 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Writer Adaptation via Multimodal In-Context Learning
Mar 31, 2026While state-of-the-art Handwritten Text Recognition (HTR) models perform well on standard benchmarks, they frequently struggle with writers exhibiting highly specific styles that are underrepresented in the training data. To handle unseen and atypical writers, writer adaptation techniques personalize HTR models to individual handwriting styles. Leading writer adaptation methods require either offline fine-tuning or parameter updates at inference time, both involving gradient computation and backpropagation, which increase computational costs and demand careful hyperparameter tuning. In this work, we propose a novel context-driven HTR framework3 inspired by multimodal in-context learning, enabling inference-time writer adaptation using only a few examples from the target writer without any parameter updates. We further demonstrate the impact of context length, design a compact 8M-parameter CNN-Transformer that enables few-shot in-context adaptation, and show that combining context-driven and standard OCR training strategies leads to complementary improvements. Experiments on IAM and RIMES validate our approach with Character Error Rates of 3.92% and 2.34%, respectively, surpassing all writer-independent HTR models without requiring any parameter updates at inference time.
Predicting Patient Survival with Airway Biomarkers using nn-Unet/Radiomics
Jun 13, 2025The primary objective of the AIIB 2023 competition is to evaluate the predictive significance of airway-related imaging biomarkers in determining the survival outcomes of patients with lung fibrosis.This study introduces a comprehensive three-stage approach. Initially, a segmentation network, namely nn-Unet, is employed to delineate the airway's structural boundaries. Subsequently, key features are extracted from the radiomic images centered around the trachea and an enclosing bounding box around the airway. This step is motivated by the potential presence of critical survival-related insights within the tracheal region as well as pertinent information encoded in the structure and dimensions of the airway. Lastly, radiomic features obtained from the segmented areas are integrated into an SVM classifier. We could obtain an overall-score of 0.8601 for the segmentation in Task 1 while 0.7346 for the classification in Task 2.
Classifying the Unknown: In-Context Learning for Open-Vocabulary Text and Symbol Recognition
Apr 09, 2025We introduce Rosetta, a multimodal model that leverages Multimodal In-Context Learning (MICL) to classify sequences of novel script patterns in documents by leveraging minimal examples, thus eliminating the need for explicit retraining. To enhance contextual learning, we designed a dataset generation process that ensures varying degrees of contextual informativeness, improving the model's adaptability in leveraging context across different scenarios. A key strength of our method is the use of a Context-Aware Tokenizer (CAT), which enables open-vocabulary classification. This allows the model to classify text and symbol patterns across an unlimited range of classes, extending its classification capabilities beyond the scope of its training alphabet of patterns. As a result, it unlocks applications such as the recognition of new alphabets and languages. Experiments on synthetic datasets demonstrate the potential of Rosetta to successfully classify Out-Of-Distribution visual patterns and diverse sets of alphabets and scripts, including but not limited to Chinese, Greek, Russian, French, Spanish, and Japanese.
TD-Paint: Faster Diffusion Inpainting Through Time Aware Pixel Conditioning
Oct 11, 2024



Diffusion models have emerged as highly effective techniques for inpainting, however, they remain constrained by slow sampling rates. While recent advances have enhanced generation quality, they have also increased sampling time, thereby limiting scalability in real-world applications. We investigate the generative sampling process of diffusion-based inpainting models and observe that these models make minimal use of the input condition during the initial sampling steps. As a result, the sampling trajectory deviates from the data manifold, requiring complex synchronization mechanisms to realign the generation process. To address this, we propose Time-aware Diffusion Paint (TD-Paint), a novel approach that adapts the diffusion process by modeling variable noise levels at the pixel level. This technique allows the model to efficiently use known pixel values from the start, guiding the generation process toward the target manifold. By embedding this information early in the diffusion process, TD-Paint significantly accelerates sampling without compromising image quality. Unlike conventional diffusion-based inpainting models, which require a dedicated architecture or an expensive generation loop, TD-Paint achieves faster sampling times without architectural modifications. Experimental results across three datasets show that TD-Paint outperforms state-of-the-art diffusion models while maintaining lower complexity.
Multiple Noises in Diffusion Model for Semi-Supervised Multi-Domain Translation
Sep 25, 2023Domain-to-domain translation involves generating a target domain sample given a condition in the source domain. Most existing methods focus on fixed input and output domains, i.e. they only work for specific configurations (i.e. for two domains, either $D_1\rightarrow{}D_2$ or $D_2\rightarrow{}D_1$). This paper proposes Multi-Domain Diffusion (MDD), a conditional diffusion framework for multi-domain translation in a semi-supervised context. Unlike previous methods, MDD does not require defining input and output domains, allowing translation between any partition of domains within a set (such as $(D_1, D_2)\rightarrow{}D_3$, $D_2\rightarrow{}(D_1, D_3)$, $D_3\rightarrow{}D_1$, etc. for 3 domains), without the need to train separate models for each domain configuration. The key idea behind MDD is to leverage the noise formulation of diffusion models by incorporating one noise level per domain, which allows missing domains to be modeled with noise in a natural way. This transforms the training task from a simple reconstruction task to a domain translation task, where the model relies on less noisy domains to reconstruct more noisy domains. We present results on a multi-domain (with more than two domains) synthetic image translation dataset with challenging semantic domain inversion.
Domain Translation via Latent Space Mapping
Dec 06, 2022In this paper, we investigate the problem of multi-domain translation: given an element $a$ of domain $A$, we would like to generate a corresponding $b$ sample in another domain $B$, and vice versa. Acquiring supervision in multiple domains can be a tedious task, also we propose to learn this translation from one domain to another when supervision is available as a pair $(a,b)\sim A\times B$ and leveraging possible unpaired data when only $a\sim A$ or only $b\sim B$ is available. We introduce a new unified framework called Latent Space Mapping (\model) that exploits the manifold assumption in order to learn, from each domain, a latent space. Unlike existing approaches, we propose to further regularize each latent space using available domains by learning each dependency between pairs of domains. We evaluate our approach in three tasks performing i) synthetic dataset with image translation, ii) real-world task of semantic segmentation for medical images, and iii) real-world task of facial landmark detection.
Object Detection in the DCT Domain: is Luminance the Solution?
Jun 22, 2020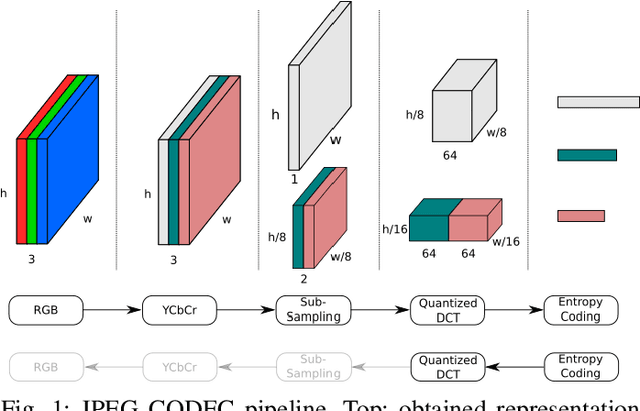
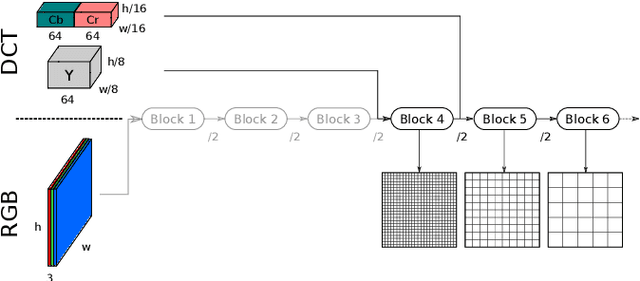
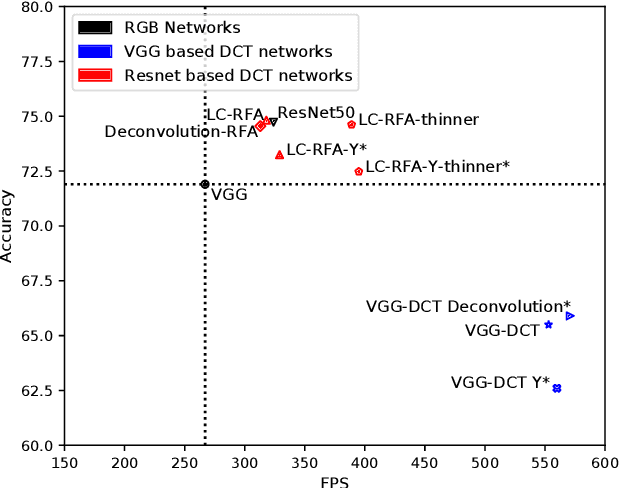
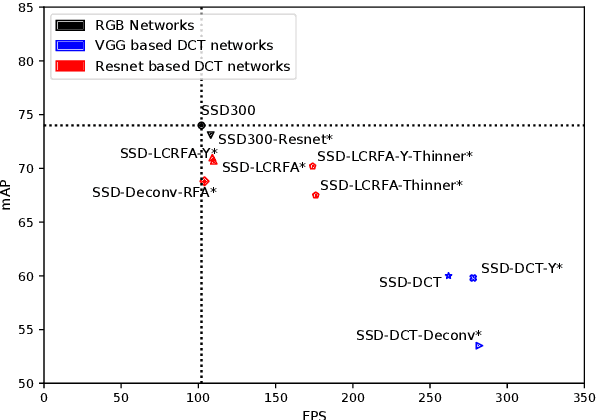
Object detection in images has reached unprecedented performances. The state-of-the-art methods rely on deep architectures that extract salient features and predict bounding boxes enclosing the objects of interest. These methods essentially run on RGB images. However, the RGB images are often compressed by the acquisition devices for storage purpose and transfer efficiency. Hence, their decompression is required for object detectors. To gain in efficiency, this paper proposes to take advantage of the compressed representation of images to carry out object detection usable in constrained resources conditions. Specifically, we focus on JPEG images and propose a thorough analysis of detection architectures newly designed in regard of the peculiarities of the JPEG norm. This leads to a $\times 1.7$ speed up in comparison with a standard RGB-based architecture, while only reducing the detection performance by 5.5%. Additionally, our empirical findings demonstrate that only part of the compressed JPEG information, namely the luminance component, may be required to match detection accuracy of the full input methods.