 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing Image Generation to Mitigate Spurious Correlations
Dec 27, 2024



Instance features in images exhibit spurious correlations with background features, affecting the training process of deep neural classifiers. This leads to insufficient attention to instance features by the classifier, resulting in erroneous classification outcomes. In this paper, we propose a data augmentation method called Spurious Correlations Guided Synthesis (SCGS) that mitigates spurious correlations through image generation model. This approach does not require expensive spurious attribute (group) labels for the training data and can be widely applied to other debiasing methods. Specifically, SCGS first identifies the incorrect attention regions of a pre-trained classifier on the training images, and then uses an image generation model to generate new training data based on these incorrect attended regions. SCGS increases the diversity and scale of the dataset to reduce the impact of spurious correlations on classifiers. Changes in the classifier's attention regions and experimental results on three different domain datasets demonstrate that this method is effective in reducing the classifier's reliance on spurious correlations.
WaterMamba: Visual State Space Model for Underwater Image Enhancement
May 14, 2024Underwater imaging often suffers from low quality due to factors affecting light propagation and absorption in water. To improve image quality, some underwater image enhancement (UIE) methods based on convolutional neural networks (CNN) and Transformer have been proposed. However, CNN-based UIE methods are limited in modeling long-range dependencies, and Transformer-based methods involve a large number of parameters and complex self-attention mechanisms, posing efficiency challenges. Considering computational complexity and severe underwater image degradation, a state space model (SSM) with linear computational complexity for UIE, named WaterMamba, is proposed. We propose spatial-channel omnidirectional selective scan (SCOSS) blocks comprising spatial-channel coordinate omnidirectional selective scan (SCCOSS) modules and a multi-scale feedforward network (MSFFN). The SCOSS block models pixel and channel information flow, addressing dependencies. The MSFFN facilitates information flow adjustment and promotes synchronized operations within SCCOSS modules. Extensive experiments showcase WaterMamba's cutting-edge performance with reduced parameters and computational resources, outperforming state-of-the-art methods on various datasets, validating its effectiveness and generalizability. The code will be released on GitHub after acceptance.
Windformer:Bi-Directional Long-Distance Spatio-Temporal Network For Wind Speed Prediction
Nov 24, 2023Wind speed prediction is critical to the management of wind power generation. Due to the large range of wind speed fluctuations and wake effect, there may also be strong correlations between long-distance wind turbines. This difficult-to-extract feature has become a bottleneck for improving accuracy. History and future time information includes the trend of airflow changes, whether this dynamic information can be utilized will also affect the prediction effect. In response to the above problems, this paper proposes Windformer. First, Windformer divides the wind turbine cluster into multiple non-overlapping windows and calculates correlations inside the windows, then shifts the windows partially to provide connectivity between windows, and finally fuses multi-channel features based on detailed and global information. To dynamically model the change process of wind speed, this paper extracts time series in both history and future directions simultaneously. Compared with other current-advanced methods, the Mean Square Error (MSE) of Windformer is reduced by 0.5\% to 15\% on two datasets from NERL.
Ultrasound Image Segmentation of Thyroid Nodule via Latent Semantic Feature Co-Registration
Oct 13, 2023Segmentation of nodules in thyroid ultrasound imaging plays a crucial role in the detection and treatment of thyroid cancer. However, owing to the diversity of scanner vendors and imaging protocols in different hospitals, the automatic segmentation model, which has already demonstrated expert-level accuracy in the field of medical image segmentation, finds its accuracy reduced as the result of its weak generalization performance when being applied in clinically realistic environments. To address this issue, the present paper proposes ASTN, a framework for thyroid nodule segmentation achieved through a new type co-registration network. By extracting latent semantic information from the atlas and target images and utilizing in-depth features to accomplish the co-registration of nodules in thyroid ultrasound images, this framework can ensure the integrity of anatomical structure and reduce the impact on segmentation as the result of overall differences in image caused by different devices. In addition, this paper also provides an atlas selection algorithm to mitigate the difficulty of co-registration. As shown by the evaluation results collected from the datasets of different devices, thanks to the method we proposed, the model generalization has been greatly improved while maintaining a high level of segmentation accuracy.
Two-Stream Joint-Training for Speaker Independent Acoustic-to-Articulatory Inversion
Feb 26, 2023Acoustic-to-articulatory inversion (AAI) aims to estimate the parameters of articulators from speech audio. There are two common challenges in AAI, which are the limited data and the unsatisfactory performance in speaker independent scenario. Most current works focus on extracting features directly from speech and ignoring the importance of phoneme information which may limit the performance of AAI. To this end, we propose a novel network called SPN that uses two different streams to carry out the AAI task. Firstly, to improve the performance of speaker-independent experiment, we propose a new phoneme stream network to estimate the articulatory parameters as the phoneme features. To the best of our knowledge, this is the first work that extracts the speaker-independent features from phonemes to improve the performance of AAI. Secondly, in order to better represent the speech information, we train a speech stream network to combine the local features and the global features. Compared with state-of-the-art (SOTA), the proposed method reduces 0.18mm on RMSE and increases 6.0% on Pearson correlation coefficient in the speaker-independent experiment. The code has been released at https://github.com/liujinyu123/AAINetwork-SPN.
MVNet: Memory Assistance and Vocal Reinforcement Network for Speech Enhancement
Sep 15, 2022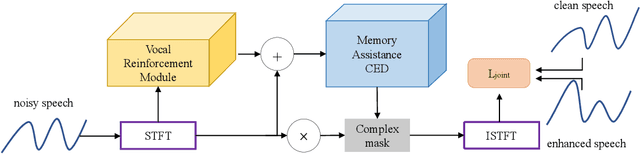
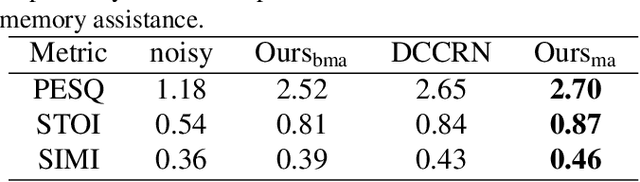
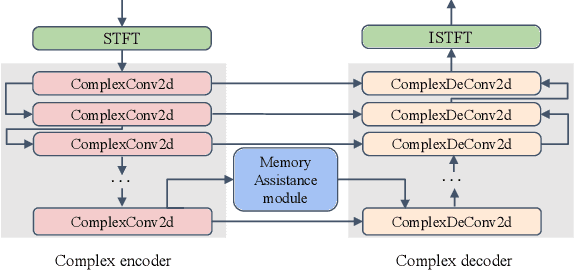
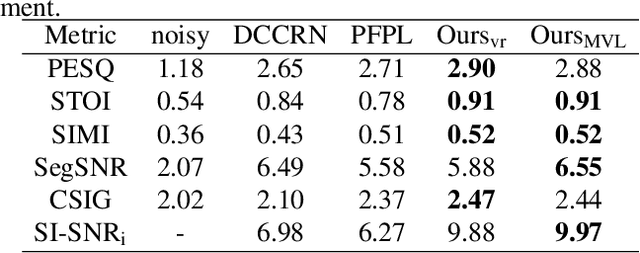
Speech enhancement improves speech quality and promotes the performance of various downstream tasks. However, most current speech enhancement work was mainly devoted to improving the performance of downstream automatic speech recognition (ASR), only a relatively small amount of work focused on the automatic speaker verification (ASV) task. In this work, we propose a MVNet consisted of a memory assistance module which improves the performance of downstream ASR and a vocal reinforcement module which boosts the performance of ASV. In addition, we design a new loss function to improve speaker vocal similarity. Experimental results on the Libri2mix dataset show that our method outperforms baseline methods in several metrics, including speech quality, intelligibility, and speaker vocal similarity et al.
Reinforced Swin-Convs Transformer for Underwater Image Enhancement
May 01, 2022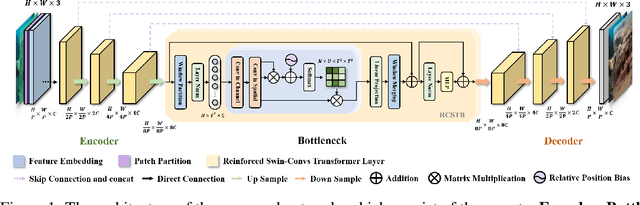
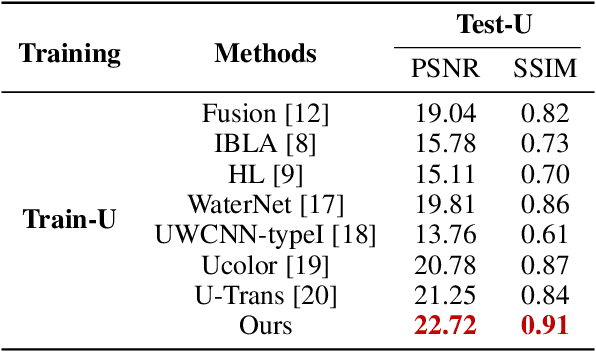
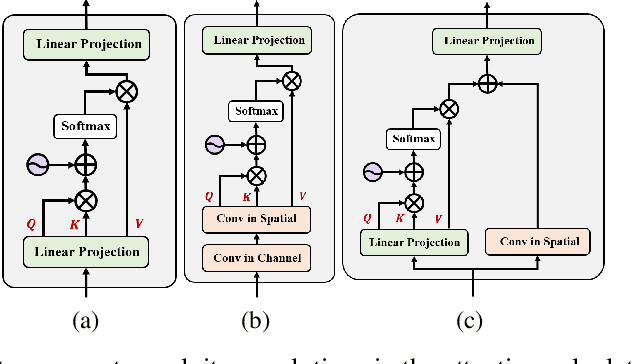
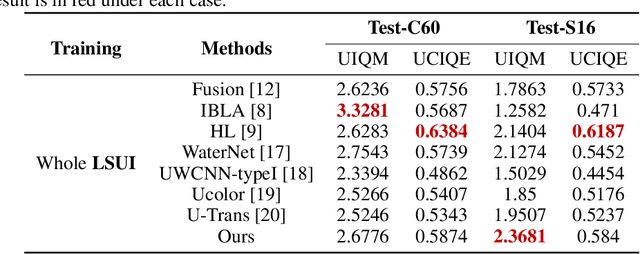
Underwater Image Enhancement (UIE) technology aims to tackle the challenge of restoring the degraded underwater images due to light absorption and scattering. To address problems, a novel U-Net based Reinforced Swin-Convs Transformer for the Underwater Image Enhancement method (URSCT-UIE) is proposed. Specifically, with the deficiency of U-Net based on pure convolutions, we embedded the Swin Transformer into U-Net for improving the ability to capture the global dependency. Then, given the inadequacy of the Swin Transformer capturing the local attention, the reintroduction of convolutions may capture more local attention. Thus, we provide an ingenious manner for the fusion of convolutions and the core attention mechanism to build a Reinforced Swin-Convs Transformer Block (RSCTB) for capturing more local attention, which is reinforced in the channel and the spatial attention of the Swin Transformer. Finally, the experimental results on available datasets demonstrate that the proposed URSCT-UIE achieves state-of-the-art performance compared with other methods in terms of both subjective and objective evaluations. The code will be released on GitHub after acceptance.
Domain Adaptation for Underwater Image Enhancement
Aug 22, 2021



Recently, learning-based algorithms have shown impressive performance in underwater image enhancement. Most of them resort to training on synthetic data and achieve outstanding performance. However, these methods ignore the significant domain gap between the synthetic and real data (i.e., interdomain gap), and thus the models trained on synthetic data often fail to generalize well to real underwater scenarios. Furthermore, the complex and changeable underwater environment also causes a great distribution gap among the real data itself (i.e., intra-domain gap). However, almost no research focuses on this problem and thus their techniques often produce visually unpleasing artifacts and color distortions on various real images. Motivated by these observations, we propose a novel Two-phase Underwater Domain Adaptation network (TUDA) to simultaneously minimize the inter-domain and intra-domain gap. Concretely, a new dual-alignment network is designed in the first phase, including a translation part for enhancing realism of input images, followed by an enhancement part. With performing image-level and feature-level adaptation in two parts by jointly adversarial learning, the network can better build invariance across domains and thus bridge the inter-domain gap. In the second phase, we perform an easy-hard classification of real data according to the assessed quality of enhanced images, where a rank-based underwater quality assessment method is embedded. By leveraging implicit quality information learned from rankings, this method can more accurately assess the perceptual quality of enhanced images. Using pseudo labels from the easy part, an easy-hard adaptation technique is then conducted to effectively decrease the intra-domain gap between easy and hard samples.
Single Underwater Image Enhancement Using an Analysis-Synthesis Network
Aug 20, 2021



Most deep models for underwater image enhancement resort to training on synthetic datasets based on underwater image formation models. Although promising performances have been achieved, they are still limited by two problems: (1) existing underwater image synthesis models have an intrinsic limitation, in which the homogeneous ambient light is usually randomly generated and many important dependencies are ignored, and thus the synthesized training data cannot adequately express characteristics of real underwater environments; (2) most of deep models disregard lots of favorable underwater priors and heavily rely on training data, which extensively limits their application ranges. To address these limitations, a new underwater synthetic dataset is first established, in which a revised ambient light synthesis equation is embedded. The revised equation explicitly defines the complex mathematical relationship among intensity values of the ambient light in RGB channels and many dependencies such as surface-object depth, water types, etc, which helps to better simulate real underwater scene appearances. Secondly, a unified framework is proposed, named ANA-SYN, which can effectively enhance underwater images under collaborations of priors (underwater domain knowledge) and data information (underwater distortion distribution). The proposed framework includes an analysis network and a synthesis network, one for priors exploration and another for priors integration. To exploit more accurate priors, the significance of each prior for the input image is explored in the analysis network and an adaptive weighting module is designed to dynamically recalibrate them. Meanwhile, a novel prior guidance module is introduced in the synthesis network, which effectively aggregates the prior and data features and thus provides better hybrid information to perform the more reasonable image enhancement.
Cross-Modal Knowledge Distillation Method for Automatic Cued Speech Recognition
Jun 25, 2021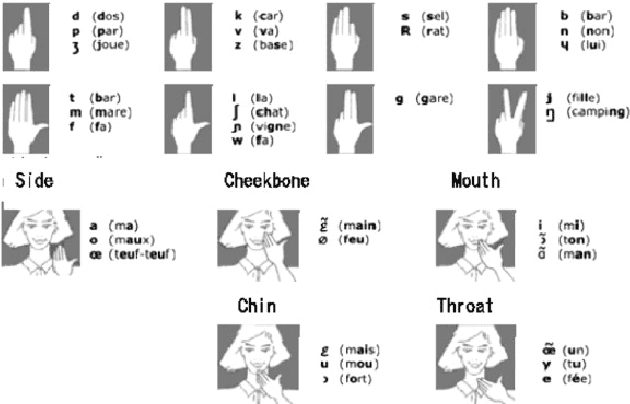
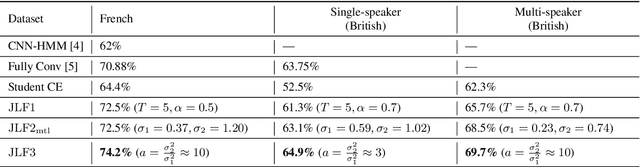
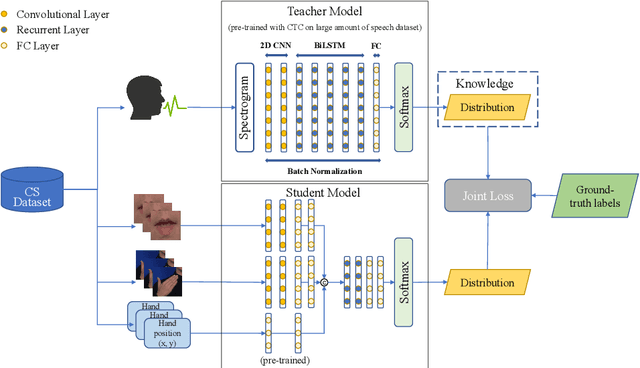
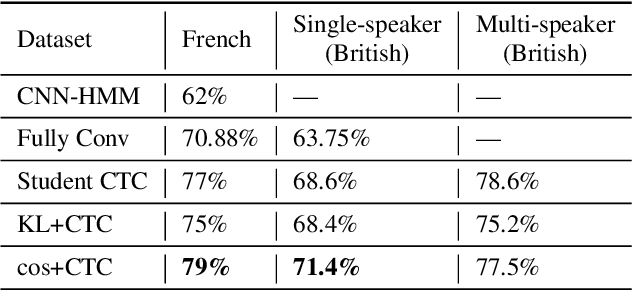
Cued Speech (CS) is a visual communication system for the deaf or hearing impaired people. It combines lip movements with hand cues to obtain a complete phonetic repertoire. Current deep learning based methods on automatic CS recognition suffer from a common problem, which is the data scarcity. Until now, there are only two public single speaker datasets for French (238 sentences) and British English (97 sentences). In this work, we propose a cross-modal knowledge distillation method with teacher-student structure, which transfers audio speech information to CS to overcome the limited data problem. Firstly, we pretrain a teacher model for CS recognition with a large amount of open source audio speech data, and simultaneously pretrain the feature extractors for lips and hands using CS data. Then, we distill the knowledge from teacher model to the student model with frame-level and sequence-level distillation strategies. Importantly, for frame-level, we exploit multi-task learning to weigh losses automatically, to obtain the balance coefficient. Besides, we establish a five-speaker British English CS dataset for the first time. The proposed method is evaluated on French and British English CS datasets, showing superior CS recognition performance to the state-of-the-art (SOTA) by a large margin.