 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Explicit Network (GEN): A novel deep learning architecture for solving partial differential equations
Apr 02, 2026Machine learning, especially physics-informed neural networks (PINNs) and their neural network variants, has been widely used to solve problems involving partial differential equations (PDEs). The successful deployment of such methods beyond academic research remains limited. For example, PINN methods primarily consider discrete point-to-point fitting and fail to account for the potential properties of real solutions. The adoption of continuous activation functions in these approaches leads to local characteristics that align with the equation solutions while resulting in poor extensibility and robustness. A general explicit network (GEN) that implements point-to-function PDE solving is proposed in this paper. The "function" component can be constructed based on our prior knowledge of the original PDEs through corresponding basis functions for fitting. The experimental results demonstrate that this approach enables solutions with high robustness and strong extensibility to be obtained.
Underwater Image Enhancement with Cascaded Contrastive Learning
Nov 16, 2024



Underwater image enhancement (UIE) is a highly challenging task due to the complexity of underwater environment and the diversity of underwater image degradation. Due to the application of deep learning, current UIE methods have made significant progress. Most of the existing deep learning-based UIE methods follow a single-stage network which cannot effectively address the diverse degradations simultaneously. In this paper, we propose to address this issue by designing a two-stage deep learning framework and taking advantage of cascaded contrastive learning to guide the network training of each stage. The proposed method is called CCL-Net in short. Specifically, the proposed CCL-Net involves two cascaded stages, i.e., a color correction stage tailored to the color deviation issue and a haze removal stage tailored to improve the visibility and contrast of underwater images. To guarantee the underwater image can be progressively enhanced, we also apply contrastive loss as an additional constraint to guide the training of each stage. In the first stage, the raw underwater images are used as negative samples for building the first contrastive loss, ensuring the enhanced results of the first color correction stage are better than the original inputs. While in the second stage, the enhanced results rather than the raw underwater images of the first color correction stage are used as the negative samples for building the second contrastive loss, thus ensuring the final enhanced results of the second haze removal stage are better than the intermediate color corrected results. Extensive experiments on multiple benchmark datasets demonstrate that our CCL-Net can achieve superior performance compared to many state-of-the-art methods. The source code of CCL-Net will be released at https://github.com/lewis081/CCL-Net.
WaterMamba: Visual State Space Model for Underwater Image Enhancement
May 14, 2024Underwater imaging often suffers from low quality due to factors affecting light propagation and absorption in water. To improve image quality, some underwater image enhancement (UIE) methods based on convolutional neural networks (CNN) and Transformer have been proposed. However, CNN-based UIE methods are limited in modeling long-range dependencies, and Transformer-based methods involve a large number of parameters and complex self-attention mechanisms, posing efficiency challenges. Considering computational complexity and severe underwater image degradation, a state space model (SSM) with linear computational complexity for UIE, named WaterMamba, is proposed. We propose spatial-channel omnidirectional selective scan (SCOSS) blocks comprising spatial-channel coordinate omnidirectional selective scan (SCCOSS) modules and a multi-scale feedforward network (MSFFN). The SCOSS block models pixel and channel information flow, addressing dependencies. The MSFFN facilitates information flow adjustment and promotes synchronized operations within SCCOSS modules. Extensive experiments showcase WaterMamba's cutting-edge performance with reduced parameters and computational resources, outperforming state-of-the-art methods on various datasets, validating its effectiveness and generalizability. The code will be released on GitHub after acceptance.
MDDD: Manifold-based Domain Adaptation with Dynamic Distribution for Non-Deep Transfer Learning in Cross-subject and Cross-session EEG-based Emotion Recognition
Apr 24, 2024Emotion decoding using Electroencephalography (EEG)-based affective brain-computer interfaces represents a significant area within the field of affective computing. In the present study, we propose a novel non-deep transfer learning method, termed as Manifold-based Domain adaptation with Dynamic Distribution (MDDD). The proposed MDDD includes four main modules: manifold feature transformation, dynamic distribution alignment, classifier learning, and ensemble learning. The data undergoes a transformation onto an optimal Grassmann manifold space, enabling dynamic alignment of the source and target domains. This process prioritizes both marginal and conditional distributions according to their significance, ensuring enhanced adaptation efficiency across various types of data. In the classifier learning, the principle of structural risk minimization is integrated to develop robust classification models. This is complemented by dynamic distribution alignment, which refines the classifier iteratively. Additionally, the ensemble learning module aggregates the classifiers obtained at different stages of the optimization process, which leverages the diversity of the classifiers to enhance the overall prediction accuracy. The experimental results indicate that MDDD outperforms traditional non-deep learning methods, achieving an average improvement of 3.54%, and is comparable to deep learning methods. This suggests that MDDD could be a promising method for enhancing the utility and applicability of aBCIs in real-world scenarios.
EnvPool: A Highly Parallel Reinforcement Learning Environment Execution Engine
Jun 21, 2022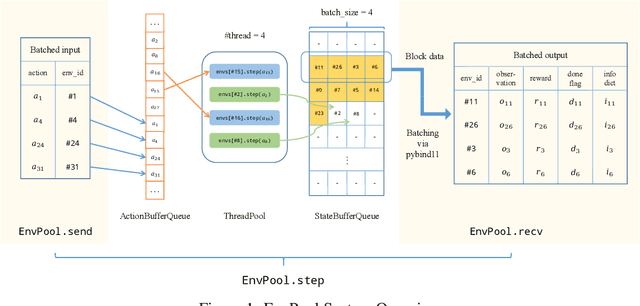
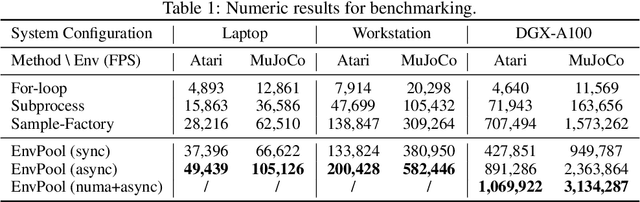
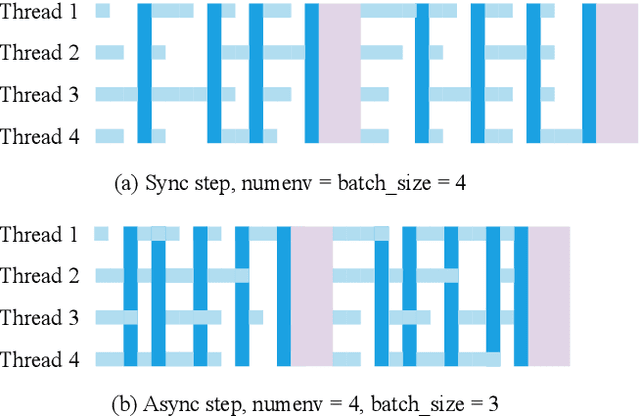
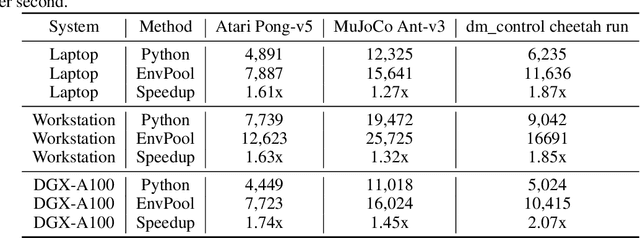
There has been significant progress in developing reinforcement learning (RL) training systems. Past works such as IMPALA, Apex, Seed RL, Sample Factory, and others aim to improve the system's overall throughput. In this paper, we try to address a common bottleneck in the RL training system, i.e., parallel environment execution, which is often the slowest part of the whole system but receives little attention. With a curated design for paralleling RL environments, we have improved the RL environment simulation speed across different hardware setups, ranging from a laptop, and a modest workstation, to a high-end machine like NVIDIA DGX-A100. On a high-end machine, EnvPool achieves 1 million frames per second for the environment execution on Atari environments and 3 million frames per second on MuJoCo environments. When running on a laptop, the speed of EnvPool is 2.8 times of the Python subprocess. Moreover, great compatibility with existing RL training libraries has been demonstrated in the open-sourced community, including CleanRL, rl_games, DeepMind Acme, etc. Finally, EnvPool allows researchers to iterate their ideas at a much faster pace and has the great potential to become the de facto RL environment execution engine. Example runs show that it takes only 5 minutes to train Atari Pong and MuJoCo Ant, both on a laptop. EnvPool has already been open-sourced at https://github.com/sail-sg/envpool.
Reinforced Swin-Convs Transformer for Underwater Image Enhancement
May 01, 2022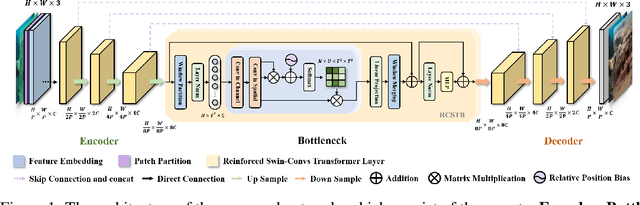
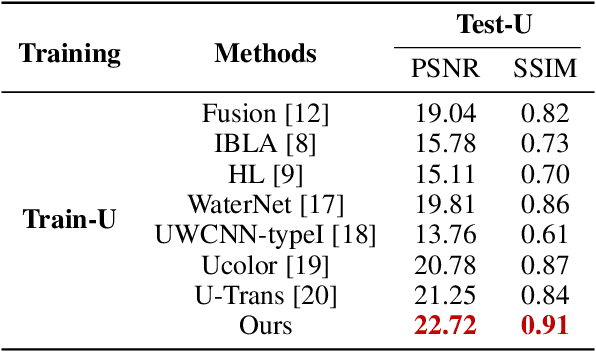
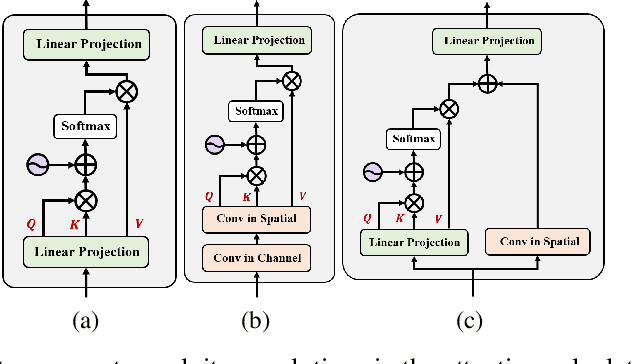
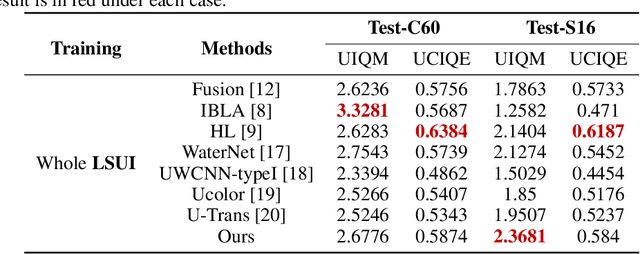
Underwater Image Enhancement (UIE) technology aims to tackle the challenge of restoring the degraded underwater images due to light absorption and scattering. To address problems, a novel U-Net based Reinforced Swin-Convs Transformer for the Underwater Image Enhancement method (URSCT-UIE) is proposed. Specifically, with the deficiency of U-Net based on pure convolutions, we embedded the Swin Transformer into U-Net for improving the ability to capture the global dependency. Then, given the inadequacy of the Swin Transformer capturing the local attention, the reintroduction of convolutions may capture more local attention. Thus, we provide an ingenious manner for the fusion of convolutions and the core attention mechanism to build a Reinforced Swin-Convs Transformer Block (RSCTB) for capturing more local attention, which is reinforced in the channel and the spatial attention of the Swin Transformer. Finally, the experimental results on available datasets demonstrate that the proposed URSCT-UIE achieves state-of-the-art performance compared with other methods in terms of both subjective and objective evaluations. The code will be released on GitHub after acceptance.