 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic Image Manipulation with Background-guided Internal Learning
Mar 24, 2022
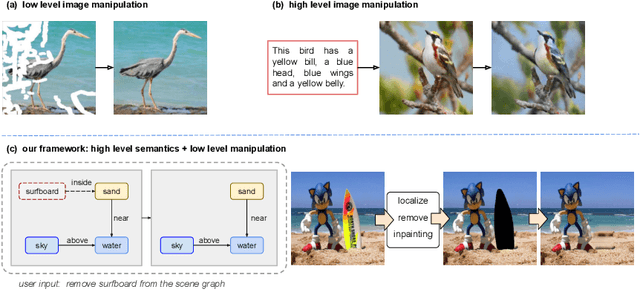
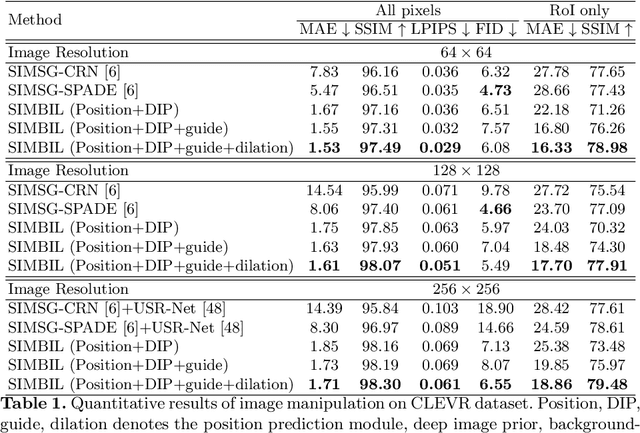
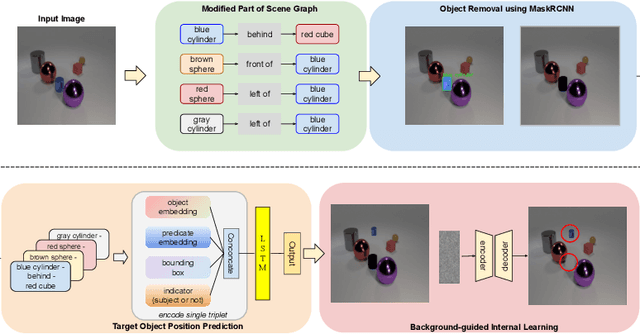

Image manipulation has attracted a lot of interest due to its wide range of applications. Prior work modifies images either from low-level manipulation, such as image inpainting or through manual edits via paintbrushes and scribbles, or from high-level manipulation, employing deep generative networks to output an image conditioned on high-level semantic input. In this study, we propose Semantic Image Manipulation with Background-guided Internal Learning (SIMBIL), which combines high-level and low-level manipulation. Specifically, users can edit an image at the semantic level by applying changes on a scene graph. Then our model manipulates the image at the pixel level according to the modified scene graph. There are two major advantages of our approach. First, high-level manipulation of scene graphs requires less manual effort from the user compared to manipulating raw image pixels. Second, our low-level internal learning approach is scalable to images of various sizes without reliance on external visual datasets for training. We outperform the state-of-the-art in a quantitative and qualitative evaluation on the CLEVR and Visual Genome datasets. Experiments show 8 points improvement on FID scores (CLEVR) and 27% improvement on user evaluation (Visual Genome), demonstrating the effectiveness of our approach.
ClimateNeRF: Physically-based Neural Rendering for Extreme Climate Synthesis
Nov 26, 2022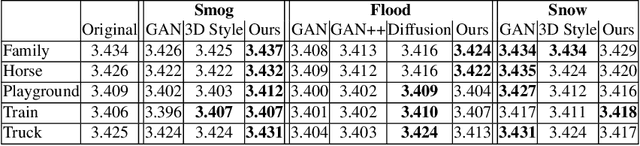
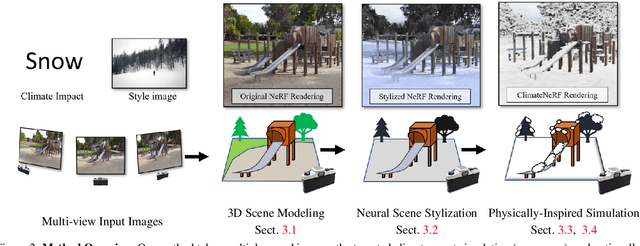


Physical simulations produce excellent predictions of weather effects. Neural radiance fields produce SOTA scene models. We describe a novel NeRF-editing procedure that can fuse physical simulations with NeRF models of scenes, producing realistic movies of physical phenomena inthose scenes. Our application -- Climate NeRF -- allows people to visualize what climate change outcomes will do to them. ClimateNeRF allows us to render realistic weather effects, including smog, snow, and flood. Results can be controlled with physically meaningful variables like water level. Qualitative and quantitative studies show that our simulated results are significantly more realistic than those from state-of-the-art 2D image editing and 3D NeRF stylization.
Contrastive View Design Strategies to Enhance Robustness to Domain Shifts in Downstream Object Detection
Dec 09, 2022
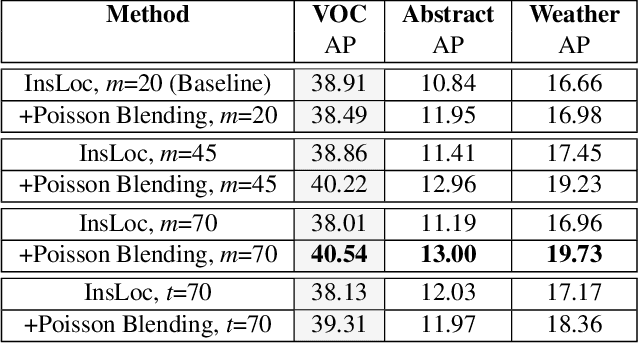

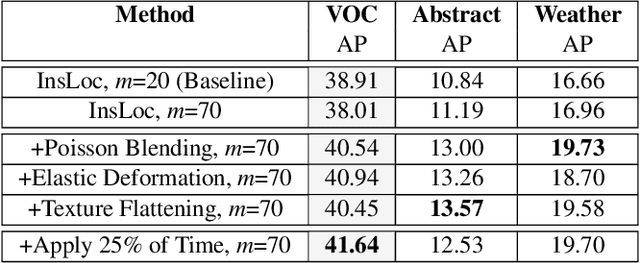
Contrastive learning has emerged as a competitive pretraining method for object detection. Despite this progress, there has been minimal investigation into the robustness of contrastively pretrained detectors when faced with domain shifts. To address this gap, we conduct an empirical study of contrastive learning and out-of-domain object detection, studying how contrastive view design affects robustness. In particular, we perform a case study of the detection-focused pretext task Instance Localization (InsLoc) and propose strategies to augment views and enhance robustness in appearance-shifted and context-shifted scenarios. Amongst these strategies, we propose changes to cropping such as altering the percentage used, adding IoU constraints, and integrating saliency based object priors. We also explore the addition of shortcut-reducing augmentations such as Poisson blending, texture flattening, and elastic deformation. We benchmark these strategies on abstract, weather, and context domain shifts and illustrate robust ways to combine them, in both pretraining on single-object and multi-object image datasets. Overall, our results and insights show how to ensure robustness through the choice of views in contrastive learning.
Benchmarking Self-Supervised Learning on Diverse Pathology Datasets
Dec 09, 2022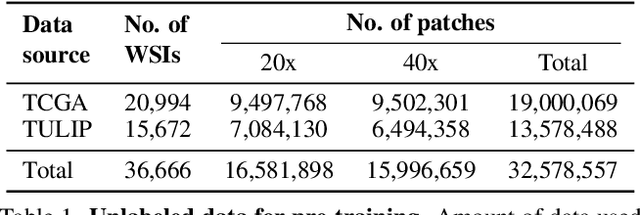

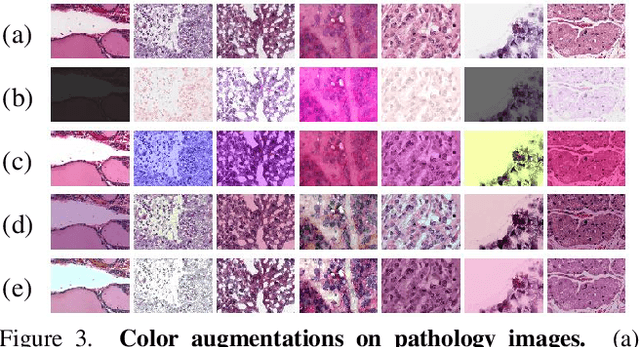
Computational pathology can lead to saving human lives, but models are annotation hungry and pathology images are notoriously expensive to annotate. Self-supervised learning has shown to be an effective method for utilizing unlabeled data, and its application to pathology could greatly benefit its downstream tasks. Yet, there are no principled studies that compare SSL methods and discuss how to adapt them for pathology. To address this need, we execute the largest-scale study of SSL pre-training on pathology image data, to date. Our study is conducted using 4 representative SSL methods on diverse downstream tasks. We establish that large-scale domain-aligned pre-training in pathology consistently out-performs ImageNet pre-training in standard SSL settings such as linear and fine-tuning evaluations, as well as in low-label regimes. Moreover, we propose a set of domain-specific techniques that we experimentally show leads to a performance boost. Lastly, for the first time, we apply SSL to the challenging task of nuclei instance segmentation and show large and consistent performance improvements under diverse settings.
Diffusion Probabilistic Models beat GANs on Medical Images
Dec 14, 2022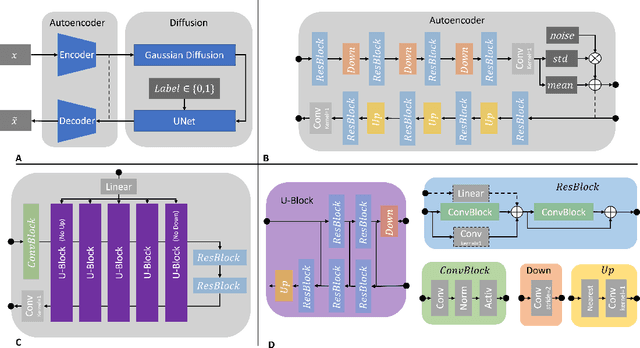
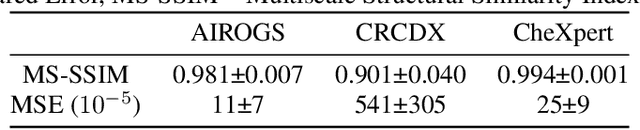
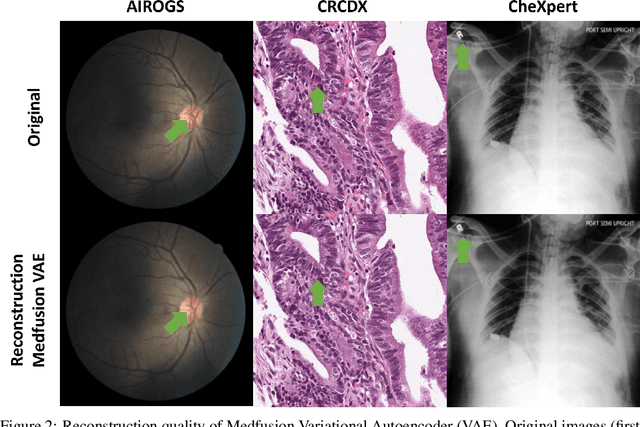
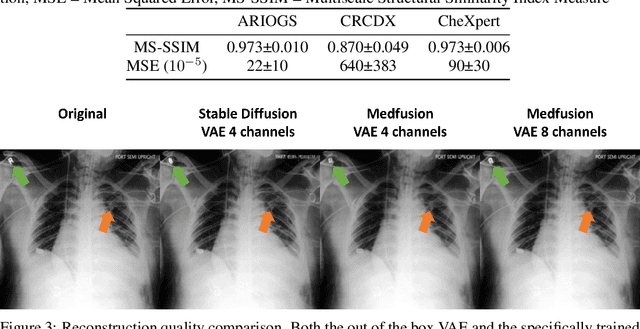
The success of Deep Learning applications critically depends on the quality and scale of the underlying training data. Generative adversarial networks (GANs) can generate arbitrary large datasets, but diversity and fidelity are limited, which has recently been addressed by denoising diffusion probabilistic models (DDPMs) whose superiority has been demonstrated on natural images. In this study, we propose Medfusion, a conditional latent DDPM for medical images. We compare our DDPM-based model against GAN-based models, which constitute the current state-of-the-art in the medical domain. Medfusion was trained and compared with (i) StyleGan-3 on n=101,442 images from the AIROGS challenge dataset to generate fundoscopies with and without glaucoma, (ii) ProGAN on n=191,027 from the CheXpert dataset to generate radiographs with and without cardiomegaly and (iii) wGAN on n=19,557 images from the CRCMS dataset to generate histopathological images with and without microsatellite stability. In the AIROGS, CRMCS, and CheXpert datasets, Medfusion achieved lower (=better) FID than the GANs (11.63 versus 20.43, 30.03 versus 49.26, and 17.28 versus 84.31). Also, fidelity (precision) and diversity (recall) were higher (=better) for Medfusion in all three datasets. Our study shows that DDPM are a superior alternative to GANs for image synthesis in the medical domain.
SCS-Co: Self-Consistent Style Contrastive Learning for Image Harmonization
Apr 29, 2022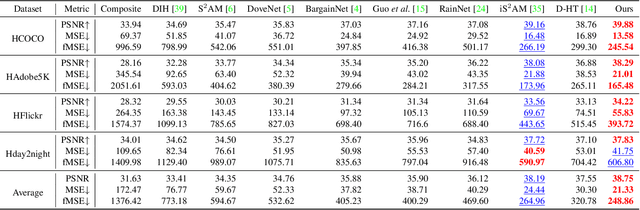
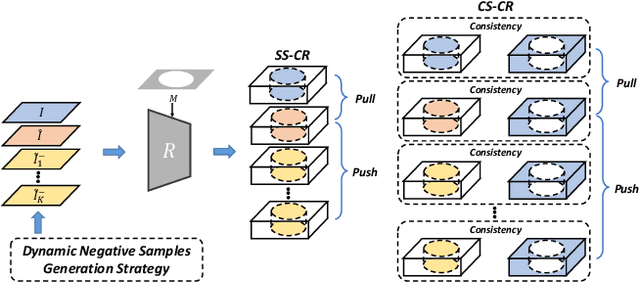
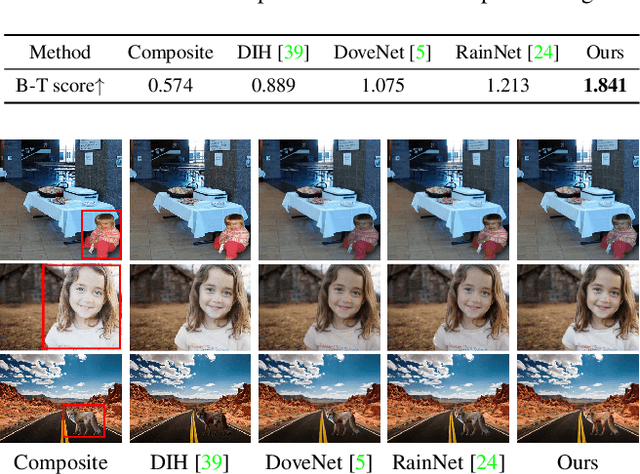
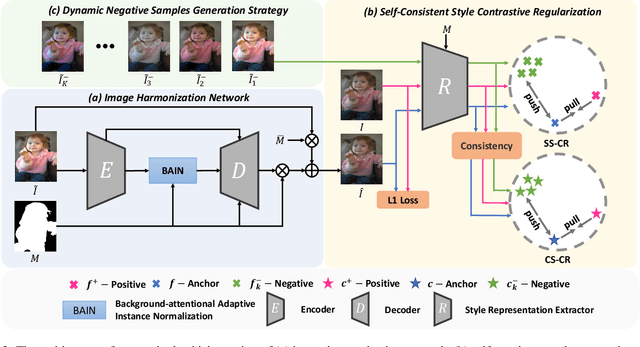
Image harmonization aims to achieve visual consistency in composite images by adapting a foreground to make it compatible with a background. However, existing methods always only use the real image as the positive sample to guide the training, and at most introduce the corresponding composite image as a single negative sample for an auxiliary constraint, which leads to limited distortion knowledge, and further causes a too large solution space, making the generated harmonized image distorted. Besides, none of them jointly constrain from the foreground self-style and foreground-background style consistency, which exacerbates this problem. Moreover, recent region-aware adaptive instance normalization achieves great success but only considers the global background feature distribution, making the aligned foreground feature distribution biased. To address these issues, we propose a self-consistent style contrastive learning scheme (SCS-Co). By dynamically generating multiple negative samples, our SCS-Co can learn more distortion knowledge and well regularize the generated harmonized image in the style representation space from two aspects of the foreground self-style and foreground-background style consistency, leading to a more photorealistic visual result. In addition, we propose a background-attentional adaptive instance normalization (BAIN) to achieve an attention-weighted background feature distribution according to the foreground-background feature similarity. Experiments demonstrate the superiority of our method over other state-of-the-art methods in both quantitative comparison and visual analysis.
Domain Translation via Latent Space Mapping
Dec 06, 2022

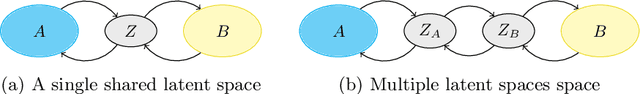

In this paper, we investigate the problem of multi-domain translation: given an element $a$ of domain $A$, we would like to generate a corresponding $b$ sample in another domain $B$, and vice versa. Acquiring supervision in multiple domains can be a tedious task, also we propose to learn this translation from one domain to another when supervision is available as a pair $(a,b)\sim A\times B$ and leveraging possible unpaired data when only $a\sim A$ or only $b\sim B$ is available. We introduce a new unified framework called Latent Space Mapping (\model) that exploits the manifold assumption in order to learn, from each domain, a latent space. Unlike existing approaches, we propose to further regularize each latent space using available domains by learning each dependency between pairs of domains. We evaluate our approach in three tasks performing i) synthetic dataset with image translation, ii) real-world task of semantic segmentation for medical images, and iii) real-world task of facial landmark detection.
Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
Dec 06, 2022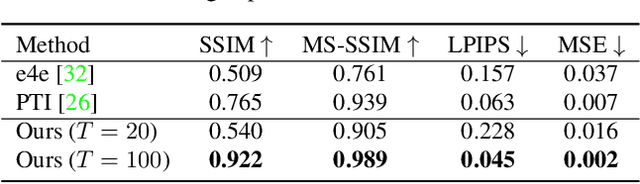
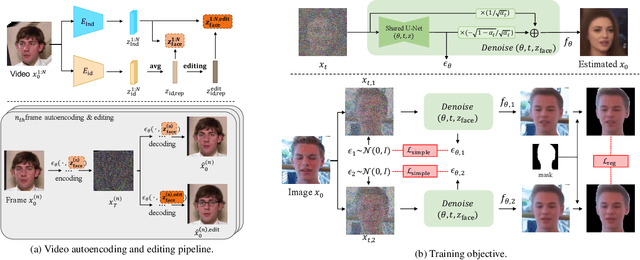
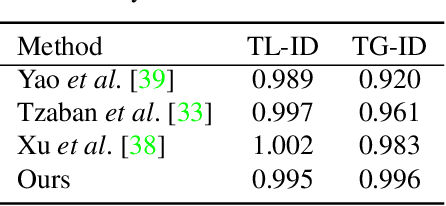
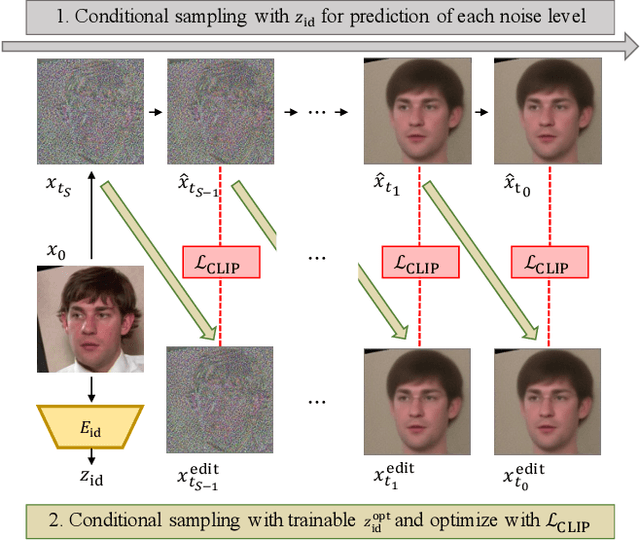
Inspired by the impressive performance of recent face image editing methods, several studies have been naturally proposed to extend these methods to the face video editing task. One of the main challenges here is temporal consistency among edited frames, which is still unresolved. To this end, we propose a novel face video editing framework based on diffusion autoencoders that can successfully extract the decomposed features - for the first time as a face video editing model - of identity and motion from a given video. This modeling allows us to edit the video by simply manipulating the temporally invariant feature to the desired direction for the consistency. Another unique strength of our model is that, since our model is based on diffusion models, it can satisfy both reconstruction and edit capabilities at the same time, and is robust to corner cases in wild face videos (e.g. occluded faces) unlike the existing GAN-based methods.
Training Vision-Language Models with Less Bimodal Supervision
Nov 01, 2022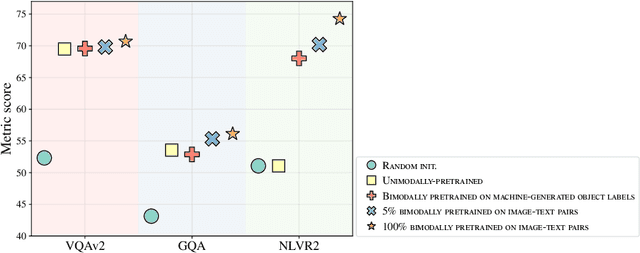
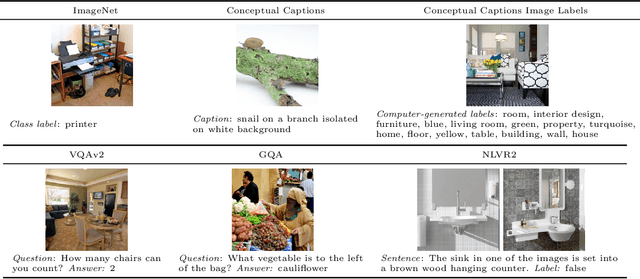
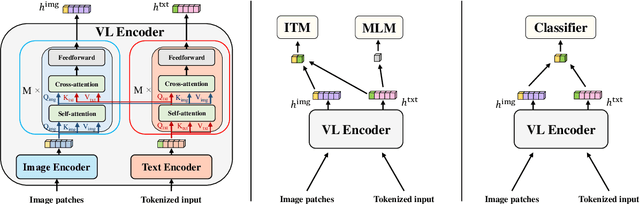
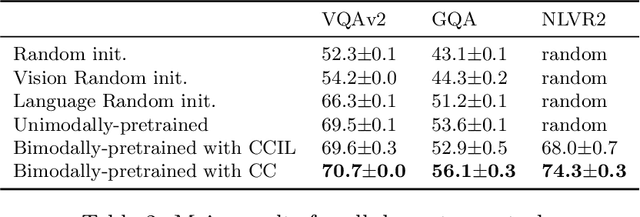
Standard practice in pretraining multimodal models, such as vision-language models, is to rely on pairs of aligned inputs from both modalities, for example, aligned image-text pairs. However, such pairs can be difficult to obtain in low-resource settings and for some modality pairs (e.g., structured tables and images). In this work, we investigate the extent to which we can reduce the reliance on such parallel data, which we term \emph{bimodal supervision}, and use models that are pretrained on each modality independently. We experiment with a high-performing vision-language model, and analyze the effect of bimodal supervision on three vision-language tasks. We find that on simpler tasks, such as VQAv2 and GQA, one can eliminate bimodal supervision completely, suffering only a minor loss in performance. Conversely, for NLVR2, which requires more complex reasoning, training without bimodal supervision leads to random performance. Nevertheless, using only 5\% of the bimodal data (142K images along with their captions), or leveraging weak supervision in the form of a list of machine-generated labels for each image, leads to only a moderate degradation compared to using 3M image-text pairs: 74\%$\rightarrow$$\sim$70\%. Our code is available at https://github.com/eladsegal/less-bimodal-sup.
Image Compression and Actionable Intelligence With Deep Neural Networks
Mar 30, 2022

If a unit cannot receive intelligence from a source due to external factors, we consider them disadvantaged users. We categorize this as a preoccupied unit working on a low connectivity device on the edge. This case requires that we use a different approach to deliver intelligence, particularly satellite imagery information, than normally employed. To address this, we propose a survey of information reduction techniques to deliver the information from a satellite image in a smaller package. We investigate four techniques to aid in the reduction of delivered information: traditional image compression, neural network image compression, object detection image cutout, and image to caption. Each of these mechanisms have their benefits and tradeoffs when considered for a disadvantaged user.