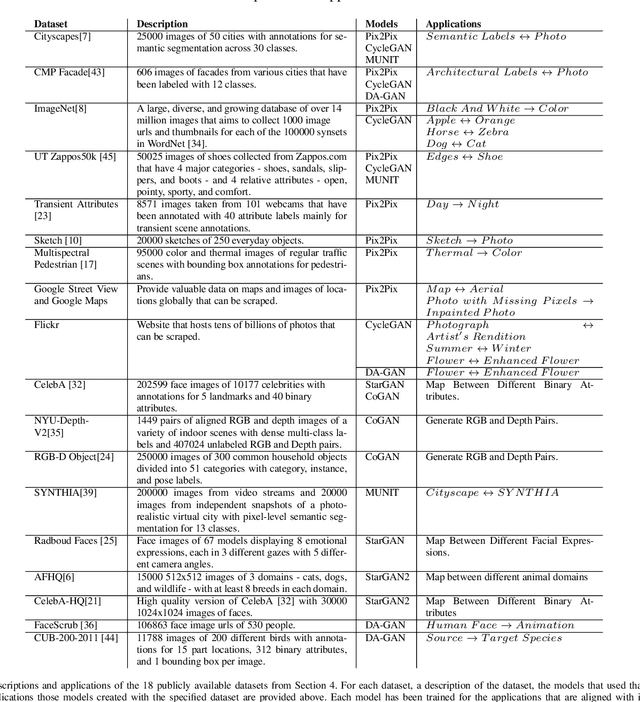
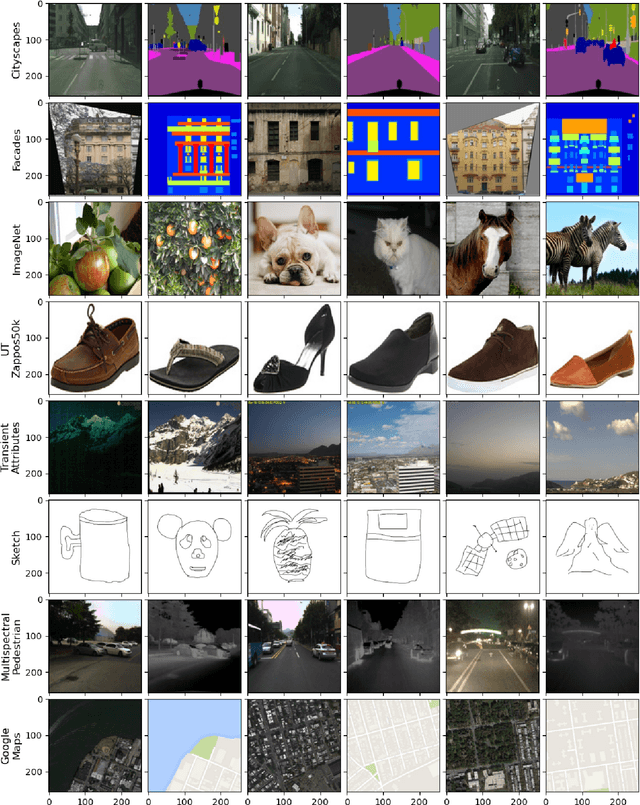
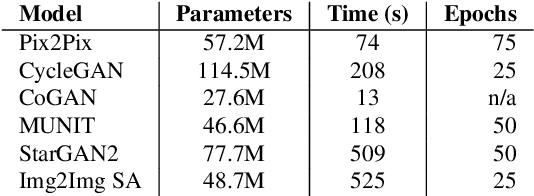
Generative Adversarial Networks (GANs) have recently introduced effective methods of performing Image-to-Image translations. These models can be applied and generalized to a variety of domains in Image-to-Image translation without changing any parameters. In this paper, we survey and analyze eight Image-to-Image Generative Adversarial Networks: Pix2Px, CycleGAN, CoGAN, StarGAN, MUNIT, StarGAN2, DA-GAN, and Self Attention GAN. Each of these models presented state-of-the-art results and introduced new techniques to build Image-to-Image GANs. In addition to a survey of the models, we also survey the 18 datasets they were trained on and the 9 metrics they were evaluated on. Finally, we present results of a controlled experiment for 6 of these models on a common set of metrics and datasets. The results were mixed and showed that on certain datasets, tasks, and metrics some models outperformed others. The last section of this paper discusses those results and establishes areas of future research. As researchers continue to innovate new Image-to-Image GANs, it is important that they gain a good understanding of the existing methods, datasets, and metrics. This paper provides a comprehensive overview and discussion to help build this foundation.