 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Pipeline for Real-Time Visualization of Faces for VR-based Telepresence and Live Broadcasting Utilizing Neural Rendering
Jan 04, 2023While head-mounted displays (HMDs) for Virtual Reality (VR) have become widely available in the consumer market, they pose a considerable obstacle for a realistic face-to-face conversation in VR since HMDs hide a significant portion of the participants faces. Even with image streams from cameras directly attached to an HMD, stitching together a convincing image of an entire face remains a challenging task because of extreme capture angles and strong lens distortions due to a wide field of view. Compared to the long line of research in VR, reconstruction of faces hidden beneath an HMD is a very recent topic of research. While the current state-of-the-art solutions demonstrate photo-realistic 3D reconstruction results, they require high-cost laboratory equipment and large computational costs. We present an approach that focuses on low-cost hardware and can be used on a commodity gaming computer with a single GPU. We leverage the benefits of an end-to-end pipeline by means of Generative Adversarial Networks (GAN). Our GAN produces a frontal-facing 2.5D point cloud based on a training dataset captured with an RGBD camera. In our approach, the training process is offline, while the reconstruction runs in real-time. Our results show adequate reconstruction quality within the 'learned' expressions. Expressions not learned by the network produce artifacts and can trigger the Uncanny Valley effect.
Unmasking Communication Partners: A Low-Cost AI Solution for Digitally Removing Head-Mounted Displays in VR-Based Telepresence
Nov 06, 2020

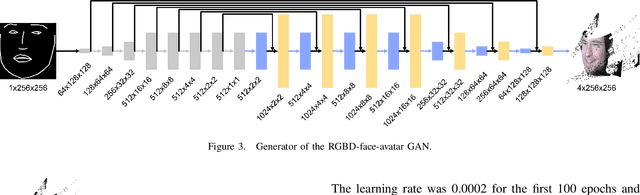
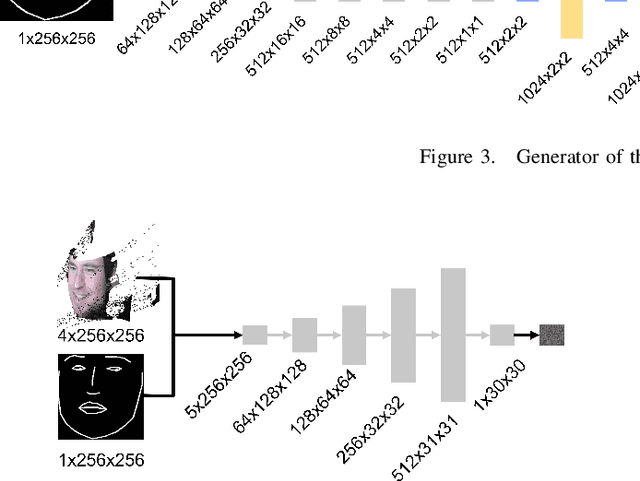
Face-to-face conversation in Virtual Reality (VR) is a challenge when participants wear head-mounted displays (HMD). A significant portion of a participant's face is hidden and facial expressions are difficult to perceive. Past research has shown that high-fidelity face reconstruction with personal avatars in VR is possible under laboratory conditions with high-cost hardware. In this paper, we propose one of the first low-cost systems for this task which uses only open source, free software and affordable hardware. Our approach is to track the user's face underneath the HMD utilizing a Convolutional Neural Network (CNN) and generate corresponding expressions with Generative Adversarial Networks (GAN) for producing RGBD images of the person's face. We use commodity hardware with low-cost extensions such as 3D-printed mounts and miniature cameras. Our approach learns end-to-end without manual intervention, runs in real time, and can be trained and executed on an ordinary gaming computer. We report evaluation results showing that our low-cost system does not achieve the same fidelity of research prototypes using high-end hardware and closed source software, but it is capable of creating individual facial avatars with person-specific characteristics in movements and expressions.