 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Trajectory-Word Alignments for Video-Language Tasks
Jan 06, 2023

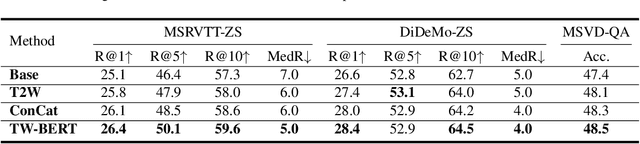
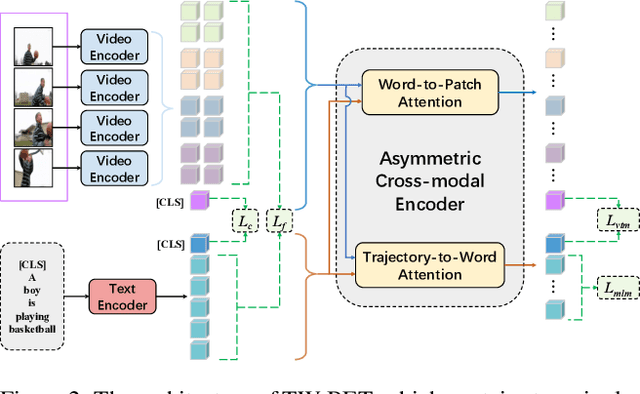
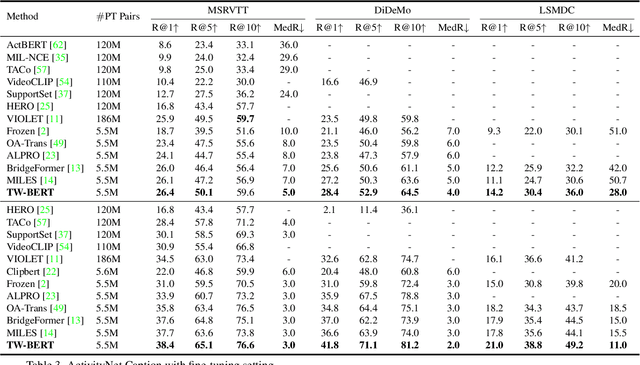
Aligning objects with words plays a critical role in Image-Language BERT (IL-BERT) and Video-Language BERT (VDL-BERT). Different from the image case where an object covers some spatial patches, an object in a video usually appears as an object trajectory, i.e., it spans over a few spatial but longer temporal patches and thus contains abundant spatiotemporal contexts. However, modern VDL-BERTs neglect this trajectory characteristic that they usually follow IL-BERTs to deploy the patch-to-word (P2W) attention while such attention may over-exploit trivial spatial contexts and neglect significant temporal contexts. To amend this, we propose a novel TW-BERT to learn Trajectory-Word alignment for solving video-language tasks. Such alignment is learned by a newly designed trajectory-to-word (T2W) attention. Besides T2W attention, we also follow previous VDL-BERTs to set a word-to-patch (W2P) attention in the cross-modal encoder. Since T2W and W2P attentions have diverse structures, our cross-modal encoder is asymmetric. To further help this asymmetric cross-modal encoder build robust vision-language associations, we propose a fine-grained ``align-before-fuse'' strategy to pull close the embedding spaces calculated by the video and text encoders. By the proposed strategy and T2W attention, our TW-BERT achieves SOTA performances on text-to-video retrieval tasks, and comparable performances on video question answering tasks with some VDL-BERTs trained on much more data. The code will be available in the supplementary material.
Towards a Pipeline for Real-Time Visualization of Faces for VR-based Telepresence and Live Broadcasting Utilizing Neural Rendering
Jan 04, 2023
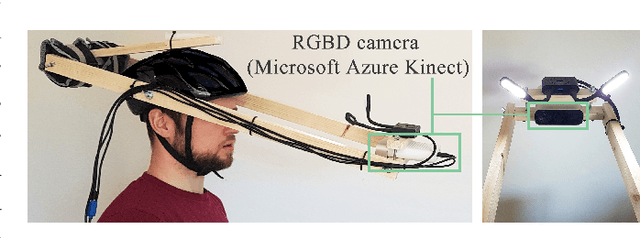
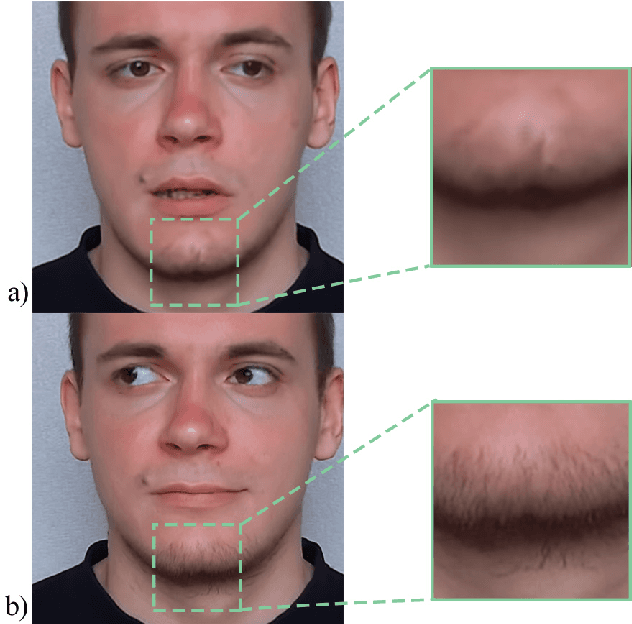
While head-mounted displays (HMDs) for Virtual Reality (VR) have become widely available in the consumer market, they pose a considerable obstacle for a realistic face-to-face conversation in VR since HMDs hide a significant portion of the participants faces. Even with image streams from cameras directly attached to an HMD, stitching together a convincing image of an entire face remains a challenging task because of extreme capture angles and strong lens distortions due to a wide field of view. Compared to the long line of research in VR, reconstruction of faces hidden beneath an HMD is a very recent topic of research. While the current state-of-the-art solutions demonstrate photo-realistic 3D reconstruction results, they require high-cost laboratory equipment and large computational costs. We present an approach that focuses on low-cost hardware and can be used on a commodity gaming computer with a single GPU. We leverage the benefits of an end-to-end pipeline by means of Generative Adversarial Networks (GAN). Our GAN produces a frontal-facing 2.5D point cloud based on a training dataset captured with an RGBD camera. In our approach, the training process is offline, while the reconstruction runs in real-time. Our results show adequate reconstruction quality within the 'learned' expressions. Expressions not learned by the network produce artifacts and can trigger the Uncanny Valley effect.
COVID-Net USPro: An Open-Source Explainable Few-Shot Deep Prototypical Network to Monitor and Detect COVID-19 Infection from Point-of-Care Ultrasound Images
Jan 04, 2023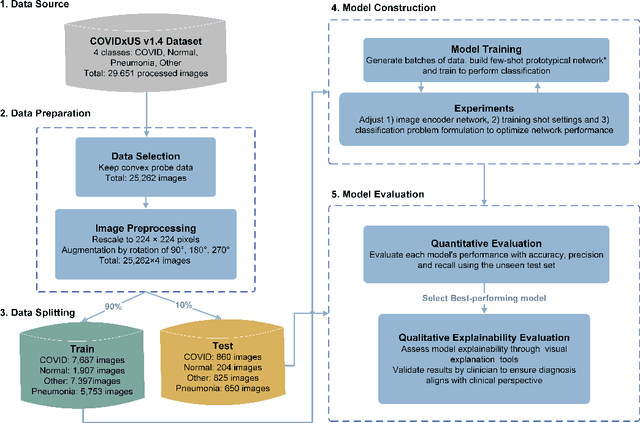
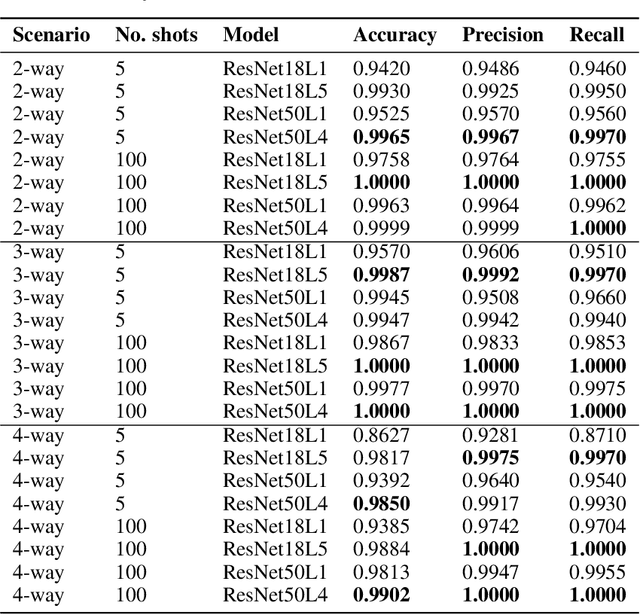
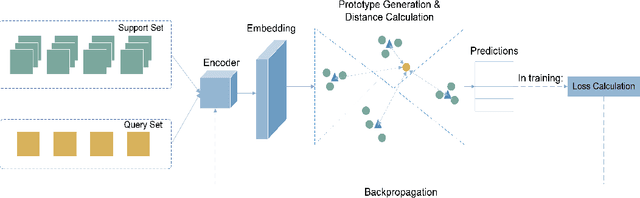
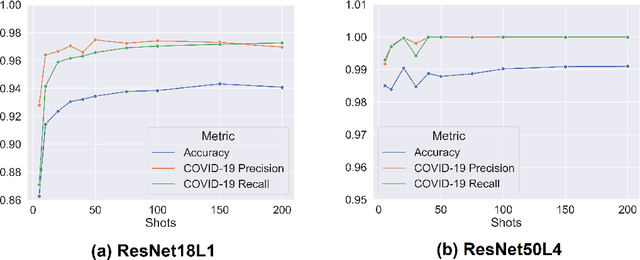
As the Coronavirus Disease 2019 (COVID-19) continues to impact many aspects of life and the global healthcare systems, the adoption of rapid and effective screening methods to prevent further spread of the virus and lessen the burden on healthcare providers is a necessity. As a cheap and widely accessible medical image modality, point-of-care ultrasound (POCUS) imaging allows radiologists to identify symptoms and assess severity through visual inspection of the chest ultrasound images. Combined with the recent advancements in computer science, applications of deep learning techniques in medical image analysis have shown promising results, demonstrating that artificial intelligence-based solutions can accelerate the diagnosis of COVID-19 and lower the burden on healthcare professionals. However, the lack of a huge amount of well-annotated data poses a challenge in building effective deep neural networks in the case of novel diseases and pandemics. Motivated by this, we present COVID-Net USPro, an explainable few-shot deep prototypical network, that monitors and detects COVID-19 positive cases with high precision and recall from minimal ultrasound images. COVID-Net USPro achieves 99.65% overall accuracy, 99.7% recall and 99.67% precision for COVID-19 positive cases when trained with only 5 shots. The analytic pipeline and results were verified by our contributing clinician with extensive experience in POCUS interpretation, ensuring that the network makes decisions based on actual patterns.
POLCOVID: a multicenter multiclass chest X-ray database (Poland, 2020-2021)
Dec 15, 2022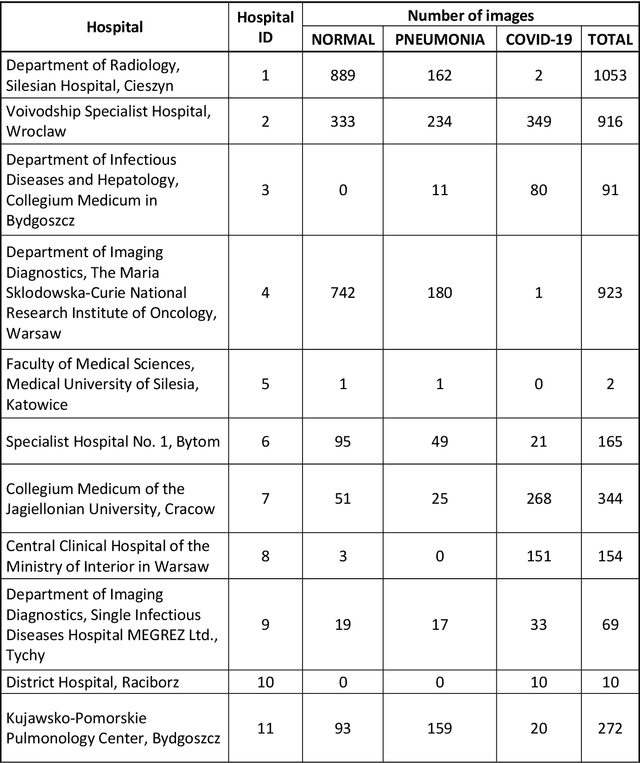
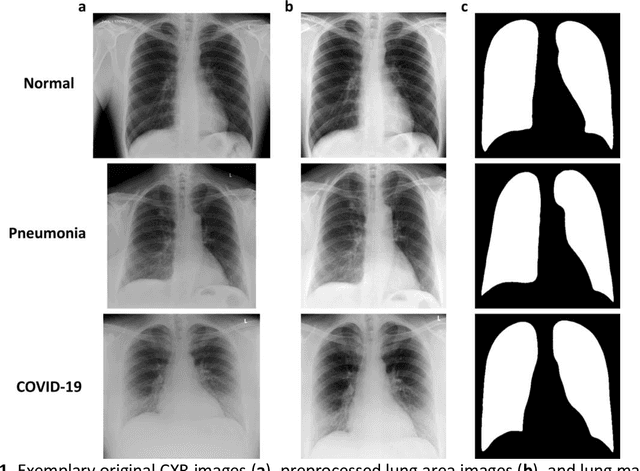
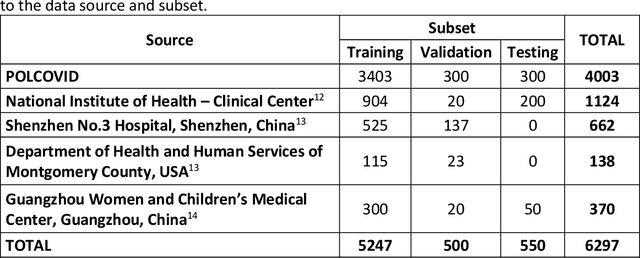
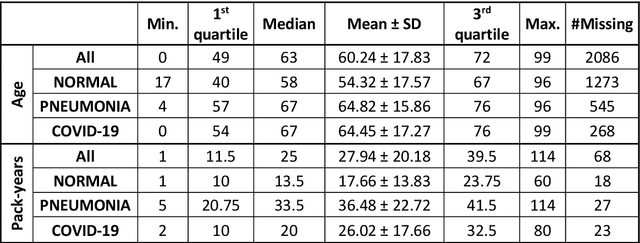
The outbreak of the SARS-CoV-2 pandemic has put healthcare systems worldwide to their limits, resulting in increased waiting time for diagnosis and required medical assistance. With chest radiographs (CXR) being one of the most common COVID-19 diagnosis methods, many artificial intelligence tools for image-based COVID-19 detection have been developed, often trained on a small number of images from COVID-19-positive patients. Thus, the need for high-quality and well-annotated CXR image databases increased. This paper introduces POLCOVID dataset, containing chest X-ray (CXR) images of patients with COVID-19 or other-type pneumonia, and healthy individuals gathered from 15 Polish hospitals. The original radiographs are accompanied by the preprocessed images limited to the lung area and the corresponding lung masks obtained with the segmentation model. Moreover, the manually created lung masks are provided for a part of POLCOVID dataset and the other four publicly available CXR image collections. POLCOVID dataset can help in pneumonia or COVID-19 diagnosis, while the set of matched images and lung masks may serve for the development of lung segmentation solutions.
Image Generation Network for Covert Transmission in Online Social Network
Jul 21, 2022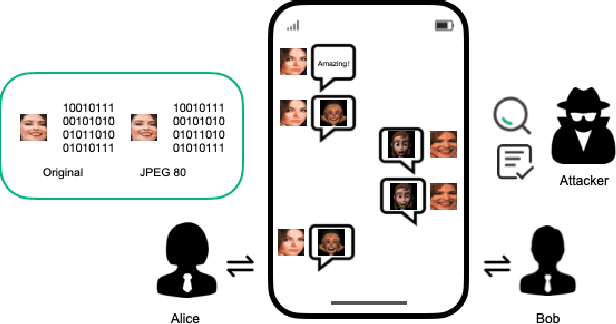
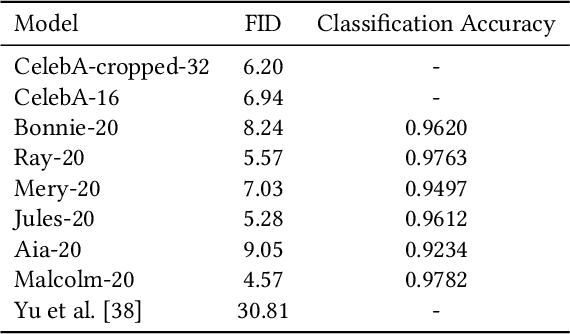
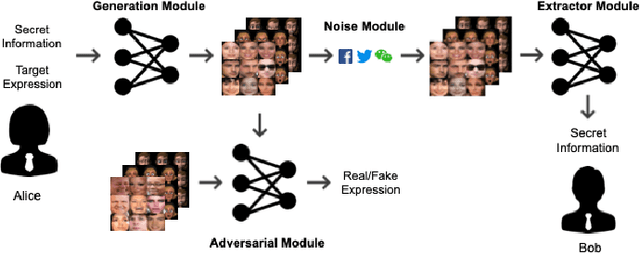
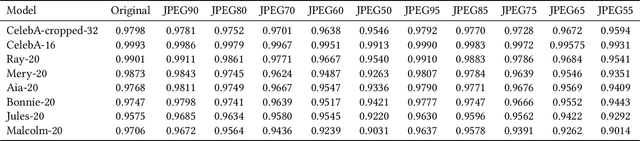
Online social networks have stimulated communications over the Internet more than ever, making it possible for secret message transmission over such noisy channels. In this paper, we propose a Coverless Image Steganography Network, called CIS-Net, that synthesizes a high-quality image directly conditioned on the secret message to transfer. CIS-Net is composed of four modules, namely, the Generation, Adversarial, Extraction, and Noise Module. The receiver can extract the hidden message without any loss even the images have been distorted by JPEG compression attacks. To disguise the behaviour of steganography, we collected images in the context of profile photos and stickers and train our network accordingly. As such, the generated images are more inclined to escape from malicious detection and attack. The distinctions from previous image steganography methods are majorly the robustness and losslessness against diverse attacks. Experiments over diverse public datasets have manifested the superior ability of anti-steganalysis.
BALF: Simple and Efficient Blur Aware Local Feature Detector
Nov 29, 2022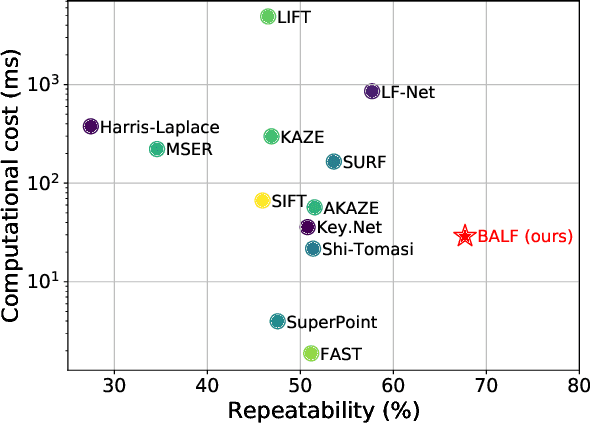
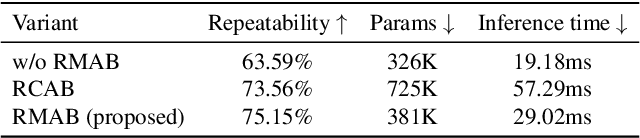
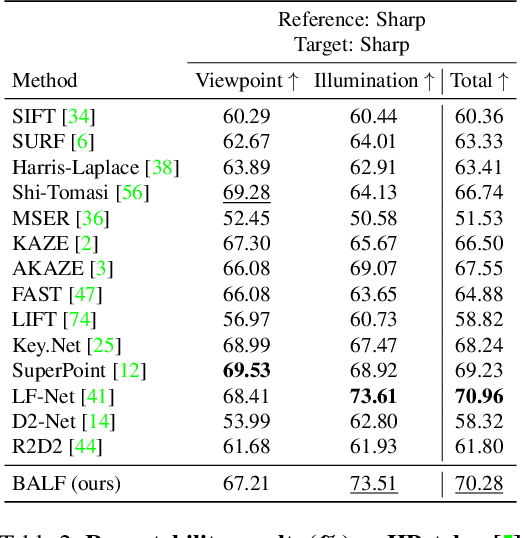
Local feature detection is a key ingredient of many image processing and computer vision applications, such as visual odometry and localization. Most existing algorithms focus on feature detection from a sharp image. They would thus have degraded performance once the image is blurred, which could happen easily under low-lighting conditions. To address this issue, we propose a simple yet both efficient and effective keypoint detection method that is able to accurately localize the salient keypoints in a blurred image. Our method takes advantages of a novel multi-layer perceptron (MLP) based architecture that significantly improve the detection repeatability for a blurred image. The network is also light-weight and able to run in real-time, which enables its deployment for time-constrained applications. Extensive experimental results demonstrate that our detector is able to improve the detection repeatability with blurred images, while keeping comparable performance as existing state-of-the-art detectors for sharp images.
CLIP the Gap: A Single Domain Generalization Approach for Object Detection
Jan 13, 2023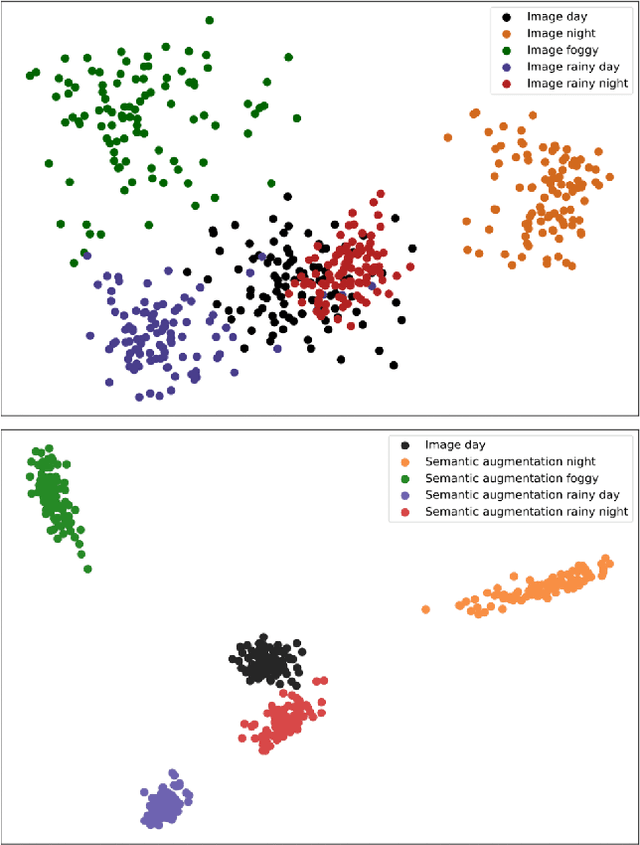
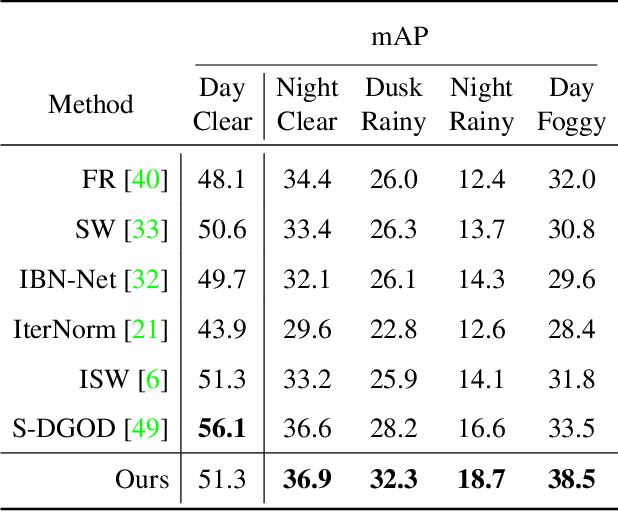
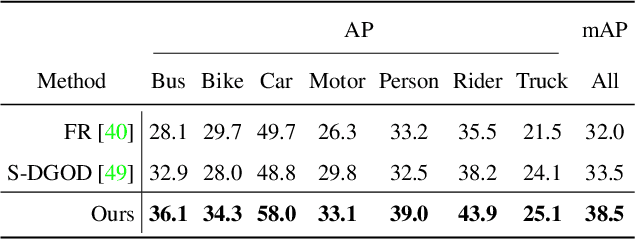
Single Domain Generalization (SDG) tackles the problem of training a model on a single source domain so that it generalizes to any unseen target domain. While this has been well studied for image classification, the literature on SDG object detection remains almost non-existent. To address the challenges of simultaneously learning robust object localization and representation, we propose to leverage a pre-trained vision-language model to introduce semantic domain concepts via textual prompts. We achieve this via a semantic augmentation strategy acting on the features extracted by the detector backbone, as well as a text-based classification loss. Our experiments evidence the benefits of our approach, outperforming by 10% the only existing SDG object detection method, Single-DGOD [49], on their own diverse weather-driving benchmark.
Image-Based Detection of Modifications in Gas Pump PCBs with Deep Convolutional Autoencoders
Oct 07, 2022

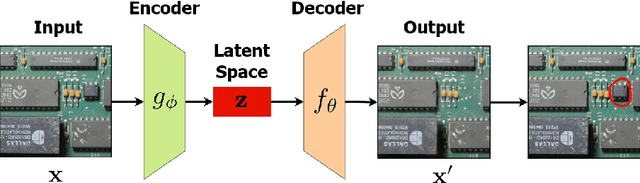
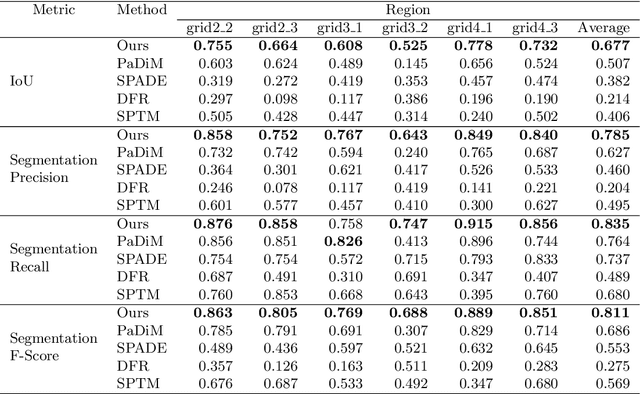
In this paper, we introduce an approach for detecting modifications in assembled printed circuit boards based on photographs taken without tight control over perspective and illumination conditions. One instance of this problem is the visual inspection of gas pumps PCBs, which can be modified by fraudsters wishing to deceive costumers or evade taxes. Given the uncontrolled environment and the huge number of possible modifications, we address the problem as a case of anomaly detection, proposing an approach that is directed towards the characteristics of that scenario, while being well-suited for other similar applications. The proposed approach employs a deep convolutional autoencoder trained to reconstruct images of an unmodified board, but which remains unable to do the same for images showing modifications. By comparing the input image with its reconstruction, it is possible to segment anomalies and modifications in a pixel-wise manner. Experiments performed on a dataset built to represent real-world situations (and which we will make publicly available) show that our approach outperforms other state-of-the-art approaches for anomaly segmentation in the considered scenario, while producing comparable results on the popular MVTec-AD dataset for a more general object anomaly detection task.
DAG: Depth-Aware Guidance with Denoising Diffusion Probabilistic Models
Dec 17, 2022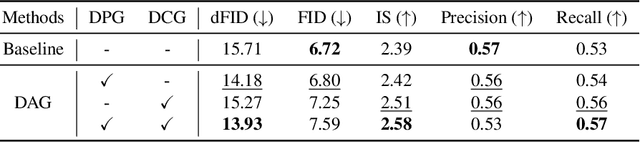
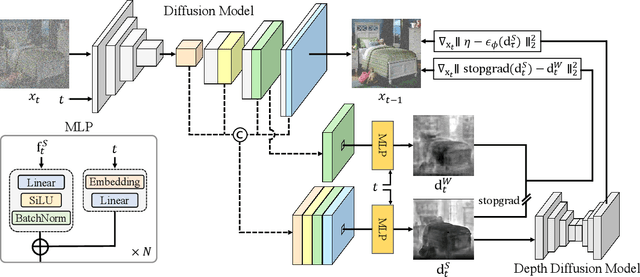
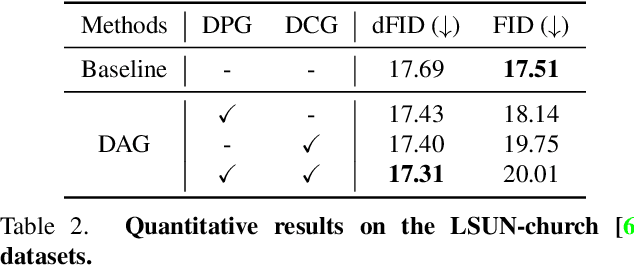

In recent years, generative models have undergone significant advancement due to the success of diffusion models. The success of these models is often attributed to their use of guidance techniques, such as classifier and classifier-free methods, which provides effective mechanisms to trade-off between fidelity and diversity. However, these methods are not capable of guiding a generated image to be aware of its geometric configuration, e.g., depth, which hinders the application of diffusion models to areas that require a certain level of depth awareness. To address this limitation, we propose a novel guidance approach for diffusion models that uses estimated depth information derived from the rich intermediate representations of diffusion models. To do this, we first present a label-efficient depth estimation framework using the internal representations of diffusion models. At the sampling phase, we utilize two guidance techniques to self-condition the generated image using the estimated depth map, the first of which uses pseudo-labeling, and the subsequent one uses a depth-domain diffusion prior. Experiments and extensive ablation studies demonstrate the effectiveness of our method in guiding the diffusion models toward geometrically plausible image generation. Project page is available at https://ku-cvlab.github.io/DAG/.
Test-time image-to-image translation ensembling improves out-of-distribution generalization in histopathology
Jun 30, 2022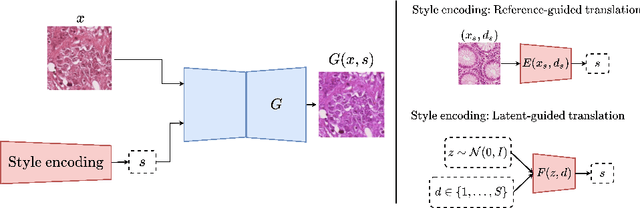
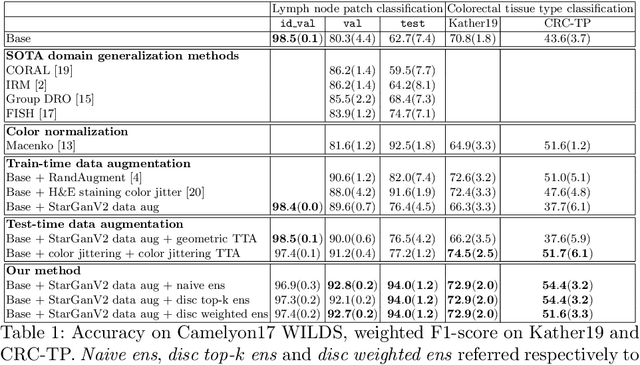
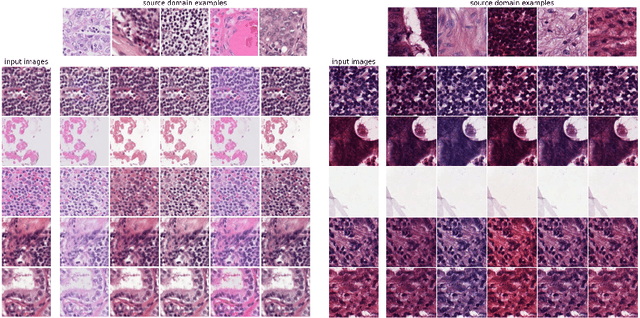
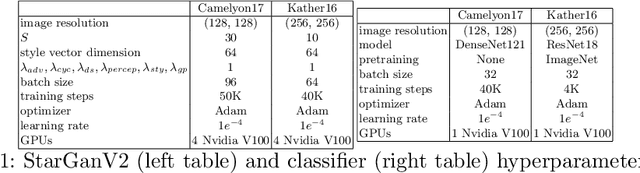
Histopathology whole slide images (WSIs) can reveal significant inter-hospital variability such as illumination, color or optical artifacts. These variations, caused by the use of different scanning protocols across medical centers (staining, scanner), can strongly harm algorithms generalization on unseen protocols. This motivates development of new methods to limit such drop of performances. In this paper, to enhance robustness on unseen target protocols, we propose a new test-time data augmentation based on multi domain image-to-image translation. It allows to project images from unseen protocol into each source domain before classifying them and ensembling the predictions. This test-time augmentation method results in a significant boost of performances for domain generalization. To demonstrate its effectiveness, our method has been evaluated on 2 different histopathology tasks where it outperforms conventional domain generalization, standard H&E specific color augmentation/normalization and standard test-time augmentation techniques. Our code is publicly available at https://gitlab.com/vitadx/articles/test-time-i2i-translation-ensembling.