 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Train smarter, not harder: learning deep abdominal CT registration on scarce data
Nov 30, 2022
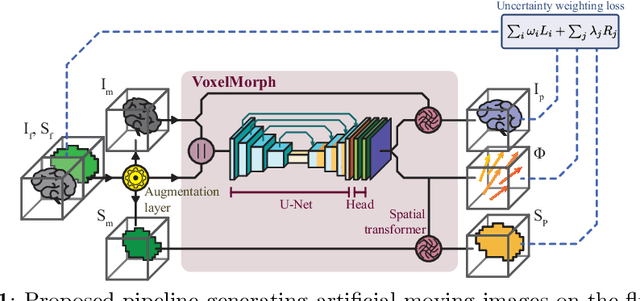
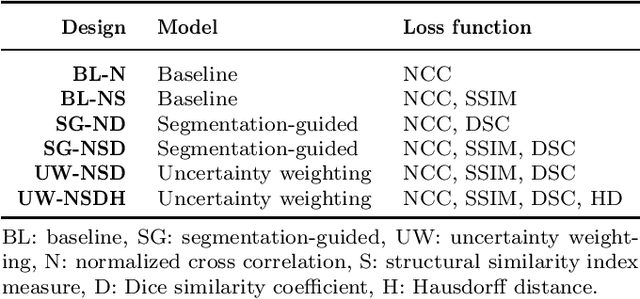
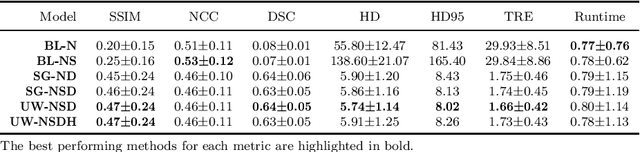
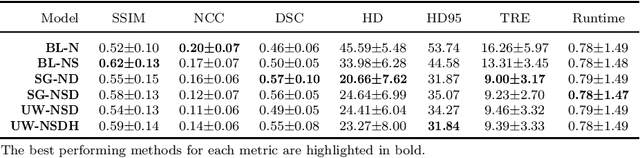
Purpose: This study aims to explore training strategies to improve convolutional neural network-based image-to-image registration for abdominal imaging. Methods: Different training strategies, loss functions, and transfer learning schemes were considered. Furthermore, an augmentation layer which generates artificial training image pairs on-the-fly was proposed, in addition to a loss layer that enables dynamic loss weighting. Results: Guiding registration using segmentations in the training step proved beneficial for deep-learning-based image registration. Finetuning the pretrained model from the brain MRI dataset to the abdominal CT dataset further improved performance on the latter application, removing the need for a large dataset to yield satisfactory performance. Dynamic loss weighting also marginally improved performance, all without impacting inference runtime. Conclusion: Using simple concepts, we improved the performance of a commonly used deep image registration architecture, VoxelMorph. In future work, our framework, DDMR, should be validated on different datasets to further assess its value.
SRTGAN: Triplet Loss based Generative Adversarial Network for Real-World Super-Resolution
Nov 22, 2022

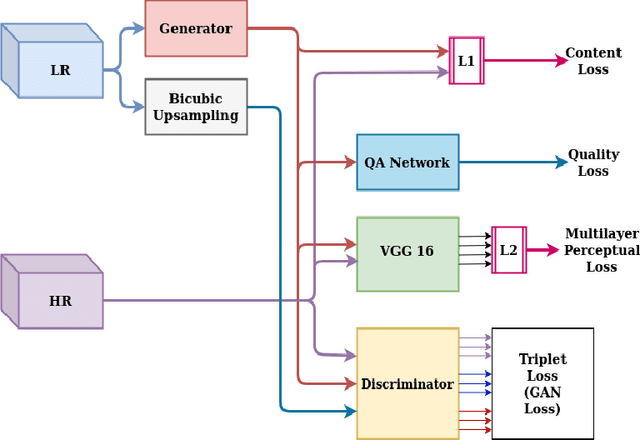

Many applications such as forensics, surveillance, satellite imaging, medical imaging, etc., demand High-Resolution (HR) images. However, obtaining an HR image is not always possible due to the limitations of optical sensors and their costs. An alternative solution called Single Image Super-Resolution (SISR) is a software-driven approach that aims to take a Low-Resolution (LR) image and obtain the HR image. Most supervised SISR solutions use ground truth HR image as a target and do not include the information provided in the LR image, which could be valuable. In this work, we introduce Triplet Loss-based Generative Adversarial Network hereafter referred as SRTGAN for Image Super-Resolution problem on real-world degradation. We introduce a new triplet-based adversarial loss function that exploits the information provided in the LR image by using it as a negative sample. Allowing the patch-based discriminator with access to both HR and LR images optimizes to better differentiate between HR and LR images; hence, improving the adversary. Further, we propose to fuse the adversarial loss, content loss, perceptual loss, and quality loss to obtain Super-Resolution (SR) image with high perceptual fidelity. We validate the superior performance of the proposed method over the other existing methods on the RealSR dataset in terms of quantitative and qualitative metrics.
Automatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022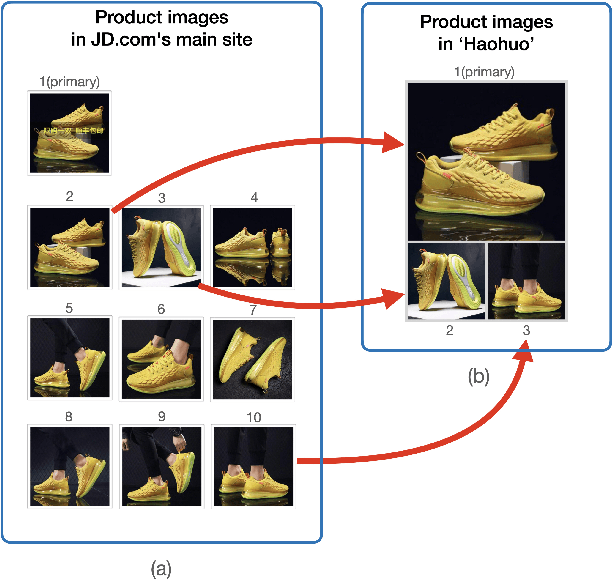

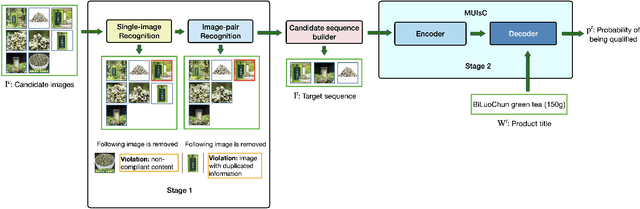
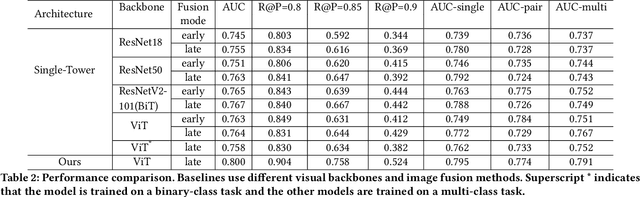
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
Neural Color Operators for Sequential Image Retouching
Jul 17, 2022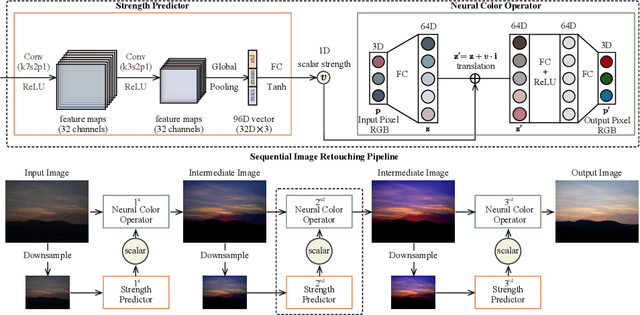
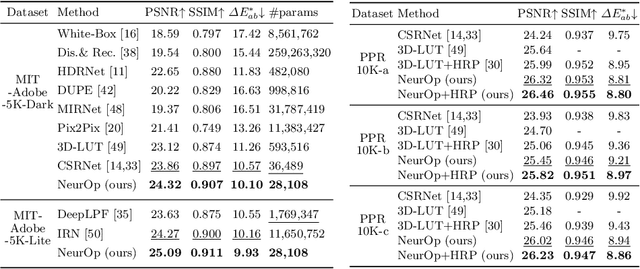


We propose a novel image retouching method by modeling the retouching process as performing a sequence of newly introduced trainable neural color operators. The neural color operator mimics the behavior of traditional color operators and learns pixelwise color transformation while its strength is controlled by a scalar. To reflect the homomorphism property of color operators, we employ equivariant mapping and adopt an encoder-decoder structure which maps the non-linear color transformation to a much simpler transformation (i.e., translation) in a high dimensional space. The scalar strength of each neural color operator is predicted using CNN based strength predictors by analyzing global image statistics. Overall, our method is rather lightweight and offers flexible controls. Experiments and user studies on public datasets show that our method consistently achieves the best results compared with SOTA methods in both quantitative measures and visual qualities. The code and data will be made publicly available.
DELS-MVS: Deep Epipolar Line Search for Multi-View Stereo
Dec 13, 2022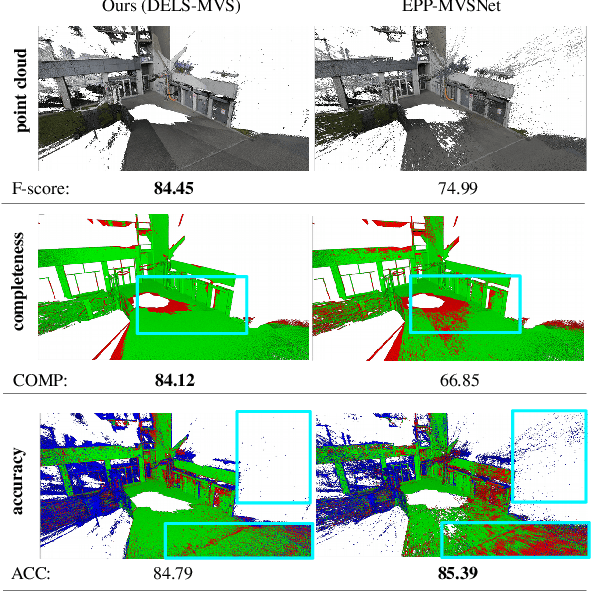
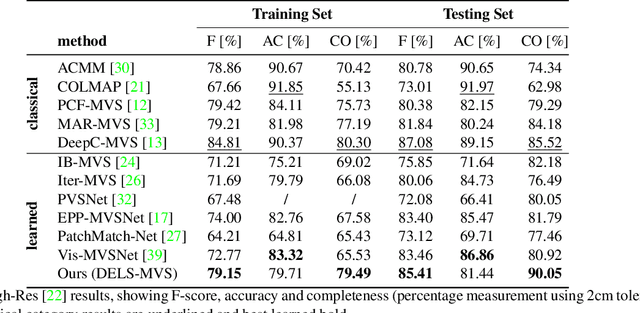
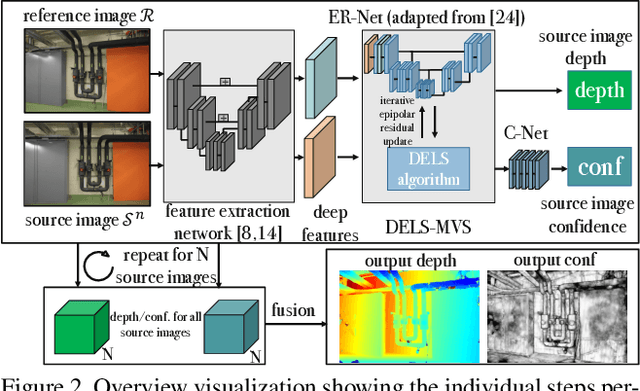
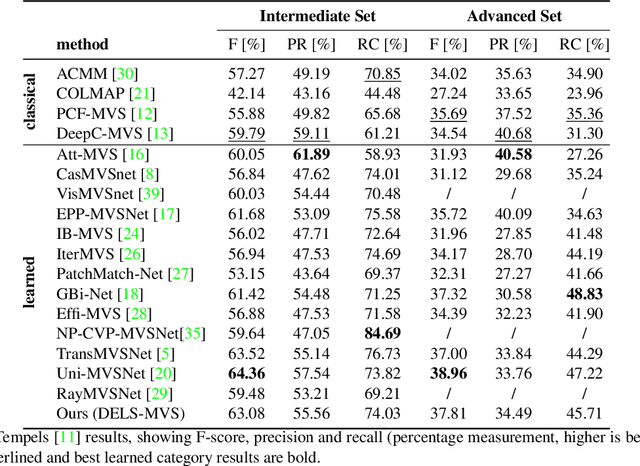
We propose a novel approach for deep learning-based Multi-View Stereo (MVS). For each pixel in the reference image, our method leverages a deep architecture to search for the corresponding point in the source image directly along the corresponding epipolar line. We denote our method DELS-MVS: Deep Epipolar Line Search Multi-View Stereo. Previous works in deep MVS select a range of interest within the depth space, discretize it, and sample the epipolar line according to the resulting depth values: this can result in an uneven scanning of the epipolar line, hence of the image space. Instead, our method works directly on the epipolar line: this guarantees an even scanning of the image space and avoids both the need to select a depth range of interest, which is often not known a priori and can vary dramatically from scene to scene, and the need for a suitable discretization of the depth space. In fact, our search is iterative, which avoids the building of a cost volume, costly both to store and to process. Finally, our method performs a robust geometry-aware fusion of the estimated depth maps, leveraging a confidence predicted alongside each depth. We test DELS-MVS on the ETH3D, Tanks and Temples and DTU benchmarks and achieve competitive results with respect to state-of-the-art approaches.
SUCRe: Leveraging Scene Structure for Underwater Color Restoration
Dec 18, 2022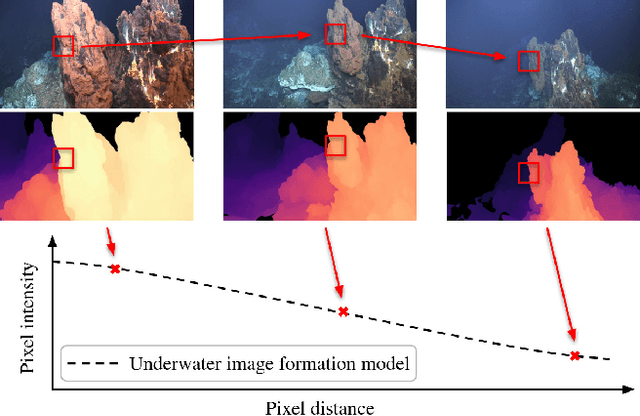

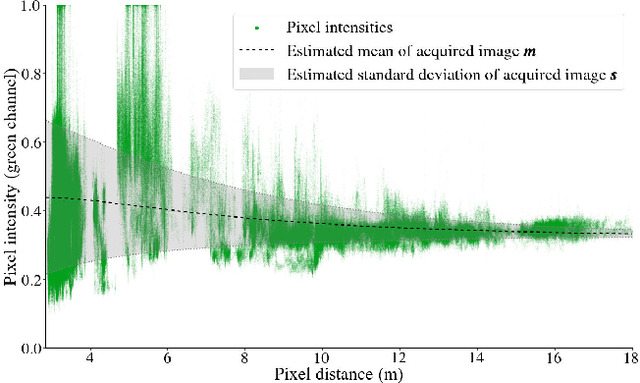
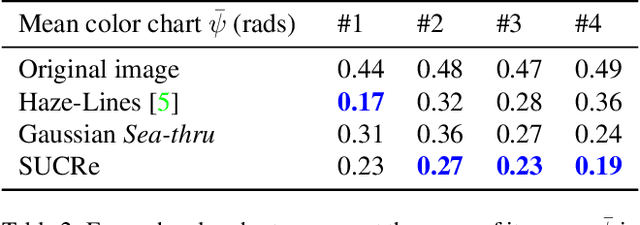
Underwater images are altered by the physical characteristics of the medium through which light rays pass before reaching the optical sensor. Scattering and strong wavelength-dependent absorption significantly modify the captured colors depending on the distance of observed elements to the image plane. In this paper, we aim to recover the original colors of the scene as if the water had no effect on them. We propose two novel methods that rely on different sets of inputs. The first assumes that pixel intensities in the restored image are normally distributed within each color channel, leading to an alternative optimization of the well-known \textit{Sea-thru} method which acts on single images and their distance maps. We additionally introduce SUCRe, a new method that further exploits the scene's 3D Structure for Underwater Color Restoration. By following points in multiple images and tracking their intensities at different distances to the sensor we constrain the optimization of the image formation model parameters. When compared to similar existing approaches, SUCRe provides clear improvements in a variety of scenarios ranging from natural light to deep-sea environments. The code for both approaches is publicly available at https://github.com/clementinboittiaux/sucre .
A Deep Learning Approach Using Masked Image Modeling for Reconstruction of Undersampled K-spaces
Aug 24, 2022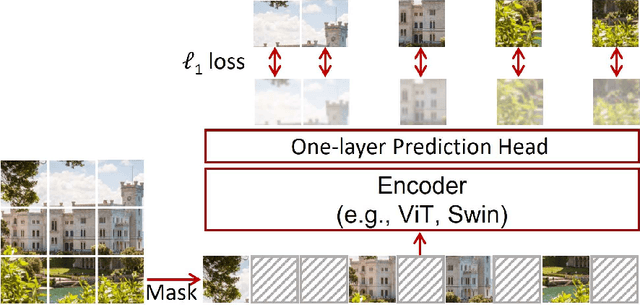
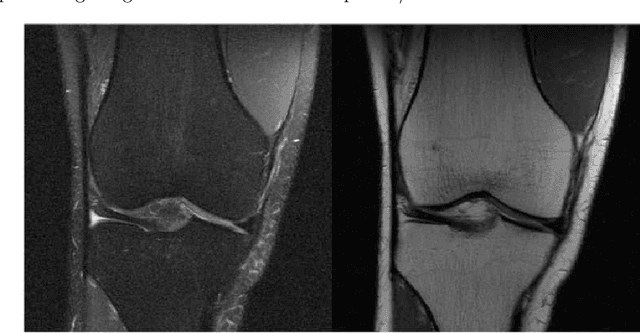
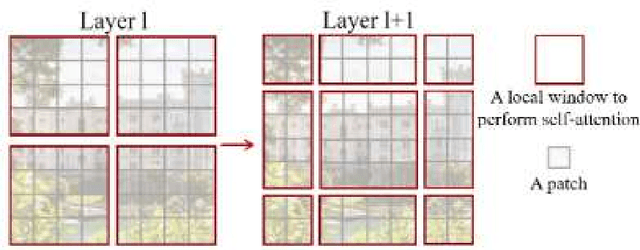
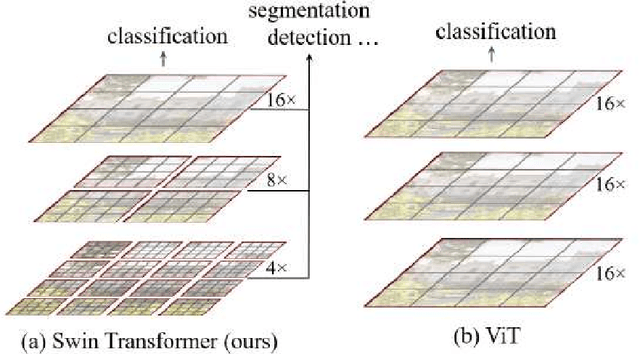
Magnetic Resonance Imaging (MRI) scans are time consuming and precarious, since the patients remain still in a confined space for extended periods of time. To reduce scanning time, some experts have experimented with undersampled k spaces, trying to use deep learning to predict the fully sampled result. These studies report that as many as 20 to 30 minutes could be saved off a scan that takes an hour or more. However, none of these studies have explored the possibility of using masked image modeling (MIM) to predict the missing parts of MRI k spaces. This study makes use of 11161 reconstructed MRI and k spaces of knee MRI images from Facebook's fastmri dataset. This tests a modified version of an existing model using baseline shifted window (Swin) and vision transformer architectures that makes use of MIM on undersampled k spaces to predict the full k space and consequently the full MRI image. Modifications were made using pytorch and numpy libraries, and were published to a github repository. After the model reconstructed the k space images, the basic Fourier transform was applied to determine the actual MRI image. Once the model reached a steady state, experimentation with hyperparameters helped to achieve pinpoint accuracy for the reconstructed images. The model was evaluated through L1 loss, gradient normalization, and structural similarity values. The model produced reconstructed images with L1 loss values averaging to <0.01 and gradient normalization values <0.1 after training finished. The reconstructed k spaces yielded structural similarity values of over 99% for both training and validation with the fully sampled k spaces, while validation loss continually decreased under 0.01. These data strongly support the idea that the algorithm works for MRI reconstruction, as they indicate the model's reconstructed image aligns extremely well with the original, fully sampled k space.
T2CI-GAN: Text to Compressed Image generation using Generative Adversarial Network
Oct 01, 2022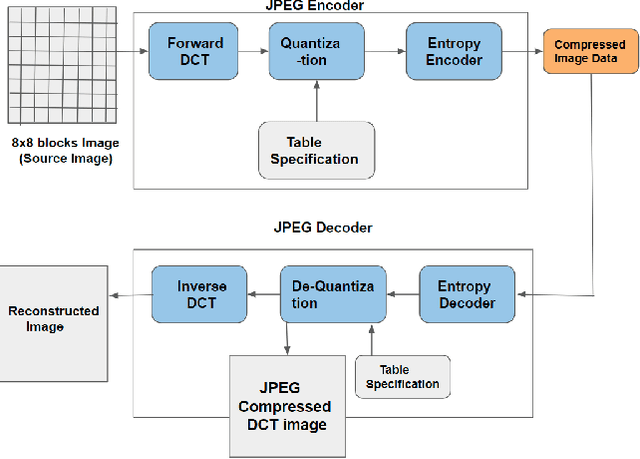


The problem of generating textual descriptions for the visual data has gained research attention in the recent years. In contrast to that the problem of generating visual data from textual descriptions is still very challenging, because it requires the combination of both Natural Language Processing (NLP) and Computer Vision techniques. The existing methods utilize the Generative Adversarial Networks (GANs) and generate the uncompressed images from textual description. However, in practice, most of the visual data are processed and transmitted in the compressed representation. Hence, the proposed work attempts to generate the visual data directly in the compressed representation form using Deep Convolutional GANs (DCGANs) to achieve the storage and computational efficiency. We propose GAN models for compressed image generation from text. The first model is directly trained with JPEG compressed DCT images (compressed domain) to generate the compressed images from text descriptions. The second model is trained with RGB images (pixel domain) to generate JPEG compressed DCT representation from text descriptions. The proposed models are tested on an open source benchmark dataset Oxford-102 Flower images using both RGB and JPEG compressed versions, and accomplished the state-of-the-art performance in the JPEG compressed domain. The code will be publicly released at GitHub after acceptance of paper.
Which Pixel to Annotate: a Label-Efficient Nuclei Segmentation Framework
Dec 20, 2022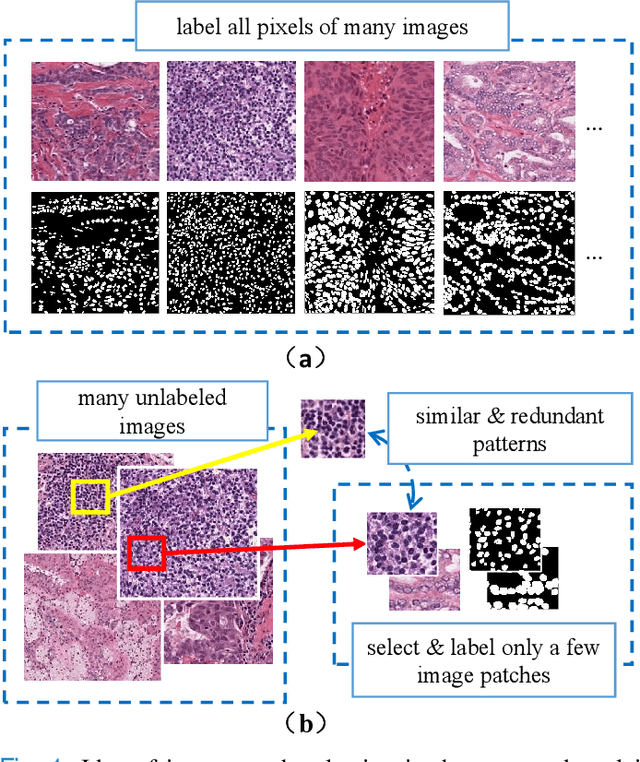
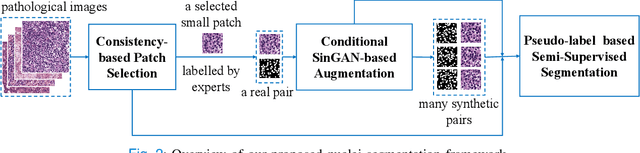
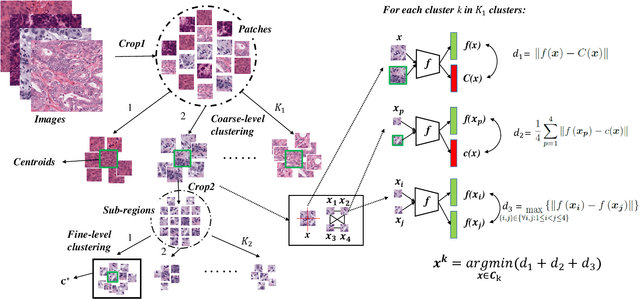
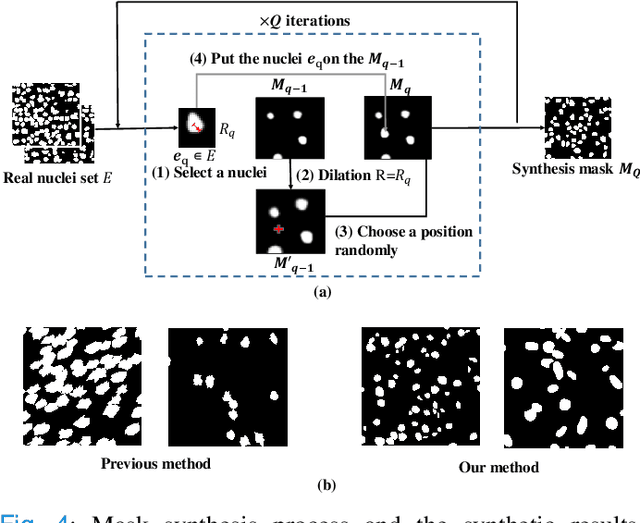
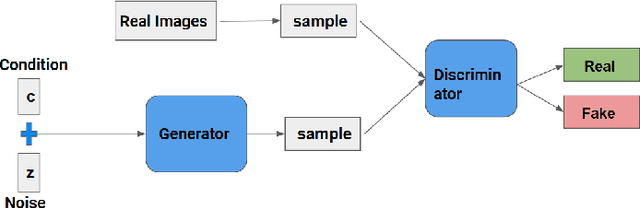
Recently deep neural networks, which require a large amount of annotated samples, have been widely applied in nuclei instance segmentation of H\&E stained pathology images. However, it is inefficient and unnecessary to label all pixels for a dataset of nuclei images which usually contain similar and redundant patterns. Although unsupervised and semi-supervised learning methods have been studied for nuclei segmentation, very few works have delved into the selective labeling of samples to reduce the workload of annotation. Thus, in this paper, we propose a novel full nuclei segmentation framework that chooses only a few image patches to be annotated, augments the training set from the selected samples, and achieves nuclei segmentation in a semi-supervised manner. In the proposed framework, we first develop a novel consistency-based patch selection method to determine which image patches are the most beneficial to the training. Then we introduce a conditional single-image GAN with a component-wise discriminator, to synthesize more training samples. Lastly, our proposed framework trains an existing segmentation model with the above augmented samples. The experimental results show that our proposed method could obtain the same-level performance as a fully-supervised baseline by annotating less than 5% pixels on some benchmarks.
Blind Knowledge Distillation for Robust Image Classification
Nov 21, 2022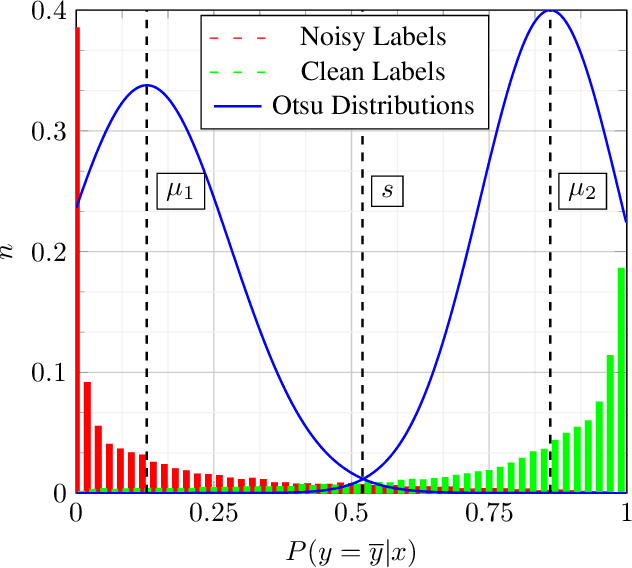
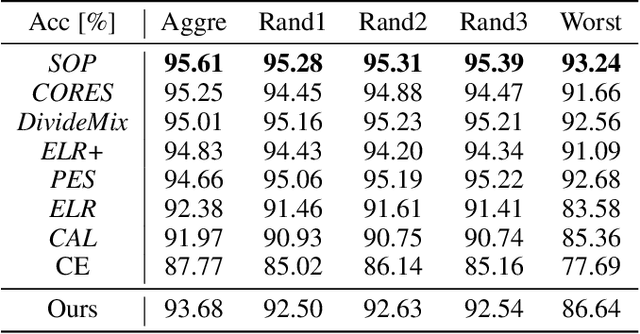
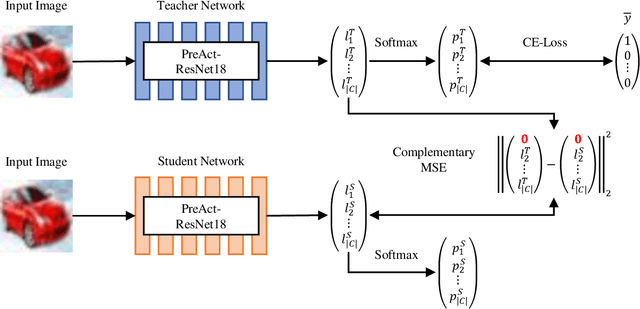
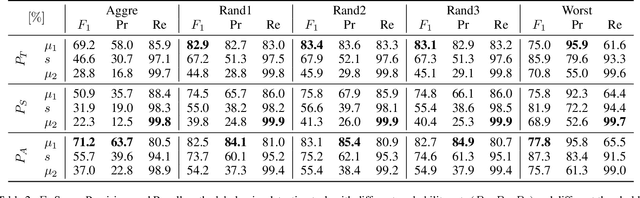
Optimizing neural networks with noisy labels is a challenging task, especially if the label set contains real-world noise. Networks tend to generalize to reasonable patterns in the early training stages and overfit to specific details of noisy samples in the latter ones. We introduce Blind Knowledge Distillation - a novel teacher-student approach for learning with noisy labels by masking the ground truth related teacher output to filter out potentially corrupted knowledge and to estimate the tipping point from generalizing to overfitting. Based on this, we enable the estimation of noise in the training data with Otsus algorithm. With this estimation, we train the network with a modified weighted cross-entropy loss function. We show in our experiments that Blind Knowledge Distillation detects overfitting effectively during training and improves the detection of clean and noisy labels on the recently published CIFAR-N dataset. Code is available at GitHub.