 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFantasyID: A dataset for detecting digital manipulations of ID-documents
Jul 28, 2025Advancements in image generation led to the availability of easy-to-use tools for malicious actors to create forged images. These tools pose a serious threat to the widespread Know Your Customer (KYC) applications, requiring robust systems for detection of the forged Identity Documents (IDs). To facilitate the development of the detection algorithms, in this paper, we propose a novel publicly available (including commercial use) dataset, FantasyID, which mimics real-world IDs but without tampering with legal documents and, compared to previous public datasets, it does not contain generated faces or specimen watermarks. FantasyID contains ID cards with diverse design styles, languages, and faces of real people. To simulate a realistic KYC scenario, the cards from FantasyID were printed and captured with three different devices, constituting the bonafide class. We have emulated digital forgery/injection attacks that could be performed by a malicious actor to tamper the IDs using the existing generative tools. The current state-of-the-art forgery detection algorithms, such as TruFor, MMFusion, UniFD, and FatFormer, are challenged by FantasyID dataset. It especially evident, in the evaluation conditions close to practical, with the operational threshold set on validation set so that false positive rate is at 10%, leading to false negative rates close to 50% across the board on the test set. The evaluation experiments demonstrate that FantasyID dataset is complex enough to be used as an evaluation benchmark for detection algorithms.
Investigation of Accuracy and Bias in Face Recognition Trained with Synthetic Data
Jul 28, 2025Synthetic data has emerged as a promising alternative for training face recognition (FR) models, offering advantages in scalability, privacy compliance, and potential for bias mitigation. However, critical questions remain on whether both high accuracy and fairness can be achieved with synthetic data. In this work, we evaluate the impact of synthetic data on bias and performance of FR systems. We generate balanced face dataset, FairFaceGen, using two state of the art text-to-image generators, Flux.1-dev and Stable Diffusion v3.5 (SD35), and combine them with several identity augmentation methods, including Arc2Face and four IP-Adapters. By maintaining equal identity count across synthetic and real datasets, we ensure fair comparisons when evaluating FR performance on standard (LFW, AgeDB-30, etc.) and challenging IJB-B/C benchmarks and FR bias on Racial Faces in-the-Wild (RFW) dataset. Our results demonstrate that although synthetic data still lags behind the real datasets in the generalization on IJB-B/C, demographically balanced synthetic datasets, especially those generated with SD35, show potential for bias mitigation. We also observe that the number and quality of intra-class augmentations significantly affect FR accuracy and fairness. These findings provide practical guidelines for constructing fairer FR systems using synthetic data.
Addressing the Elephant in the Room: Robust Animal Re-Identification with Unsupervised Part-Based Feature Alignment
May 22, 2024



Animal Re-ID is crucial for wildlife conservation, yet it faces unique challenges compared to person Re-ID. First, the scarcity and lack of diversity in datasets lead to background-biased models. Second, animal Re-ID depends on subtle, species-specific cues, further complicated by variations in pose, background, and lighting. This study addresses background biases by proposing a method to systematically remove backgrounds in both training and evaluation phases. And unlike prior works that depend on pose annotations, our approach utilizes an unsupervised technique for feature alignment across body parts and pose variations, enhancing practicality. Our method achieves superior results on three key animal Re-ID datasets: ATRW, YakReID-103, and ELPephants.
Learning Transformations To Reduce the Geometric Shift in Object Detection
Jan 13, 2023



The performance of modern object detectors drops when the test distribution differs from the training one. Most of the methods that address this focus on object appearance changes caused by, e.g., different illumination conditions, or gaps between synthetic and real images. Here, by contrast, we tackle geometric shifts emerging from variations in the image capture process, or due to the constraints of the environment causing differences in the apparent geometry of the content itself. We introduce a self-training approach that learns a set of geometric transformations to minimize these shifts without leveraging any labeled data in the new domain, nor any information about the cameras. We evaluate our method on two different shifts, i.e., a camera's field of view (FoV) change and a viewpoint change. Our results evidence that learning geometric transformations helps detectors to perform better in the target domains.
CLIP the Gap: A Single Domain Generalization Approach for Object Detection
Jan 13, 2023



Single Domain Generalization (SDG) tackles the problem of training a model on a single source domain so that it generalizes to any unseen target domain. While this has been well studied for image classification, the literature on SDG object detection remains almost non-existent. To address the challenges of simultaneously learning robust object localization and representation, we propose to leverage a pre-trained vision-language model to introduce semantic domain concepts via textual prompts. We achieve this via a semantic augmentation strategy acting on the features extracted by the detector backbone, as well as a text-based classification loss. Our experiments evidence the benefits of our approach, outperforming by 10% the only existing SDG object detection method, Single-DGOD [49], on their own diverse weather-driving benchmark.
DSR: Towards Drone Image Super-Resolution
Aug 25, 2022
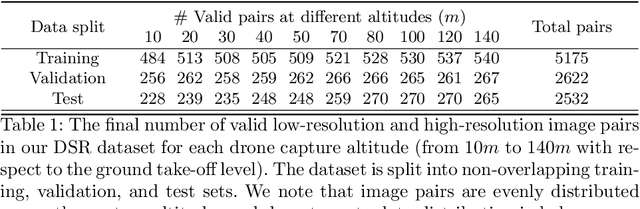

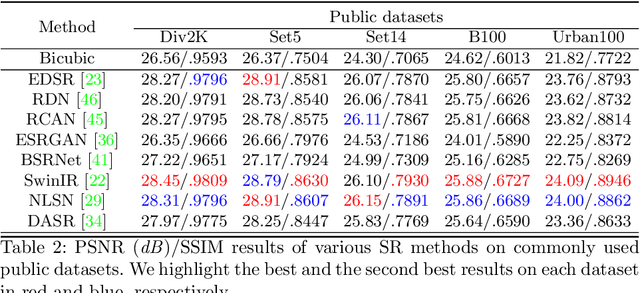
Despite achieving remarkable progress in recent years, single-image super-resolution methods are developed with several limitations. Specifically, they are trained on fixed content domains with certain degradations (whether synthetic or real). The priors they learn are prone to overfitting the training configuration. Therefore, the generalization to novel domains such as drone top view data, and across altitudes, is currently unknown. Nonetheless, pairing drones with proper image super-resolution is of great value. It would enable drones to fly higher covering larger fields of view, while maintaining a high image quality. To answer these questions and pave the way towards drone image super-resolution, we explore this application with particular focus on the single-image case. We propose a novel drone image dataset, with scenes captured at low and high resolutions, and across a span of altitudes. Our results show that off-the-shelf state-of-the-art networks witness a significant drop in performance on this different domain. We additionally show that simple fine-tuning, and incorporating altitude awareness into the network's architecture, both improve the reconstruction performance.